Java-多线程-深入理解ConcurrentHashMap
目录
- 什么是ConcurrentHashMap?
- 为什么有ConcurrentHashMap?
- 和HashMap区别
-
- 示例代码对比
- JDK7和JDK8中ConcurrentHashMap整体架构的区别
-
- JDK7中
- JDK8中
- ConcurrentHashMap的基本功能
- 在性能方面的优化
- 使用到的技术-CAS
-
- 概念说明
- 比较并交换的过程如下:
- 举例说明
- 底层原理
- 代码演示
- 总结

什么是ConcurrentHashMap?
ConcurrentHashMap(Concurrent:并存的,同时发生的;)
ConcurrentHashMap是Java中的一个线程安全的哈希表实现,它可以在多线程环境下高效地进行并发操作。
为什么有ConcurrentHashMap?
HashMap线程不安全,在多线程操作下可能会导致数据错乱
和HashMap区别

示例代码对比
使用HashMap和ConcurrentHashMap分别实现以下需求。
用30个线程向实例化出的map中插入key,value。每一次插入后,把map打印出来(for循环中sout)
key为for循环中的i值
value:使用UUID
public class HashMapUnsafeTest {
public static void main(String[] args) throws InterruptedException {
//演示HashMap
Map<String, String> map = new HashMap<>();
for (int i = 0; i < 30; i++) {
String key = String.valueOf(i);
new Thread(() -> {
//向集合添加内容
map.put(key, UUID.randomUUID().toString().substring(0, 8));
//从集合中获取内容
System.out.println(map);
}, "").start();
}
}
}
public class ConcurrentHashMapSafe {
public static void main(String[] args) throws InterruptedException {
//演示ConcurrentHashMap
Map<String, String> map = new ConcurrentHashMap<>();
for (int i = 0; i < 30; i++) {
String key = String.valueOf(i);
new Thread(() -> {
//向集合添加内容
map.put(key, UUID.randomUUID().toString().substring(0, 8));
//从集合中获取内容
System.out.println(map);
}, "").start();
}
}
}
多个线程同时对同一个集合进行增删操作导致错误
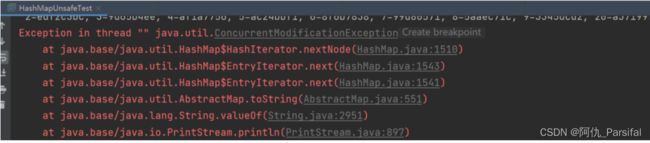
JDK7和JDK8中ConcurrentHashMap整体架构的区别
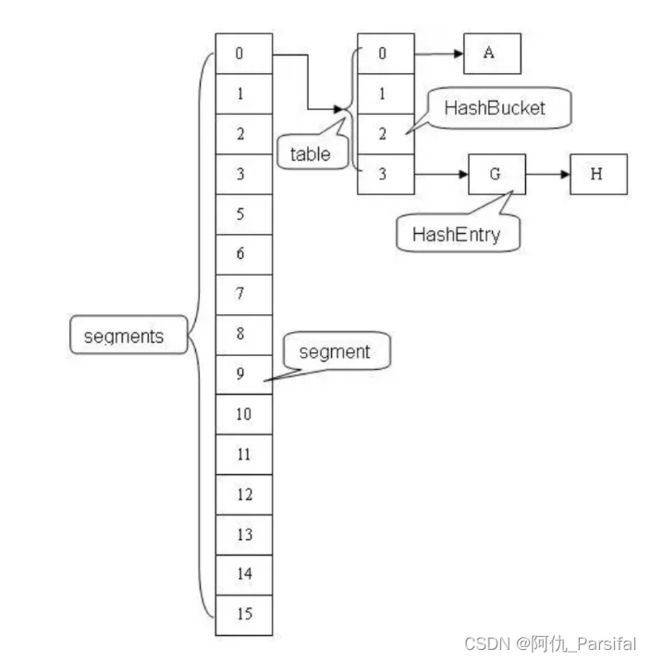
JDK7中
JDK8中
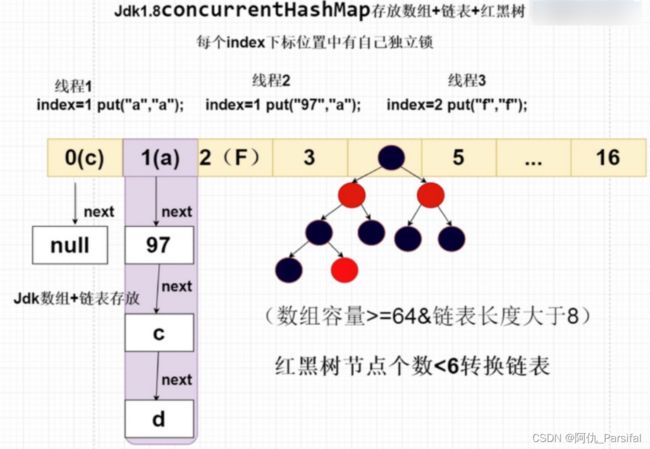
使用到的数据结构:数组、单向链表、红黑树
其中涉及到几个核心的参数
// 最大容量,2^30
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认长度
private static final int DEFAULT_CAPACITY = 16;
//遗留问题:为什么树化条件是8而取消树化条件却是6呢?
// 链表树化条件-是根据线程竞争情况和红黑树的操作成本进行设计的。
static final int TREEIFY_THRESHOLD = 8;
// 取消树化条件-为了避免过度的树化,防止内存占用过高。
static final int UNTREEIFY_THRESHOLD = 6; //链表结构中,每个节点只需要存储指向下一个节点的指针,而不需要存储节点的值。因此,链表只需要存储节点的引用,占用较少的内存空间。树结构中每个节点需要存储节点的值以及指向子节点的指针。
核心为Hash表,存在Hash冲突问题
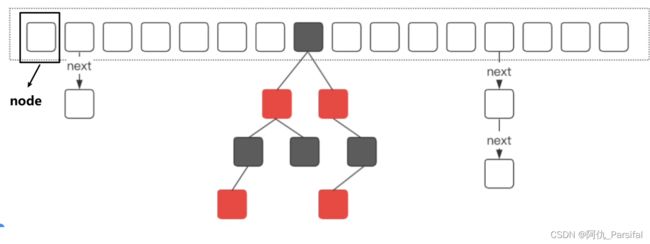
使用链式存储方式解决冲突,冲突较多时,导致链表过长,查询效率较低,在JDK1.8中引入红黑树机制;
当数组长度大于64,且链表长度大于等于8时,单项链表转为红黑树
当链表长度小于6时,红黑树会退化为单向链表
ConcurrentHashMap的基本功能
本质上是一个HashMap,功能和HashMap是一样的
但ConcurrentHashMap在HashMap基础上提供了并发安全的实现,主要通过对node节点加锁实现,来保证对数据更新的安全性
锁粒度变小
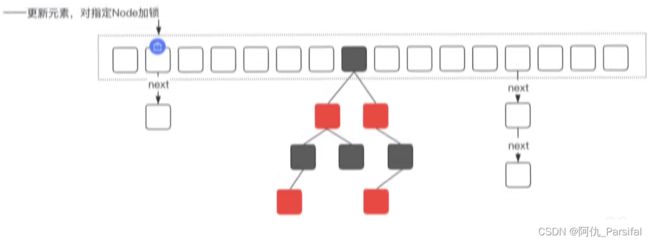
在性能方面的优化
在JDK1.8中锁的粒度是数组中的某一个节点,在JDK1.7中锁定的是一个Segment,锁的范围更大
保证线程安全机制:
JDK7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。
JDK8采用CAS(读)+Synchronized(写)保证线程安全。
锁的粒度:原来是对需要进行数据操作的Segment加锁,JDK8调整为对每个数组元素加锁(Node)。
链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
使用到的技术-CAS
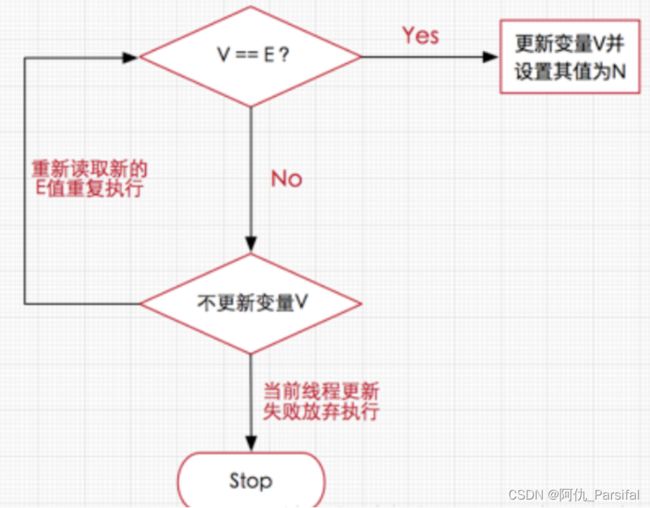
概念说明
CAS的全称是:比较并交换(Compare And Swap)。在CAS中,有这样三个值:
V:要更新的变量(var)
E:预期值(expected)
N:新值(new)
比较并交换的过程如下:
判断V是否等于E,如果等于,将V的值设置为N;如果不等,说明已经有其它线程更新了V,则当前线程放弃更新,什么都不做。
举例说明
如果有一个多个线程共享的变量i原本等于5,我现在在线程A中,想把它设置为新的值6;
我们使用CAS来做这个事情;
首先我们用i去与5对比,发现它等于5,说明没有被其它线程改过,那我就把它设置为新的值6,此次CAS成功,i的值被设置成了6;
如果不等于5,说明i被其它线程改过了(比如现在i的值为2),那么我就什么也不做,此次CAS失败,i的值仍然为2。
底层原理
unsafe类——以下是类中涉及到的三个方法用来实现CAS效果的,这三个方法都是由native进行修饰的。具体的实现是由C++写的。

代码演示
没有使用CAS的代码
package com.example.threadpool.CAS;
public class NoCASDemo {
private static int counter = 0;
public static void main(String[] args) throws InterruptedException {
//线程一
Thread thread1= new Thread(() -> {
for (int i=0; i<10000;i++){
counter++;
}
});
//线程二
Thread thread2= new Thread(() -> {
for (int i=0; i<10000;i++){
counter++;
}
});
//执行线程
thread1.start();
thread2.start();
//等待执行完线程1和2
thread1.join();
thread2.join();
System.out.println("查看counter的总数"+counter);
}
}
使用CAS的代码
package com.example.threadpool.CAS;
import java.util.concurrent.atomic.AtomicInteger;
public class CASDemo {
private static AtomicInteger counter = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
//线程一
Thread thread1= new Thread(() -> {
for (int i=0; i<10000;i++){
increment();
}
});
//线程二
Thread thread2= new Thread(() -> {
for (int i=0; i<10000;i++){
increment();
}
});
//执行线程
thread1.start();
thread2.start();
//等待执行完线程1和2
thread1.join();
thread2.join();
System.out.println("查看counter的总数"+counter.get());
}
public static void increment() {
int currentValue;
int newValue;
do {
//获取counter对象的value值
currentValue = counter.get();
//将counter对象的value值加1
newValue = currentValue + 1;
} while (!counter.compareAndSet(currentValue, newValue));
}
}
总结
总的来说,ConcurrentHashMap是Java中线程安全的哈希表实现,它通过使用锁分段技术来提供高效的并发性能。相比于Hashtable,ConcurrentHashMap在多线程环境下能够更好地支持高并发读写操作。
使用ConcurrentHashMap可以在多线程环境下安全地进行数据操作,而无需手动加锁。它通过将整个数据结构分成多个段来实现并发性能的提升,不同的线程可以同时访问不同的段,从而减少了线程之间的竞争。
ConcurrentHashMap的设计考虑了线程安全和性能的平衡。它提供了一些有用的方法,如putIfAbsent()、replace()等,可以方便地进行原子性的操作。此外,ConcurrentHashMap还支持遍历操作,可以通过迭代器安全地遍历其中的元素。
需要注意的是,虽然ConcurrentHashMap是线程安全的,但并不保证对于单个操作的原子性。如果需要进行复合操作,仍然需要额外的同步措施。
总的来说,ConcurrentHashMap是一个强大的线程安全的哈希表实现,适用于多线程环境下的高并发读写操作。它提供了高效的并发性能,可以提升系统的吞吐量和响应速度。