PaddleOCR数据准备

<注> 以下三篇文章,重新修改后在呈现给大家,共同学习!!!。
- PaddleOCR文字识别C#部署-1
- PaddleOCR文字识别C#部署-2
- PaddleOCR文字识别C#部署-3
文章目录
-
- 数据集
- 自定义数据集
-
- 合成工具
- text_renderer
数据集
PaddleOCR准备了很多数据集链接,除了开源数据集,Baidu还准备了合成工具和标注工具。
PaddleOCR 数据准备

文本检测以icdar2015数据集为例,介绍PaddleOCR检测模型训练、评估和测试。数据转换工具在 ppocr/utils/gen_label.py,

# 将官网下载的标签文件转换为 train_icdar2015_label.txt
python gen_label.py --mode="det" --root_path="./train_data/icdar2015/text_localization/icdar_c4_train_imgs/" --input_path="./train_data/icdar2015/text_localization/ch4_training_localization_transcription_gt" --output_label="./train_data/icdar2015/text_localization/train_icdar2015_label.txt"
#gen_label.py 源代码中编码问题
import os
import argparse
import json
def gen_rec_label(input_path, out_label):
with open(out_label, 'w') as out_file:
with open(input_path, 'r') as f:
for line in f.readlines():
tmp = line.strip('\n').replace(" ", "").split(',')
img_path, label = tmp[0], tmp[1]
label = label.replace("\"", "")
out_file.write(img_path + '\t' + label + '\n')
def gen_det_label(root_path, input_dir, out_label):
with open(out_label, 'w',encoding='utf-8') as out_file:
for label_file in os.listdir(input_dir):
img_path = root_path + label_file[3:-4] + ".jpg"
label = []
print(label_file)
with open(os.path.join(input_dir, label_file), "r",encoding='UTF-8-sig') as f:
for line in f.readlines():
print(line)
#tmp = str(line).replace("\\xef\\xbb\\xbf", "").split(',')
#tmp = str(line).strip("\\r\\n").replace("\\xef\\xbb\\xbf", "").split(',')
tmp=str(line).strip("\n\r").split(',')
print(tmp)
points = tmp[:8]
print(len(points))
s = []
for i in range(0, len(points), 2):
b = points[i:i + 2]
print(b)
b = [int(float(t)) for t in b]
s.append(b)
result = {"transcription": tmp[8], "points": s}
label.append(result)
out_file.write(img_path + '\t' + json.dumps(
label, ensure_ascii=False) + '\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--mode',
type=str,
default="rec",
help='Generate rec_label or det_label, can be set rec or det')
parser.add_argument(
'--root_path',
type=str,
default="text_localization/ch4_test_images/",
help='The root directory of images.Only takes effect when mode=det ')
parser.add_argument(
'--input_path',
type=str,
default="icdar2015/text_localization/Challenge4_Test_Task1_GT",
help='Input_label or input path to be converted')
parser.add_argument(
'--output_label',
type=str,
default="text_localization/test_icdar2015_label.txt",
help='Output file name')
args = parser.parse_args()
if args.mode == "rec":
print("Generate rec label")
gen_rec_label(args.input_path, args.output_label)
elif args.mode == "det":
gen_det_label(args.root_path, args.input_path, args.output_label)
/PaddleOCR/train_data/icdar2015/text_localization/
└─ icdar_c4_train_imgs/ icdar数据集的训练数据
└─ ch4_test_images/ icdar数据集的测试数据
└─ train_icdar2015_label.txt icdar数据集的训练标注
└─ test_icdar2015_label.txt icdar数据集的测试标注

自定义数据集
数据准备
配置参数
合成工具

text_renderer
下载地址:链接1和链接2,text_renderer是是目前看起来效果比较好的.
支持模块化设计。你可以很容易地添加语料库,效果,布局。
支持生成与OCR兼容的lmdb数据集,见数据集
支持在不同字体、字号或字体颜色的图像上呈现多个语料库。布局负责多个语料库之间的布局
不支持:生成垂直文本
不支持:语料库采样器:有助于执行字符平衡
在Windows下测试
git clone https://github.com/oh-my-ocr/text_renderer
cd text_renderer # 自己换个文件夹
python setup.py develop
pip install -r requirements.txt
# windows下 是 docker\requirements.txt(因为发现如果是 / 的话,按tab键没有提示)
# 然后就会开始安装了
python main.py --config example_data/example.py --dataset img --num_processes 2 --log_period 10



text_renderer生成自己数据,在运行示例是main.py需要参数:
python main.py --config example_data/example.py --dataset img --num_processes 2 --log_period 10
#说明
config:配置文件路径
dataset: 数据集
num_processes: 使用的进程数量
log_period: 日志打印时间 (0, 100)。(PS:上面的是10,意思是进度每完成10%打印一次)
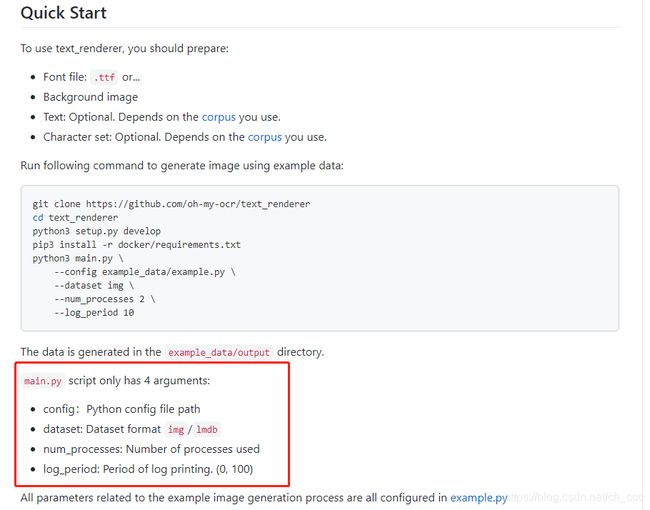

main.py:配置文件路径、数据集、使用的进程数量、日志打印时间
tool:lmdb2img.py用于转换文件标记类型
text_renderer:最主要的
example_data:要合成需要的文件,背景、字符串等
参考CV学习笔记(十八):文本数据集生成(text_renderer)下载了FarringtonDb.ttf字体。PaddleOCR数字仪表识别——2(New). textrenderer使用及修改使之符合PaddleOCR数据标准

- bg文件夹:存放要产生的图片的背景。
- char文件夹: 默认有两个txt文件,chn.txt和eng.txt.(utf-8的格式)
- font文件夹: 存放字体ttf.
- font_list文件夹 默认有一个font_list.txt文件,每行一个字体名称(对应于font文件夹中的.ttf文件)
- output文件夹: 输出图片及标签的文件
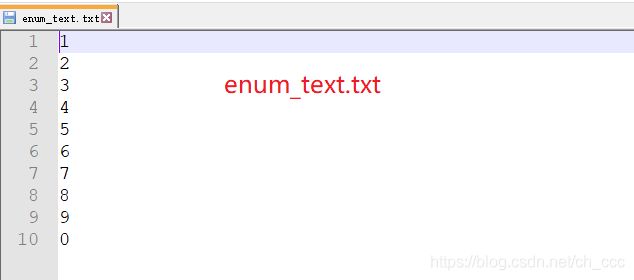
- text文件夹 默认有三个txt文件,分别是chn_text.txt,eng_text.txt,enum_text.txt。更改了一下enum_text.txt.
#修改example.py 只保留enum_data部分
import os
from pathlib import Path
from text_renderer.effect import *
from text_renderer.corpus import *
from text_renderer.config import (
RenderCfg,
NormPerspectiveTransformCfg,
GeneratorCfg,
)
from text_renderer.layout.same_line import SameLineLayout
from text_renderer.layout.extra_text_line import ExtraTextLineLayout
CURRENT_DIR = Path(os.path.abspath(os.path.dirname(__file__)))
OUT_DIR = CURRENT_DIR / "output"
DATA_DIR = CURRENT_DIR
BG_DIR = DATA_DIR / "bg"
CHAR_DIR = DATA_DIR / "char"
FONT_DIR = DATA_DIR / "font"
FONT_LIST_DIR = DATA_DIR / "font_list"
TEXT_DIR = DATA_DIR / "text"
font_cfg = dict(
font_dir=FONT_DIR,
font_list_file=FONT_LIST_DIR / "font_list.txt",
font_size=(30, 31),
)
perspective_transform = NormPerspectiveTransformCfg(20, 20, 1.5)
# chn_data = GeneratorCfg(
# num_image=50,
# save_dir=OUT_DIR / "char_corpus",
# render_cfg=RenderCfg(
# bg_dir=BG_DIR,
# perspective_transform=perspective_transform,
# corpus=CharCorpus(
# CharCorpusCfg(
# text_paths=[TEXT_DIR / "chn_text.txt", TEXT_DIR / "eng_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "chn.txt",
# length=(5, 10),
# char_spacing=(-0.3, 1.3),
# **font_cfg
# ),
# ),
# corpus_effects=Effects([Line(0.5), OneOf([DropoutRand(), DropoutVertical()])]),
# ),
# )
enum_data = GeneratorCfg(
num_image=50,#修改产生图片的数量 num_image
save_dir=OUT_DIR / "enum_corpus",
render_cfg=RenderCfg(
bg_dir=BG_DIR,
perspective_transform=perspective_transform,
corpus=EnumCorpus(
EnumCorpusCfg(
text_paths=[TEXT_DIR / "enum_text.txt"],
filter_by_chars=True,
num_pick=5,#num_pick 生成文本由enum_text几个组成
chars_file=CHAR_DIR / "chn.txt",
**font_cfg
),
),
#text_color_cfg= SimpleTextColorCfg(alpha=(200, 255)) #添加
),
)
rand_data = GeneratorCfg(
num_image=50,
save_dir=OUT_DIR / "rand_corpus",
render_cfg=RenderCfg(
bg_dir=BG_DIR,
perspective_transform=perspective_transform,
corpus=RandCorpus(RandCorpusCfg(chars_file=CHAR_DIR / "chn.txt", **font_cfg),),
),
)
# eng_word_data = GeneratorCfg(
# num_image=50,
# save_dir=OUT_DIR / "word_corpus",
# render_cfg=RenderCfg(
# bg_dir=BG_DIR,
# perspective_transform=perspective_transform,
# corpus=WordCorpus(
# WordCorpusCfg(
# text_paths=[TEXT_DIR / "eng_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "eng.txt",
# **font_cfg
# ),
# ),
# ),
# )
# same_line_data = GeneratorCfg(
# num_image=100,
# save_dir=OUT_DIR / "same_line_data",
# render_cfg=RenderCfg(
# bg_dir=BG_DIR,
# perspective_transform=perspective_transform,
# layout=SameLineLayout(),
# gray=False,
# corpus=[
# EnumCorpus(
# EnumCorpusCfg(
# text_paths=[TEXT_DIR / "enum_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "chn.txt",
# **font_cfg
# ),
# ),
# CharCorpus(
# CharCorpusCfg(
# text_paths=[TEXT_DIR / "chn_text.txt", TEXT_DIR / "eng_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "chn.txt",
# length=(5, 10),
# font_dir=font_cfg["font_dir"],
# font_list_file=font_cfg["font_list_file"],
# font_size=(30, 35),
# ),
# ),
# ],
# corpus_effects=[Effects([Padding(), DropoutRand()]), NoEffects(),],
# layout_effects=Effects(Line(p=1)),
# ),
# )
# extra_text_line_data = GeneratorCfg(
# num_image=100,
# save_dir=OUT_DIR / "extra_text_line_data",
# render_cfg=RenderCfg(
# bg_dir=BG_DIR,
# perspective_transform=perspective_transform,
# layout=ExtraTextLineLayout(),
# corpus=[
# CharCorpus(
# CharCorpusCfg(
# text_paths=[TEXT_DIR / "chn_text.txt", TEXT_DIR / "eng_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "chn.txt",
# length=(9, 10),
# font_dir=font_cfg["font_dir"],
# font_list_file=font_cfg["font_list_file"],
# font_size=(30, 35),
# ),
# ),
# CharCorpus(
# CharCorpusCfg(
# text_paths=[TEXT_DIR / "chn_text.txt", TEXT_DIR / "eng_text.txt"],
# filter_by_chars=True,
# chars_file=CHAR_DIR / "chn.txt",
# length=(9, 10),
# font_dir=font_cfg["font_dir"],
# font_list_file=font_cfg["font_list_file"],
# font_size=(30, 35),
# ),
# ),
# ],
# corpus_effects=[Effects([Padding()]), NoEffects()],
# layout_effects=Effects(Line(p=1)),
# ),
# )
# fmt: off
# configs = [
# chn_data,
# enum_data,
# rand_data,
# eng_word_data,
# same_line_data,
# extra_text_line_data
# ]
# fmt: on
configs = [
enum_data
]
#生成文本
python main.py --config example_data\example.py --dataset img --num_processes 2 --log_period 10

百度字体编辑器网页版(线上网址没打开)
FontStore(最好下载压缩包,不然字体是镜像翻转)
参考:
PaddleOCR 使用以及用自己的数据训练
CV学习笔记(十八):文本数据集生成(text_renderer)
CV学习笔记(十九):数据集拼接生成