ARMv8体系结构基础03:加载和存储指令
目录
1 A64指令集概述
1.1 A64指令集特征
1.1.1 指令定长
1.1.2 可使用64位指针
1.1.3 使用一致的编码结构(consistent encoding scheme)
1.1.4 指令中可使用更大范围的常数
1.1.5 数据类型更简单
1.1.6 指令中可使用更大的偏移量(long offset)
1.2 寄存器在指令中的编码
1.3 A64指令集的2种形式
1.4 条件执行
1.5 其他内容
2 Load / Store指令详解
2.1 概述
2.2 Load / Store指令寻址方式
2.2.1 Offset modes
2.2.2 Index modes
2.2.3 PC-relative modes
2.3 LDR / STR(immediate)指令
2.3.1 LDR(immediate)指令编码
2.3.2 STR(immediate)指令编码分析
2.3.3 LDR / STR(immediate)指令实验
2.3.4 LDR(register)指令编码分析
2.3.5 LDR(register)指令编码验证
2.3.6 STR(register)指令编码分析
2.3.7 LDT / STR(register)指令实验
2.3.8 实验:实现memcpy函数
2.3.9 LDR(literal)指令编码分析
2.3.10 LDR(literal)指令编码验证
2.3.11 LDR伪指令
2.3.12 LDR(literal)/ LDR伪指令实验
2.3.13 LDR / STR指令数据长度问题
2.3.14 LDR / STR多数据
2.3.15 实验:实现memset函数
2.3.16 使用ldr / str指令访问寄存器的注意事项
3 MOV指令详解
3.1 MOV(to/from SP)指令编码分析
3.2 MOV(to/from SP)指令编码验证
3.3 MOV(inverted wide immediate)指令编码分析
3.4 MOV(inverted wide immediate)指令编码验证
3.5 MOV(wide immediate)指令编码分析
3.6 MOV(wide immediate)指令编码验证
3.7 MOV(bitmask immediate)指令编码分析
3.8 MOV(bitmask immediate)指令编码验证
3.9 MOV(register)指令编码分析
3.10 MOV(register)指令编码验证
1 A64指令集概述
1.1 A64指令集特征
A64指令集由ARMv8体系结构引入,在AArch64状态下执行,该指令集主要特征如下,
1.1.1 指令定长
所有A64指令长度均为32位
注意:指令长度为32位并不影响指令访问64位的地址空间,因为指针可以存储在64位寄存器中。当然,编码到指令中的偏移量offset还是会受到32位指令长度的限制
1.1.2 可使用64位指针
1. A64指令集可以使用64位指针(存储在64位寄存器中)访问内存
2. 可以提供更大的虚拟地址空间
1.1.3 使用一致的编码结构(consistent encoding scheme)
A32指令集中某些指令的编码(e.g. 为了让LDR & STR指令支持半字操作)与主流编码结构不同,而A64使用了一致的编码结构
1.1.4 指令中可使用更大范围的常数
1. 算术运算指令(arithmetic instruction)一般接受12位立即数
2. 逻辑运算指令(logical instruction)一般接受32位或64位常数(但是在编码上有限制)
3. MOV指令接受16位立即数
4. 地址生成指令(address generation instruction)产生的地址可以以4KB页对齐
1.1.5 数据类型更简单
A64指令集本身就能处理64位的有 / 无符号数据类型,因此可以更好地支持其他编程语言(e.g. C和Java)中的64位整型
1.1.6 指令中可使用更大的偏移量(long offset)
A64指令集的PC-relative寻址方式提供了更大的偏移量,可以在更大范围内跳转和访问内存,具体如下
1. PC-relative寻址文字池(literal pools)的偏移量为±1MB
2. PC-relative有条件跳转(conditional branch)的偏移量为±1MB,基本可以满足在单个函数内的跳转
3. PC-relative无条件跳转(unconditional branch)的偏移量为±128MB,基本可以满足在一个加载模块内的跳转(e.g. 可执行程序、函数库)
说明1:什么是literal pools
① literal pools是被编码在指令流中的数据块
② literal pools不会被执行,而是会被周围的指令以PC-relative的寻址方式访问
③ literal pools中一般包含不能被mov指令直接使用的立即数(因为mov指令对可使用的立即数有编码限制)
说明2:增加PC-relative跳转范围,可以减少对veneers(胶合)函数的使用
说明3:ARMv8体系结构中也提供了A32和T32指令集,用于与ARMv7体系结构保持向后兼容,同时也进行了一些改进
1.2 寄存器在指令中的编码
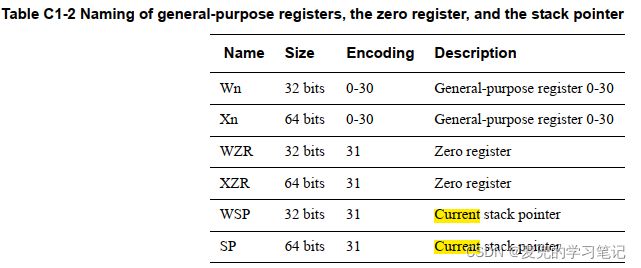
1. A64指令集中有X0 ~ X30共31个64位通用寄存器
2. 可以单独使用其中的低32位,即W0 ~ W31。读取低32位时,高32位被忽略;写入低32位时,高32位被清零
3. 没有X31 / W31寄存器,依据不同指令,在指令中编码为31的寄存器是零寄存器或当前栈指针寄存器
1.3 A64指令集的2种形式
A64指令集中的大多数指令有2种形式,分别用于操作32位和64位操作数,可通过指令中使用的寄存器区分
1. 如果使用Xn寄存器,则使用的是64位形式
2. 如果使用Wn寄存器,则使用的是32位形式
说明:使用32位形式的注意事项
① 循环右移(ROR指令)将移出的位被插入操作数的bit [31]而不是bit [63]
② 根据低32位的计算结果设置条件标志位
③ 注意操作寄存器低32位时对高32位的影响
1.4 条件执行
1. 在A64指令集中,并不是所有指令都可以条件执行,而是只有特定指令可以(e.g. B指令)
2. 具体的条件码如下图所示

说明:在ARMv7体系结构中,几乎所有指令都可以条件执行,在指令编码时条件码占据4bit空间。当时引入条件执行的目的,是为了减少分支操作,从而减少清空流水线
在A64指令集中不再支持所有指令条件执行,是因为条件执行带来的收益不足以弥补耗费大量指令编码空间的代价
1.5 其他内容
1. A64指令集汇编语言支持全大写或全小写,但是不能混用
2. 程序和数据标号(label)大小写敏感
说明:GCC支持汇编语言大小写混用,但肯定是不推荐的
2 Load / Store指令详解
2.1 概述
1. 与之前的ARM体系结构相同,ARMv8体系结构也是Load / Store架构。也就是说,数据处理指令不能直接操作内存中的数据,而是要先加载(Load)到寄存器中,处理之后再存储(Store)到内存中
2. Load / Sotre指令的基本形式如下,
LDR Rt, // 将存储器地址的数据加载到目标寄存器中
STR Rn, // 将源寄存器中的值存储到存储器地址处 3. 内存访问对齐检查
① 除了exclusive access和ordered access,其他Load / Store指令都支持对normal memory的非对齐访问
② 取指时对PC寄存器有对齐检查,要求4B对齐,即取指地址的bit [1:0]均为0
非对齐取指会产生异常
③ 入栈出栈时对SP寄存器有对齐检查,要求16B对齐,即访问地址的bit [3:0]均为0。也就是说,当将SP作为基址寄存器使用时,需要16B对齐
非对齐访问会产生异常,但是SP对齐检查可以关闭
说明:Rt / Rn为通用寄存器标记,根据指令的32位和64位形式,被替换为Xn和Wn
2.2 Load / Store指令寻址方式
2.2.1 Offset modes
1. 有一个64位的基址寄存器(base register)
2. 将一个立即数 / 寄存器值 / 修改后的寄存器值加到64位的基址寄存器上,这个加上的数就是offset

说明1:上图中标记的指令格式有误,应为
LDR X0, [X1, X2, LSL #3] // LSL和#3之间没有逗号说明2:基址寄存器必须是64位寄存器
说明3:当加到64位基址寄存器的数值使用32位寄存器存储时,需要通过零扩展(zero-extension,使用UXTW指示符)或符号扩展(sign-extension,使用SXTW)指令扩展为64位参与运算
说明4:对于移位值的限制
移位值必须是0或者log2(8) = 3,其中
① 0是默认值
② log2(8)的描述是log2 of the access size in byte,在A64指令集中,access size为8,所以移位值为3
2.2.2 Index modes
1. index modes的寻址方式与offset modes类似,但是会更新基址寄存器的值
2. 只能以立即数的形式提供offset
3. index modes又分为pre-index和post-index,其中,
① pre-index先更新基址寄存器,后访问内存
② post-index先访问内存,后更新基址寄存器

说明:从后续指令编码分析可知,在index modes寻址模式下,指令编码中要包含9位立即数,已经无法再容纳一个寄存器编码
2.2.3 PC-relative modes
1. 以PC作为基地址寄存器
2. 将标号(label)编码为到PC的偏移量offset
3. 在寻址时,将这个偏移量加到PC上

说明1:PC-relative modes寻址方式基于当前PC,因此是地址无关操作
说明2:A64指令集引入PC-relative modes寻址模式是因为在A64指令集中,PC不再是通用寄存器,不能直接访问
在ARMv7体系结构中,PC属于通用寄存器,可以直接将PC作为基址寄存器。PC-relative modes寻址方式达到了同样的效果
说明3:标号(label)本质上是一个数值,即符号地址(链接地址),该地址需要4B对齐
说明4:根据不同的寻址模式,以及提供offset的不同方式,LDR / STR指令有不同的编码方式

![]()
此处指令编码方式与寻址方式的对应关系如下,
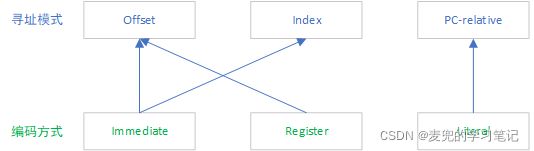
虽然指令的编码方式不同,但是均使用STR / LDR助记符,从而减轻了程序员的负担
2.3 LDR / STR(immediate)指令
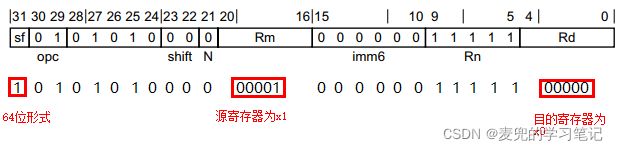
2.3.1 LDR(immediate)指令编码
如上文所述,immediate提供offset的方式可以用于offset modes和index modes寻址方式,他们对应的编码方式各不相同
2.3.1.1 Post-index(后变基模式)编码分析
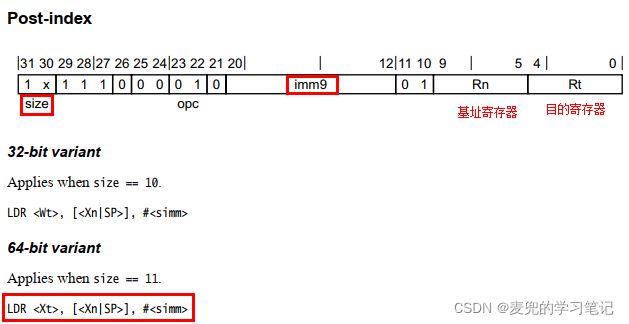
1. size字段体现指令的32位形式还是64位形式
2. 可以以SP寄存器作为基址寄存器,此时就是栈操作
3. #
2.3.1.2 Post-index(后变基模式)编码验证
编译如下指令,
ldr x0, [x1], #8对应机器码如下,
![]()

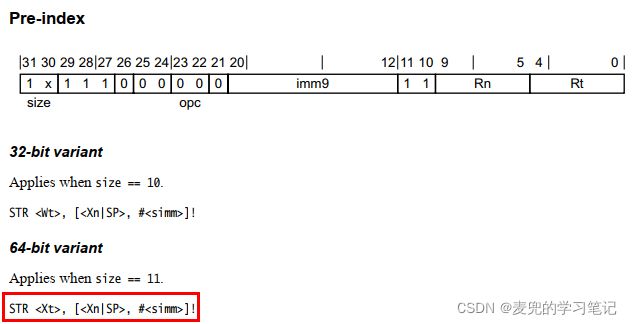
2.3.1.3 Pre-index(前变基模式)编码分析

Pre-index的编码方式与Post-index类似
2.3.1.4 Pre-index(前变基模式)编码验证
编译如下指令,
ldr x0, [x1, #8]!对应机器码如下,
![]()

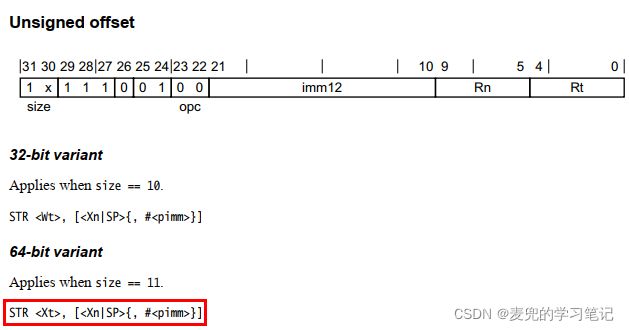
2.3.1.5 Unsigned offset(偏移量模式)编码分析

#
1. 对于32位形式,表示0 ~ 16380之间的4的倍数,此时imm12字段被编码为
positive imm12的取值范围为0 ~ 4095,以4为倍数,则可表示的取值范围为0 ~ 16380
2. 对于64位形式,表示0 ~ 32760之间的8的倍数,此时imm12字段被编码为
positive imm12的取值范围为0 ~ 4095,以8为倍数,则可表示的取值范围为0 ~ 32760
2.3.1.6 Unsigned offset(偏移量模式)编码验证
1. 通用寄存器操作
编译如下指令,
ldr x0, [x1, #8]对应机器码如下,
![]()

可见imm12字段编码的确实是#
2. 栈寄存器操作
编译如下指令,
ldr x0, [sp, #8]对应机器码如下,
![]()

可见SP作为基址寄存器被编码为31
3. 偏移量合法性验证
如上文所述,imm12为正数且被编码为#
① #
编译如下指令,
ldr x0, [sp, #-8]经过验证,可以编译通过,对应的机器码如下,
![]()
可见ldr指令被替换为ldur指令,该指令有9位的#
② #
编译如下指令,
ldr x0, [sp, #7]经过验证,可以编译通过,对应的机器码如下,
![]()
可见此处的ldr指令也被替换为ldur指令
说明:ldur指令
上面的验证中,ldr指令均被编译器替换为ldur指令,那我们就来分析一下该指令的编码

2.3.2 STR(immediate)指令编码分析
STR(immediate)的指令编码方式与LDR(immediate)类似,各字段编码方式相同,此处不再赘述

2.3.3 LDR / STR(immediate)指令实验
2.3.3.1 实验代码框架
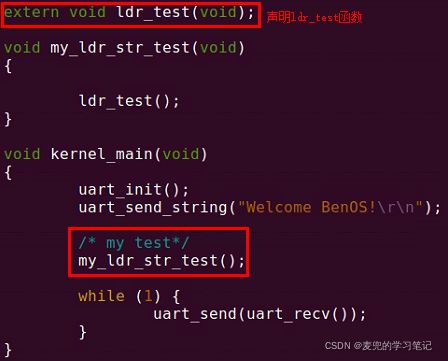
1. 在src/asm_test.S文件中,以汇编语言定义ldr_test函数,同时将该函数设置为全局可见
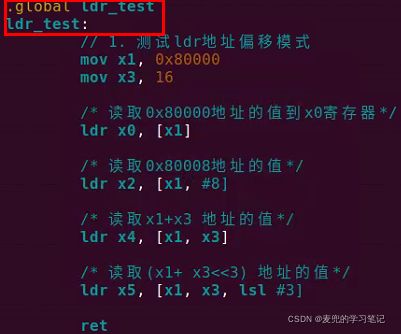
2. 在src/kernel.c文件中,声明ldr_test函数并进行调用
2.3.3.2 Post-index模式实验
2.3.3.2.1 实验代码
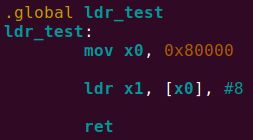
2.3.3.2.2 调试分析
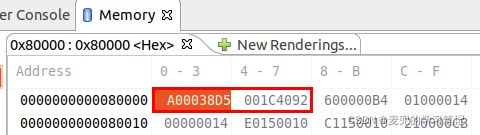
ldr指令执行完成后,寄存器状态如下,
![]()
加载到x1寄存器中的值与内存中一致,
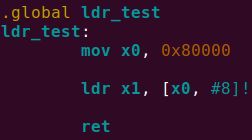
2.3.3.3 Pre-index模式实验
2.3.3.3.1 实验代码
2.3.3.3.2 调试分析
ldr指令执行后,寄存器状态如下,
![]()
加载到x1寄存器中的值与内存中一致,

2.3.3.4 Unsigned offset模式实验
2.3.3.4.1 实验代码

2.3.3.4.2 调试分析
ldr指令执行后,寄存器状态如下,
![]()
加载到x1寄存器中的值与内存中一致,

2.3.4 LDR(register)指令编码分析
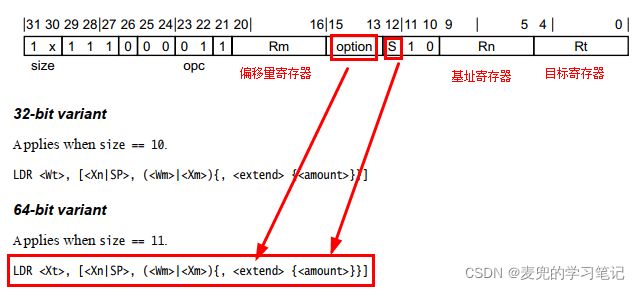
1. LDR(register)指令的特征,就是使用寄存器提供偏移量offset,同时可以对该寄存器进行扩展或移位操作
2. 提供偏移量offset的寄存器可以是32位(Wm)也可以是64位(Xm),编码在Rm字段
3.

其实可以发现,在
4.
① 对于32位形式,取值为0(默认值)或2(log2(4))
② 对于64位形式,取值为0(默认值)或3(log2(8))
5. 需要注意,在
2.3.5 LDR(register)指令编码验证
1. 仅有offset寄存器字段
编译如下指令,
ldr x0, [x1, x2]对应机器码如下,
![]()

可见编码与手册描述是一致的,option字段的默认值为LSL;S字段的默认值为0,即移位值为0
2. 包含扩展字段
编译如下指令,
ldr x0, [x1, w2, SXTW]对应机器码如下,
![]()

3. 包含移位字段
编译如下指令,
ldr x0, [x1, x2, LSL #3]对应机器码如下,
![]()
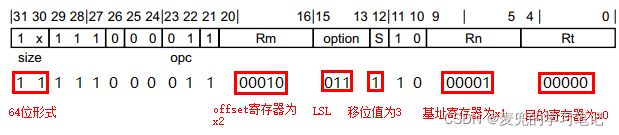
4. 同时包含扩展和移位字段
编译如下指令,
ldr x0, [x1, w2, SXTW #3]对应机器码如下,
![]()

说明:合法的移位值
根据手册,64位形式中,合法的移位值只有0和3。编译如下移位值不合法的指令,
ldr x0, [x1, x2, LSL #1]编译会报出移位值无效错误

2.3.6 STR(register)指令编码分析
STR(register)的指令编码方式与LDR(register)类似,各字段编码方式相同,此处不再赘述

2.3.7 LDT / STR(register)指令实验
2.3.7.1 实验代码
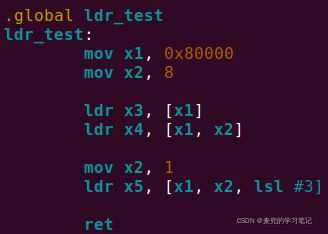
2.3.7.2 调试分析
1. ldr x3, [x1]指令执行后,寄存器状态如下,

加载到x3寄存器中的值与内存中一致,

2. ldr x4, [x1, x2]指令执行后,寄存器状态如下,

加载到x4寄存器中的值与内存中一致,
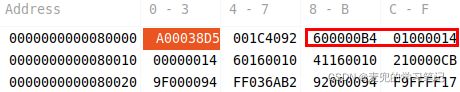
3. ldr x5, [x1, x2, lsl #3]指令执行后,寄存器状态如下,

由于x1中的值为1,左移3位后为8,所以从内存中加载的值与上一条指令一样
2.3.8 实验:实现memcpy函数
2.3.8.1 实验要求
使用ldr / str指令实现memcpy函数,从0x80000地址拷贝32个字节到0x200000地址处
2.3.8.2 实验代码
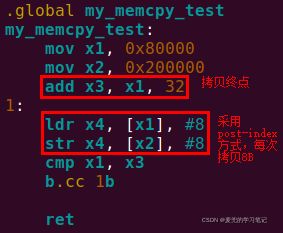
说明:b.cc执行条件码
① b.cc执行的条件码CC表示Carry Clear,也就是C标志位没有被置位
② 如01. ARMv8体系结构简介 chapter 3.3.3的讨论,对于SUBS指令(CMP指令通过SUBS指令实现),当没有发生算术运算借位时,C标志位为1;当发生算术运算借位时,C标志位为0
所以,对于条件码CC,表示无符号数小于,符合跳转的条件为x1 < x3
2.3.8.3 调试分析
1. 第一次执行完cmp指令时,比较的值为0x80008和0x80020

cmp指令执行后,cpsr寄存器的值如下,
![]()

对应的C标志位为0,这也印证了之前的分析,即CMP指令在发生算术运算借位时,C标志位为0
2. 当需要跳过循环体时,可以使用u line_num命令,直接执行至该行号

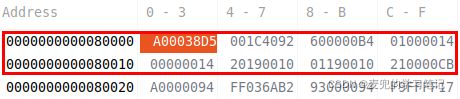
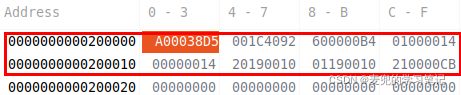
3. 拷贝完成后,源地址与目的地址处的内存状态如下,可见数据拷贝成功
2.3.9 LDR(literal)指令编码分析
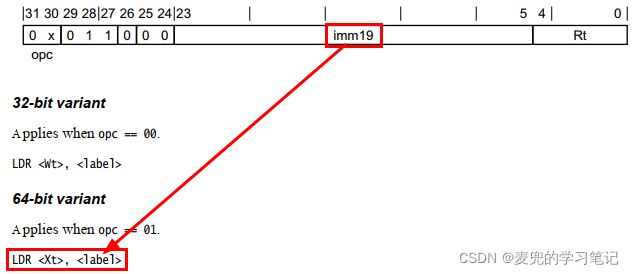
1.
2. 编码到imm19中的内容,为
3. 编码时以4B为单位,因此imm19可取值的范围为2^(19 + 2) = 2^21,体现在偏移量上就是±1MB
4. 最终是从[PC + imm19编码的偏移量]处加载值到目标寄存器中
2.3.10 LDR(literal)指令编码验证
1. label在指令之前
编译如下代码,
label:
mov x0, x0
ldr x0, label对应机器码如下,


① 当执行到ldr指令时,将PC - 4(越过mov指令),即可得到PC-relative的label地址
② 而且确实可以看出,PC-relative寻址是地址无关操作
2. label在指令之后
编译如下代码,
ldr x0, label
label:
mov x0, x0对应机器码如下,


当执行到ldr指令时,将PC + 4(越过ldr指令本身),即可得到PC-relative的label地址
2.3.11 LDR伪指令
2.3.11.1 伪指令概述
1. 伪指令是对编译器发出的命令,在对程序进行汇编的过程中由汇编器处理
2. 伪指令一般用于定义程序模式、定义数据、分配存储区、指示程序结束等功能,实现对汇编过程的控制
3. 伪指令可以不对应指令(这种情况也称作伪操作),也可以对应多条指令
2.3.11.2 LDR伪指令功能
1. LDR伪指令格式如下,
ldr Xt, =2. LDR伪指令主要用于加载立即数,
① 当要加载的立即数可以由MOV等指令编码时,则被编译为MOV等指令
② 当要加载的立即数不能由MOV等指令编码时,则使用literal pool实现
2.3.11.3 LDR伪指令验证
编译如下代码,
label:
mov x0, x0
ldr x0, =label对应的机器码如下,

可见此处被编译为LDR(literal)指令,加载到x0寄存器中的是label的链接地址
2.3.12 LDR(literal)/ LDR伪指令实验
2.3.12.1 实验代码
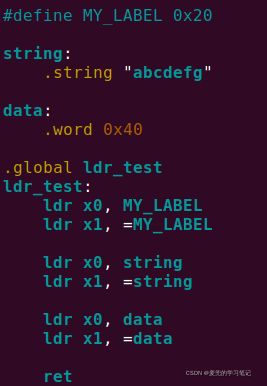
2.3.12.2 调试分析
2.3.12.3.1 MY_LABEL组ldr指令
1. MY_LABEL是一个宏定义(这种用法在实际程序中并不常见)
2. ldr指令执行前,pc值如下,
![]()
3. ldr指令执行后,x0寄存器值如下,
![]()
4. 我们来分析一下该指令的编码
![]()

可见在编码时,将MY_LABEL宏代表的0x20作为偏移量编码到指令的imm19字段
5. 因此这条ldr指令是从pc + 0x20 = 0x802bc + 0x20 = 0x802dc处加载数据到寄存器,加载到寄存器中的值与内存中一致,即0x000802B000000000

2.3.11.3.2 MY_LABEL组ldr伪指令
1. ldr伪指令执行后,x1寄存器值如下,
![]()
2. ldr伪指令加载宏定义所代表的立即数到寄存器
2.3.12.3.3 string组ldr指令
1. ldr指令执行后,x0寄存器值如下,
![]()
2. ldr指令从string标号处加载数据到寄存器
2.3.12.3.4 string组ldr伪指令
1. ldr伪指令执行后,x1寄存器值如下,
![]()
2. ldr伪指令加载string的链接地址到寄存器

2.3.12.3.5 data组ldr指令
1. ldr指令执行后,x0寄存器值如下,
![]()
2. ldr指令从data标号处加载数据到寄存器。需要注意的是,data处只定义了4B的word类型数据,而加载时是8B
![]()

2.3.12.3.6 data组ldr伪指令
1. ldr伪指令执行后,x1寄存器值如下,
![]()
2. ldr伪指令加载data的链接地址到寄存器
2.3.13 LDR / STR指令数据长度问题
2.3.13.1 LDR指令数据长度问题
当要加载的数据长度小于目标寄存器长度时,可以使用如下指令,

在指令编码上有如下形式,此处不再赘述
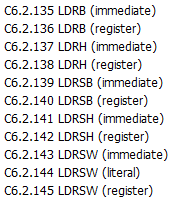
说明:上述指令的加载效果如下图所示

2.3.13.2 STR指令数据长度问题
当要存储的数据长度小于源寄存器长度时,可以使用如下指令,

可见只有加载时才存在是零扩展还是符号扩展问题,在存储时则无需考虑
2.3.14 LDR / STR多数据
2.3.14.1 概述
1. A64指令集中没有LDM和STM指令,而是提供了LDP和STP指令
2. LDP / STP指令用于读写一对(Pair)整型寄存器
3. LDP / STP指令允许非对齐访问
4. LDP指令的加载效果如下图所示,STP指令的存储效果与其类似,只是方向相反
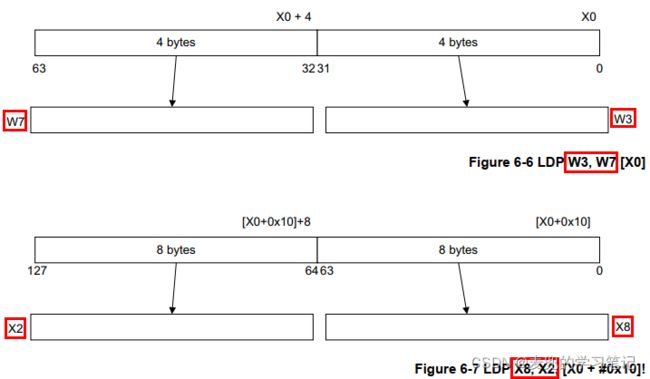
由上图可知,在使用LDP / STP指令加载和存储数据时,没有寄存器标号与内存地址的对应关系(ARMv7体系结构的LDM / STM指令有对应关系),而是第1个操作数对应低地址,第2个操作数对应高地址
2.3.14.2 LDP指令编码分析
LDP指令的编码方式分为Post-index、Pre-index和Signed offset三种,具体指令编码如下,




1. LDP指令用于一次性加载2个32位或64位寄存器
2. 基址寄存器必须是64位寄存器Xn,SP可以作为基址寄存器
3. #
① 对于32位形式,表示-256 ~ 252之间的4的倍数,此时imm7字段被编码为
imm7字段的取值范围为-64 ~ 63,以4为倍数,则可表示的取值范围为-256 ~ 252
② 对于64位形式,表示-512 ~ 504之间的8的倍数,此时imm7字段被编码为
imm7字段的取值范围为-64 ~ 63,以8为倍数,则可表示的取值范围为-512 ~ 504
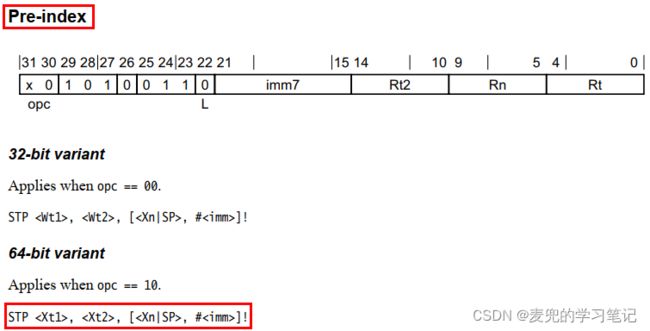
2.3.14.3 STP指令编码分析
STP指令的编码方式分为Post-index、Pre-index和Signed offset三种,具体指令编码如下



2.3.15 实验:实现memset函数
2.3.15.1 实验要求
1. 使用stp指令实现memset函数,函数原型为
void *memset(void *s, int c, sieze_t count);2. 对于内存地址s和count不是16B对齐的情况,需要优化实现
2.3.15.2 实验代码
1. 实现16B对齐情况下的memset函数

其中函数参数的传递遵循AAPCS规范
2. 实现按字节的memset函数

3. 实现可处理非16B对齐情况的memset函数
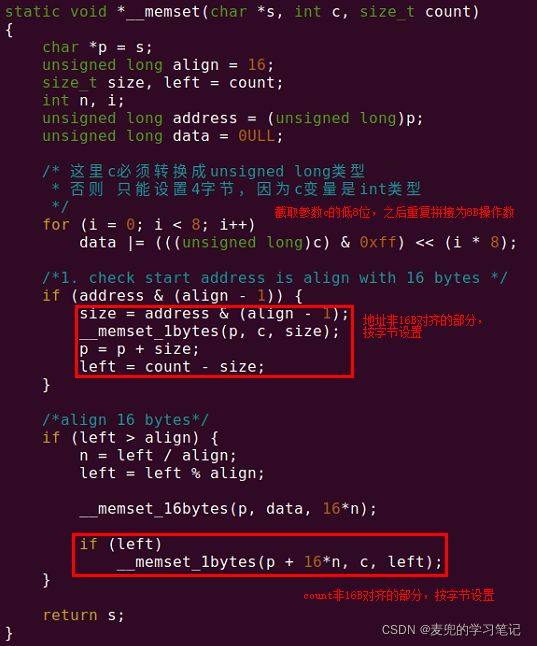
函数最后的调用方式如下,
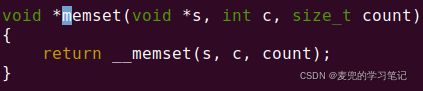
2.3.15.3 调试分析
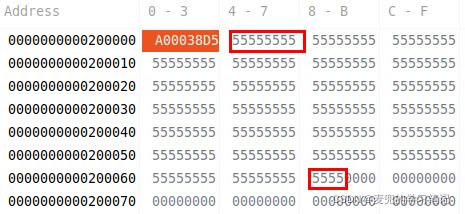
在实验代码中,以如下方式调用memset函数,可见起始地址s与count均为16B对齐

1. 调用进入__memset函数后,通过寄存器传递的参数符合预期

2. memset函数执行后,从0x200004 ~ 0x200069共102B被正确设置为0x55
说明:__memset_1bytes函数反汇编分析

2.3.16 使用ldr / str指令访问寄存器的注意事项
在ARM体系结构中,设备寄存器以MMIO的方式映射到物理地址空间,所以是使用ldr / str指令访问设备寄存器。目前大多数设备寄存器的长度为32位,因此在操作设备寄存器时,需要主要位宽
我们以树莓派串口初始化函数uart_init为例进行说明,
1. 树莓派串口寄存器的长度均为32位

2. C程序在访问串口寄存器时,使用readl & writel函数
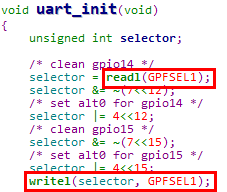
3. readl & writel函数在实现时,将操作限制在32位位宽
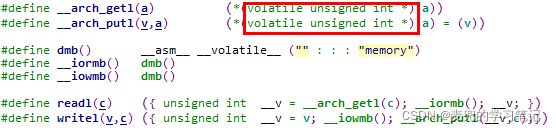
4. 从uart_init函数的反汇编结果可见,在编译后的指令中也将操作限制在32位位宽
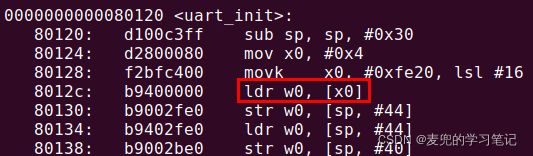
5. 如果不注意设备寄存器位宽问题,则可能导致相邻设备寄存器被设置
假设有如下代码,就会导致U_IBRD_REG寄存器及之后的一个寄存器也被设置
ldr x1, =U_IBRD_REG
mov x2, #26
str x2, [x1] // 正确形式应为str w2, [x1]3 MOV指令详解
3.1 MOV(to/from SP)指令编码分析

1. MOV(to/from SP)指令以ADD(immediate)指令实现
2. SP可以作为源寄存器,也可以作为目的寄存器
3.2 MOV(to/from SP)指令编码验证
1. to SP
编译如下指令,
mov sp, x0对应机器码如下,

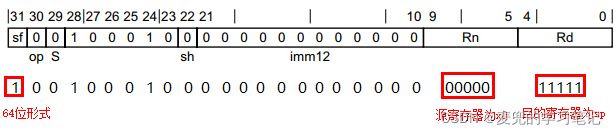
可见imm12字段在MOV(to/from SP)指令编码中没有使用
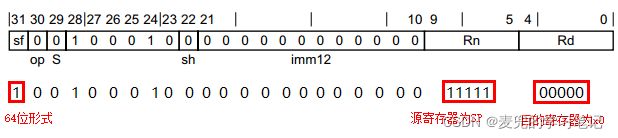
2. from SP
编译如下指令,
mov x0, sp对应机器码如下,
![]()
3.3 MOV(inverted wide immediate)指令编码分析

1. MOV(inverted wide immediate)指令以MOVN指令实现
2. #
① 对于32位形式,这是一个32位立即数,被编码在"imm16:hw"字段,其中不包含0xffff0000和0x0000ffff
② 对于64位形式,这是一个64位立即数,被编码在"imm16:hw"字段
3. 关于hw字段的编码,也因形式而异,
① 对于32位形式,#
② 对于64位形式,#
说明1:需要特别注意的是,对于mov Xn, #imm指令,对#imm立即数的形式是有要求的,编译器会尝试以各种方式生成该立即数。如果生成失败,则编译报错
对于MOV(inverted wide immediate)指令,就是以"imm16 + 移位 + 取反"的方式生成立即数
说明2:给出一个无法用MOV指令传输立即数的例子
mov x0, 0x12345678
对于这类立即数,可以用LDR伪指令加载
3.4 MOV(inverted wide immediate)指令编码验证
由于MOV(inverted wide immediate)指令是以"imm16 + 移位 + 取反"的方式生成立即数,那么我们就构造一个这样的立即数进行验证
编译如下指令,
mov x0, #0xffffffffffffffff对应机器码如下,
![]()

3.5 MOV(wide immediate)指令编码分析

1. MOV(wide immediate)指令以MOVZ指令实现
2. #
① 对于32位形式,这是一个32位立即数,被编码在"imm16:hw"字段
② 对于64位形式,这是一个64位立即数,被编码在"imm16:hw"字段
3. 关于hw字段的编码,也因形式而异,
① 对于32位形式,#
② 对于64位形式,#
说明:如上文所述,MOV(wide immediate)指令以"imm16 + 移位"的方式生成立即数,这又是一种生成立即数的方式
3.6 MOV(wide immediate)指令编码验证
编译如下指令,
mov x0, 0x50500000对应机器码如下,
![]()

3.7 MOV(bitmask immediate)指令编码分析
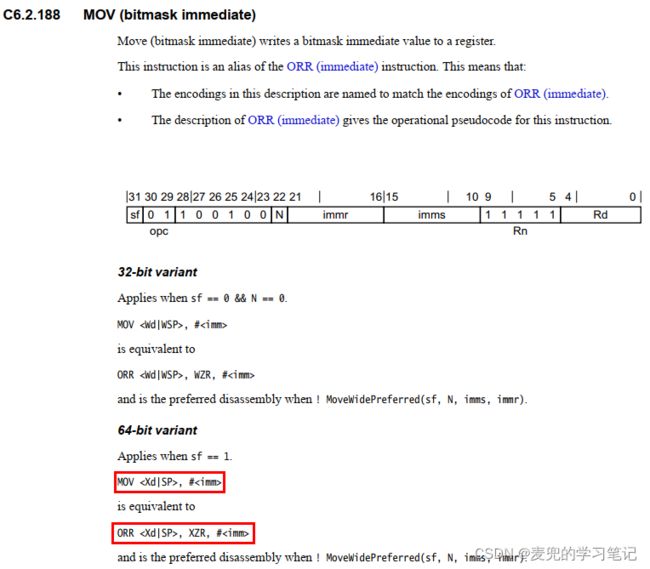
1. MOV(bitmask immediate)指令以ORR指令实现
2. #
① 对于32位形式,#
② 对于64位形式,#
3. 通过对零寄存器XZR和#
3.8 MOV(bitmask immediate)指令编码验证
编译如下指令,
mov x0, 0x00ffffff对应机器码如下,
![]()
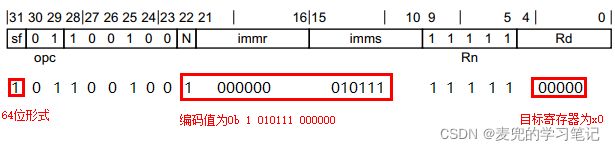
说明:关于bitmask immediate的编码尚未理解
3.9 MOV(register)指令编码分析

可见MOV(register)指令也是以ORR指令实现
3.10 MOV(register)指令编码验证
编译如下指令,
mov x0, x1对应机器码如下,
![]()