马毅、LeCun联合发布EMP-SSL,突破自监督学习效率极限

夕小瑶科技说 分享
来源 | 新智元
EMP-SSL实现了超高的自监督学习效率,训练1个epoch即可实现不错的分类性能。
过去几年,无监督和自监督学习(SSL)取得了巨大进步,通过SSL学习得到的表征在分类性能上甚至赶上了有监督学习,在某些情况下甚至还能超过有监督学习,这一趋势也为视觉任务的大规模数据驱动无监督学习提供了可能。
虽然自监督学习的实验性能惊人,但大多数自监督学习方法都是相当「低效」的,通常需要数百个训练epoch才能完全收敛。
最近,马毅教授、图灵奖得主Yann LeCun团队发布了一种新的自监督学习方法Extreme-Multi-Patch Self-Supervised-Learning(EMP-SSL),证明了高效自监督学习的关键是增加每个图像实例中的图像块数量。

论文链接:
https://arxiv.org/pdf/2304.03977.pdf
代码链接:
https://github.com/tsb0601/EMP-SSL
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
hi!
该方法不依赖于自监督学习中常见的启发式技术,如分支之间的权重共享,特征归一化、输出量化和停止梯度等,并将训练时间减少了两个数量级。
实验结果表明,只需一个训练epoch,文中所提出的方法就能够在CIFAR-10数据集上收敛到85.1%的准确率,在CIFAR-100数据集上收敛到58.5%,在Tiny ImageNet上收敛到38.1%,在ImageNet-100上收敛到58.5%
如果将训练epoch数提高到10,该方法可以在CIFAR-10上实现91.5%,在CIFAR-100上实现70.1%,在Tiny ImageNet上实现51.5%,在ImageNet-100上实现78.9%
此外,研究结果还表明,相比其他基线方法,EMP-SSL展现出相当好的训练数据领域外(out-of-domain)的迁移性能。
马毅教授于1995年获得清华大学自动化与应用数学双学士学位,并于1997年获加州大学伯克利分校EECS硕士学位,2000年获数学硕士学位与EECS博士学位。

2018年马毅教授加入加州大学伯克利分校电子工程与计算机科学系,今年1月加入香港大学出任数据科学研究院院长,最近又接任香港大学计算系主任。
主要研究方向为3D计算机视觉、高维数据的低维模型、可扩展性优化和机器学习,最近的研究主题包括大规模3D几何重构和交互以及低维模型与深度网络的关系。
EMP-SSL
整体流程
与其他 SSL 方法类似,EMP-SSL也是从图像的增强视图(augmented views)中获得联合嵌入,其中增强视图是固定大小的图像块(image patch)
这类方法有两个目标:
-
同一图像的两个不同增强图像的表征应该更接近;
-
表征空间不应该是collapsed trivial space,即必须保留数据的重要几何或随机结构。
之前的研究主要探索了各种策略和不同的启发式方法来实现这两个特性,并取得了越来越好的性能,其成功主要源于对图像块共现的学习。
为了让图像块共现的学习更有效率,研究人员在EMP-SSL中将自监督学习中的图像块数量增加到了极限(extreme)。
首先,对于输入的图像,先通过随机裁剪(可重叠)切分成n个固定大小的图像块,然后使用标准的数据增强技术对图像块进行增强。
对每个增强的图像块,通过两个网络分别获得获取嵌入(embedding)和投影(projection),其中嵌入网络是一个比较深的网络(如ResNet-18),投影网络更小,只有两个全连接层,二者共同组成编码器。

在训练期间,模型采用Total Coding Rate(TCR)正则化技术来避免表征崩溃。

研究人员也希望来自同一图像的不同图像块的表征是不变的,即在表示空间中应该尽可能接近,所以要尽量缩小增强图像的表征与同一图像中所有增强图像块的平均表征之间的距离,所以训练目标为:

其中Z代表不同增强图像块的表征平均值,D为距离函数(余弦相似度),即D的值越大,二者越相似。
这个目标函数可以看作是最大速率下降(maximal rate reduction)的一个变体,也可以看作是基于协方差的 SSL 方法的广义版本,将n设置为2就是常见的2-view自监督学习方法,也可以将n设的更大,以提高图像块贡献的学习速度

特征袋模型
研究人员将输入图像的表征定义为所有图像块的嵌入平均值,但也有工作认为,如果嵌入表征中包含更多的等差数列和局部性,性能也会更好,而投影应该更稳定,不过这个结论仍然缺乏严格证明。
架构
研究人员尝试采用自监督学习中经常使用的简单网络架构形式,即EMP-SSL 不需要预测网络、动量编码器、无差别算子或停止梯度。
虽然这些方法在某些自监督学习方法中已被证明是有效的,但其有效性可以留在下一步工作中继续探索,这篇论文主要关注提出的自监督学习方法的有效性。
实验结果
一个epoch的自监督学习
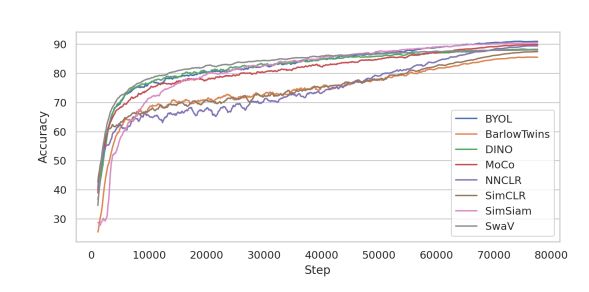
对比其他最先进的自监督学习方法,可以看到,即便EMP-SSL只看过一次数据集,也能收敛到接近完全收敛的SOTA性能。

结果表明,该方法不仅在提高当前 SSL 方法的收敛性方面具有巨大潜力,而且在计算机视觉的其他领域,如在线学习、增量学习和机器人学习中,也具有巨大潜力。
标准数据集上快速收敛
在标准数据集中,包括CIFAR-10、CIFAR-100、Tiny ImageNet 和 ImageNet-100,研究人员验证了所提目标函数在收敛速度方面的效率。
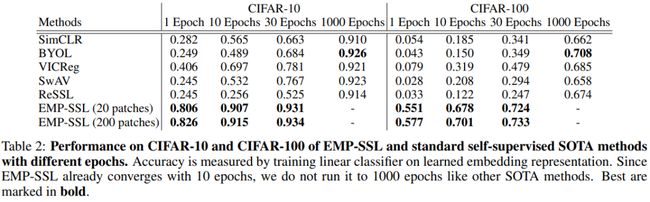
可以看到,EMP-SSL仅在一个epoch的训练之后,就在 20 个图像块的设置下实现了 80.6% 的准确率,在 200 个图像块设置下可以实现82.6%的准确率。

在10个epoch后,EMP-SSL就已经收敛到超过90%,也是CIFAR-10数据集上最先进的自监督学习方法;而30个 epochs 时,EMP-SSL 的准确率更是超过了当前所有方法,达到了 93% 以上。
关于时间效率问题,在联合嵌入自监督学习中,图像块数量的增加可能会延长训练时间。
研究人员对比了每种方法在 CIFAR 上达到规定性能所需的时间,使用两台 A100 GPU 进行实验。

从实验结果可以看出,在 CIFAR-10数据集上,EMP-SSL 不仅收敛所需的训练epoch少得多,而且运行时间也更短。
在更复杂的 CIFAR-100 数据集上,这一优势更加明显,以前的方法需要更多的训练epoch,因此收敛时间也更长,而 EMP-SSL 只需要几个训练epoch就能达到很好的效果。
表征可视化
研究人员使用 t-SNE maps的结果来证明,尽管只训练几个epoch,EMP-SSL 已经学到了有意义的表征。

在CIFAR-10训练集上学到的表征图中,EMP-SSL 使用 200 个图像块训练了 10 个 epochs,其他 SOTA 方法则训练了 1000 个 epochs,其中每个颜色代表一个不同的类别。
可以看到,EMP-SSL 为不同类别学习到的表征分离得更好,并且更结构化;与其他 SOTA 方法相比,EMP-SSL学习到的特征显示出更精细的低维结构。
最令人惊叹的是,所有这些结构都是在短短 10 个epoch的训练中学到的!
图像块数量消融实验
研究人员还对目标函数中的图像块数量n进行了消融实验,证明了该参数在收敛过程中的重要性。

大模型AI全栈手册
**行业首份AI全栈手册开放下载啦!!**
长达3000页,涵盖大语言模型技术发展、AIGC技术最新动向和应用、深度学习技术等AI方向。微信公众号关注“夕小瑶科技说”,回复“789”下载资料

参考资料
[1]https://arxiv.org/pdf/2304.03977.pdf