7.19~7.20学习总结
(快速了解数据库的基本增删查改操作,前提是要先熟悉数据库的基本操作);
数据库里面对表里的字段类型修改:
ALTER TABLE student MODIFY COLUMN charm VARCHAR(4);这里是将student表中的charm字段的类型改为varchar(4);
对字段名称的修改:
ALTER TABLE student CHANGE COLUMN charm charming VARCHAR(4); 这里是将表中的charm字段名称改成charming字段;
删除字段:
ALTER TABLE student DROP COLUMN charming ;这里的意思是删除一个字段名为charming的一段;
ALTER TABLE student DROP COLUMN sex,DROP COLUMN grade;而这里是删除一个字段名为sex,grade的字段;
删除表:
DROP TABLE student;这里是删除一个名为student的表;
查看表结构:
DESCRIBE student;这里查看一个名为student的表结构;结果如下

在表中的操作:
查询表中的所有数据:
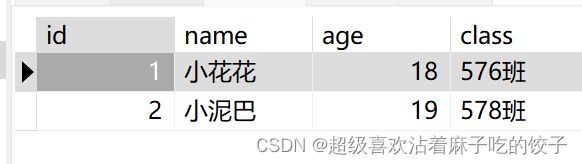
SELECT *FROM student;查询student表中所有数据,结果如下:
给表插入数据:(在myaql里面字符串使用单引号括起来的);
INSERT INTO student VALUES (3,'小卷卷',17,'584班');这里是插入了一个名id为1的字段;但是这种就要按照从左到右列的名称来插入,还有一个可以自己制定顺序的:
INSERT INTO student (id,name,class,age)VALUES(4,'陈培林','575班',19);
这里制定输入顺序为id,name,class,age;来插入一个学生的数据;
INSERT INTO student (id,name) VALUE(5,'小七七');这里也可以指定不是所有的顺序,这时候其他的就会变成Null,比如这个的运行结果;

但是这里有个前提少的字段必须被要求是可以为空,如果设置了NOT NULL,那么就不可以;
主键不能重复,也不能是Null,insert支持批量插入,可以只设置一次顺序,插入多次value,也可以按照自然顺序插入多次,比如这里设置顺序插入;
INSERT INTO student (id,name,class,age)VALUES (6,'小朋友','593班',19),(7,'小孩儿','578班',20);但是有几种特殊情况,比如,表的字段是有默认值的(不给字段值,填默认值),表的字段是整数,切实自动增长(默认自动增长);
CREATE TABLE student1(
id int(10) NOT NULL AUTO_INCREMENT,
name VARCHAR(10) DEFAULT '匿名',
PRIMARY KEY(id)
);这里创建了一个新表,id字段不可以为空,并且设置为自动增长,name字段设置默认值为’匿名‘,并且把id设置为主键;
INSERT INTO student1 (name) VALUES ('小微凉'),('小笨蛋'); 然后尝试一段代码之后,就会得到结果:

INSERT INTO student1 (id) VALUE (5);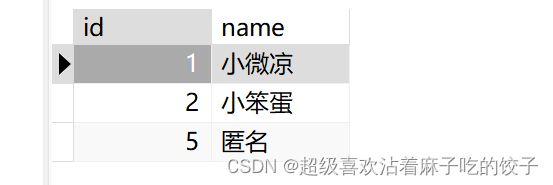
修改数据:
UPDATE student SET age=18;
UPDATE student SET age=19,name='小麻子';第一行,修改所有student人的年龄字段值为18,第二行,修改student人的所有年龄改为十九,名称改为小麻子;
要修改某个特定的条件的内容可以这样改:
UPDATE student SET age=16,name='小饺子'WHERE id=2;
UPDATE student SET age=3 WHERE id=3;对了,当有多行的时候,可以选中其中一个语句并将其右键运行已选择的,这里的意思是,将id=2的那一行里面的年龄字段改为16,名称改为小饺子;下面一行是只改一个同理;
按条件删除数据:删除行;
DELETE FROM student WHERE ID=3;删除来自student的id=3的那一行;
如果删除不加条件比如:
DELETE FROM student1;即就是删除表student1的里面的所有数据,注意,不是删除表;
关于删除的那些事,如果表中有字段是自动递增的,如果删除了某个字段是整数那么自动递增的起始点保留比如某个表中那个字段自动递增到了10,那么下一次添加如果没有设置值的话,会从10开始递增,如果想要清除保留点需要将表删除;如果在一个自动递增的字段下面删除中间的一个数据是不会影响递增的比如自动递增到了10,然后删除3,后面再添加一个不指定的,结果会是11;
查询指定列的数据:
SELECT name FROM student;意为查询student表中的name列;结果如下:

搜索多个列:
SELECT name ,age FROM student;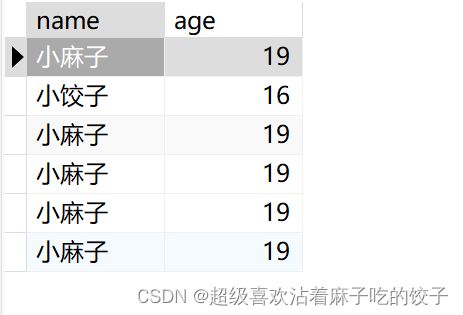
查询的时候顺便改成别名:
SELECT id '编号',name '姓名'FROM student ;
这只是方便观看,但是实际上表上面是不会变的;

合并列查询,现在有一个新需求,要求将查询一个所有人的班级和姓名并且按照‘班级-姓名’的形式,所以可以写成现在这样:
SELECT CONCAT(class, '-->', name) '班级--姓名' FROM student;
SELECT name,(age+eage) '年龄' FROM student;这里括号里面的是两个年龄加起来,最后查出来列框显示的是’年龄‘,也就是说支持加法;
查询时去除重复的值:
SELECT DISTINCT class FROM student;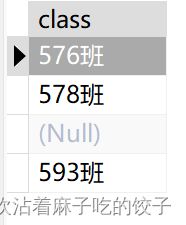
正则表达式:

正则表达式里面:
\d:表示0~9里面的任意一位数字,注意是一位!!,如果是大写的\D的话就表示为是非数字;\w表示字母数字下划线 ,同理\w表示除了这些都是;\s表示匹配空白符,空格换行制表符等;同理\S取反 .可以匹配任意一个字符除了换行,如果想匹配所有字符包括换行符那么则用[\s\S];
方括号匹配方式:匹配方括号里面的任意字符,做或运算,如果在方括号里面加了^则为取反的意思,除了方括号里的都匹配;如果中括号里面有-的话表示的是从某个字符按顺序到另一个字符中间的所有字符都可以比如[2-8];
如果要搜索多位数字几个\d来描述,但是也可以用\d{数字的位数};匹配字符默认是贪婪模式,如果\d{m,n}里面表示的是最少匹配m次,最多匹配n次,也就是此时有多个字符,他的首选是匹配n次;
非贪婪模式:匹配字符后面加一个问号?匹配字符越少越好;{m,}表示至少重复m次;但是没有最多六次{,6}这种形式,如果是一个单独的放在要匹配的字符后面的?号其实就相当于{0,1};最少零次最多一次;+如果放在要匹配的字符后面表示最少1次;
字符边界:^在方括号外面的话表示的就是字符串开始的地方,比如^i字符串只有一个开头的地方如果在最开始的地方没有i的话就不会匹配到了;同理$表示字符串结尾,如果要匹配7$表示的是如果被匹配的那整段字符串不是以7结尾,那么就不会匹配到其他的7;\b找到要匹配的字符串的它位置,如果它前面和后面不全是\w可以表示的就可以匹配;
捕获组和非捕获组:如果想要匹配到4个字母的字符串,其中后面两个和前面两个是重复的,可以用([a-z]{2})\1;表示先匹配两个连在一起的字母,然后后面的\1表示重复前面的第一组,记多少组是记左括号为准;但是捕获组会占用内存如果不用重复内容的话,可以在括号的里面加一个?:
零宽断言(环视):有这么几个表达式 :

以第二个举例:


上面是表达式,下面是要等待匹配的字符串;可以发现,这个式子指的是在一个字母前面如果出现了ing就可以标记上这个字母及其后面连着的字母;但是不包括ing表达式,这就正好演示了零宽;
实现字符串判断:比如邮箱的简单判断:


正则表达式在ideal里面判断字符串:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class regex {
public static void main(String []args)
{
//使用正则表达式在字符串中匹配;
Pattern p= Pattern.compile("\\w+");
Matcher m=p.matcher("asdfghj&&2345");
//boolean yesorno=m.matches();
boolean yesorno1=m.find();
boolean yesorno2=m.find();
// System.out.println(yesorno);
System.out.println(yesorno1);
System.out.println(yesorno2);
}
}
得到的结果:
true
true
先来解释一下matches匹配,是匹配一整个字符串,而find则是匹配到后面不匹配了就返回匹配正确,下一次就继续匹配到满足的返回,记住匹配字符串的指针是有记忆的,比如:
在刚刚的例子里面如果那个匹配一整个字符串的匹配到不成功的地方,后面如果还继续执行find(),则find则会在匹配失败的地方重新开始;
如果想要将找到的字符串打印出来的话可以将用group方法;比如上面的代码写成这样:
boolean yesorno1=m.find();
boolean yesorno2=m.find();
System.out.println(m.group());
也就是在刚刚的两行后面加上一个这个语句,得到的结果就是:
2345
true
true
打印出来了最后一次。
group()和group(0)都是匹配以后一整个字符串的子字符串;
关于group(1)表示分组;比如:
public static void main(String []args)
{
//使用正则表达式在字符串中匹配;
// Pattern p= Pattern.compile("\\w+");
//Matcher m=p.matcher("asdfghj&&2345");
//boolean yesorno=m.matches();
//boolean yesorno1=m.find();
//boolean yesorno2=m.find();
// System.out.println(m.group());
Pattern p1=Pattern.compile("([a-z]+)([0-9]+)");
Matcher m1=p1.matcher("123ds&&fds43&&23dgf23");
m1.find();
System.out.println(m1.group(1));
System.out.println(m1.group(2));
// System.out.println(m1.group(3));
// System.out.println(yesorno);
// System.out.println(yesorno1);
//System.out.println(yesorno2);
}
/*
fds
43
*/
也就是按照括号分组,分别打印第一组和第二组;
还有就是字符串的替换和分割:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class regex1 {//将数字用#号代替
public static void main(String[]args)
{
Pattern p=Pattern.compile("[0-9]");
Matcher m=p.matcher("aaa2332add adsd12");
String msg=m.replaceAll("#");
System.out.println(msg);
}
}
/*
aaa####add adsd##
*/分割:
建立连接比较耗时,因为链接对象内部其实包含了Socket对象,是一个远程的连接;
接口:Statement是PreparedStatement和CallableStatement 的父类;
一般不使用Statement接口:容易发生sql注入:

import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBC1 {
public static void main(String[]args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/xiaohuahua","root","123456");
//System.out.println(conn);
//但是statement接口的弊端:如果给定的是Java里面的字符串name,则要转换'"+name+"'
Statement stt=conn.createStatement();
String aql="insert student (name,age,class) values ('赵六',16,'576班')";
stt.execute(aql);
}
}
生活中本就充满了失望,不是所有的等待都能如愿以偿。你且笑对,不必慌张。
