MySQL及SQL语句(1)
MySQL及SQL语句(1)
文章目录
-
-
- MySQL及SQL语句(1)
-
- 一、数据库的基本概念
-
- 数据库的特点
- 常见的数据库软件
- MySQL的前世今生
- 二、MySQL数据库软件
-
- 2.1 安装
- 2.2 卸载
- 2.3 配置
-
- MySQL服务启动
- MySQL登录
- MySQL退出
- MySQL目录结构
- 三、SQL
-
- 3.1 什么是SQL
- 3.2 SQL通用语法
- 3.3 SQL分类
-
- DDL
- DML
- DQL
- DCL
- 3.4 DDL:操作数组库、表
-
- 3.4.1 操作数据库 :CRUD
- 3.4.2 操作表:CRUD
- 3.5 DML:增删改表中数据
-
- 添加数据
- **删除数据**
- **修改数据**
- 3.6 DQL:查询表中的记录
-
- 3.6.1 语法
- 3.6.2 基础查询
- 3.6.3 条件查询
- 3.6.4 排序查询
- 3.6.5 聚合函数
- 3.6.6 分组查询
- 3.6.7 分页查询
-
一、数据库的基本概念
数据库(DataBase),简称DB。用于存储和管理数据的仓库。
数据库的特点
- 持久化存储数据,本质上就是一个文件系统。
- 方便存储和管理数据
- 使用了统一的方式操作数据库(SQL)
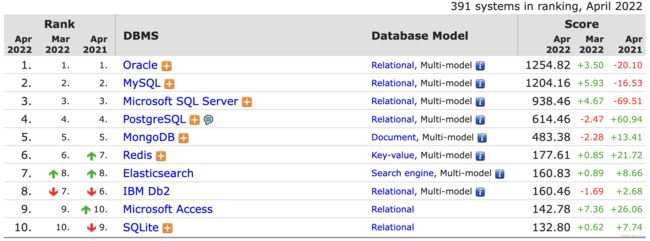
常见的数据库软件
https://db-engines.com/en/ranking 可查询实时排名情况
MySQL的前世今生
2008 年美国 Sun 公司花费 10 亿美元收购 MySQL,一年后 Oracle 公司又花费 60 亿美元收购了 Sun 公司,从此 Sun 公司的服务器、操作系统、MySQL 等产品线全部归属 Oracle 公司。
拉力·艾立森奉行的经营哲学是“竞争不过它,我就买了它”。竞争不过,说明竞争对手的产品更具优势,所以收购它,从而变成自己的优势。几十年来,Oracle 从一家小型数据库公司变成今天覆盖硬件、平台软件、数据库、中间件、应用软件各个层次产品线的 IT 巨无霸,靠的就是美国的良好环境和总裁奉行的收购策略。
MySQL 数据库占据中小型数据库应用市场的半壁江山,在这块市场,Oracle 数据库明显占下风,巅峰时世界上超过 70% 的网站后台都采用 MySQL 数据库。但是自从被 Oracle 公司收购后,MySQL 发展明显趋缓,是继续开源还是闭源,Oracle 公司一直没下定论。于是 MySQL 的原班人马陆续离开 Oracle 公司,另立炉灶,推出了 MariaDB 开源数据库。
MariaDB 继承了 MySQL 小巧精悍、简洁高效、稳定可靠的特征,并与 MySQL 保持兼容。时至今日,已有 Google、Facebook 等知名企业把应用从 MySQL 切换到了 MariaDB 上,各种 Linux 发行版的操作系统默认数据库都开始采用 MariaDB;而 Apple 公司反应更快,当 Oracle 公司收购 Sun 公司时,就切换到了 PostgreSQL 数据库。
截至 2014 年年末的数据库综合排名,MySQL 继续位居第二名,但是其表现出来的颓势较明显,而 MariaDB 却具备强劲的生命力。
MariaDB 是一个开源的免费的关系数据库,截至发稿前的最新版本是 10.0.15,安装包可从 https://downloads.mariadb.org 网站下载。整个安装包大约 200MB,几乎能在所有的操作系统上安装和运行,与 Oracle 数据库、SQL Server、DB2 等商业数据库动辄好几张光盘相比,算是短小精悍了。
二、MySQL数据库软件
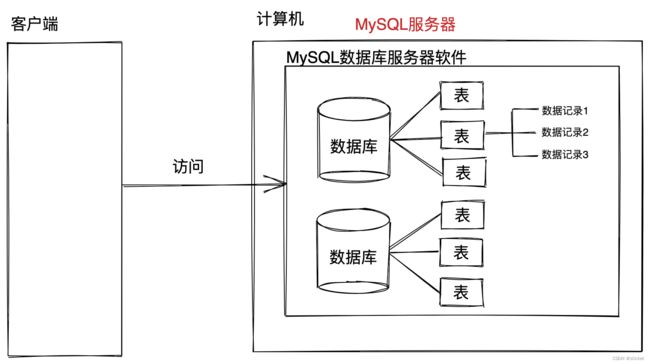
以下安装卸载配置均针对windows版本:
2.1 安装
比较简单,参考网上的各种安装教程
2.2 卸载
- 去mysql的安装目录找到my.ini文件
- 复制 datadir = “C:/ProgreamData/MySQL/MySQL Server 5.5/Data/”
- 在控制面板程序中卸载MySQL
- 删除C:/ProgramData目录下的MySQL文件夹
2.3 配置
MySQL服务启动
-
手动打开windows的服务管理界面
-
cmd–> services.msc 快捷打开服务的窗口
-
使用管理员权限打开cmd
net start mysql: 启动mysql的服务net stop mysql: 关闭mysql服务
MySQL登录
mysql -uroot -p密码mysql -hip -uroot -p连接目标的密码mysql --host=ip --user=root --password=连接目标的密码
MySQL退出
exitquit
MySQL目录结构
-
MySQL安装目录
配置文件
my.ini -
MySQL数据目录
几个概念:数据库 – >文件夹,表–>文件,数据–>文件中的数据
三、SQL
3.1 什么是SQL
Structured Query Language: 结构化查询语言
其实就是定义了操作所有关系型数据库的规则。每一种数据库操作的方式存在不一样的地方,称为“方言”。
3.2 SQL通用语法
SQL语句可以单行或多行书写,以分号结尾。可使用空格和缩进来增强语句的可读性。MySQL 数据库的SQL语句不区分大小写,关键字建议使用大写。
SQL语句中的3种注释:
- 单行注释:-- 注释内容 或 # 注释内容(mysql特有)
- 多行注释:/* 注释 */
3.3 SQL分类
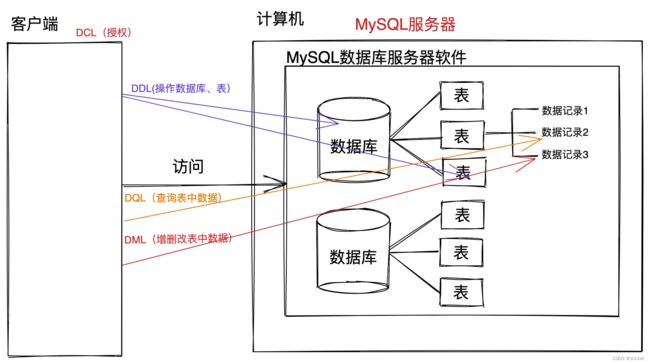
DDL
Data Definition Language 数据定义语言,用来定义数据库对象:数据库,表,列等。关键字:create,drop,alter等
DML
Data Manipulation Language 数据操作语言,用来对数据库中表的数据进行增删改。关键字:insert,delete,update等
DQL
Data Query Language 数据库查询语言,用来查询数据库中表的记录(数据)。关键字:select,where等。
DCL
Data Control Language 数据库控制语言(了解),用来定义数据库的访问权限和安全级别,及创建用户。关键字:GRANT,REVOKE等。
3.4 DDL:操作数组库、表
3.4.1 操作数据库 :CRUD
C(Create):创建
-
创建数据库:
create database 数据库名称; -
创建数据库,判断不存在,再创建:
create database if not exists 数据库名称; -
创建数据库,并指定字符集:
create database 数据库名称 character set 字符集名;
练习:创建db4数据库,判断是否存在,并指定字符集为gbk
create database if not exists db4 character set gbk;
R(Retrieve):查询
-
查询所有数据库的名称:
show databases; -
查询某个数据库的字符集:查询某个数据库的创建语句
show create database 数据库名称;
U(Update):修改
- 修改数据库的字符集:
alter database 数据库名称 character set 字符集名称;
D(Delete):删除
-
删除数据库:
drop database 数据库名称; -
判断数据库存在,存在再删除:
drop database if exists 数据库名称;
使用数据库
-
查询当前正在使用的数据库名称:
select database(); -
使用数据库:
use 数据库名称;
3.4.2 操作表:CRUD
C:创建
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
... ,
列名n 数据类型n
);
注意:最后一列,不需要加逗号,否则会出现语法错误
数据库数据类型:
-
int:整型类型 -
double:小数类型 -
date: 日期,只包含年月日,yyyy-MM-dd -
datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss -
timestamp:时间戳类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss 。如果不给这个字段赋值,或赋值为null, 则默认使用当前的系统时间,来自动赋值。 -
varchar:字符串,name varchar(20)–姓名最大20个字符
练习:创建学生表
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);
复制表:create table 表名 like 被复制的表名;
R(Retrieve):查询
-
查询某个数据库中所有的表的名称:
show tables; -
查询表结构:
desc 表名;
U(Update):修改
-
修改表名
alter table 表名 rename to 新的表名; -
修改表的字符集
alter table 表名 character set 字符集名称; -
添加列
alter table 表名 add 列名 数据类型; -
修改列名称/类型
alter table 表名 change 列名 新列名 新数据类型;alter table 表名 modify 列名 新数据类型; -
删除列
alter table 表名 drop 列名;
D(Delete):删除
-
drop table 表名; -
drop table if exists 表名;
3.5 DML:增删改表中数据
添加数据
语法:insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
注意:
-
列名和值要一一对应。
-
如果表名后,不定义列名,则默认给所有列添加值
insert into 表名 values(值1,值2,...值n); -
除了数字类型,其他类型需要引用引号(单双都可以)引起来
删除数据
语法:delete from 表名 [where 条件]
注意:
- 如果不加条件,则删除表中所有记录。
- 如果要删除所有记录,有以下两种方法:
delete from 表名;– 不推荐使用。有多少条记录就会执行多少次删除操作TRUNCATE TABLE 表名;– 推荐使用,效率更高,先删除表,然后再创建一张一样的表。
修改数据
语法:update 表名 set 列名1 = 值1, 列名2 = 值2, ... [where 条件];
注意:如果不添加任何条件,则会将表中所有记录全部修改。
3.6 DQL:查询表中的记录
selcet * from 表名;
3.6.1 语法
select 字段列表 from 表名列表 where 条件列表 group by 分组字段 having 分组之后的条件 order by 排序 limit 分页限定
3.6.2 基础查询
- 多个字段的查询:
select 字段名1, 字段名2, ... from 表名;注意:如果查询所有字段,则可以使用*来代替字段列表。 - 去除重复:
select distinct 字段列表 from 表名; - 计算列:
select 字段1,字段2,字段1+字段2 from 表名;- 一般可以使用四则运算计算一些列的值。(一般只会进行数值型的计算)
ifnull(表达式1, 表达式2):null参与的运算, 计算结果都为null。表达式1:哪个字段需要判断是否为null,表达式2:如果该字段为null 后的替换值。
- 起别名:
as–as也可以省略,具体使用:select 字段1,字段2,字段3+ IFNULL(字段4,0) as 总分 from student;
CREATE TABLE student (
id INT, -- 编号
NAME VARCHAR(20), -- 姓名
age INT, -- 年龄
sex VARCHAR(5), -- 性别
address VARCHAR(100), -- 地址
math INT, -- 数学
english INT -- 英语
);
INSERT INTO student(
id,NAME,age,sex,address,math,english) VALUES
(1,'马云',55,'男','杭州',66,78),
(2,'马化腾',45,'女','深圳',98,87),
(3,'赵晓',20,'女','盐城',3,100),
(4,'刘德华',57,'男','香港',99,99),
(5,'德玛西亚',18,'男','香港',56,65),
(6,'赵雷',32,'男','南京',0,0),
(7,'李志',40,'男','南京',88,null),
(8,'许巍',51,'男','杭州',98,89);
-- 查询,一般情况下不允许这么查,可读性差
SELECT * FROM student;
-- 查询 姓名 和 年龄 (常用的查询语句,针对表比较复杂的时候)
SELECT
NAME, -- 姓名
age -- 年龄
from
student; -- 学生表
-- 查询 地址 发现有重复的
SELECT address FROM student;
-- 去除重复的结果集
SELECT DISTINCT address FROM student;
SELECT DISTINCT NAME, address FROM student;
-- 计算 math 和 english 分数之和
SELECT `name`,math,english,math+english FROM student;
-- 如果有null参与的运算结果都为null
SELECT `name`,math,english,math+IFNULL(english,0) FROM student;
-- 起别名
SELECT `name`,math,english,math+IFNULL(english,0) as 总分 FROM student;
SELECT `name`,math 数学,english 英语,math+IFNULL(english,0) as 总分 FROM student;
3.6.3 条件查询
where子句后跟条件及一些运算符的使用
SELECT * FROM student;
-- 查询年龄大于20岁
SELECT * FROM student WHERE age > 20;
SELECT * FROM student WHERE age >= 20;
-- 查询年龄等于20岁
SELECT * FROM student WHERE age = 20;
-- 查询年龄不等于20岁
SELECT * FROM student WHERE age != 20;
SELECT * FROM student WHERE age <> 20;
-- 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <= 30;
SELECT * FROM student WHERE age >= 20 AND age <= 30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
-- 查询年龄22岁,18岁,55岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 55;
SELECT * FROM student WHERE age IN (22,18,55);
-- 查询英语成绩为null
SELECT * FROM student WHERE english = NULl; -- 不对的,null值不能使用 =(!=)进行判断
SELECT * FROM student WHERE english IS NULL;
-- 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;
模糊查询–LIKE运算符:两个占位符
- _:单个任意字符
- %:多个任意字符
-- 查询姓马的有哪些
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名中第二字为化的人
SELECT * FROM student WHERE NAME LIKE '_化%';
-- 查询姓名是三个字的人
SELECT * FROM student WHERE NAME LIKE '___';
-- 查询名字中含马的人
SELECT * FROM student WHERE NAME LIKE '%马%';
3.6.4 排序查询
语法:order by 字句
排序方式:ASC—升序,默认;DESC—降序。
注意:如果有过个排序条件,则当前面的条件值一样时才会判断第二条件。
-- 按照数学成绩排序
SELECT * FROM student ORDER BY math;
SELECT * FROM student ORDER BY math ASC;
SELECT * FROM student ORDER BY math DESC;
-- 按照数学成绩排序,数学成绩一样的按英语成绩排
SELECT * FROM student ORDER BY math,english DESC;
3.6.5 聚合函数
聚合函数:将一列数据作为一个整体,进行纵向的计算。
计算方式:count–计算个数(一般选择非空的列,即主键),max-- 计算最大值,min–计算最小值,sum–计算和,avg-- 计算平均值
注意:聚合函数的计算,排除null值。
-- 计算个数,关于NULL的处理
SELECT COUNT(english) FROM student;
SELECT COUNT(id) FROM student;
SELECT COUNT(IFNULL(english,0)) FROM student;
-- 列的最大值
SELECT MAX(math) FROM student;
-- 最小值
SELECT MIN(math) FROM student;
-- 求和
SELECT SUM(math) FROM student;
-- 平均值
SELECT AVG(math) FROM student;
3.6.6 分组查询
语法:group by 分组字段;
注意:
- 分组之后查询的字段:分组字段、聚合函数
- where和having的区别:
- where在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来。
- where后不可以跟聚合函数,having可以进行聚合函数的判断。
-- 按照性别分组,分别查询男女同学的平均分
SELECT sex,AVG(math) FROM student GROUP BY sex;
-- 按照性别分组,分别查询男女同学的平均分,人数
SELECT sex,AVG(math),COUNT(id) FROM student GROUP BY sex;
-- 按照性别分组,分别查询男女同学的平均分,人数 要求:低于70分的人,不参与分组
SELECT sex,AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;
-- 按照性别分组,分别查询男女同学的平均分,人数 要求:低于70分的人,不参与分组;分组之后,人数大于2个人
SELECT sex,AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id)>2;
3.6.7 分页查询
语法:limit 开始是的索引,每页查询的条数
公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
注意:limit 是一个MySQL的“方言”,用来完成分页操作,而其他类型的关系型数据库也有自己的分页方言。
-- 分页操作,一页3条,查询第一页
SELECT * FROM student LIMIT 0,3;
SELECT * FROM student LIMIT 3,3; -- 第2页
SELECT * FROM student LIMIT 6,3; -- 第3页