【论文阅读笔记|EMNLP2022】A Span-level Bidirectional Network for Aspect Sentiment Triplet Extraction
论文题目:A Span-level Bidirectional Network for Aspect Sentiment Triplet Extraction
论文来源:EMNLP2022
论文链接:https://aclanthology.org/2022.emnlp-main.289.pdf
代码链接:https://github.com/chen1310054465/SBN
0 摘要
aspect情感三元组提取(ASTE)是一种新的细粒度情感分析任务,旨在从复习句子中提取三元组aspect、情感和opinion。最近,span级模型通过利用对所有可能跨度的预测,在ASTE任务上取得了令人满意的结果。由于所有可能的跨度都显著增加了潜在的aspect 和opinion候选词的数量,因此有效地提取其中的三元组是至关重要和具有挑战性的。在本文中,我们提出了一个span级双向网络,它利用所有可能的跨度作为输入,并双向从跨度中提取三元组。具体地说,我们设计了aspect解码器和opinion解码器来解码跨度表示,并从aspect到opinion和opinion到aspect的方向上提取三元组。通过这两个解码器的互补作用,整个网络可以更全面地从span域中提取出三元组。此外,考虑到不能保证跨度之间的互斥,我们设计了一个相似的跨度分离损失,通过在训练过程中扩展相似跨度的KL发散来促进区分正确跨度的下游任务;在推理过程中,我们采用推理策略,根据他们的认知分数从结果中消除冲突的三元组。实验结果表明,我们的框架不仅显著优于现有的方法,而且在预测具有多标记实体的三元组和提取包含多三元组的句子中取得了更好的性能。
1 引言
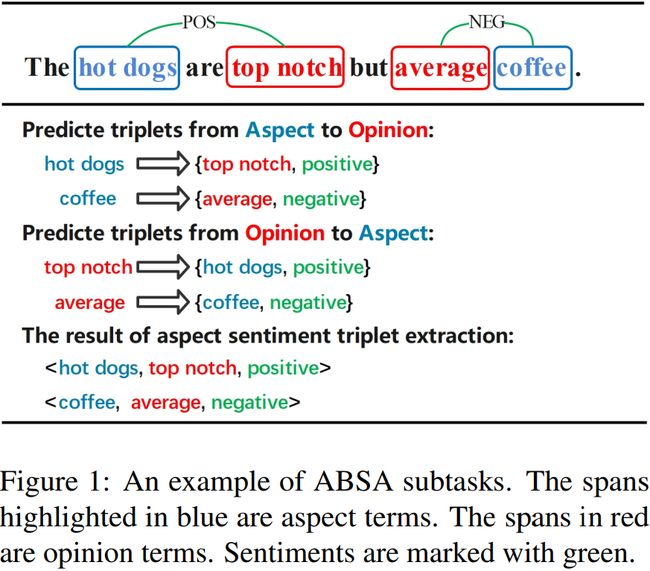
基于aspect的情感分析(ABSA)是自然语言处理(NLP)中的一个重要领域。ABSA任务包含各种基本的子任务,如aspect术语提取(ATE)、opinion提取(OTE)和aspect级情感分类(ASC)。最近的研究集中于单独解决这些任务,或做两个子任务的组合,如aspect极性共同提取(APCE)、aspect和opinion共同提取(AOCE)和aspect-opinion对提取(AOPE)。然而,这些子任务中没有一个旨在同时提取aspect(AT)及其相应的opinion(OT)和情感极性(SP)。为了解决这个问题,(Peng et al.,2020)提出了aspect情感三元组提取(ASTE)任务,该任务旨在提取图1中的(AT、OT、ST)三元组,如(hot dogs, top notch, positive)和(coffee, average, negative)。
为了解决ASTE任务,最近的工作使用顺序token级别的方法,并将该任务表示为序列标注问题。尽管这些工作都取得了很好的结果,但是token级模型由于顺序解码而遭受级联错误。因此,提出了一个span级模型,通过枚举所有可能的span作为输入,来捕获aspect和opinion之间的span-to-span的交互作用。尽管他们的工作取得了很好的结果,但现有的span级模型仍然存在几个挑战。
- 由于aspect和opinion都可以触发三元组,因此双向识别三元组是一个挑战。
- 与token级方法不同,span级输入不能保证span之间的互斥性,因此类似的span(共享token的span),如hot dogs, dogs,和 the hot dogs,可能会导致下游任务的混淆。因此,span级模型有效区分这些相似的span是一个挑战。
- 相似span的存在使span级模型能够在结果中产生相互冲突的三元组,如(hot dogs, top notch,positive), (hot dogs,are top notch, positive)和(the hot dogs, top notch, positive)。
为了解决这些挑战,我们提出了一个针对ASTE任务的span级双向网络。与之前的span级工作不同,我们通过aspect解码器和opinion解码器的联合,从aspect到opinion和opinion到aspect的两个不同的方向解码所有可能的跨度表示。
- 在aspect到opinion的方向上,aspect解码器的目的是提取aspect词,如{热狗,咖啡},而opinion解码器的目的是提取每个特定的aspect词,如{热狗}。
- 在opinion到aspect的方向上,利用opinion解码器和aspect解码器分别提取opinion词及其对应的aspect词。
此外,我们设计了相似的跨度分离损失,以指导模型在训练过程中有意区分相似的跨度表示;并提出了一种在预测过程中采用的推理策略来消除提取结果中的冲突三元组。为了验证我们的框架的有效性,我们在四个基准数据集上进行了一系列的实验。实验结果表明,我们的框架大大优于现有的方法。综上所述,我们的贡献如下:
- 我们设计了一个跨级双向网络,在一个跨级模型中,从aspect对观点和opinion到aspect的方向上提取三元组。通过这种设计,我们的网络可以更全面地识别三元组。
- 我们提出使用类似的跨度分离损失来分离包含共享标记的跨度的表示。基于这些不同的跨度表示,下游模型可以更精确地区分跨度表示。
- 我们设计了一种推理策略来消除由于跨度之间缺乏互斥性而导致的潜在冲突三元组。
2 相关工作
基于aspect的情感分析(ABSA)是一项细粒度的情感分析任务,由各种子任务组成,包括aspect提取(ATE)、opinion提取(OTE)、aspect层面的情感分类(ASC)。由于这些子任务是单独解决的,最近的研究试图将两个子任务作为一个复合任务相结合,如aspect项极性共提取(APCE);aspect和opinion的共同提取,aspect类别和情感分类,和aspect-opinion对提取(AOPE)。虽然许多工作在这些任务上取得了很大的进展,但没有一个任务的目标是识别aspect以及它们相应的opinion和情感极性。
为了解决这一问题,(Peng et al.,2020)提出了aspect情感三元组提取(ASTE)任务,该任务旨在提取aspect术语、aspect术语的情感以及导致情感的opinion。一些方法(设计了一个统一的标记方案来解决这一任务。其他一些人将该任务制定为多回合机器阅读理解任务,并使用机器阅读理解框架来解决它。最近,(Xu et al.,2021)提出了一个跨级模型,首先提取aspect词和OTs,然后预测每个(aspect词,opinion)对的情感关系。
3 方法
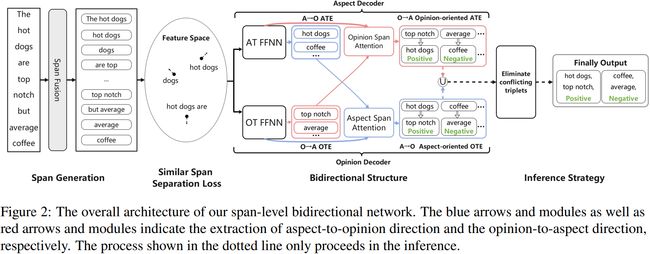
如图2所示,我们的网络由四个部分组成:跨度生成、类似的跨度分离损失、双向结构和推理策略。在下面的小节中,我们首先给出ASTE任务的识别,然后详细说明我们的网络结构。
3.1 任务定义
对于一个句子![]() 包括n单词,ASTE任务的目标是从给定的句子中提取一组aspect情感三元组
包括n单词,ASTE任务的目标是从给定的句子中提取一组aspect情感三元组![]() ,其中(a, o, c)指的是(aspect、opinion、sentiment polarity),c∈{P ositive, Neutral, Negative}。
,其中(a, o, c)指的是(aspect、opinion、sentiment polarity),c∈{P ositive, Neutral, Negative}。
3.2 跨度生成
给定一个带有n个标记的句子S,总共有m个可能的跨度。每个跨度![]() 包含从start(i)到end(i)在内的所有token定义,且跨度
包含从start(i)到end(i)在内的所有token定义,且跨度 的最大长度为
的最大长度为![]() :
:
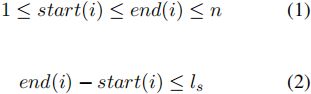
为了获得跨度表示,我们需要首先获得标记级的表示。在本文中,我们用BERT作为句子编码器,获得给定句子S的标记级上下文表示![]() 。然后,通过最大池化对标记级表示进行组合。请注意,可以使用各种方法来生成跨度的表示,这些跨度生成方法的有效性将在附录中的消融研究中进行研究。我们将跨度si的表示定义为:
。然后,通过最大池化对标记级表示进行组合。请注意,可以使用各种方法来生成跨度的表示,这些跨度生成方法的有效性将在附录中的消融研究中进行研究。我们将跨度si的表示定义为:
![]()
其中,Max表示最大池化。
3.3 相似span间隙损失
在生成跨度的表示之后,大多数以前的模型直接为下游任务使用跨度表示。然而,在一个句子中列举所有可能的跨度不可避免地会产生大量具有相同token 的跨度,并且由于它们的相邻分布,模型可能在处理这些相似的跨度而受到限制。为了分离具有相似分布的跨度,我们提出了一个基于KL散度的相似的跨度分离损失来分离相似的跨度,如图2所示。类似的跨度分离损失定义为:
![]()
![]()
![]()
其中,![]() 表示与
表示与 共享至少一个token的跨度的表示集合。请注意,我们并没有直接使用KL散度作为分离损失,而是结合log(1 + 1/x)函数,以实现当KL散度很小时,分离损失很大,反之亦然。
共享至少一个token的跨度的表示集合。请注意,我们并没有直接使用KL散度作为分离损失,而是结合log(1 + 1/x)函数,以实现当KL散度很小时,分离损失很大,反之亦然。
3.4 双向结构
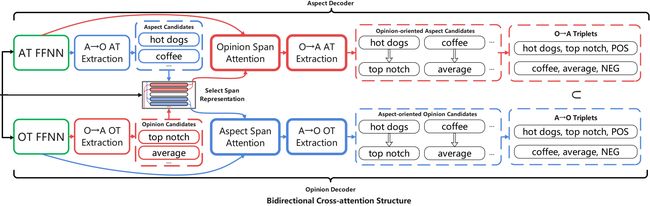
由于aspect情感三元组可以由一个aspect或一个opinion触发,我们提出了一个双向结构来解码跨度表示。如图2所示,该双向结构由一个aspect解码器和一个opinion解码器组成。双向结构中每个组件的细节将在下面的小节中给出。
3.4.1 Aspect-to-opinion Direction
在aspect到opinion的方向上(图2中的蓝色箭头和模块),aspect解码器的目的是从句子中提取所有的aspect词和他们的情感。我们可以得到的置信度得分和AT情感的概率如下:
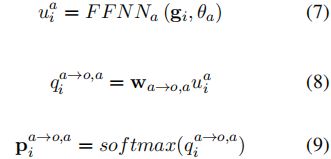
其中![]() 表示aspect解码器的FFNN,θa是FFNN的参数,
表示aspect解码器的FFNN,θa是FFNN的参数,![]() 0是一个可训练的权重向量,c
0是一个可训练的权重向量,c![]() 是类别的数量。
是类别的数量。
然后,给出所有有效aspect词![]() 的原始跨度表示的集合Ga,利用opinion解码器利用注意机制识别所有OTs及其对每个特定有效aspect词的情感。同样,我们通过以下方法得到了OT情感的概率分布及其置信度得分:
的原始跨度表示的集合Ga,利用opinion解码器利用注意机制识别所有OTs及其对每个特定有效aspect词的情感。同样,我们通过以下方法得到了OT情感的概率分布及其置信度得分:
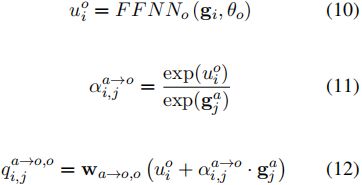
![]()
其中![]() 代表opinion解码器的FFNN,θo是FFNN的参数,
代表opinion解码器的FFNN,θo是FFNN的参数,![]() 是一个可训练的权重向量,
是一个可训练的权重向量,![]() 是情感极性的数量。此外,我们将aspect-to-opinion方向的损失定义为:
是情感极性的数量。此外,我们将aspect-to-opinion方向的损失定义为:
![]()
其中,![]() 和
和![]() 分别是给定特定有效的aspect词和opinion情感的基本真实标签
分别是给定特定有效的aspect词和opinion情感的基本真实标签
3.4.2 Opinion-to-aspect Direction
从opinion到aspect的方向(图2中的红色箭头和模块),首先部署opinion解码器,从句子中提取所有的opinion词和它们的情感。为了最小化模型参数的数量,在aspect对opinion和opinion对aspect的方向上的opinion解码器共享FFNN特征,如式(10)所述。OTs情感的概率分布和置信度得分可以得到:
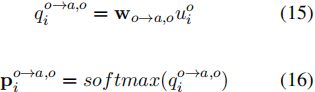
其中![]() 是一个可训练的权重向量。
是一个可训练的权重向量。
给定一个集合Go,如果所有有效的opinion词![]() 的原始跨度表示,aspect解码器被部署来识别每个特定有效的opinion词的aspect词及其情感。注意,在opinion-to-aspect方向的aspect解码器也与在aspect-to-opinion方向的aspect解码器共享公式(7)中描述的相同的FFNN特征。aspect词的日志及其对opinion-to-aspect方向的置信度得分可通过以下方法获得:
的原始跨度表示,aspect解码器被部署来识别每个特定有效的opinion词的aspect词及其情感。注意,在opinion-to-aspect方向的aspect解码器也与在aspect-to-opinion方向的aspect解码器共享公式(7)中描述的相同的FFNN特征。aspect词的日志及其对opinion-to-aspect方向的置信度得分可通过以下方法获得:
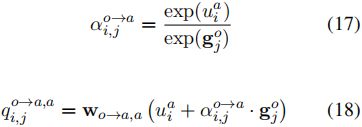
![]()
其中![]() 是一个可训练的权重向量。
是一个可训练的权重向量。
最后,opinion间方向的损失定义为:
![]()
其中![]() 和
和![]() 是真实标签。然后,我们结合上述损失函数,形成整个模型的损失目标:
是真实标签。然后,我们结合上述损失函数,形成整个模型的损失目标:
![]()
3.5 推理
与token级方法中的三元组的互斥性相比,span级模型不能保证任何两个三元组之间不存在冲突。因此,我们提出了一种推理策略来消除推理过程中潜在的冲突三元组。如算法1中所示,我们首先通过取并集T(第1行)将两个方向的提取结果结合起来。然后,对于整个三元组集T中在 aspect a和opinion o都有重复的三元组(第5行),通过丢弃置信分数较低的三元组(第6-9行),可以消除相互冲突的结果。请注意,在确定两个三元组是否相互冲突的条件下(第5行),确定联合集是否为空是在位置索引上执行的,而不是在标记上执行的。

4 实验
4.1 数据集
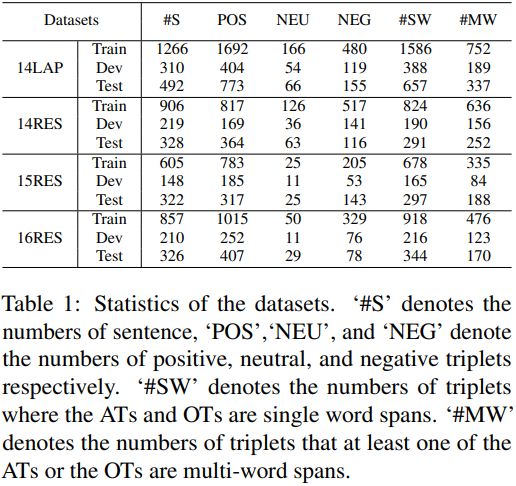
为了验证我们的网络的有效性,我们在四个基准数据集上进行了实验,表1列出了这些数据集的统计数据。
4.2 实验设置
在我们的实验中,我们采用了bert-base-cased,其中包含110M的参数。在训练过程中,我们使用AdamW来优化模型参数。BERT的微调率和其他模型的学习率分别设置为1e-5和1e-4。同时,批量大小设置为16,dropout设置为0.1。生成的跨度的最大长度设置为8。我们在NVIDIA Tesla V100 GPU上总共训练了120个epoch。
4.3 评价
为了综合评价不同方法的性能,我们采用精确度、召回率、F1值评分作为评价指标。当且仅当预测的跨度与真实跨度完全匹配时,提取的aspect词和OTs被认为是正确的。在实验中,我们的测试结果为模型在验证集上达到最佳性能的模型的结果。
4.4 Baselines
为了证明我们的网络的有效性,我们将我们的方法与以下基线进行了比较:
- Peng-two-stage(Peng et al.,2020)是一个两阶段的pipline模型。在第一阶段同时提取aspect-情感对和opinion词。在第二阶段,通过关系分类器将提取结果配对成三元组。
- JET(Xu et al.,2020)是一种端到端模型,它提出了一种新的位置感知标记方案来联合提取三元组。它还设计了因子分解的特征表示,以有效地捕获三元组因子之间的交互作用。
- GTS(Wu et al.,2020)是一个端到端模型,它将ASTE定义为一个统一的网格标记任务。首先提取每个标记的情感特征,然后基于这些标记级特征得到标记对的初始预测概率。它还设计了一种推理策略,利用不同opinion因素之间的潜在相互指示,并进行最终预测。
- Dual-MRC(Mao et al.,2021)是一个由两个机器阅读理解组成的联合训练模型。MRC的一个用于aspect提取,另一个用于面向aspect的opinion提取和情感分类。
- B-MRC (Chen et al., 2021)将ASTE任务形式化为多回合机器阅读理解任务,并提出了三种类型的查询,分别提取目标、观点和aspect-opinion对的情感极性。
- Span-ASTE(Xu et al.,2021)考虑了一个句子中所有可能的跨度,并在预测它们的情感关系时建立了aspect术语和观点术语的整个跨度之间的交互作用。他们还提出了一种双通道跨度剪枝策略,以缓解由跨度枚举引起的高计算代价。
4.5 主要结果
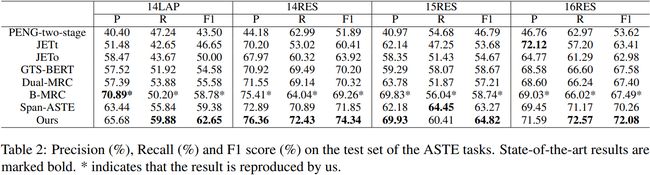
表2报告了我们的框架和基线模型的结果。根据研究结果,我们的框架在所有数据集上都取得了最先进的性能。
- 具体来说,我们的框架在ASTE上平均超过了2.3%的f1分。这一结果表明,我们的框架可以利用双向解码,有效地区分跨度表示。
- 虽然部分召回率略低于Span-ASTE,但在大多数数据集中,精度的提高明显优于之前的基线,这表明我们的网络有更高的预测精度。
- 值得注意的是,BMRC和Dual-MRC的性能优于JET和PENG-两阶段。这可能是因为BMRC和Dual-MRC将ASTE任务形式化为一个多回合的机器阅读理解任务,并从询问模型问题中获益。
- 与这些方法不同,SpanASTE和我们的方法都利用span级交互来处理ASTE任务,并避免级联错误。此外,我们的模型优于Span-ASTE,因为我们的方法从aspect到opinion和opinion到aspect的方向识别三元组,而不是匹配每个aspect的跨度和opinion跨度。
- 此外,我们的网络还利用相似的跨分离损失和推理策略,克服了span间互斥的缺点。
4.6 消融研究
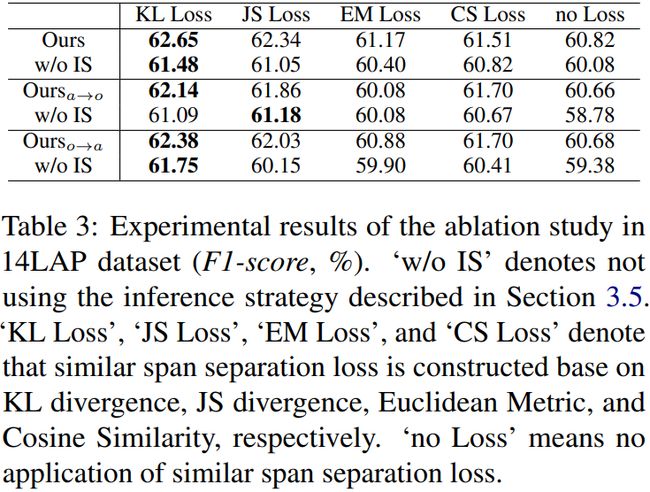
为了验证我们的网络中显著改进的起源,我们在14个LAP数据集上进行了消融实验。如表3所示,我们的双向模型比单向模型产生更好的结果,这清楚地说明了协作在两个方向上对解码跨度表示的优越性。从opinion到aspect的推理结果优于另一个方向,这可能是由于在14个LAP数据集中提取opinion的简单性。
此外,该推理策略对模型的性能也有所提高。然而,推理策略带来的改进并不显著,因为在多标记结果中往往存在冲突的三元组,并且在14个LAP数据集中只有一小部分联体包含多标记术语。我们相信推理策略的效果将在多标记三元组的数据集中更加明显。
此外,为了证明我们提出的基于KL散度的相似跨度分离损失的有效性,我们进一步设计了基于JS散度、欧氏距离和余弦相似度的相似距离分离损失。实验结果表明,这些损失函数对我们的网络都有增强作用,其中基于KL散度的分离损耗效果最好。请注意,可以使用许多相似性度量来分离相似的跨度,其中可能有一些更好的度量,可以给模型带来更多的改进。
4.7 实体长度的影响
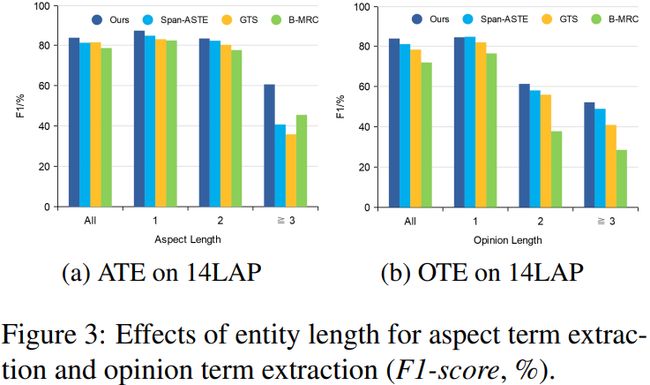
为了研究不同方法在不同实体长度的ATE和OTE上的性能,我们报告了我们的框架、SpanASTE、GTS和B-MRC在不同实体长度的提取任务上的F1值。结果如图3所示。随着实体长度的增加,我们的框架和其他模型之间的性能差距变得更加明显。由于我们的方法直接为每个实体建模span级特征,并减轻了span级特征之间没有互斥性的缺点,因此我们的方法不会随着实体长度的增加而受到很大的影响。事实上,对我们模型改进的大部分贡献来自于多token实体的性能。
4.8 多个三元组的影响
为了进一步验证我们的框架处理多个三元组的能力,我们比较了我们的网络和其他基线在句子中具有不同数量三元组的ASTE任务上的性能,结果如表4所示。
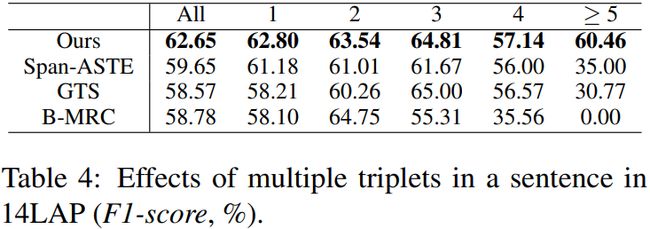
我们将句子分成14个LAP测试集为5个子类。每个子类分别包含包含1、2、3、4或≥5个三元组的句子。当从包含1或2个三元组的句子中提取三元组时,我们的框架的性能可以与其他模型竞争。然而,当三联体数量增加时,SpanASTE、GTS和B-MRC的性能显著下降,而我们的网络的性能保持稳定,甚至略有提高。这些实验结果证明了我们的框架在处理一个句子中的多个三元组aspect的效率和稳定性。
5 结论
在这项工作中,我们提出了一个span级双向网络的ASTE任务。这个span级模型有aspect到opinion和opinion到aspect的两个不同的方向。双向解码可以确保aspect词或opinion词都能触发aspect情感三元组,这更符合人类的感知。由于不能保证跨度之间的互斥性的缺点,我们采用相似的跨度分离损失来指导模型区分相似的跨度。我们进一步设计了一个推理策略来消除特定于跨级模型的相互冲突的三元组结果。实验结果表明,我们的网络的性能显著优于比较的基线,并取得了最先进的性能。