高性能内存队列-Disruptor
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题。基于Disruptor开发的系统单线程能支撑每秒600万订单。
2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
martin fowler的的大作:原文、参考译文
ps:恕我浅薄,直接看大神的文章,说实话,是有些看不明白的,包括有些观点确实还不能消化,因为高度不够,看不清其背后的逻辑本质。
qcon演讲原文在qcon上没找到,不过qcon上倒是有蛮多将Disruptor文章的,比如disruptor 高性能队列最佳选择
为什么需要高性能队列
jdk提供的队列:
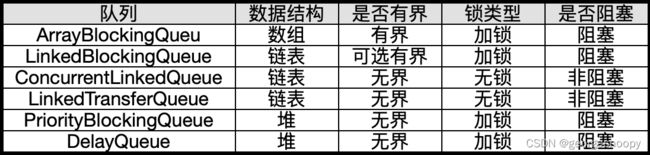
在稳定性要求较高的场景中,为了防止生产者速度过快,导致内存溢出,最终会导致OOM使得jvm重启,所以在实际生产环境,都会选用有界队列。所以,在jdk提供的队列中,其实也就是ArrayBlockingQueue和linkedBlockIngQueue了。
但是这两个队列都是基于悲观锁来实现的,并且没有处理伪共享的问题,导致在性能要求非常高的场景中,不能满足要求。
CPU高速缓存共享与伪共享
计算机的基本结构

- 主存是全部插槽上的所有cpu共享的。也是不同cpu之间要交换数据的通路,即一个数据被一个cpu修改后,另外一个cpu要能看到最新的修改,那么就必须先写入主存,然后从主存中读取,才能看到最新的变化。
- L3缓存,是一个物理cpu独享的,即每个cpu会有自己的L3,但是被一个cpu上的多个内核共享。
- L2和L1是每个cpu内核独享的。
越靠近cpu的缓存,速度就越快,但是成本也就更高,所以往往受限于成本,容量也就越小。
不同级别存储的大约耗时:
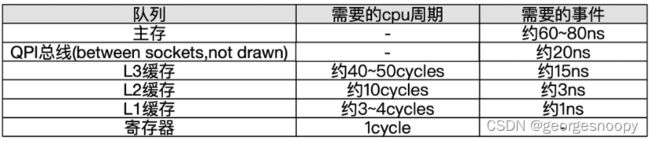
当CPU在执行运算、需要数据的时候,首先回去L1查找所需的数据、查不到再去L2查、然后是L3,如果L3中还是没有,那么就只能去主存中加载,走得越远,运算耗费的时间就越长。所以在一些追求极致性能的场景中,会让cpu尽量的使用到高速缓存,减少去主存中加载数据的频率。
另外,线程之间共享一份数据的时候,需要一个线程把数据写回主存,而另一个线程访问主存中相应的数据。所以说,当一个cpu改变了一个数据的时候,会通过总线发送事件,其他cpu监听到后,会将告诉缓存中缓存的数据标记为脏数据,当再次需要这个数据的时候,就只能去主存去加载,避免自己是基于自己过期的高速缓存数据在作运算
缓存行
计算机里存储数据的基本单位是字节,内存编址也是按照字节来进行编址的,但是实际使用的时候,使用的单位并不一定就真的是一个字节一个字节的使用的,如果是这样,应用层会非常难受,比如编程语言中的数据类型,其实就是封装了定量字节的内存来存储数据,比如int占4个字节,其实就是底层封装了,一次性读取4个字节,并且解析成一个数字,展现出来,这样程序员就不用费很大精力去管理内存了。
对于主存的分配管理上,都是连续分配的,而连续分配的内存中存储的信息往往是有一定的关联性的,这样的对于cpu来说,多次计算依赖主存中的数据,很大概率上就是一段连续内存中存储的数据。比如数组遍历,数组中所有元素是存储在一块连续内存中的,当cpu读取上个元素和遍历下个元素依赖的数据,其实就是连续的。这个其实就是局部性原理。
基于局部性原理,cpu在将数据从主存加载到高速缓存的时候,不是以字节为单位去加载数据的,而是以缓存行为单位去主存中加载数据,一个缓存行占64字节。也就是说,当cpu计算需要的数据不在高速缓存中时,会去主存中加载数据,除了会将需要的数据加载到高速缓存外,会将数据相邻的数据凑够64字节一次性加载到内存中。
伪共享
正是由于cpu从主存中加载数据是一次性加载64字节,那么加载的数据很有可能不是本次计算所需要的,如果这部分额外多加载的数据被其他cpu也加载到内存了,且发生了改变,写到了主存。那么当前cpu加载到高速缓存中的数据就成了脏数据了,当需要的时候就只能再次去主存中加载。那这部分额外加载进高速缓存的数据,不但没有带来好处,反而影响了性能。这种
比如:内存中有a到y的这么一堆long型数据。这个时候cpu1需要a这个数据,发现高速缓存中没有,就层层去主存中加载。然后cpu2需要f这个数据,发现自己的高速缓存没有,同样也层层去主存中加载。

但是由于每次每次加载是加载64字节,所以cpu1加载a的时候会将a相邻的其他56个字节也加载进去,即加载进去的是a到h这64字节。同样的cpu2加载f的时候,也加载了f到m这64字节。这个时候如果cpu在努力的计算中,使用完a后,下次计算还会使用到b到h的任何数据,那么就很方便了,直接从高速缓存中取,减少了内存加载,那么效率是很高的。但是如果cpu1在计算过程中,cpu2将f的值变更了,要写入到主存,那么就会导致cpu1加载进去的a到h全都失效,因为其中的f已经变化了,那么cpu1再次用到a或者b,即使用不到f,也不得不重新从内存中加载。那么因为这种共享反而导致了更加频繁的内存加载,影响性能。
在实际生产中,会出现伪共享导致性能的一个主要场景,就是将经常发生变更的数据和不太发生变更的数据分配在了连续的内存中存储。比如jdk的ArrayList中的记录数组大小的size字段和真正存储数据的数组,那么size是经常变更的,如果将size和底层数组一起加载进了高速缓存,只要其他cpu有添加删除数组元素,导致size变更,就会导致加载进高速缓存的整个缓存行失效。
对于队列ArrayBlockingQueue来说,它有三个经常变的数据putIndex、takeIndex、count,只要它们和底层储存数据的数组在同一个缓存行加载进高速缓存,就会出现伪共享而影响性能。
所以,解决伪共享的方式,就是用空间换时间,让那些会经常发生变化的独占一个缓存行,保证它不会和其他数据在同一个缓存行中加载进高速缓存。问题:为了保证一个long型变量独占缓存行,是需要填充多少字节,填充56个字节够了么?
高性能队列Disruptor
Disruptor高性能的原因:
-
引入环形的数组结构:数组元素不会被回收,避免频繁的 GC。
-
无锁的设计:采用 CAS 无锁方式,保证线程的安全性
-
属性填充:通过填充队头/队尾下标,来避免伪共享。
-
元素位置的定位:采用跟一致性哈希一样的方式,一个索引,进行自增
环形数组及元素定位
对于队列的实现,底层要么使用数组存储,要么使用链表存储。Jdk中大多队列是使用链表存储的,使用链表存储实现会简单很多,这对出队后,节点的重用要方便一些。如果使用数组实现,要么出队后就挪动剩下的元素,要么就利用下标来实现一个循环数组来存储数据。Disruptor使用了循环数组的方式,而且有个小变化就是下标都是一直增长的,然后需要获取具体下标元素的时候,就通过取余的方式来定位数组真实的下表(实际是用与运算来替代取余运算)

环形数组中元素共享问题
在jdk的数组实现队列中,当出队的时候,这个元素就不再复用了,当需要再次入队的时候,是直接完全new了一个新对象,放到了原来的坑位中。
但是Disruptor不是的,是直接复用原来对象,然后生产入队的时候,是给你一个回调,让你去改变原有对象的数据就好了。同样的消费者消费的时候,也是给你了这个对象的引用,

消费的时候,也是回调传入的元素对象的引用
这就需要特别注意了,消费者就只是从对象中读取数据,别去修改元素对象的数据,否则就成了消费者生产数据了。java中没有什么机制可以不让方法修改入参引用的属性,所以这里只能使用者注意了。
这种复用元素对象的好处就是,不用生产的时候实时分配内存,且减少了一定的gc,但问题就是使用起来稍微复杂点。这也可以看出Disruptor的设计上,是不放过任何一点性能提升的。
属性填充避免伪共享
Disruptor中的队头、队尾等这种可能会经常变化的,都是使用了Sequence来进行分装的,封装的目的主要干了几件事情:
- 填充避免伪共享
- 访问数据的时候,是通过Unsafe直接操作内存
- 生产者与生产者之间、生产者于消费者之间、消费者与消费者之间的协调。说白了他们之间的协调都是各自维护的下标大小之间的约束,所以Disruptor将这些关系统一封装到了Sequence中。
Sequence分为了两类:一类是用于表示生产者生产下标(队尾)。

另一类就是用于表示消费者消费进度的下标。ps:这个不能单纯的说是队尾,因为每个消费者是自己保存自己的消费进度的。
看下Sequence中是如何填充避免伪共享的:

这里的value其实就是实际使用的下标值。这里也就回答了上面的问题,为了让一个变量独占缓存行,需要填充多少个字节的问题。
Disruptor支持的消费模式
如何实现广播消费
所谓的广播消费就是,生产者向队列中发送一条消息后,所有注册上来的消费者,都将消费到这条消息。
一个通用的做法就是:每个消费者管理自己的消费进度offset。
- 每个注册到队列的消费者都各自维护一个自己的消费进度offset,相互不影响。这样一个消费者消费了某条消息,也只是改变自己的offset,不影响其他的。
- 队列上需要维护一个最慢消费者的消费offset。其作用是:
-
- 如果是有界队列,生产者生产的时候,将用它来判断,是否可复用这个位置生产元素了,如果说最慢的消费者都已经消费了这个坑位了,说明所有的消费者都已经消费了,那么就可以复用这个坑位了;
- 如果是有持久化能力的队列,那么将会用这个offset来对历史消息进行删除或者归档。当所有消费者都消费了该条消息的时候,其实就可以把这个消息给删除了(实际生产环境中,更多的是归档,即从队列中删除,放到hbase中)
-
Ps:这里说的最慢消费者的offset只是用来表达一个进度概念,用来判断是否所有消费者都消费了该条消息。实际实现的时候,就有非常多的方式了,比如最简单的计数法,也是ok的。
这种么个消费者各自管理自己的消费进度offset实现广播的方式,在队列框架中基本是个通用手段,比如Disruptor这种内存队列,kafka这种分布式消息队列都是这种方式。
如何实现点对点消费
Java的JMS标准,就是一个纯单播的协议,因为当一个消费者消费消息后,它会直接将这条消息从队列中删除,那么其他消费者就一定不会消费了。
但现在比较流行的消息框架,更多的是实现组播,保证一条消息,在一个分组内的所有消费者中,只会有一个消费者消费一次。
所以通用做法就是:对消费者进行分组,一个组内的所有消费者共用一个消费进度offset。
- Kafka的做法是,有消费者变更的时候,会竞争一次到底组内的哪个消费者消费,确定后就会一直是这个消费者消费消息,直到消费者有变化(有宕机的或者有新增的)。即将竞争这个共享的offset的时机放在了组内消费者变化的时候
- Disruptor的做法。在实际消费的时候,各个消费者一拥而上,谁抢到谁就消费。
有一点需要注意,Disruptor中实现消费者组的是WorkPool,一个WorkPool是一个消费者组。它里面还有个EventHandlerGroup,它是用来实现流水线消费的,不是消费者组
两个方式就比较明显了:kafka这种方式,其实一旦确定了,后面所有消息一直都是那一个消费者消费。而disruptor每个消息都可能是组内任何一个消费者消费。
单单从这个方面看,其实disruptor的方式更好,整体上看,负载起码是均匀的。
但是kafka为不这么做呢?原因就是成本,disruptor是个内存队列,offset也是维护在内存里的,所谓的争抢,无非就是CAS。但是kafka不一样,kafka是一个分布式的消息组件,对于这种争抢就不能是高效的CAS,甚至效率都赶不上进程内的悲观锁,它需要一个分布式协调算法来争抢,比如Raft、Paxos等
如何实现pipeline的消费
所谓的流水线消费,就是当consumerD消费一条消息1的时候,要求消费者consumerA、consumerB、consumerC都已经消费了消息1,这个时候consumerD才能消费消费者1。
不太清楚kafka有这种消费模式,Disruptor是在消费者中记录一个依赖的消费进度,当消费的时候去检查依赖的消费进度都已经消费了,才会消费改消息,否则就执行等待策略。
sequenceBarrier

要使用pipeline消费,就不能直接使用Disruptor提供api,是需要使用EventHandlerGroup中的and()/then(),使用这里的api会传入一个sequenceBarrier,然后在消费的时候,会判断
消费者是维护了自己的消费进度的,判断一个消费者是否消费了消息,比较消费进度offset就好了。
而且生产者和消费者之间的协调,其实就两方面:生产者不要覆盖没有消费的消息;消费者不能消费已经消费过的消息。转换在队列实现中,其实就是比较生产者和消费者的生产进度和消费进度,而Disruptor使用了永远递增的下标使得这个比较简化了很多。
ps:ThreadPoolExecutor Disruptor guava的EventBus kafka之间的区别
这些框架其实都是生产者-消费者模型,不过侧重点和使用场景是不一样的。
- ThreadPool更多的是一个资源池化设计,为了复用线程资源的。生产者提交的其实是任务(就是一个逻辑计算任务,简单理解就是个函数)。消费者就是实实在在的线程,它去驱动执行这个任务。
- Disruptor、EventBus、kafka之类的分布式消息框架,其本质是个事件驱动模型。生产者生产的是事件(说白了就是一堆数据),然后每个消费者都各自定义如何处理这个事件数据,即生产者-消费者之间传递的是事件
- EventBus不算是个消息框架,它没有消息存储能力的,消费者不是根据自己的情况选择什么时候来消费的,而是在post()事件的时候直接去让消费者消费,它更多的是个观察者模式的实现,无非这个观察值是同步执行还是一部执行
Disruptor和kafka其实算是一个实现功能比较丰富的消息框架,区别在于Disruptor是一个内存框架,kafka是一个分布式的框架。Disruptor的生产者和消费者都是同一进程下的线程,所以线程的管理会方便很多。而kafka的生产者既可以是线程也可以是进程,因为是个分布式的,管理协调起来就复杂了很多。
当队列空了,消费者怎么办?
在构建Disruptor的时候会指定一个WaitStrategy,这个就是来指示当队空的时候,消费者的行为的。
当队列满了,生产者怎么办?
队满的含义:是指最慢的消费者
这就要看生产者使用的是什么接口了:如果说使用的是Disruptor#publishEvent(),那么生产者就会阻塞:
如果使用的是Disruptor#getRingBuffer()#publishEvent(),则这个方法会返回false,由生产者决定怎么处理。

其实可以看即便是这种大名鼎鼎的组件,写代码的时候也有手抖的时候,按照Disruptor对性能锱铢必较的态度,这里这种写法肯定是不ok的,因为抛异常会对性能有损耗,因为异常会收集堆栈信息。但是如果不抛异常,用返回值,那么tryNext()怎么返回呢?又不能返回true 或者false,那就只能用一个特殊的值表示队满,比如-1,这样的话其实也很蛋疼,可读性就不好了。我猜也正是这个原因,选择了使用异常来表示队满。但是至少InsufficientCapacityException应该定义成让他别收集堆栈信息,要么就是用参数控制,要么就是像这里一样,覆盖收集堆栈的方法。
多生产者同时修改队尾下标的问题
生产者生产元素都是要放在队尾的,所以生产完元素后,一定要去修改队尾下标。在Disrutor中,队尾的下标是存放在生产者Sequence的cusor中的,所以当生产完元素后,一定会涉及多线程修改cursor的问题。
Disruptor(3.2.2)并没有用什么特殊的手段来避免多线程同时修改同一个变量,还是使用互斥来解决的,只是这里的互斥不是使用的悲观锁,而是CAS

当然,使用CAS就会有ABA的问题,这里如果出现,就会出现队尾cursor不正确,所以修改队尾是不能出现ABA的问题的。
比如当前cursor=8,ProducerA和ProducerB同时都要生产元素,这个时候ProducerA先进到next方法中,获得了cursor=8,然后计算next加1后为9,所以就会在9这个位置写入元素。当ProducerA执行到这里CAS的时候,ProducerB也进入到next方法,因为ProducerA还没执行CAS,所以ProducerB拿到的cursor也是8,并计算next=9.。然后ProducerA执行CAS,将cursor变成了9。如果这个时候,ProducerB执行到了CAS这,因为current和next不等,所以不会返回,会重新获得可写入位置。。但是当ProducerA CAS成功写入后,然后消费者直接消费了cursor=9这个位置的数据,那么会不会有问题?。
答案是不会:cusor是一直增长的,消费者消费后,并不会将cursor变回8,所以ProducerB还是会失败。其实这是一个典型的ABA问题,绝大部分情况,ABA是不会有什么问题的,但是这里如果出现ABA就会有问题。而一般避免ABA问题的手段,就是给数据带上版本。如果说这里的下标不是一直增长,而是0~bufferSize循环使用,是不是就会有ABA的问题,其实也就会引起错误,导致队头是错误的。这里使用的方式是一直增长,其本身就可以认为自带版本,避免ABA问题
Ps:其实很多地方都会有写入瓶颈。一个类似的例子就是jdk8中的ConcurrentHashMap,当多线程put()元素后,会去更新size,那这个就是多个线程争相改动的共享变量,那坑定是存在争抢的。但是ConcurrentHashMap中的处理方式是进行分片,每个分片维护一部分数据,每个分片都有一个size,各自进行维护,当多线程修改有一个分片的数据的时候,那就只能是互斥修改了(ConcurrentHashMap用的也是CAS),然后如果要使用整个HashMap的size的时候,就是实时将各个分片的size进行累加得到的,这么搞的一个小问题就是数据不是绝对强一直的。
其实使用这种分片思想来解决写入瓶颈,提交写入并发的例子还是很多的,比如db的分库分表,kafka的partition,ES的sharding等,其实即使各自起名不一样,其实思路都是一个。
这些只是个人看代码的一个记录总结,了解了这些背后思路后再去看代码,其实就会容易一些,能够看清楚它到底为什么会这么写代码了