python文件处理-CSV文件的读取、处理、写入
什么是csv文件
csv是"Comma-Separated Values(逗号分割的值)"的首字母缩写,它其实和txt文件一样,都是纯文本文件。但csv文件可以显示为电子表格的样式,所以我们也可以把csv文件视为一种简化版的电子表格。
简化版是什么意思呢?回顾一下我们常见的Excel表格,不仅有“居中”排版,表格边框等样式,还有各种Excel公式等其他功能,这些功能在csv文件中是不存在的。
正如概念中强调的一样,csv文件是纯文本文件,它只能存储数据。
值得注意的是,csv文件有多种打开方式,如果你使用文本编译器(如记事本)打开它,它就会以文本形式显示;但如果你使用常用的office软件(Excel表格,WPS表格,Numbers表格)打开,csv就会直接显示为表格样式。
下面的图片中,就是对同一份csv文件的不同显示方式,希望你能注意到文本形式中的逗号,每一个逗号都将数据分隔开来,就像表格里的边框分开不同的数据一样。
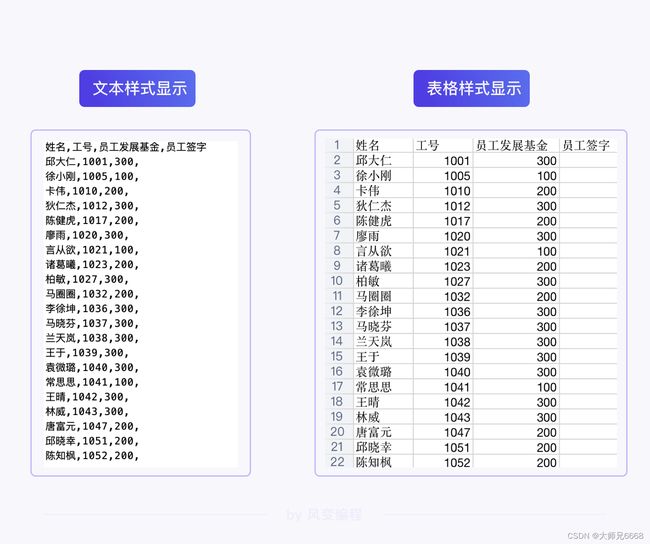
如果只是记录数据,不对数据进行操作的话,相较于Excel表格,csv文件会更加简洁轻便。
CSV文件的读取
使用Python来读写csv文件是非常容易的,因为实现csv的读取和写入功能的csv模块,是一个内置模块,我们可以直接使用。
使用csv模块时,需要先导入它,即在代码一开始写入import csv。
打开CSV文件
了解了什么是csv文件后,接下来就是要用Python来打开它。使用的函数你也很熟悉——open()。
是的,函数open()不仅可以打开txt文本文件,它也可以用来打开csv文件。使用open()打开的文件,都会返回一个文件对象。
与打开txt文本文件稍有不同的地方是,我们需要在open()中传入新的参数newline=‘’。根据Python官方文档的相关规定,当我们打开csv文件时,需要设置参数newline=‘’,这样可以避免一些不必要的空行。
会产生空行的原因涉及了不同计算机系统的设计标准,这些问题比较深奥,有兴趣的同学自己可以研究一下。
推荐的打开方式
我一直在强调:所有打开的文件对象,都应该被关闭。即使用open()打开文件时,在最后都需要使用方法文件对象.close()来关闭打开的文件。
但是,人难免有疏忽的时候。如果不使用该方法,不仅是一种较差的编程习惯,还可能会产生一些异常。
为了避免你出现忘记写close()的情况发生,同时也为了不让程序发生一些意料之外的异常,我要介绍一种不写文件对象.close()的方法,一种更好地打开文件的方法:
with open() as …
with open() as …是对原有open()和close()的优化。
使用with open() as …语句后,在with下面的代码块结束时,会自动执行close()关闭文件。
用法是把open()函数放在with后面,把变量名放在as后面,结束时要加冒号:,然后把要执行的文件处理语句缩进到with open() as …下方的代码块中。

需要特别强调的是,在传统方法中,我们将open()返回的文件对象以变量= open ()的形式赋值给了变量。但在with…as…中时,我们没有使用变量 =的形式,而是直接将变量放在了as后面,如下图所示。

请务必记住缩进,打开文件之后的其他文件操作,都应该位于with下缩进的代码块中。
读取CSV文件内容
csv模块内置了两种读取csv文件的方式:函数reader()和类DictReader,为了确保知识的完整性,让你对csv模块有更加全面的认识,我会先从最基本的reader()函数讲起。
reader()函数
reader()函数是csv模块内的一个函数,当使用open()打开csv文件,得到文件对象后,可以把这个文件对象传入reader()函数。

reader()函数会返回一个reader对象,这是一个可迭代对象,该对象里面的每一个元素都是一个列表,每一个列表都对应了csv文件中的一行。
因此,通过遍历,我们可以读取csv文件中的每一行。
代码示例:
# 导入csv模块
import csv
# 使用with open() as 打开'./reader_demo.csv',注意设置必要的参数
with open('./reader_demo.csv','r',newline='')as cs:
# 将文件对象转换为reader对象
reader=csv.reader(cs)
# 循环遍历reader对象,
for i in reader:
print(i)
# 打印csv文件中的每一行内容
DictReader类
讲完了函数reader(),下面来讲我们代码中使用的DictReader类。(reader()是函数,DictReader是类,注意区分。)
他们二者有什么区别呢?什么时候应该使用reader(),什么时候用DictReader呢?
如果在csv文件中存在映射关系(即csv文件的第一行为表格中的表头),如图所示:

这样的csv文件当然可以使用reader()函数来读取,但是csv模块为我们提供了一种更好的读取方式——DictReader类,使用这个类来读取第一行为表头的csv文件,可以更好地反映出表头与文件内容的映射关系。
那么,DictReader到底是什么呢?相关代码应该怎么写呢?我们先来看看Python官方文档中的写法。

DictReader类的操作类似于常规的reader(),但DictReader会将读取到的信息转换为字典形式。
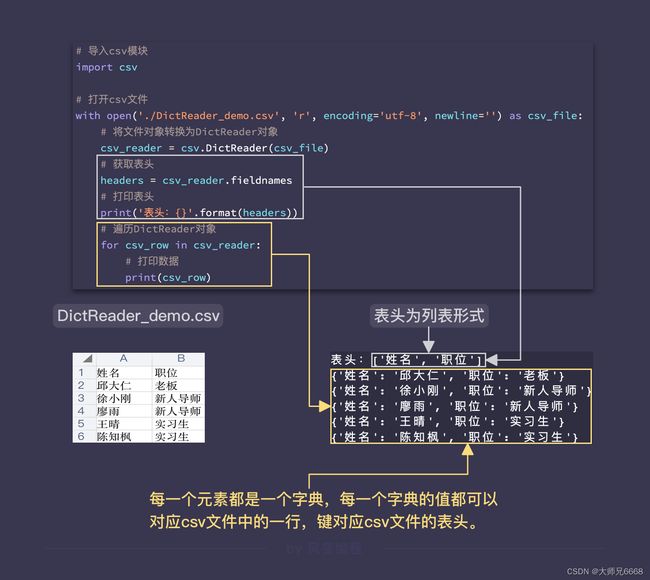
实例化DictReader类后,会得到一个DictReader对象,这是一个可迭代对象,我们可以使用循环来遍历它的每一个元素。但不同于reader()的是,该对象里面的每一个元素都是一个字典,每一个字典的值都可以对应csv文件中的一行,键对应csv文件的表头。
这个类还有个属性fieldnames,该属性可以将csv文件(表格)的表头(第一行)读取出来,返回值是列表。这个表头也就是字典的键(key)。
通过fieldnames取得表头是列表形式的。for循环遍历DictReader后,打印了除表头外的所有内容,其中的每一个元素都是字典,字典的键就是表头。如图所示。
数据写入CSV文件
与读取功能类似,csv模块也为我们准备了两种写入方式——函数writer()与类DictWriter。为了确保知识的完整性,我要先讲writer(),然后再讲代码会用到的DictWriter。
writer()函数
writer()函数是csv模块内的一个函数,当使用open()打开csv文件,得到文件对象后,可以把这个文件对象传入writer()函数。

writer()函数会返回一个writer对象,可以调用该对象的方法将字符串文本写入csv文件。
具体要如何做呢?
要将内容写入csv文件,需要先把open()返回的文件对象转化为writer对象。
然后需要调用writer对象的方法writerow(row),该方法会将参数row当作一行内容写入csv文件中。
参数row代表了你想要写入csv文件的内容,它必须是一个可迭代对象,这里推荐使用列表。
另外,如果你想通过这个方法写入多行数据。需要借助循环来实现。
DictWriter类
讲完了函数writer(),现在来说说我在任务代码中使用的DictWriter类。(writer()是函数,DictWriter是类,注意区分。)
从名字上就可以看出来,DictWriter是可以和刚才讲过的DictReader对应起来的。

ictWriter的操作类似于常规的writer(),但DictWriter会将字典写入(映射)到csv文件的行中。
即通过DictWriter写入的行,都必须是字典形式,这点和writer()还是有区别的。
所以,当我们需要将字典类型的数据写入csv文件时,使用DictWriter会是一种更好的选择。
有一点需要你特别注意,与DictReader不同,在上面的图片中,我特意标注出了一个参数fieldnames。
在实例化DictWriter时,必须要传入该参数。
我们需要将一个列表传给参数fieldnames,它的作用是设置csv文件的第一行数据(即表头数据)。当我们要将字典通过DictWriter对象写入csv文件时,通常会把字典的键(key)存入一个列表,再把这个列表传给参数fieldnames。

实例化DictWriter后,会得到一个DictWriter对象,我们需要通过该对象来调用两个方法来写入内容。
writeheader()
第一个方法:writeheader(),该方法可将表头(即字典中的键(key))写入csv的第一行。
也就是说,如果要写入表头,不仅要在DictWriter中传入参数fieldnames,还需要调用writeheader()方法。这点很重要,一定要记住。
writerow(row)
第二个方法:writerow(row),与writer对象调用writerow(row)不同的是,这里的参数row必须是字典形式的数据。
在写入时,该方法会根据字典的键,找到相应的表头,然后再将此键对应的值写入表头对应的列。

知识点总结
