【Hystrix技术指南】(6)请求合并机制原理分析
[每日一句]
也许你度过了很糟糕的一天,但这并不代表你会因此度过糟糕的一生。
[背景介绍]
- 分布式系统的规模和复杂度不断增加,随着而来的是对分布式系统可用性的要求越来越高。在各种高可用设计模式中,【熔断、隔离、降级、限流】是经常被使用的。而相关的技术,Hystrix本身早已算不上什么新技术,但它却是最经典的技术体系!。
- Hystrix以实现熔断降级的设计,从而提高了系统的可用性。
- Hystrix是一个在调用端上,实现断路器模式,以及隔舱模式,通过避免级联故障,提高系统容错能力,从而实现高可用设计的一个Java服务组件库。
- *Hystrix实现了资源隔离机制
请求合并的作用场景和原理
Hystrix请求合并用于应对服务器的高并发场景,通过合并请求,减少线程的创建和使用,降低服务器请求压力,提高在高并发场景下服务的吞吐量和并发能力
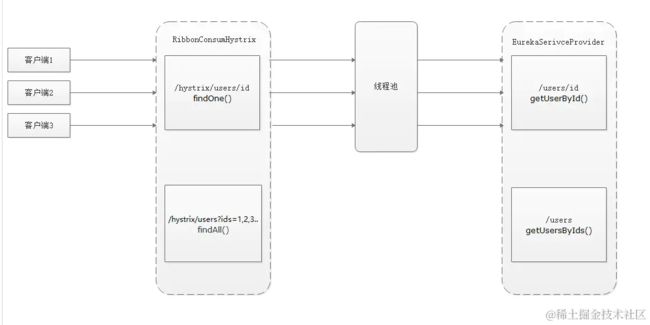
在正常的分布式请求中,客户端发送请求,服务器在接受请求后,向服务提供者发送请求获取数据,这种模式在高并发的场景下就会导致线程池有大量的线程处于等待状态,从而导致响应缓慢,同时线程池的资源也是有限的,每一个请求都分配一个资源,也是无谓的消耗了很多服务器资源,在这种场景下我们可以通过使用hystrix的请求合并来降低对提供者过多的访问,减少线程池资源的消耗,从而提高系统的吞吐量和响应速度。
如下图,采用请求合并后的服务模式
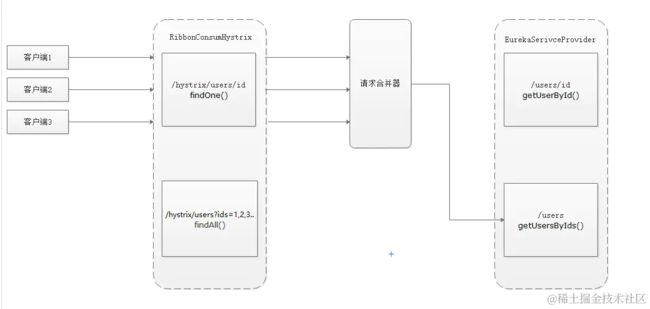
请求合并可以通过 构建类和添加注解的方式实现,这里我们先说通过构建合并类的方式实现请求合并
- 请求合并的实现包含了两个主要实现类,一个是合并请求类,一个是批量处理类,合并请求类的作用是收集一定时间内的请求,将他们传递的参数汇总。
- *然后调用批量处理类,通过向服务调用者发送请求获取批量处理的结果数据,最后在对应的request方法体中依次封装获取的结果,并返回回去
请求合并
- 可以在HystrixCommand之前放置一个『请求合并器』(HystrixCollapser为请求合并器的抽象父类),该合并器可以将多个发往同一个后端依赖服务的请求合并成一个。
- *Hystrix请求合并用于应对服务器的高并发场景,通过合并请求,减少线程的创建和使用,降低服务器请求压力,提高在高并发场景下服务的吞吐量和并发能力
下图展示了在两种场景(未增加『请求合并器』和增加『请求合并器』)下,线程和网络连接数量(假设所有请求在一个很小的时间窗口内,例如 10ms,是『并发』的): 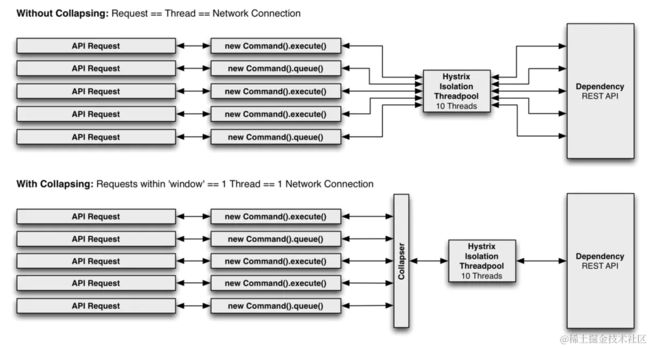
为什么要使用请求合并?
在并发执行HystrixCommand时,利用请求合并能减少线程和网络连接数量。
通过使用HystrixCollapser,Hystrix能自动完成请求的合并,开发者不需要对现有代码做批量化的开发。
全局上下文(适用于所有Tomcat线程)
理想情况下,合并过程应该发生在系统全局层面,这样用户发起的,由Tomcat线程执行的所有请求都能被执行合并操作。
例如, 有这样一个需求,用户需要获取电影评级,而这些数据需要系统请求依赖服务来获取,对依赖服务的请求使用HystrixCommand进行包装,并增加了请求合并的配置,这样,当同一个JVM中其他线程需要执行同样的请求时, Hystrix会将这个请求同其他同样的请求合并,只产生一个网络请求。
注意:合并器会传递一个HystrixRequestContext对象到合并的网络请求中,因此,下游系统需要支持批量化,以使请求合并发挥其高效的特点。
用户请求上下文(适用于单个 Tomcat 线程)
如果给HystrixCommand只配置成针对单个用户进行请求合并,则 Hystrix 只会在单个 Tomcat 线程(即请求)中进行请求合并。
例如,如果用户想加载 300 个视频对象的书签,请求合并后,Hystrix 会将原本需要发起的 300 个网络请求合并到一个。
对象模型和代码复杂度
很多时候,当你创建一个对象模型,适用于对象的消费者逻辑,结果发现这个模型会导致生产者无法充分利用其拥有的资源。
例如,这里有一个包含300个视频对象的列表,需要遍历这个列表,并对每一个对象调用getSomeAttribute()方法,这是一个显而易见的对象模型,但如果简单处理的话,可能会导致300 次的网络请求(假设getSomeAttribute()方法内需要发出网络请求),每一个网络请求可能都会花上几毫秒(显然,这种方式非常容易拖慢系统)。
当然,你也可以要求用户在调用getSomeAttribute()之前,先判断一下哪些视频对象真正需要请求其属性。
你可以将对象模型进行拆分,从一个地方获取视频列表,然后从另一个地方获取视频的属性。
但这些实现会导致API非常丑陋,且实现的对象模型无法完全满足用户使用模式。 并且在企业级开发时,很容易因为开发者的疏忽导致错误或者不够高效,因为不同的开发者可能有不同的请求方式,这样一个地方的优化不足以保证在所有地方都会有优化。
通过将合并逻辑下沉到Hystrix层,不管你如何设计对象模型,或者以何种方式去调用依赖服务,又或者开发者是否意识到这些逻辑需要不需要进行优化,这些都不需要考虑,因为Hystrix能统一处理。
getSomeAttribute()方法能放在它最适合的位置,并且能以最适合的方式被调用,Hystrix 的请求合并器会自动将请求合并到合并时间窗口内。
请求合并带来的额外开销
请求合并会导致依赖服务的请求延迟增高(该延迟为等待请求的延迟),延迟的最大值为合并时间窗口大小。
若某个请求耗时的中位数是 5ms,合并时间窗口为 10ms,那么在最坏情况下(注:合并时间窗口开启时发起请求),请求需要消耗 15ms 才能完成。通常情况下,请求不太可能恰好在合并时间窗口开启时发起,因此,请求合并带来的额外开销应该是合并时间窗口的一般,在此例中是 5ms。
请求合并带来的额外开销是否值得,取决于将要执行的命令,高延迟的命令相比较而言不会有太大的影响。同时,缓存 Key 的选择也决定了在一个合并时间窗口内能『并发』执行的命令数量:如果一个合并时间窗口内只有 1~2 个请求,将请求合并显然不是明智的选择。
事实上,如果单线程循环调用同一个依赖服务的情况下,如果将请求合并,会导致这个循环成为系统性能的瓶颈,因为每一个请求都需要等待 10ms 的合并时间周期。
然而,如果一个命令具有高并发度,并且能批量处理多个,甚至上百个的话,请求合并带来的性能开销会因为吞吐量的极大提升而基本可以忽略,因为 Hystrix 会减少这些请求所需的线程和网络连接数量。
请求合并器的执行流程
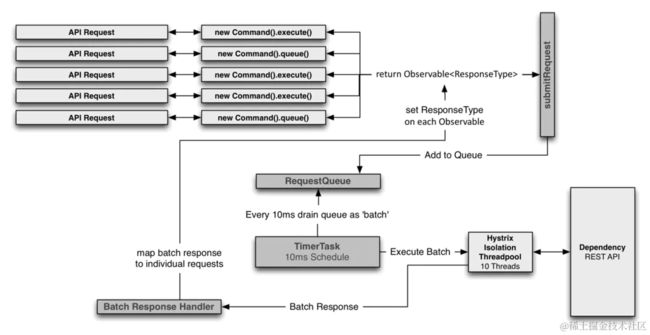
请求合并器的执行流程
请求缓存
在HystrixCommand和HystrixObservableCommand的实现中,你可以定义一个缓存的 Key,这个Key用于在同一个请求上下文(全局或者用户级)中标识缓存的请求结果,当然,该缓存是线程安全的。
下例展示了在一个完整 HTTP 请求周期内,两个线程执行命令的流程:

请求缓存例子
请求缓存有如下好处:
不同请求路径上针对同一个依赖服务进行的重复请求(有同一个缓存 Key),不会真实请求多次 这个特性在企业级系统中非常有用,在这些系统中,开发者往往开发的只是系统功能的一部分。(注:这样,开发者彼此隔离,不太可能使用同样的方法或者策略去请求同一个依赖服务提供的资源)
例如,请求一个用户的Account的逻辑如下所示,这个逻辑往往在系统不同地方被用到:
Account account = new UserGetAccount(accountId).execute();
Observable accountObservable = new UserGetAccount(accountId).observe();
复制代码
Hystrix的RequestCache只会在内部执行run()方法一次,上面两个线程在执行HystrixCommand命令时,会得到相同的结果,即使这两个命令是两个不同的实例。
数据获取具有一致性
因为缓存的存在,除了第一次请求需要真正访问依赖服务以外,后续请求全部从缓存中获取,可以保证在同一个用户请求内,不会出现依赖服务返回不同的回应的情况。
避免不必要的线程执行
在construct()或run()方法执行之前,会先从请求缓存中获取数据,因此,Hystrix 能利用这个特性避免不必要的线程执行,减小系统开销。
若Hystrix没有实现请求缓存,那么HystrixCommand和HystrixObservableCommand的实现者需要自己在construct()或run()方法中实现缓存,这种方式无法避免不必要的线程执行开销。
分享资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9sEg6B06-1691457511837)(https://pic.imgdb.cn/item/64d0dc6a1ddac507cc857b30.png)]
获取以上资源请访问开源项目 点击跳转