X86汇编语言从实模式到保护模式06:从1加到100并显示结果
目录
1. 显示字符串
2. 计算1到100的累加和
3. 累加和数位的分解与显示
3.1 栈的概念
3.2 栈的初始化
3.3 栈的操作
3.3.1 压栈操作(push)
3.3.2 出栈操作(pop)
3.4 栈调试实例
3.4.1 栈初始化后状态
3.4.2 数据压栈后状态
3.4.3 数据出栈后状态
3.5 栈使用注意事项
3.6 逻辑或指令or
3.7 逻辑与指令and
4. 8086处理器的寻址方式
4.1 寻址方式概述
4.2 非内存寻址
4.2.1 寄存器寻址
4.2.2 立即数寻址
4.3 内存寻址
4.3.1 直接寻址
4.3.2 基址寻址
4.3.3 变址寻址
4.3.4 基址变址寻址
1. 显示字符串
jmp near start ;越过数据区
message db '1+2+3+...+100=' ;声明要显示的字符串
start:
mov ax,0x7c0 ;设置数据段的段基地址
mov ds,ax
mov ax,0xb800 ;设置附加段基址到显示缓冲区
mov es,ax
;以下显示字符串
mov si,message ; 源地址偏移为message汇编地址
mov di,0 ; 目的地址偏移为显存起始地址
mov cx,start-message ; 循环次数为要显示的字节数
@g:
mov al,[si]
mov [es:di],al ;要显示的字符
inc di ;递增显存索引
mov byte [es:di],0x07 ;设置显示属性
inc di ;递增显存索引
inc si ;指向下一个要显示的字符
loop @g ;构成循环示例程序中声明字符串的方式更加方便直接,在汇编阶段,汇编器会将他们拆开,以形成一个个单独的字节
2. 计算1到100的累加和
;以下计算1到100的和
xor ax,ax ;清空AX寄存器,用于保存累加和
mov cx,1 ;加数
@f:
add ax,cx
inc cx
cmp cx,100
jle @f ;当CX <= 100,继续循环这里需要注意,AX寄存器可以容纳的无符号数最大为65535,此处累加和为5050,所以不会越界
说明:如何求1到1000的累加和
1到1000的累加和为500500,超过了AX寄存器所能容纳的无符号数范围,所以需要使用DX : AX保存累加和,同时需要使用ADC指令,处理低16位累加可能产生的进位
示例代码如下,
xor dx, dx ;累加和的高16位
xor ax, ax ;累加和的低16位
mov cx, 1 ;加数
@f:
add ax, cx
adc dx, 0 ;和0相加并加上进位
inc cx
cmp cx, 1000
jle @f3. 累加和数位的分解与显示
;以下计算累加和的每个数位
xor cx,cx ;设置堆栈段的段基地址
mov ss,cx ;ss = 0x0
mov sp,cx ;sp = 0x0
mov bx,10 ;分解数位时使用的除数
xor cx,cx ;保存分解的数位个数
@d:
inc cx
xor dx,dx ;清空DX寄存器,AX构成被除数
div bx
or dl,0x30 ;将数位转换为数字字符
push dx ;将分解出的数位数字字符入栈
cmp ax,0
jne @d ;如果商不为0,则继续分解;否则不再分解
;以下显示各个数位
@a:
pop dx ;分解数位从高位出栈
mov [es:di],dl ;显示字符
inc di
mov byte [es:di],0x07 ;设置显示属性
inc di
loop @a ;CX中保存了分解的数位个数,正好作为循环控制变量3.1 栈的概念
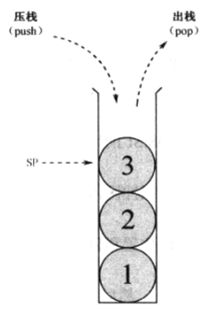
① 栈(Stack)是一种数据结构,数据的存取只能从一端进行,具有后进先出(Last In Firtst Out,LIFO)的特性
② 分解整数时从低位分解,从高位显示,正好符合栈的特性
3.2 栈的初始化
① 和代码段、数据段和附加段一样,栈也被定义成一个内存段,即栈段(Stack Segment)
② 栈段由SS寄存器提供段地址,SP寄存器提供偏移地址
③ 在示例程序中,将SS & SP寄存器均设置为0(即栈段与代码段重叠),则栈的范围为[0x0000 : 0x0000] ~ [0x0000 : 0xFFFF]
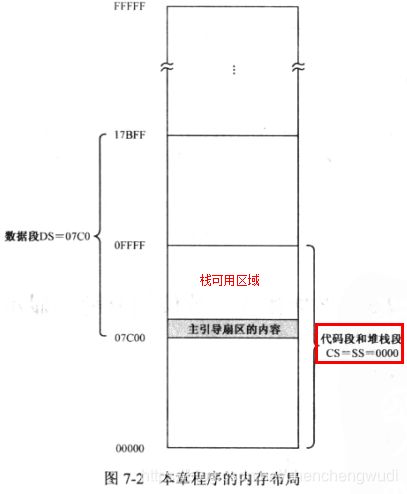
说明:栈的可用范围
① 主引导扇区使用的内存范围为[0x0000 : 0x7C00] ~ [0x0000 : 0x7E00]
② 8086中使用满减栈,使用时从高地址向低地址推进,所以栈的可用范围为[0x0000 : 0x7E00] ~ [0x0000 : 0xFFFF],约32KB
只要栈的使用限制在可用区域范围内,就不会影响到主引导扇区的内容
3.3 栈的操作
3.3.1 压栈操作(push)
push指令格式如下,
push r/m说明1:在16位的8086处理器上,push指令的操作数必须是16位的寄存器或内存单元
push al ;非法
push ax ;合法
push byte [0x2002] ;非法
push word [0x2002] ;合法需要注意的是,虽然8086处理器push指令的操作数只能是16位的,但是push word [0x2002]指令中的word关键字是必须的,因为后续的32位和64位处理器允许压入字、双字或四字
说明2:push指令执行过程
① SP = SP - 操作数的大小(字节)
② 根据[SS : SP]生成物理地址
③ 将操作数写入上述地址
说明3:push指令不影响任何标志位
3.3.2 出栈操作(pop)
pop指令格式如下,
pop r/m说明1:同样地,在16位的8086处理器上,pop指令的操作数也必须是16位的寄存器或内存单元
说明2:pop指令执行过程
① 根据[SS : SP]生成物理地址
② 从上述地址处取得数据,存入由操作数提供的目标地址处
③ SP = SP + 操作数的大小(字节)
说明3:pop指令也不影响任何标志位
3.4 栈调试实例
我们调试如下示例程序,
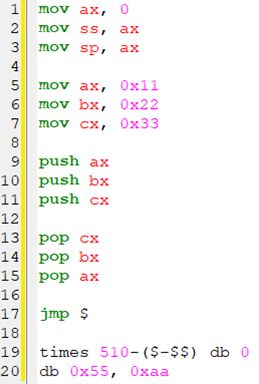
3.4.1 栈初始化后状态
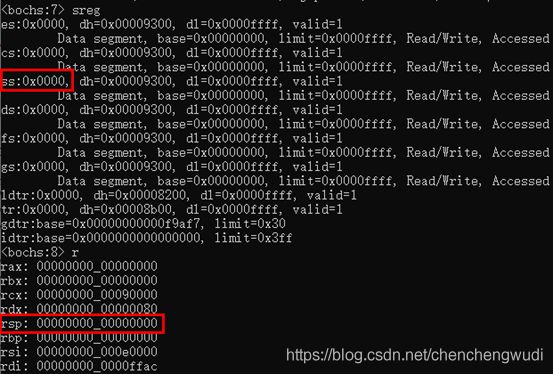

说明:print-stack命令可以基于当前的[SS : SP]打印栈顶的16个字
![]()
3.4.2 数据压栈后状态
将AX寄存器中的值压栈后,状态如下图所示,

说明1:第一次执行压栈操作时的内存状态,如下图所示,

可见将SP寄存器初值设置为0x0000,减去操作的长度2B后数值绕回,首次压栈时SP寄存器的值为0xFFFE
说明2:将AX、BX、CX寄存器的值均压栈后,状态如下图所示,
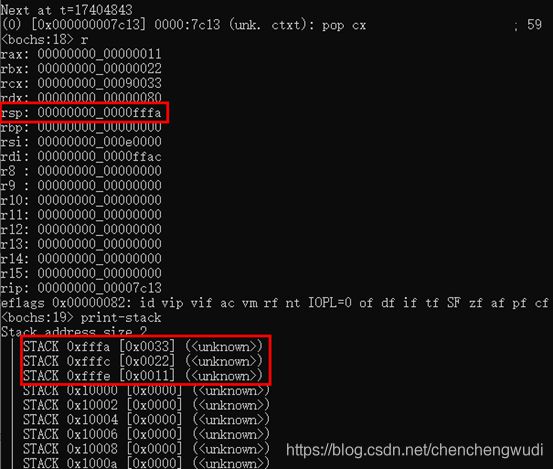
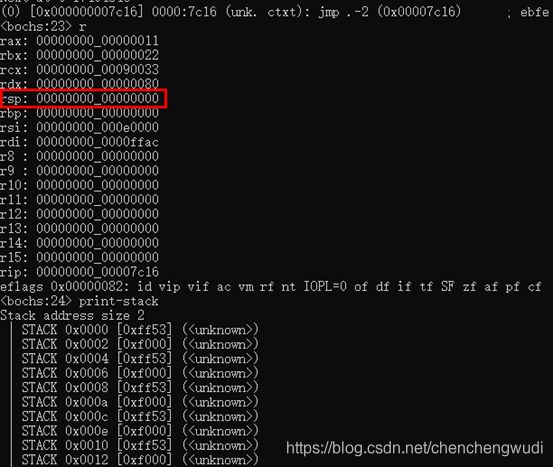
3.4.3 数据出栈后状态
可见栈恢复到了使用前的状态
3.5 栈使用注意事项
① 栈本质上也是普通的内存区域,之所以使用push和pop指令来访问,是因为我们将他看成栈。而push和pop操作可以简化对栈的操作
② 要注意保持栈的平衡,push和pop指令的调用要对称
③ 在编写程序前,必须充分估计所需要的栈空间,以防止破坏有用的数据,特别是在栈和其他段属于同一个段的时候
④ 尽管不能完全阻止程序中的错误,但是通过将栈定义到一个单独的64KB段,可以使错误仅局限于栈,而不破坏其他段的有用数据
因为即使栈使用错误,SP寄存器的内容也永远在0x0000 ~ 0xFFFF之间来回滚动
3.6 逻辑或指令or
逻辑或指令格式如下,
or r/m, r/m/imm说明1:示例程序中通过逻辑或达到加0x30的效果,是一种特殊情况下的用法,作者只是想引入该指令
or dl,0x30 ;将数位转换为数字字符此处之所以可行,是因为dl中保存的是除法后的余数,也就是分解出的位数,他们在0x0 ~ 0x9之间,所以高4位为0
说明2:逻辑或指令对标志位的影响
① OF = 0,CF = 0
② SF、ZF和PF依据计算结果而定
③ AF的状态未定义
3.7 逻辑与指令and
逻辑与指令格式如下,
and r/m, r/m/imm逻辑与指令对标志位的影响与逻辑或指令相同
4. 8086处理器的寻址方式
4.1 寻址方式概述
寻址方式(Addressing Mode)就是如何找到要操作的数据,以及如何找到存放操作结果的地方
4.2 非内存寻址
非内存寻址方式,就是寻址过程中无需访问内存。传统上,非内存寻址的速度较快
4.2.1 寄存器寻址
操作数位于寄存器中,可以从寄存器中取得
mov ax, cx
inc dx4.2.2 立即数寻址
操作数位于指令中,是指令的一部分
add bx, 0xf000
mov dx, label_a说明:标号本质上是数字,代表他所在位置的汇编地址,在汇编阶段会被转换成一个立即数
4.3 内存寻址
① 内存寻址是非常重要的寻址方式,因为处理器的寄存器有限(寄存器寻址的缺点),且我们不可能总是知道要操作的数是多少(立即数寻址的缺点)
② 8086处理器通过[段地址 : 偏移地址]的方式访问内存,而段地址由段寄存器提供,所以偏移地址要由指定来提供
因此,所谓内存寻址,就是寻找偏移地址,即如何在指令中提供偏移地址
③ 偏移地址也称为有效地址(Effective Address,EA)
4.3.1 直接寻址
直接寻址的偏移地址为一个具体的数值
mov ax, [0x2002]
xor byte [es:label_a], 0x054.3.2 基址寻址
基址寻址使用BX或BP寄存器提供偏移地址
add byte [bx], 0x55
mov ax, [bp]说明1:使用BX寄存器时,默认使用DS段寄存器;使用BP寄存器时,默认使用SS段寄存器
说明2:机制寻址允许在基址寄存器的基础上增加一个偏移量
[bx + 偏移量]
[bp + 偏移量]偏移量仅用于在指令执行时形成有效地址,不会改变BX或BP寄存器的值
4.3.3 变址寻址
变址寻址与基址寻址类似,只是使用的是变址寄存器SI和DI,同时也支持在编址寄存器的基础上增加一个偏移量
[SI]
[DI]
[SI + 偏移量]
[DI + 偏移量]说明:使用变址寄存器时默认使用DS段寄存器
4.3.4 基址变址寻址
基址变址寻址就是使用一个基址寄存器,外加一个变址寄存器,还可以增加一个偏移量。合法的基址变址寻址方式如下,
[bp/bx + si/di]
[bp/bx + si/di + 偏移量]说明:当基址变址寻址中使用BP寄存器,默认使用SS段寄存器