性能问题通用排查思路(一)CPU
本系列文章只是梳理一些常见的线上问题的通用排查思路,能解决70%的问题,对于剩下的30%是一些极端的问题,需要对计算机底层知识有充分的了解,并积累大量问题排查经验,仔细分析才能找到具体原因。
这里基于Linux操作系统,覆盖一台服务器上主要的四大件:CPU、内存、磁盘、网络
- CPU:介绍CPU load和使用率的相关问题
- 内存:介绍内存,包括jvm的内存和native内存的相关问题
- 磁盘:介绍磁盘和文件系统相关问题
- 网络:介绍网络相关问题,包括TCP常遇到的坑
这四大件中每一个都能扩展出N多本书来仔细讲解,如果你对性能很感兴趣,可参考书籍:
- 性能之巅
- BPF之巅
- CPU性能分析与优化
JVM性能可参考:
- 深入理解java虚拟机
- 垃圾回收的算法与实现
性能问题排查通常遵循的套路:发现问题->提出猜想->观测大盘->深入细节->解决问题
- 发现问题:监控、报警、用户反馈问题。
- 提出猜想:排查问题最先要有个方向,大胆提出一些可能的猜想。
- 观测大盘:通过第三方监控、操作系统、编程语言提供的工具或命令,观测系统整体情况,分析问题出现的频率、周期、整体指标,问题发生时对系统有一个整体的把控和认知。
- 深入细节:使用工具排查问题,需要精确到具体的任务、代码等才能解决问题。
- 解决问题:修复问题,并总结复盘,积累经验。
在问题出现时,我们通常会盲猜是自己业务变更导致的,比如写出内存泄露的bug,所以通常会第一时间回滚上线的代码,然后翻代码找原因。但随着虚拟化技术的出现,一台机器上可能混部多个应用,性能问题可能由物理机上的其他应用导致,这就需要细致的排查。
关于本系列文章与读者约定:
- 如果你感觉阅读起来困难,不妨初步阅读,遇到问题时再来看看。
- 每一章会介绍一些相关工具,很多工具展示的信息很全面,如top即包含了cpu信息,也包含内存信息。为了降低学习成本,我会忽略与本章内容无关的信息,放在相应的章节中介绍。
CPU篇
CPU load高怎么办?
CPU load:是指CPU运行时的有效负载
Linux操作系统下的load当然是由操作系统在运行时刻进行采样统计的,我们可以使用常用的命令获取load:
uptime # uptime能够获取当前命令执行瞬间的load信息

每一列含义如下:
HH:mm:ss:系统时间up xx days,HH:mm:系统自启动以来运行了多久x users:有几个登录用户load average:平均负载,三个数值分别为 过去1分钟、5分钟、15分钟的平均值
top # top能够实时观测进程、CPU、内存等信息

top命令信息量还是比较多的。这里只介绍第一行,后面会介绍其他行。每一列含义如下:
top -:命令为top。HH:mm:ss:系统时间。up xx days,HH:mm:系统自启动以来运行了多久。x users:有几个登录用户。load average:平均负载,三个数值分别为过去1分钟、5分钟、15分钟的平均值。
load到底是什么?
在Linux中,任务(进程/线程)状态分为(这里忽略初始状态和死亡状态):
- **TASK_RUNNING:**任务在CPU run queue队列的状态,包括即将要运行的和正在运行的任务。
- TASK_UNINTERRUPTIBLE:不可中断状态的任务,正在读写磁盘、网络等IO操作,系统认为这种状态被中断会造成严重的数据损坏,是不可接受的,所以不可中断。
- TASK_INTERRUPTIBLE:可中断状态的任务,即可被信号打断的任务(对任务执行kill命令或系统调用)。
- TASK_STOPPED和TASK_TRACED:暂停状态和跟踪状态,接受了 SIGSTOP暂停任务,SIGCONT 信号让任务继续运行。
- TASK_ZOMBIE:子任务执行完成后需要父任务回收资源,父任务意外退出导致无法回收子任务,此时子任务处于ZOMBIE状态(僵尸进程)
题外话:僵尸状态通常只出现在进程中,线程状态中看不到不代表没有,只是很难触发且很容易被处理掉。
TASK_RUNNING和TASK_UNINTERRUPTIBLE是load关注的重点,Linux的load统计就是记录了这两种状态下任务在单位时间内CPU的使用情况。
每一颗CPU核分配一个任务,正常情况下load应该小于1,等于1代表满载,大于1代表超载。
举个栗子,在CPU 2核的情况下:
| load值 | 说明 |
|---|---|
| <1 | 只有1颗核在工作,还没有跑满 |
| =1 | 只有1颗核在工作,刚好跑满 |
| >1且<2 | 2颗核在工作,有一颗跑满,另外一颗还没有跑满 |
| =2 | 2颗核在工作,刚好跑满 |
| >2 | 2颗核在工作,CPU非常繁忙,超出了可承受的最大负载 |
所以,load高可分为两种情况:
- 运行中的任务超过了CPU的最大负载
- IO中的任务超过了CPU的最大负载
超出最大负载,意味着你的请求会出现排队现象,响应耗时会增大。
特别要注意,CPU使用率高是因为TASK_RUNNING的任务多,问题出现时很容易直觉性的只排CPU使用率,而忽略TASK_UNINTERRUPTIBLE的任务。有的时候正是因为存在大量的不可中断IO,看起来CPU使用率并不高,但load非常高。
需要额外注意出现频繁上下文切换也会导致load升高。其主要原因是,任务占用的CPU并不多,大量的上下文切换导致CPU 将大量的时间耗费在寄存器、内核和用户栈、以及虚拟内存等资源的保存和恢复上,此时load也会表现的很高!
- TASK_RUNNING的任务多产生的load高,CPU使用率也会高,排查方法参考本章下一节。
- TASK_UNINTERRUPTIBLE,我们通常要排查下网络和磁盘的使用情况(其实不只有磁盘和网络IO会进入这种状态,比如键盘、鼠标也会进入,但都可以忽略)。
- 频繁上下文切换导致任务在内核和用户空间来回周转,所以对于状态为TASK_RUNNING和TASK_UNINTERRUPTIBLE并不能表达出这种情况,而 CPU也是在满载跑着,此时CPU使用率的表现也不高。
先忽略TASK_RUNNING,我们可以使用vmstat命令观测出到底是TASK_UNINTERRUPTIBLE还是频繁上下文导致的load高。vmstat命令直观的展现了整个系统的CPU、IO、内存、上下文切换情况。
vmstat <统计间隔x秒> <统计次数>
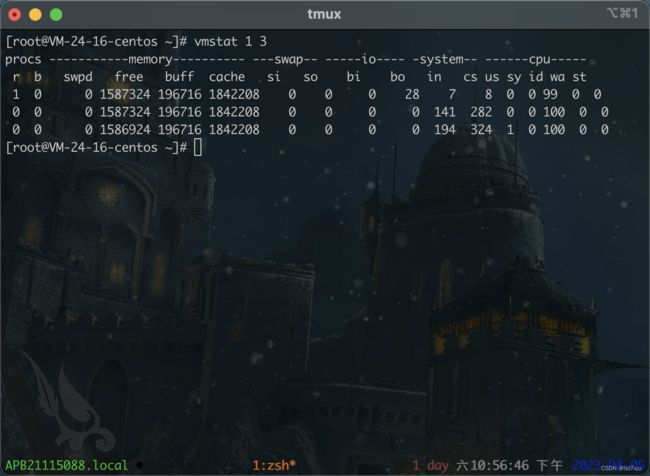
上图中vmstat 1 3的意思是每秒钟采集1次,总共采集3次。每一列含义如下:
- procs:
- r:运行中的任务数。
- b:等待IO的任务数。
- memory:
- swpd:swap分区使用情况(KB),当内存不足时Linux将内存中冷数据写到磁盘swap分区上,腾出内存供进程分配内存。
- free:空闲内存情况(KB)。
- buff:磁盘块设备的缓存使用情况(KB)。
- cache:文件系统的缓存使用情况(KB)。
- swap:
- si:swap分区换入情况(KB/秒)。
- so:swap分区写出情况(KB/秒)。
- io:
- bi:块设备每秒写入数量(block/秒)。
- bo:块设备每秒读取数量(block/秒)。
- system:
- in:每秒中断数。
- cs:每秒上下文切换数。
- cpu
- us:用户态CPU占用百分比。
- sy:内核态CPU占用百分比。
- id:CPU空闲百分比。
- wa:等待IO消耗的CPU百分比。
- st:虚拟化CPU占用百分比。
vmstat表头下面的第一行输出的是系统启动以来所有指标的平均值。
- 对于上下文切换导致的load高情况,cs指标会非常高,且每次采样变化非常大。这意味着你的线程分配不合理(可能因为抢锁)或达到了当前硬件配置可支持的最大负载。
- 对于TASK_UNINTERRUPTIBLE导致的load高情况,b、bi、bo、wa指标都会明显的过高,或增长、下降幅度大。
- 对于TASK_RUNNING情况,自然是r指标高,同时us和sy也会飙高。
在看过系统整体情况后,我们基本可以定位出load高是因为哪种情况导致的,接下来需要找到具体哪个进程,哪个线程导致的。可以使用pidstat和iotop工具进一步排查。
pidstat
pidstat是sysstat包的工具,可以观察每个进程的cpu、IO、内存、上下文切换、线程信息。所以无论是TASK_RUNNING、TASK_UNINTERRUPTIBLE、上下文切换导致的load高问题,我们都可以用pidstat命令观察出具体是哪个进程导致的。通过以下命令安装pidstat
yum install sysstat -y
执行
pidstat -w -d -u -t <统计间隔x秒> <统计次数> # -w显示上下文切换 -d显示IO情况 -u显示CPU情况 -t显示进程下的线程

以上图为例:
第一行包括:系统内核版本、当前系统日期、cpu基本型号、cpu核数。
接下来会分为三段:CPU使用情况、IO情况、上下文切换。
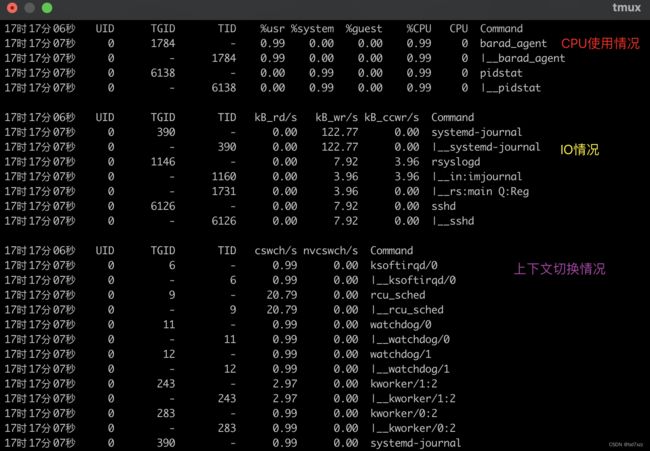
每一段的前四列和最后一列相同:
- 第一列:指标采样时间。
- UID:任务的用户id。
- TGID:线程组id,当前任务是进程,显示为进程id,是线程显示为-。
- TID:线程id,当前任务是进程显示为-,是线程显示为线程id。
- Command:当前任务是进程显示为进程名,是线程显示为线程名。
后面每一列根据不同观测目标显示的不同:
第一段关于CPU:
- %usr:用户态CPU使用率。
- %system:内核态CPU使用率。
- %guest:虚拟化CPU使用率。
- %CPU:当前任务整体CPU使用率。
- CPU:当前任务绑定的CPU编号。
TASK_RUNNING的任务会增加CPU使用率的同时也会增加load。
第二段关于IO:
- kB_rd/s:每秒从磁盘读取的数据量(KB)。
- kB_wr/s:每秒写磁盘的数据量( KB)。
- kB_ccwr/s:写入磁盘被取消的数据量(KB)。
在大量磁盘IO下,任务处于TASK_UNINTERRUPTIBLE状态,此时会导致laod高,所以需要观察磁盘读写情况。
第三段关于上下文切换:
- cswch/s:每秒主动切换上下文次数。
- nvcswch/s:每秒被动切换上下文次数。
主动上下文切换:指任务无法获取资源导致的上下文切换,如:读写IO、内存分配。
被动上下文切换:指任务由于CPU时间片用尽,被系统强制调度发生的上下文切换。
在大量IO的情况下,没有使用zero-copy技术,cswch会非常高。
在业务请求量较大时nvcswch会非常高,若业务系统出现卡顿,很可能就是已达到单机最大负载。
iotop
虽然我们讨论的是cpu问题,但可能TASK_UNINTERRUPTIBLE状态的任务过多或者这种状态任务少,但IO操作频繁。所以我们可以通过iotop命令查看每个进程IO情况,通过以下命令安装iotop。
yum install iotop -y
执行
iotop -o #只显示有io输出的任务

每一列含义如下:
- TID:当前任务的id,包括线程或者进程的id。
- PRIO:任务的优先级。
- USER:执行任务的用户名。
DISK READ:从磁盘读取的数据量。DISK WRITE:写入磁盘的数据量。- SWAPIN:从swap读取的数据量。
- IO<:显示每个任务的 I/O 操作量在总 I/O 操作中的百分比。
- COMMAND:任务名称。
上图中很明显可以看到一条dd命令写磁盘特别频繁,IO达到72.13%。
cpu 使用率高
上面我们说了load,接下来看CPU使用率,本质上CPU使用率是由Linux操作系统采集TASK_RUNNING状态下的任务对CPU的占用比例。使用率过高也会导致你的请求会被排队。
排查使用率高和load高的思路基本一致,由于不用考虑TASK_UNINTERRUPTIBLE的任务,所以排查IO状况的优先级并不高,但由于业务可能涉及到从IO设备读到大量数据后执行计算逻辑,所以IO也不能完全忽略。
我们可以使用vmstat看一下整体情况,很多情况下不用pidstat,通过top看每个任务运行情况,就能解决问题。vmstat和pidstat使用方法不再赘述,下面看看top的使用方法。
top
进入top后,按下键盘上的1,可以看到每颗CPU核的使用情况,如下图有2个核的机器上,%Cpu0代表第一个核的使用情况,%Cpu1代表第二个核的使用情况。

每一行的含义如下(这里只关注CPU相关):
| 行 | 列 | 含义 |
|---|---|---|
| Tasks | x total | 总进程数 |
| Tasks | x running | TASK_RUNNING状态的进程数 |
| Tasks | x sleeping | 包括TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE状态的进程数 |
| Tasks | x stopped | TASK_STOPPED和TASK_TRACED状态的进程数 |
| Tasks | x zombie | TASK_ZOMBIE状态的进程数 |
| %CpuX | us | 用户态CPU占用百分比 |
| %CpuX | sy | 内核态CPU占用百分比 |
| %CpuX | ni | nice设置优先级后的进程CPU占用百分比 |
| %CpuX | id | CPU空闲状态占用百分比 |
| %CpuX | wa | 等待IO的CPU占用百分比 |
| %CpuX | hi | 硬中断CPU占用百分比 |
| %CpuX | si | 软中断CPU占用百分比 |
| %CpuX | st | 虚拟化CPU占用百分比 |
进程信息列表:
- PID:进程Id。
- USER:运行进程的用户。
- PR:进程优先级,实际进程的优先级,
- NI:进程nice值,越低进程优先级越高,负值表示高优先级,正值表示低优先级。
- %CPU:CPU占用百分比。
- S:进程状态,状态值包括:。
- R:TASK_RUNNING状态的任务。
- S:TASK_INTERRUPTIBLE状态的任务。
- D:TASK_UNINTERRUPTIBLE状态的任务。
- T:TASK_STOPPED 或 TASK_TRACED 状态的任务。
- Z:TASK_ZOMBIE状态的任务。
- TIME+:进程累计占用的CPU 时间。
- COMMAND:进程名称。
VIRT\RES\SHR\%MEM和内存有关,后面内存篇再介绍。
按下shift+p可以按CPU使用率对进程排序,有助于快速定位问题。
top命令不加参数默认输出所有进程的信息,通过以下命令查看指定进程下的线程信息
top -Hp <进程id>

线程视角下top输出的内容几乎和进程的一样,这里不再赘述,其中PID列为线程的id。对于jvm应用,可以执行
printf '%x\n'
将线程id转为十六进制,因为jvm中线程id是以十六进制显示的。
执行
jstack -l |grep -A 200 <十六进制线程id>
通过jstack打印线程栈并通过grep命令列出线程id后的200行内容,通常就会很清晰的看到导致cpu使用率高的线程栈信息,这样就能定位到存在问题的代码。
通过上面的分析,我们可以发现无论是CPU还是IO问题,只要拿到线程号都可以使用jstack定位到具体的代码。
常见异常情况
| 现象 | 解决方案 |
|---|---|
| 垃圾回收,如频繁full gc导致的CPU使用率高、load高 | 检查是否存在内存泄露,或内存是否够用 |
| 大量慢SQL,数据库服务器CPU使用率高、load高 | 数据库层面kill掉执行SQL的任务,优化慢SQL |
| 算法或代码使用姿势不正确,如:正则表达式匹配时使用贪婪模式且遇到恶心的表达式 | 优化算法和代码 |
| 单机上多个视频、音频转码导致的CPU使用率高、load高 | 转码为CPU密集计算,需要控制单机可执行任务的数量 |
| 异常日志突然暴增导致的load高 | 病根在异常为何会突然这么多,要解决异常 |
| 超出硬件资源最大负载,频繁切换上下文导致的load高 | 单机算力达到瓶颈,需要及时集群扩容 |
| 单机端口耗尽导致的Load高 | Linux端口耗尽 load会大幅度升高,内核忙于遍历寻找可用端口,此时需要集群扩容或排查为啥耗费那么多端口 |