【深度学习Week2】卷积神经网络
卷积神经网络 Convolutional Neural Networks,CNN
- 【第一部分:代码练习】
-
- 1.MNIST 数据集分类
- 2.CIFAR10 数据集分类
- 3.使用 VGG16 对 CIFAR10 分类
- 【第二部分:问题总结】
【第一部分:代码练习】
1.MNIST 数据集分类
1.1 加载数据 (MNIST):
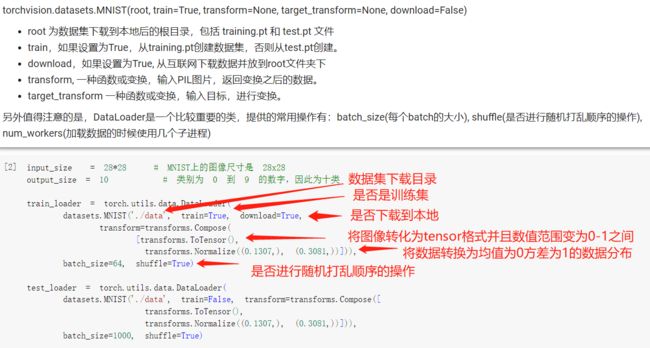
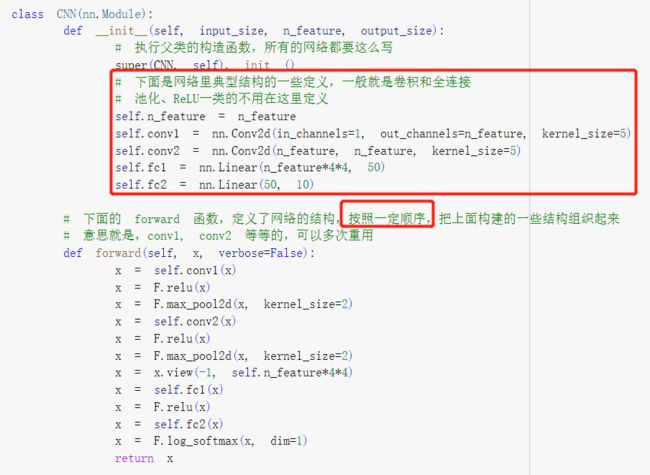
1.2 定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。

1.3 定义训练和测试函数:


1.4 在小型全连接网络上训练(Fully-connected network):

1.5 在卷积神经网络上训练:

通过上面的测试结果,可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息,主要通过两个手段:
卷积:Locality and stationarity in images
池化:Builds in some translation invariance
1.6 打乱像素顺序再次在两个网络上训练与测试:
考虑到CNN在卷积与池化上的优良特性,如果我们把图像中的像素打乱顺序,这样 卷积 和 池化 就难以发挥作用了,为了验证这个想法,我们把图像中的像素打乱顺序再试试。
首先下面代码展示随机打乱像素顺序后,图像的形态:




从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
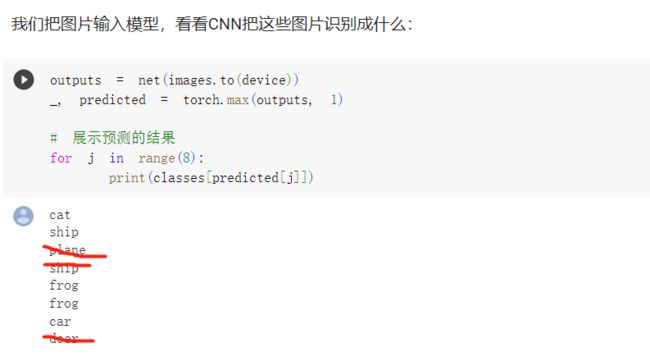
2.CIFAR10 数据集分类
使用 torchvision 加载并归一化 CIFAR10
torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。





3.使用 VGG16 对 CIFAR10 分类
3.1 定义 dataloader
这里的 transform,dataloader 和之前定义的有所不同

3.2 VGG 网络定义


3.3 网络训练

3.4 测试验证准确率:

可以看到,使用一个简化版的 VGG 网络,就能够显著地将准确率由 64%,提升到 84.92%
【第二部分:问题总结】
1. dataloader 里面 shuffle 取不同值有什么区别?
当 shuffle 取 true 时,在每个 epoch 开始时,对数据进行重新排序,打乱顺序以增加多样性,可以提高训练模型的泛化能力;
当 shuffle 取 false 时,在每个 epoch 开始时不会对数据的顺序进行打乱。
2. transform 里,取了不同值,这个有什么区别?
torchvision.transforms是pytorch中的图像预处理包,包含了很多种对图像数据进行变换的函数:
data_transforms = transforms.Compose([ # Compose方法是将多种变换组合在一起
transforms.RandomResizedCrop(224), # 进行随机大小和随机宽高比的裁剪,之后resize到指定大小224
transforms.RandomHorizontalFlip(), # 以0.5的概率水平翻转给定的PIL图像
transforms.ToTensor(), # 将PILImage转变为torch.FloatTensor的数据形式
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])# 通过平均值和标准差来标准化一个tensor图像
])
pytorch中transform函数详解
3. epoch 和 batch 的区别?
Epoch(批次)是指将整个数据集迭代一遍的过程。 在一个 Epoch 中,模型会对整个数据集进行一次前向传播和反向传播,更新所有的参数。
Batch(批量)是指为了加速训练而将大规模数据划分成小批次数据的过程。
epoch 由一个或多个 batch 组成。
4. 1x1的卷积和 FC 有什么区别?主要起什么作用?
从计算上来说,1x1的卷积和 FC 都是一个卷积计算的过程(y=WX+b),在理论上是可以相互替代的。
区别在于输入尺寸是否可变,卷积层可以对输入进行升维或者降维,以及卷积层可以引入非线性特征。全连接没办法适应输入尺寸的变化只能固定。
FC 常位于网络模型尾部,用于输出分类结果,而1×1卷积用于改变输入数据的channel
5. residual leanring 为什么能够提升准确率?
增加了深度却没有出现梯度消失,这是因为残差block在最后的输出中还加上其输入本身,这样的话它在复合求导的时候,即使某一个部分导数是0,但由于加了输入本身x,所以求导之后还是会加上一个1,这样计算出的权重就不会不发生改变了,也就避免出现梯度消失进而提升准确率。
6. 代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
练习二使用最大值池化 ,LeNet中使用平均值池化。
练习二使用ReLu激活函数,LeNet使用sigmoid激活函数。
在LeNet中最后多使用了一个卷积层,将输入图像大小变为1×1,channel为120,而在代码练习2中没有使用该卷积层,而是使用了一个全连接层,输出大小为120。
7. 代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
用1×1的卷积改变通道数,进行升维
8. 有什么方法可以进一步提升准确率?
增大训练数据集;
调整模型结构;
使用Dropout防止过拟合;
增加residual learning网络的深度;
选用更合适的损失函数和激活函数。