Java基础篇——从入门到入土
Java基础篇——从入门到入土
一、Java语言历史
Java的第一个开发工具包(JDK 1.0)JDK 1.1 JDK 1.2 JDK 1.3 JDK1.4。Java SE 5.0(内部版本号1.5.0) Java SE 6 Java7 Java8,我们不用最新的版本用最稳定的版本Java8,我们现在要学Java 涉及到JDK的安装JDK(Java Development Kit)称为Java开发包或Java开发工具,是一个编写Java的应用程序的程序开发环境。JDK是整个Java的核心,包括了Java运行环境(Java Runtime Environment),Java虚拟机 JVM,JRE是支持Java程序运行的标准环境 。JDK、JRE、JVM三者的关系,JDK包含了JRE同时包含了JVM、JRE是个运行环境,JDK是个开发环境。因此写Java程序的时候需要JDK,而运行Java程序的时候就需要JRE。而JDK里面已经包含了JRE,因此只要安装了JDK,就可以编辑Java程序,也可以正常运行Java程序。Windows系统,安装文件是.exe的文件,JDK也要安装因此JDK也是一个.exe的文件,并不会像其他软件一样生成快捷方式。
二、Java语言特点
-
简单性
-
面向对象
-
分布性
-
编译性和解释性
① 编译性
语言执行时需要先进行编译就是编译型语言,现在的高级语言在执行时,计算机不识别这个代码文件,需要先进行编译,形成字节码文件让计算机可以识别,程序才可以运行。编译型语言,肯定会形成出新的文件。(文件类型区分??? 可以通过文件后缀区分文件,Java文件后缀是.java编译形成新的文件,新文件的后缀是.class类型)
编译的过程
原来文件——规则——生成新的文件(字节码文件)
文件后缀 .java——javac(编译)——.class文件
执行的过程
javac A.java(文件名+后缀)② 解释性
两个人交流时,中间的翻译(解释).class文件计算机不认识而JVM就是.class和计算机之间的(翻译)因此Java 是解释性语言也是编译性语言。
执行class文件——翻译器(JVM)翻译给电脑
java A 文件名(不加后缀) -
可移植性
跨平台可以运行再不同的操作系统上
三、Java文件的创建
创建记事本,修改文件后缀 .java(文件一定显示后缀)然后写代码,不同的语言有不同的书写规则,Java是一个严格区分大小写的语言(大写和小写字母的含
义不同),所有的当前文件中的代码都要写在{}文件中。例如:
public class A(文件名) {
//Java程序运行时需要有一个入口(程序从哪开始执行)
//入口的书写方式:
public static void main(String[] args){
//程序员入门必经之路 hello world
//Java中的输出语句
System.out.println(“hello world”);//(英文分号结束) 打印完成后换行
System.out.print("Hello World"); 打印后不换行
}
}
四、Java语言基础
只要学编程语言就必须要学习的内容
1、常量和变量
- 常量 值不能改变 例如 数字就是常量 1 2 3 4 …
- 变量 值可以改变 例如 x+y=10;x=1; x=2;x=3;——x值从1变成2
定义变量的格式 数据类型 变量名 = 值
2、基本数据类型——整数、小数、字符、布尔
(1)整数
整数:根据数字表示的范围分成了四类 byte、short、int、long(表示的数字范围不同) ,其中byte字节是计算机中存储文件时,衡量文件大
小的单位,所有的文件 在计算机上以0和1的方式进行的文件存储(byte字节和位的关系1byte= 8位)。
| 类型 | 字节数 | 位数 | 范围 | 计算方式 |
|---|---|---|---|---|
| byte | 1个字节 | 8位 | -128到127 | -2的7次方到2的7次方-1 |
| short | 2个字节 | 16位 | -32768到32767 | -2的15次方到2的15次方-1 |
| int | 4个字节 | 32位 | -2147483648到2147483647 | 2的31次方到2的31次方-1 |
| long | 8个字节 | 64位 | 略 | -2的63次方到2的63次方-1 |
四个整数表示的数据范围不同 byte(2)小数
小数:根据占用的空间(字节)不同,表示的范围不同分成了两类float,double各自占用的字节数、位数、数据范围、小数位不同。Java中
直接书写的一个小数,默认是double类型。
| 类型 | 字节数 | 位数 | 精度 |
|---|---|---|---|
| float | 4个字节 | 32位 | 7位—8位----单精度(存储结构和整数不同) |
| double | 8个字节 | 64位 | 15位—16位-------双精度小数 |
数据范围double>float>整数。为了区分float类型的数据和double类型的数据,需要在小数末尾+f或者F的后缀就是float类
型,如果定义的数字没有小数点f可以省略就是默 认的double类型,如果定义的数字有小数点必须加f后缀。
(3)字符
字符定义方式:
char c = 'a';
只能写一个字符,计算机数据存储时实际上二进制进行的数据存放是0和1 。二进制数字可以转成十进制 (数字和数字之间的关系),编码
集(数字和字符对应表)字母(符号)和数字之间的关系,也就是字符和数字之间表示的对应的表(写什么数字对应到不同字符)。
Ascii 表:
例如 Int a = 64;Int类型的数据(十进制的数)按照ascii 对应到具体的char字符上,扩展的ascii表0-255 范围,每个国家都编写了自己的编码
集gbk2312(中文) 、Unicode编码集、中文编码集utf-8(现在使用多的中文编码集)
(4)布尔类型
boolean只有两个值true和false ,注意不要加双引号
boolean a = true
//boolean a = false
(5)数据类型转换
- 小范围数据转大范围数据 --------------转换规则:直接转换
//大范围数据类型 接收结果的变量 = 小范围数据变量
byte a = 10; float b = a;
int a = 10; long b = a;
- 大范围数据转小范围数据-----------------转换规则: 强制类型转换
//小范围数据类型 接收结果的变量 = (小范围数据类型) 大范围数据变量
float a = 10; byte b = (byte) a;
long a = 10; int b = (int) a;
(6)二进制和十进制
二进制:
计算机中进行数据存储时只有0和1两个数字存放,这就是二进制存储。二进制的存放,每个位上都是二进制。字节表示,通过8位
的二进制数字进行表示。二进制表示时,表示的位数比较多,四位一组进行表示,方便查看。
例如:一个二进制数字 :0000 0011对应的字节类型是哪个值?——>2的0次方+2的1次方=3
Java中的数据类型存储时,如果存储有符号的数字 (+ 大于0的数 - 小于0的数)八位中最前面的一位,表示数字的符号0表示正号,1表示
负号。
例如:0 111 1111 1+2+4+8+16+32+64=127
十进制:
生活中见到的数字: 629一个十进制的数也是三位数
百位 十位 个位------------都是十进制的数
6 2 9-------------十进制的数 0-9十个数,不能取10
现在的数字每个位上的数字和进制之间的关系
6*10的2次方 + 2*10的1次方+ 9* 10的0次方---------------629
3、变量名的命名规范(变量名怎么起名)
-
数字(不能开头)、字母、下划线、$
-
java中的保留字—关键字(java留下来的单词给自己使用 使用时 具有特殊的含义)例如 public class static
void byte short int long float double boolean char true false -
定义变量时,遵循规则,见名知义(不同单词组合再一起定义变量名)
-
驼峰命名法
小驼峰命名:Java 变量 (方法)多个单词组合表示变量名 首个单词首字母小写其他的单词首字母大写,例如 testboolean testBoolean
大驼峰:文件起名,多个单词组合表示变量名,所有单词首字母大写,写一个项目的文件,放到一个文件夹中,文件夹中根据文件内容,分不同的文件夹存储文件(java 给文件夹起了别的名字——包)包命名:都用小写字母来表示,用甲方公司域名的倒叙
baidu.com -----------com.baidu
bjpowernode.com----------com.bjpowernode
4、运算符的分类极其运用
(1)算数运算符
加(+)、减(-)、乘(*)、除(/)、取模/取余(%)、自增(++)、自减(--)、字符串连接符(+)。
-
数字运算 + - * /
先乘除后加减 + - * 基本上和我们学的数学运算一致 ,/ 参与运算的是整数 结果也是整;
int 和 int 数据运算,结果默认类型是 int类型;long 和 long 数据运算,结果默认类型是 long类型;
byte 和 byte、byte 和short、short和short 数据运算,结果默认类型是int类型;
不同的数据类型之间做运算,例如 int 和long运算,结果默认类型用大范围的数据接收。 -
小数运算 + - * /
float和float 做运算,结果默认是float类型,double 和double做运算 结果默认是double类型。
不同的数据类型之间做运算,结果默认类型用大范围的数据接收! -
字符类型也可以参数算术运算
字符类型char 字符和十进制数之间的对应关系(编码集)分为两种情况:
1、直接字符做运算 + -(多) (* / % 少)int a = '0' + 1; //char a = '0' + 1;结果类型的问题:取决于用什么类型接收结果:int类型接收就是数字char类型接收就是字符
2、字符变量做运算char a= '0'; int b = a + 1; //char b = a + 1;结果类型是什么:默认是int类型
-
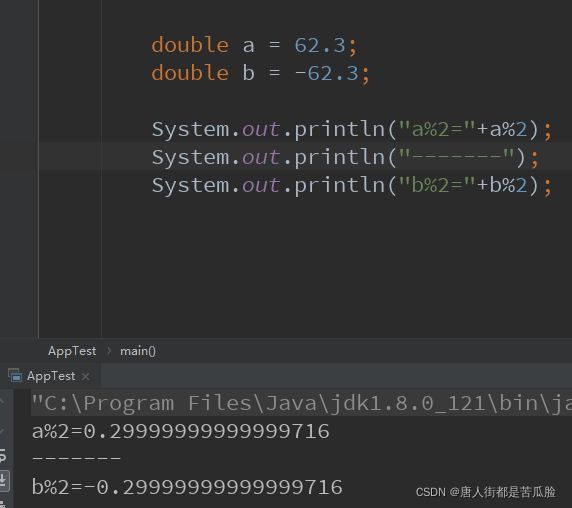
%(取模/取余)
在做取余运算的时候,先按正数进行取余,然后看%左边数字的符号,如果%左边的数字是正数,那么结果就是正数。
-
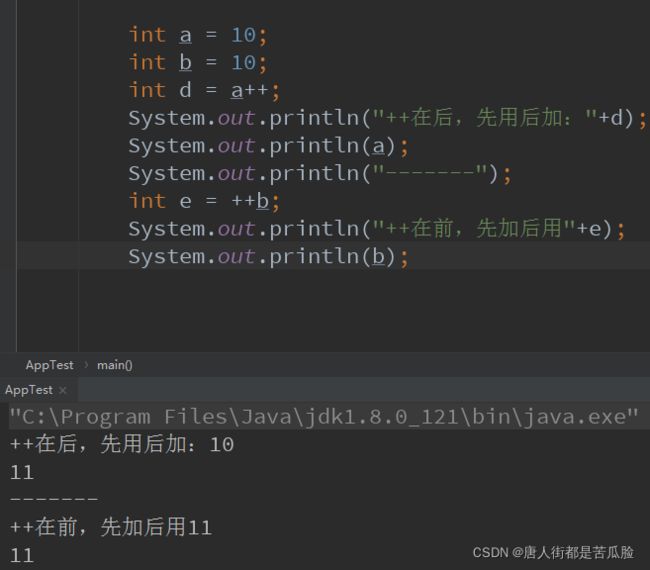
++/–(自增自减运算)
++ 给变量加一,给当前的变量加一
– 给变量减一,给当前的变量减一
变量和++(–) 组合使用 位置关系
变量a++(–) 先用变量的值用完了之后,再加一------------先用后加(减)
变量++(–) a 先加一,加完后再用a的值---------------------先加(减)后用
-
+(字符串拼接符/连接符)
和字符串 String 有关系的 +,比如字符串和数字或者字符串和字符串用+进行操作,不是求和拼接(+左侧和右侧的内容连接起来)进行数据打印时为了方便我们查看,可以给打印的变量加上一些描述信息。
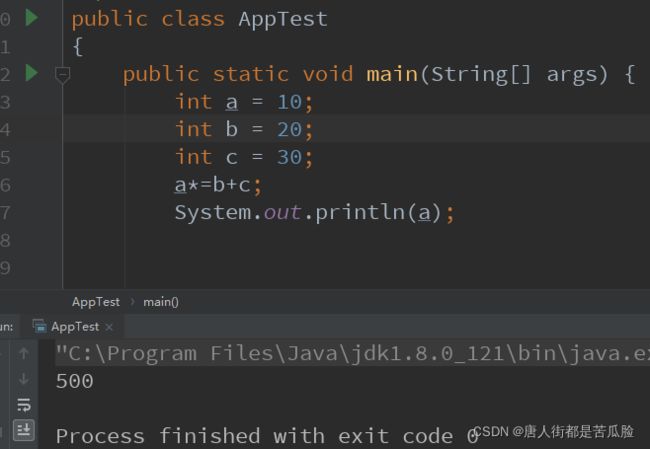
(2)赋值运算符
十二个运算符:=(等于) +=(加等) -=(减等) *=(乘等) /=(除等) %=(取余等) &=(与等) |=(或等) ^=(异或等) <<=(左
移等) >>=(右移等) >>>=(无符号右移等)
赋值运算符:把符号右侧的值赋给左侧的变量,除了=以外,其余的赋值运算符要求这个变量必须有初始值。
复合运算符:(二元运算符)就是算术运算符和赋值运算符连接在一起形成的
例如:
int a = 10;
int b = 20;
int c = a + b;
a=a+b;
//a=a+b 出现了两个a 希望简化 只有一个a
//a+=b; 通过a保存a和b的和
复合运算符和算术运算是两大类的运算符,运算符的优先级是算术运算符大于复合运算符
byte a =10;
a+=10;
//在自己本身的基础上进行的数据修改
//a的类型为byte类型(类型不发生变化,short也是)
(3)关系运算符
七个运算符:==等于、!= 不等于、>(大于) 、<(小于)、>=(大于等于)、<=(小于等于)
比较两个数的关系,结果都是boolean类型,boolean类型有两个结果值true关系成立、false 关系不成立。一个等式中可能会出现多个条件同时比较
(4)逻辑运算符
六个运算符:&与(And)、|或(Or)、!非(Not)、^异或、&&短路与、||短路或
结果都是boolean类型,用来连接关系表达式
//a>b>c 这样写是错误的要写成下面哪样
a>b && b>c
- &与(And)
当连接的表达式同时成立时,结果才是true,否则是false。如果把ture当做1,false当做0,即全1出1,有0出0。 - |或(Or)
当连接的表达式表达式都不成立时,结果才是false,否则是true。即有1出1,全0出0。 - !非(Not)
取反,非否即是,非是即否。 - ^异或
相同则为false,不同则为true。即相同为0,不同为1 。 - &&短路与
表达式1&&表达式2,如果现在表达式1已经可以决定整个表达式的结果,后边的表达式2不执行,也就是表达式2被短路 了,即如果前边的表达式的结果为false,则后边的表达式就不再运算。 - ||短路或
表达式1 || 表达式2,如果现在表达式1已经可以决定整个表达式的结果,后边的表达式2不执行-,也就是表达式2被短路 了,即如果前边的表达式的结果为true,则后边的表达式就不再运算。
其中 &与(And)、 |或(Or)又被称为全路运算符,不管前面的表达式是不是能决定整个表达式的结果,后面的都执行。&&短路与、||短路或被称为短路运算符,即如果前面的表达式1已经可以决定整个表达式的结果,后边的表达式2不执行。关系运算符优先级大于逻辑运算符
(5)位运算符
7个运算符号: &(与)、|(或)、 ^(异或)、<<(左移)、>>(右移)、>>>(无符号右移)、~(取反)
在了解每个运算符的运算规则前我们要先了解,位运算符运算的是什么东西?
位运算符针对的是整数,运算的对象是数据的补码。
数字之间的位运算:(数字必须是二进制才行)。
运算符左右两侧是数字那么结果就是数字。
那么我们就要了解一下补码是什么东西了。
- 原、反、补码
数据在计算机中是以补码形式来存储的。最高位是一个符号位:如果是正数,最高位为0,如果是负数,最高位为1。对于正数而言,原反补三码一致。负数的反码是在原码的基础上,最高位不变,其余位0变1,1变0,负数的补码是在反码的基础上+1。
举个例子:
比如说5,因为是正数那么它的原码/反码/补码都是一致的
00000000 00000000 00000000 00000101——原码/反码/补码
如果是-5
10000000 00000000 00000000 00000101——原码,负数高位为1
11111111 11111111 11111111 11111010——反码,最高位不变,其余位0变1,1变0
11111111 11111111 11111111 11111011——补码,在反码的基础上+1
当然也可以逆向推理
11111111 11111111 11111111 11110111——补码
11111111 11111111 11111111 11110110——反码,那么反码就要在补码的的基础上-1
10000000 00000000 00000000 00001001——原码,最高位不变,其余位0变1,1变0
最后得到的就是-9
-
&(与)、|(或)、 ^(异或)
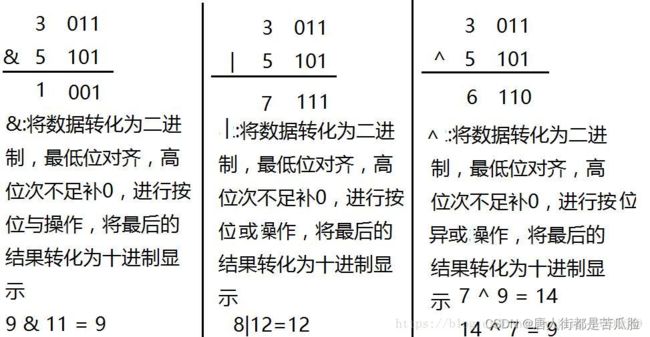
很明显我们可以利用&的特性来判断数据是否是奇偶数。 这个判断很简单,因为奇数的二进制数末尾一定是1,而偶数的末尾一定是0,那么我拿一个数和1相与,结果是0就是偶数,结果是1就是奇数。例如:4&1 4的二进制是:0100 1的二进制是:0001 结果就是0000转换为十进制也就是0表示这个是偶数 -
<<(左移)、>>(右移)、>>>(无符号右移)
首先要明白一点,这里面所有的操作都是针对存储在计算机中的二进制的操作,那么就要知道,正数在计算机中是用二进制表示的,负数在计算机中使用补码表示的。有符号移位
右移 >>
向右移动一位,按二进制形式把所有的数字向右移动对应的位数,低位移出(舍弃),高位的空位补符号位,即正数补零,负数补1。在一定范围内可以看做变成了原来的一半 。右移举个例子: 比如用12,因为是正数那么它的原码/反码/补码都是一致 00000000 00000000 00000000 00001100——原码/反码/补码 12>>2直接在原码上面进行操作 00000000 00000000 00000000 00000011——原码 得到的值是2^0+2^1=3 如果是-12 10000000 00000000 00000000 00001100——原码,负数高位为1 11111111 11111111 11111111 11110011——反码,最高位不变,其余位0变1,1变0 11111111 11111111 11111111 11110100——补码,在反码的基础上+1 -12>>2是在补码上进行操作的 11111111 11111111 11111111 11111101——补码 11111111 11111111 11111111 11111100——反码,那么反码就要在补码的的基础上-1 10000000 00000000 00000000 00000011——原码,最高位不变,其余位0变1,1变0 得到的值是-(2^0+2^1)=-3左移 <<
向左移动一位,按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。在一定范围内可以看做变成了原来的一倍。左移举个例子: 比如用5,因为是正数那么它的原码/反码/补码都是一致 00000000 00000000 00000000 00000101——原码/反码/补码 5<<2直接在原码上面进行操作 00000000 00000000 00000000 00010100——原码 得到的值是2^2+2^4=20 如果是-5 10000000 00000000 00000000 00000101——原码,负数高位为1 11111111 11111111 11111111 11111010——反码,最高位不变,其余位0变1,1变0 11111111 11111111 11111111 11111011——补码,在反码的基础上+1 -5<<2是在补码上进行操作的 11111111 11111111 11111111 11101100——补码 11111111 11111111 11111111 11101011——反码,那么反码就要在补码的的基础上-1 10000000 00000000 00000000 00010100——原码,最高位不变,其余位0变1,1变0 得到的值是-(2^2+2^4)=-20 这时候就有一个有意思的地方了,如果说左移一位表示乘2,那么左移几百位呢? 1<<100?这会等于多少?最后答案是16,1实际位移了100%32=4,也就是1<<4 可以看到100位明显是超过了int32位的最大位数了,但是左移的结果却并不是0,根据结果我们能猜的出来,虚拟机在做移位操作的时 候对移位位数根据当前数据类型做了取余操作。也就是如果是int类型变量左移,会把需要左移的位数和32取余,如果用的是long类型 的变量则会根据64位取余,值得注意的是像byte类型的变量在做移位操作的时候会被转换为int类型。
无符号移位
右移 >>>
无符号右移就是右移之后,无论该数为正还是为负,右移之后左边都是补上0为什么没有无符号左移?
主要是无符号左移<<<和左移<<是一样的概念,回忆一下左移是在后面补0,右移是在前面边补1或0,有无符号是取决于数的前面的第一位是0还是1,所以右移是会产生到底补1还是0的问题,而左移始终是在右边补,不会产生符号问题,所以没有必要无符号左移<<<。
(6)三元运算符
更据参与运算的数据的个数来进行分类
一元运算符有1个操作数。例如,递增运算符"++"就是一元运算符。
二元运算符有2个操作数。例如,除法运算符"/"有2个操作数。
三元运算符有3个操作数。例如,条件运算符"?:"具有3个操作数。
三元运算符 (三目运算符)
格式 x?y:z
整个表达式的结果是boolean类型,结果的表达式?结果是true 值1:结果是false 值2
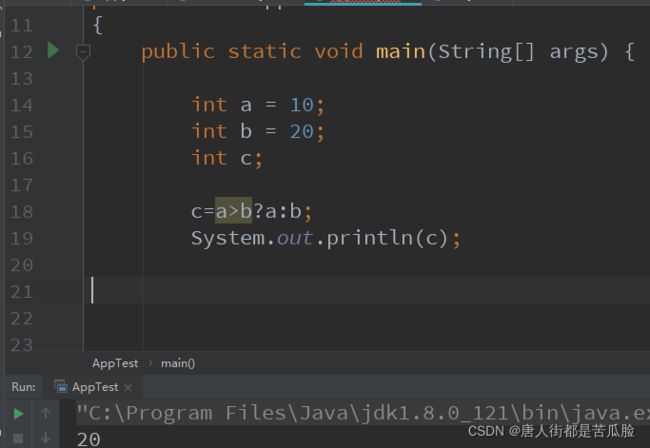
如果前面的表达式的结果是成立的(true) 将值1部分的值赋给了结果
如果前面的表达式的结果不成立 (false) 将值2部分的值赋给了结果
只能执行结果值1和值2 中的一个,不能同时执行
5、流程控制语句
(1)分支语句
分支语句有两种if语句和switch语句
①if语句
如果表达式的结果成立(true)执行一段代码,如果表达式的结果不成立 (false) 执行另一段代码,只能执行两段代码中的一段不能同时执行,if 语句有四种形式:单分支、双分支、多分支、嵌套if。
-
单分支
if (条件 boolean类型){ 条件成立时执行的代码块(多条代码) } -
双分支
if (条件 boolean类型){ 条件成立时执行的代码块(多条代码) }else{ 条件不成立时执行的代码块 } -
多分支,当条件情况比较多时 else if 进行情况判断
if (条件 boolean类型){ 条件成立时执行的代码块(多条代码) }else if(条件 boolean类型){ 条件不成立时执行的代码块 }else{ 条件都不成立时执行的代码块 } -
嵌套if
if (条件 boolean类型){ //条件成立时执行的代码块(多条代码) if (条件 boolean类型){ 条件成立时 执行的代码块(多条代码) }else{ 条件不成立时执行的代码块 } }else{ 条件都不成立时执行的代码块 }
注意:
1、if分支语句中去掉括号,则对第一行代码有效
2、else不能单独使用
①switch语句
switch分支: 进行值的匹配的----------理解为开关
//格式:
switch(表达式){
case 值:
//当表达式中的值等于case的值时 执行case中的代码
break; //代表case结束
case 值:
//当表达式中的值等于case的值时 执行case中的代码
break; //代表case结束
default:
//条件不满足时 默认的情况 (默认执行的一段代码)
//case中没有匹配到值 执行这的代码
}
注意:
1、default默认会放在末尾 (也可以放到第一个),不管case写在default上还是下 都先执行case (case优先级高于default)
2 、switch(可以放的数据类型) byte、short、int、char、String
3、 case条件结束,如果没有加break,case就会继续向下执行-----------------case穿透,要么执行到下一个break结束,要么执行到default结
束
使用if和switch 选择:
如果进行条件是否成立的判断,用if---------------编程时多
如果比较少的几个值进行配置,用switch-----------编程相比较少
(2)循环语句
针对的是一句代码需要重复多次输出,简化后就是循环了
循环引出:
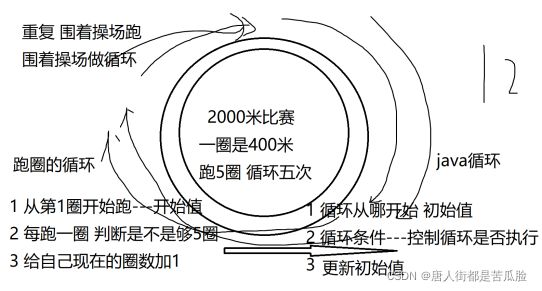
①循环语句
for循环优点:可以把三个要素写再一起 (不容易丢)
Java循环三个必备要素:循环初始值(从哪开始);循环条件(循环什么情况下执行 );更新初始值
//格式 :
for(初始值;循环条件;更新初始值){
循环体(满足循环时 做什么)
}
注意:
1、 如果忘了更新初始值,循环条件恒成立 ,循环一直执行 ,就会死循环。(for(;;){} 也是死循环 )
2、变量的作用域(变量的有效作用范围)(变量在哪可以用),找变量作用域的方式: 找包含定义变量最近一层的{} ;找变量定义时是不是(循环的//方法的)一部分,如果是他的作用域就是当前的循环或者方法。
3、变量作用域使用:在循环外要不要再用这个值,如果要用,提取变量定义,放到main中定义;如果只需要再循环中使用 不用提取
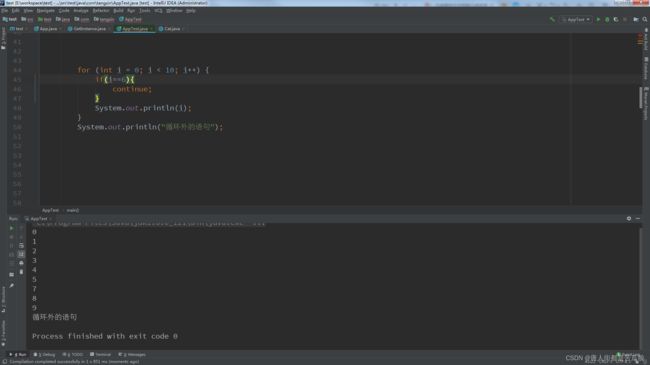
4 、循环手动结束
continue:当次循环 (循环体)不执行,不影响下一次执行
break:循环结束 不影响循环后代码的执行
return:方法结束
continue:到6的时候跳过了6的输出,不影响后面的执行
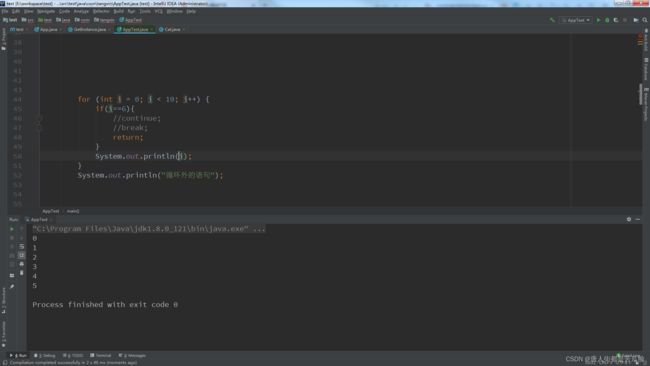
break:循环到6的时候跳出了当前循环,执行循环外的语句

return:循环到6的时候跳出了当前整个方法,所以也就结束了
——————————————————————————————————————————————————————
之后偶尔更新吧