北大提出DragonDiffusion,用Diffusion升级DragGAN,可一键实现拖拉拽
夕小瑶科技说 分享
来源 | 量子位
作者 | 明敏
北大团队最新工作,用扩散模型也能实现拖拉拽P图!
点一点,就能让雪山长个儿:
或者让太阳升起:

这就是DragonDiffusion,由北京大学张健老师团队VILLA(Visual-Information Intelligent Learning LAB),依托北京大学深圳研究生院-兔展智能AIGC联合实验室,联合腾讯ARC Lab共同带来。
它可以被理解为DragGAN的变种。
DragGAN如今GitHub Star量已经超过3w,它的底层模型基于GAN(生成对抗网络)。
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
gpt4test.com
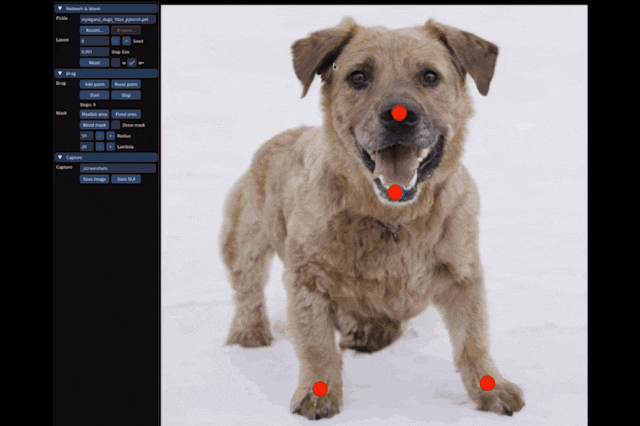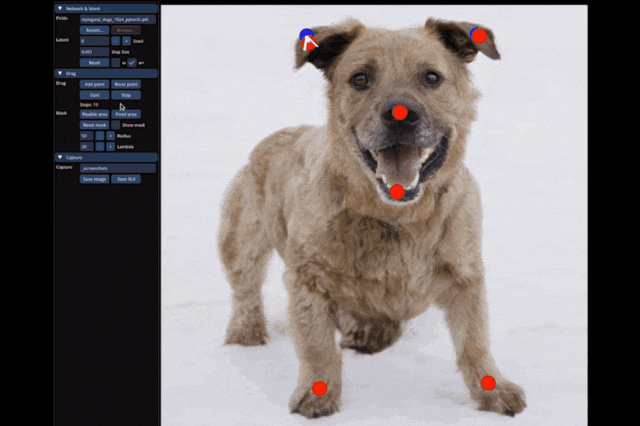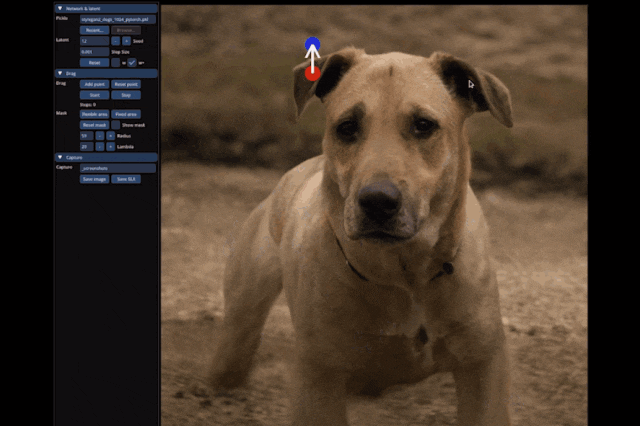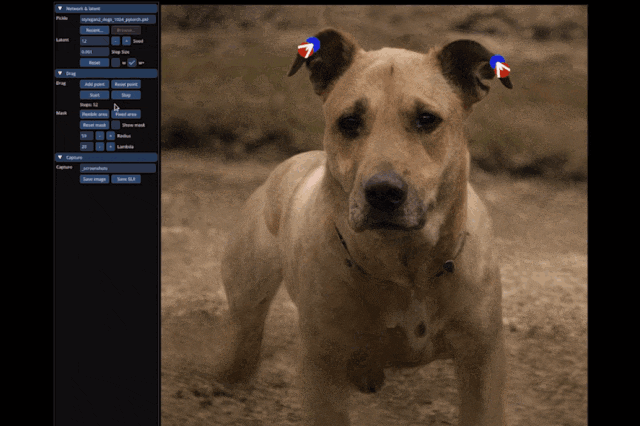
一直以来,GAN在泛化能力和生成图像质量上都有短板。
而这刚好是扩散模型(Diffusion Model)的长处。
所以张健老师团队就将DragGAN范式推广到了Diffusion模型上。
该成果发布时登上知乎热榜。
有人评价说,这解决了Stable Diffusion生成图片中部分残缺的问题,可以很好进行控制重绘。

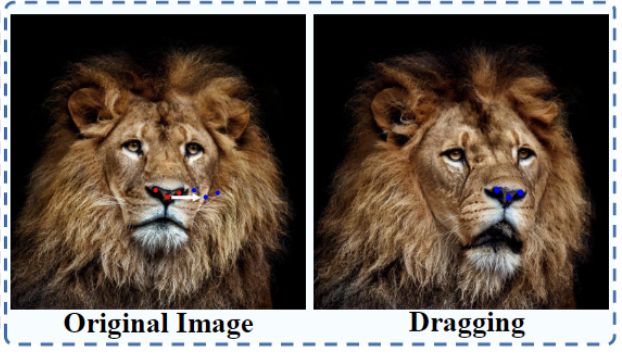
让狮子在照片中转头
Dragon Diffusion能带来的效果还包括改变车头形状:

让沙发逐渐变长:
再或者是手动瘦脸:

也能替换照片中的物体,比如把甜甜圈放到另一张图片里:

或者是给狮子转转头:
该方法框架中包括两个分支,引导分支(guidance branch)和生成分支(generation branch)。
首先,待编辑图像图片通过Diffusion的逆过程,找到该图像在扩散隐空间中的表示,作为两个分支的输入。
其中,引导分支会对原图像进行重建,重建过程中将原图像中的信息注入下方的生成分支。
生成分支的作用是引导信息对原图像进行编辑,同时保持主要内容与原图一致。
根据扩散模型中间特征具有强对应关系,DragonDiffusion在每一个扩散迭补中,将两个分支的隐变量图片通过相同的UNet去噪器转换到特征域。
然后利用两个mask,和区域。标定拖动内容在原图像和编辑后图像中的位置,然后约束的内容出现在区域。
论文通过cosin距离来度量两个区域的相似度,并对相似度进行归一化:
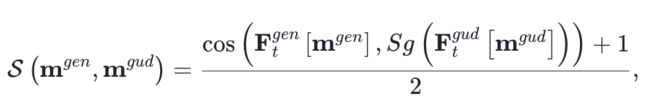
除了约束编辑后的内容变化,还应该保持其他未编辑区域与原图的一致性。这里也同样通过对应区域的相似度进行约束。最终,总损失函数设计为:
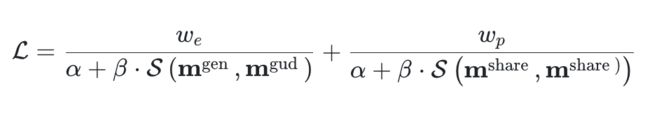
在编辑信息的注入方面,论文通过score-based Diffusion将有条件的扩散过程视为一个联合的score function:
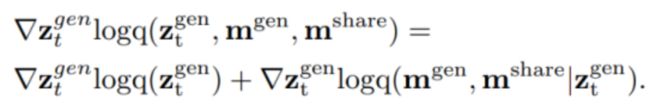
将编辑信号通过基于特征强对应关系的score function转化为梯度,对扩散过程中的隐变量进行更新。
为了兼顾语义和图形上的对齐,作者在这个引导策略的基础上引入了多尺度引导对齐设计。
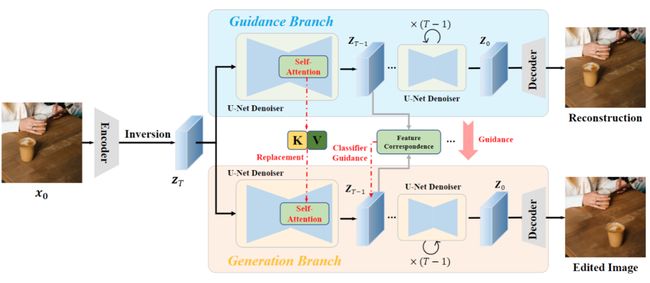
此外,为了进一步保证编辑结果和原图的一致性,DragonDiffusion方法中设计了一种跨分支的自注意力机制。
具体做法是利用引导分支自注意力模块中的Key和Value替换生成分支自注意力模块中的Key和Value,以此来实现特征层面的参考信息注入。
最终,论文提出的方法,凭借其高效的设计,为生成的图像和真实图像提供了多种编辑模式。
这包括在图像中移动物体、调整物体大小、替换物体外观和图像内容拖动。
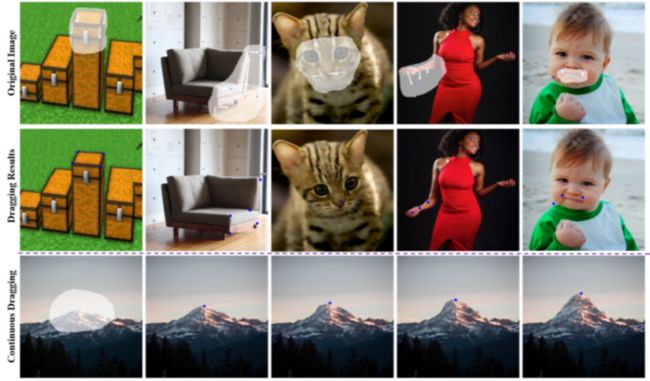
在该方法中,所有的内容编辑和保存信号都来自图像本身,无需任何微调或训练附加模块,这能简化编辑过程。
研究人员在实验中发现,神经网络第一层太浅,无法准确重建图像。但如果到第四层重建又会太深,效果同样很差。在第二/三层的效果最佳。

相较于其他方法,Dragon Diffusion的消除效果也表现更好。

来自北大张健团队等
该成果由北京大学张健团队、腾讯ARC Lab和北京大学深圳研究生院-兔展智能AIGC联合实验室共同带来。
张健老师团队曾主导开发T2I-Adapter,能够对扩散模型生成内容进行精准控制。
在GitHub上揽星超2k。
该技术已被Stable Diffusion官方使用,作为涂鸦生图工具Stable Doodle的核心控制技术。
兔展智能联手北大深研院建立的AIGC联合实验室,近期在图像编辑生成、法律AI产品等多个领域取得突破性技术成果。
就在几周前,北大-兔展AIGC联合实验室就推出了登上知乎热搜第一的的大语言模型产品ChatLaw,在全网带来千万曝光同时,也引发了一轮社会讨论。
联合实验室将聚焦以CV为核心的多模态大模型,在语言领域继续深挖ChatLaw背后的ChatKnowledge大模型,解决法律金融等垂直领域防幻觉,可私有化、数据安全问题。
据悉,实验室近期还会推出原创对标Stable Diffusion的大模型。
论文地址:https://arxiv.org/abs/2307.02421
项目主页:https://mc-e.github.io/project/DragonDiffusion/
