第三章 CUDA编译器环境配置篇
cuda教程目录
第一章 指针篇
第二章 CUDA原理篇
第三章 CUDA编译器环境配置篇
第四章 kernel函数基础篇
第五章 kernel索引(index)篇
第六章 kenel矩阵计算实战篇
第七章 kenel实战强化篇
第八章 CUDA内存应用与性能优化篇
第九章 CUDA原子(atomic)实战篇
第十章 CUDA流(stream)实战篇
第十一章 CUDA的NMS算子实战篇
第十二章 YOLO的部署实战篇
第十三章 基于CUDA的YOLO部署实战篇
cuda教程背景
随着人工智能的发展与人才的内卷,很多企业已将深度学习算法的C++部署能力作为基本技能之一。面对诸多arm相关且资源有限的设备,往往想更好的提速,满足更高时效性,必将更多类似矩阵相关运算交给CUDA处理。同时,面对市场诸多教程与诸多博客岑子不起的教程或高昂教程费用,使读者(特别是小白)容易迷糊,无法快速入手CUDA编程,实现工程化。
因此,我将结合我的工程实战经验,我将在本专栏实现CUDA系列教程,帮助读者(或小白)实现CUDA工程化,掌握CUDA编程能力。学习我的教程专栏,你将绝对能实现CUDA工程化,完全从环境安装到CUDA核函数编程,从核函数到使用相关内存优化,从内存优化到深度学习算子开发(如:nms),从算子优化到模型(以yolo系列为基准)部署。最重要的是,我的教程将简单明了直切主题,CUDA理论与实战实例应用,并附相关代码,可直接上手实战。我的想法是掌握必要CUDA相关理论,去除非必须繁杂理论,实现CUDA算法应用开发,待进一步提高,将进一步理解更高深理论。
cuda教程内容
第一章到第三章探索指针在cuda函数中的作用与cuda相关原理及环境配置;
第四章初步探索cuda相关函数编写(global、device、__host__等),实现简单入门;
第五章探索不同grid与block配置,如何计算kernel函数的index,以便后续通过index实现各种运算;
第六、七章由浅入深探索核函数矩阵计算,深入探索grid、block与thread索引对kernel函数编写作用与影响,并实战多个应用列子(如:kernel函数实现图像颜色空间转换);
第八章探索cuda内存纹理内存、常量内存、全局内存等分配机制与内存实战应用(附代码),通过不同内存的使用来优化cuda计算性能;
第九章探索cuda原子(atomic)相关操作,并实战应用(如:获得某些自加索引等);
第十章探索cuda流stream相关应用,并给出相关实战列子(如:多流操作等);
第十一到十三章探索基于tensorrt部署yolo算法,我们首先将给出通用tensorrt的yolo算法部署,该部署的前后处理基于C++语言的host端实现,然后给出基于cuda的前后处理的算子核函数编写,最后数据无需在gpu与host间复制操作,实现gpu处理,提升算法性能。
目前,以上为我们的cuda教学全部内容,若后续读者有想了解知识,可留言,我们将根据实际情况,更新相关教学内容。
大神忽略
文章目录
- cuda教程目录
- cuda教程背景
- cuda教程内容
- 前言
- 一、vs2019环境配置条件
- 二、visual studio环境配置步骤
-
- 1、新建项目
- 2、调整配置管理器平台类型
- 3、配置生成属性
- 4、配置基本库目录
- 5、配置CUDA静态链接库路径
- 6、选用CUDA静态链接库
- 7、配置源码文件风格
- 三、环境安装验证
-
- 1、验证代码
- 2、验证结果
前言
每个人都有自己喜欢的编译器,我不能将其一一列举。为此,我将以我喜欢visual studio2019作为cuda的编译器,此编译器功能较多,特别是debug模式,能更好帮助cuda开发。本节将介绍visual studio2019编译器配置cuda环境。
一、vs2019环境配置条件
若需要使用cuda环境开发,需提前安装英伟达显卡驱动、CUDA、Cudnn、visual studio2019。这些安装方法网上已有很多教程,可供参考。
二、visual studio环境配置步骤
假设我们已经安装了显卡驱动与visual studio相关环境。
温馨提示:先安装visual studo 在安装cuda驱动,否则较难配置
1、新建项目
打开VS2017→ 新建项目→Win32控制台应用程序 → “空项目”打钩
2、调整配置管理器平台类型
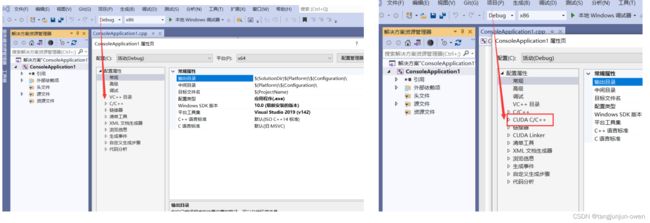
右键项目→ 属性→ 配置管理器→ 全改为“x64”

3、配置生成属性
右键项目 → 生成依赖项→ 生成自定义→ 勾选“CUDA 11.1XXX”
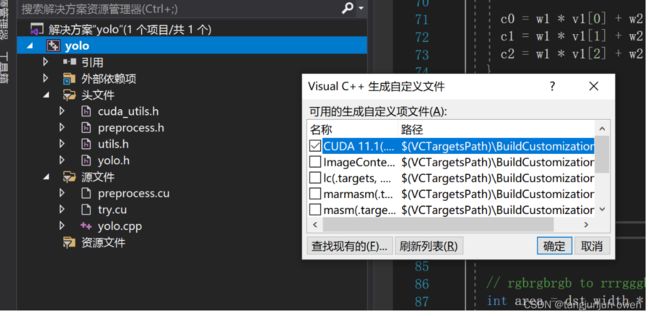
补充说明:
若不选择生成自定CUDA**选项,结果如左图,不会出现cuda相关信息;若选择,结果如右图会出现cuda相关信息。
4、配置基本库目录
注意:后续步骤中出现的目录地址需取决于你当前的CUDA版本及安装路径
右键项目→属性→ 配置属性→ VC++目录→ 包含目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\include
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\common\inc
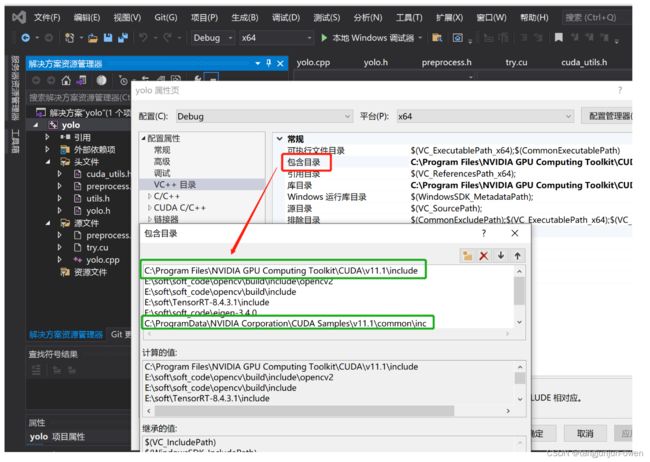
右键项目→属性→ 配置属性→ VC++目录→ 库目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.1\common\lib\x64
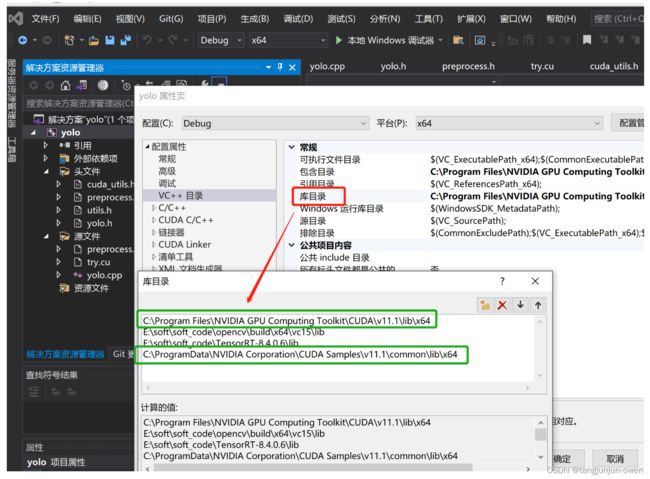

5、配置CUDA静态链接库路径
右键项目→ 属性→ 配置属性→ 链接器→ 常规→ 附加库目录,添加以下目录:
$(CUDA_PATH_V11_1)\lib$(Platform)
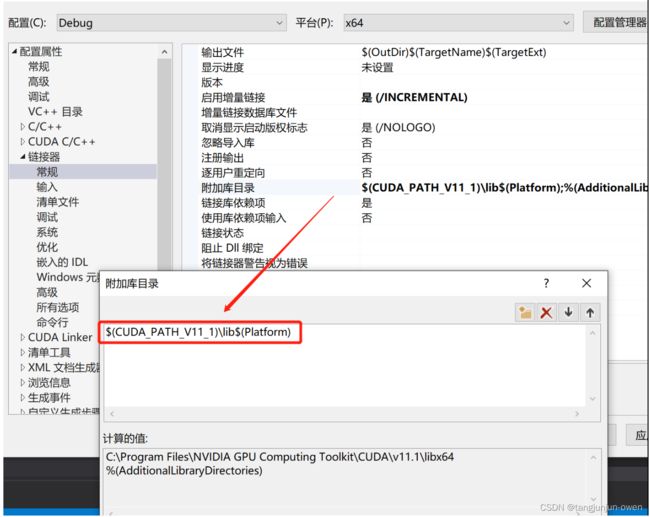
6、选用CUDA静态链接库
右键项目→ 属性→ 配置属性→ 链接器→ 输入→ 附加依赖项,添加以下库:
cublas.lib;cublas_device.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;cufft.lib;cufftw.lib;curand.lib;cusolver.lib;cusparse.lib;nppc.lib;nppial.lib;nppicc.lib;nppicom.lib;nppidei.lib;nppif.lib;nppig.lib;nppim.lib;nppist.lib;nppisu.lib;nppitc.lib;npps.lib;nvblas.lib;nvcuvid.lib;nvgraph.lib;nvml.lib;nvrtc.lib;OpenCL.lib;
添加的库目录 “C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1\lib\x64” 中的库,可参选
注意:
kernel32.lib;user32.lib;gdi32.lib;winspool.lib;comdlg32.lib;advapi32.lib;shell32.lib;ole32.lib;oleaut32.lib;uuid.lib;odbc32.lib;odbccp32.lib;%(AdditionalDependencies)
这些库为原有!
7、配置源码文件风格
右键源文件→ 添加→ 新建项→ 选择 “CUDA C/C++ File”
右键 “xxx.cu" 源文件→ 属性→ 配置属性→ 常规→ 项类型→ 设置为“CUDA C/C++”

三、环境安装验证
1、验证代码
代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
int main() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int dev;
for (dev = 0; dev < deviceCount; dev++)
{
int driver_version(0), runtime_version(0);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
if (dev == 0)
if (deviceProp.minor = 9999 && deviceProp.major == 9999)
printf("\n");
printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name);
cudaDriverGetVersion(&driver_version);
printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);
cudaRuntimeGetVersion(&runtime_version);
printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);
printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem);
printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);
printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem);
printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock);
printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock);
printf("Warp size: %d\n", deviceProp.warpSize);
printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);
printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);
printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0],
deviceProp.maxThreadsDim[1],
deviceProp.maxThreadsDim[2]);
printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);
printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);
printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);
printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);
printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);
printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);
}
return 0;
}
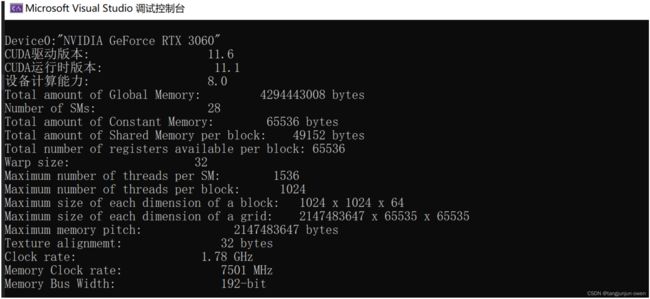
2、验证结果