Redis 内存淘汰策略,从根儿上理解
文章目录
- 前言
- 一、淘汰策略
-
- 1. 全局淘汰:
- 2. 淘汰 expire :
- 3. 不淘汰:
- 二、淘汰算法
-
- 1. LRU 算法
- 2. LFU 算法
- 三、淘汰
-
- 1. 何时清理?
- 2. 清理哪些?
- 3. 清理多少?
- 4. 怎样清理?
前言
本文参考源码版本
redis6.2
Redis 基于内存设计,所有数据存放在内存,随着时间推移,内存占用也越来也高 …
由于内存容量这个物理限制,我们需要在内存使用量达到一定比例后,做一些内存清理工作,以保证有足够的空间来完成正常的处理。
在 Redis 中,完成这个工作的就是本文的主角 ------- Redis 内存淘汰机制。
- 一定比例:在 redis 中就是 maxmemory 阈值
- 淘汰策略:在 redis 中目前有两种流行的算法:LRU 与 LFU 算法
如果让你来设计一款内存淘汰策略,你会考虑哪些方面?
1)首先,从用户体验上看:
- 不要影响服务正常使用,实现平滑淘汰
- 用户透明,用户不需要做任何额外操作
2)其次,从系统层面来看:
- 何时清理?
- 清理哪些?
- 清理多少?
- 怎样清理?
- 清理频次?
带着这些问题,我们一起来探索下,Redis 是如何考虑并实现的。
一、淘汰策略
淘汰策略也是可以在 redis.config 中指定:
maxmemory-policy ...
截止目前,共有 8 种淘汰策略,如下:
1. 全局淘汰:
1)allkeys-lru:淘汰范围是所有 keys,淘汰最久未使用的 key
2)allkeys-lfu:淘汰范围是所有 keys,淘汰使用频次最少的
3)allkeys-random:淘汰范围:所有 keys,随机淘汰 key
2. 淘汰 expire :
1)volatile-lru:淘汰范围:所有设置了 expire 时间的 keys,淘汰最久未使用的 key
2)volatile-lfu:淘汰范围:所有设置了 expire 时间的 keys,淘汰使用频次最少的 key
3)volatile-random:淘汰范围:所有设置了 expire 时间的 keys,随机淘汰 key
4)volatile-ttl:淘汰范围:所有设置了 expire 时间的 keys,淘汰 ttl 剩余时间最少的 key
3. 不淘汰:
1)noeviction:不淘汰,意味着达到限制时,将无法存储
二、淘汰算法
目前有两种常用的内存淘汰算法,分别致力于从 访问时间 和 访问频次 上解决内存问题。
1. LRU 算法
Least Recently Used,最近未使用淘汰算法,是一种按照访问时间进行淘汰的算法。
假如只从设计上考虑,我们一般会定义一个队列来存储访问记录,然后每次从队列末尾删除元素即可。
- 队首新增:访问记录不存在,则在队列尾部新增访问 key
- 元素位置调整:访问记录存在,则调整元素 key 至队首
- 队尾删除:当需要淘汰 key 时,从队尾开始判断即可。
但是在 redis 中,内存、CPU 是稀缺物,要尽可能减少内存使用量、CPU 的消耗,因此,在实现上也就更加放松。
redis 采用近似 LRU 算法,每次随机选择一个样本集,并从样本集中挑选最长时间未使用的 key 淘汰。这样一来就不用维护访问队列,而是选择一个合适的样本集大小,也能达到近似 LRU 算法效果。
我们来看看官方测试效果:
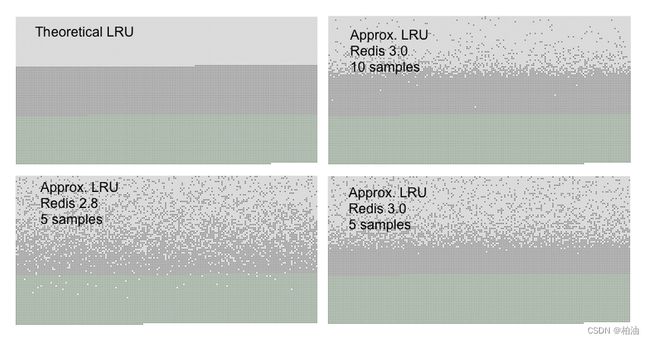
- 浅灰色代表被淘汰的数据
- 深灰色代表没有被淘汰的数据
- 绿色代表新增数据
在 redis3.0 之后,当选择样本集 maxmemory-samples = 10,其效果基本已经接近 LRU 算法,但是会更消耗 CPU。
redis.config 中的 maxmemory-samples 默认值为 5,一般情况下应该够用了。
接着,我们来看看 LRU 算法的工作原理,以及存在哪些问题:
~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~|
~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~|
~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~|
~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|
其中,~ 字符表示 1 秒,| 表示结束,A 每 5 秒访问一次,B 每两秒访问一次,C、D 每 10 秒访问一次。
我们先看 A、B、C,由于 B 访问频次最高,你会看到 B 几乎总是处于访问队列队首,C 频次最低,大概会出现在访问队列队尾。
不同的是 D,和 C 一样的频率,目前却出现在了队首。
LRU 算法认为,最近访问过的 key,再次访问的概率比较大,而很久没有访问的 key 再次访问的概率比较小(队尾),因此队尾可以优先淘汰。
但是,从以上案例,D 的情况也可以看出,会存在一些极端情况。不过,LRU 总的来说,是比较 OK 的。
每一个 key 在 redis 中都是以 redisObject 形式存在,其中 lru 字段便是记录访问时间:
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
2. LFU 算法
Least Frequently Used,即 最近最少使用淘汰策略,是一种按照访问频次处理的淘汰算法。相对于 LRU 算法,在某些方面效果可能更佳。
LRU 算法有个缺点是,临时数据可能会取代真正经常使用的数据。比如,短时间内,大量临时数据涌入 redis,而触发发生内存淘汰,可能会将那些真正经常使用的数据驱逐。
LFU 是一种按频次处理的淘汰算法,可以很好解决临时数据问题。
假如只从设计上考虑 LFU,一般情况下:要记录每个 key 的使用次数 + 统计窗口:
- int 存储使用次数:4 字节,基本满足需求
- 统计窗口:当窗口滑动时,要累加新的次数,同时也要减去过期数据;本质来说,就是要记录访问明细,看起来挺繁琐。
前面说了,redis 内存和 CPU 都是稀缺品,可以猜测下,不会采用上述方案。
redis LFU 也是采用给一个近似算法:
- 计数器:使用次数,仅采用 8 byte 存储,最大值 255
- 衰减时间:不使用滑动窗口,采用衰减时间,达到一定条件使计数器减小。
对应 redis.config 的配置是:
lfu-log-factor 10
lfu-decay-time 1
计算规则是这样的:
- 随机数 R,取数范围:0 ~ 1
- 概率参数 P = 1 / (old_value * lfu_log_factor + 1),这里 old_value 就是计数器的值。
- 计数器累加:条件是 R < P
从这个公式可以看出,影响累加器的有两个变量:
- old_value:当前计数值,随着计数值的累加,参数 P 就会越小,也就是说越往后累计越困难,这就确保了计数器不会快速膨胀至 255。
- lfu_log_factor:在 redis.conf 配置的参数,用于控制累加速度。
我来来看看官方给出的参数 lfu_log_factor,控制累加速度效果:
+--------+------------+------------+------------+------------+------------+
| factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
+--------+------------+------------+------------+------------+------------+
| 0 | 104 | 255 | 255 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 1 | 18 | 49 | 255 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 10 | 10 | 18 | 142 | 255 | 255 |
+--------+------------+------------+------------+------------+------------+
| 100 | 8 | 11 | 49 | 143 | 255 |
+--------+------------+------------+------------+------------+------------+
可以看到,随着 lfu_log_factor 值的变大,计数器累加的速度越来越慢 …
redis 为了节省内存空间,LFU 的记录仍然复用了 24 bit 的 LRU 字段:
16 bits 8 bits
+----------------+--------+
+ Last decr time | LOG_C |
+----------------+--------+
- 高 16 bits 用来记录时间
- 低 8 bits 用来记录累加数值
计数器累加相关逻辑:
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
三、淘汰
前面我们已经讨论了如何淘汰策略以及淘汰算法,这部分我们将讨论真正的淘汰过程:
- 何时清理?
- 清理哪些?
- 清理多少?
- 怎样清理?
我画了张淘汰的整体流程图,你可以参考下:
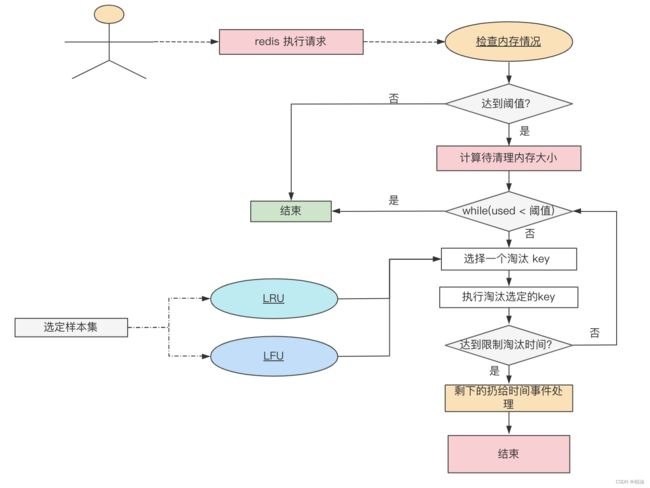
1. 何时清理?
这也是一种惰性思想,一个用户请求过来了,顺便检查下内存使用情况,当 redis 内存使用量达到预定阈值 maxmemory 时,便会触发淘汰机制。
- 每一条客户端的请求处理之后,看是否有必要进行内存淘汰。如果需要,走淘汰逻辑。
淘汰时也分两种情况:
- 淘汰数据少:这种很理想,一次性可以搞定。
- 淘汰数据多:如果数据过多,为避免长时间阻塞,提供了一些可配置的限制,如果达到限制条件还没有清理完成,暂时放入到时间事件中,等待下一轮清理。
2. 清理哪些?
这个你基本也清楚了,哪些数据需要被清理,主要是看你选择的淘汰策略,以及淘汰算法。
从淘汰策略来看:
- allkeys- … 策略,就是全局范围内淘汰。
- volatile-… 则是在设置了过期 key 范围里淘汰。
从淘汰算法来看:
- 如果选择 LRU,一般就是先淘汰访问记录末端的数据
- 而选择 LFU 则淘汰最近最少访问的数据
3. 清理多少?
待清理的大小 = used - maxmemory,即当前使用内存大小 - 设定的阈值。
一次性没处理完(可以设置一定时长限制),可以扔到时间事件中,周期性的处理,直到达到目标 …
4. 怎样清理?
这就是两种淘汰算法的工作了。LRU 和 LFU 在 redis 中都是近似算法,本质是为了减少内存和 CPU 的消耗。
- 随机选出一个样本集
- 从样本集选出一个最合适淘汰的 key,这里通过 LRU 或者 LFU 算法选择
- 清理选择的 key,如果有必要可以使用惰性删除
相关参考:
- Key eviction # redis docs
- Random notes on improving the Redis LRU algorithm # antirez blog
- Incremental eviction processing #7653