AutoML工具-AutoGluon
1、简介
AutoGluon是AutoML的自动化工具,涉及方面有图像、文本、时间序列和表格式数据。
2、入门
2.1 安装
pip install autogluon2.2 使用
(1)Tabular(解释是表格式数据,不知道对不对)
两个函数TabularDataset、TabularPredictor
例子参看:AutoGluon Tabular - Quick Start - AutoGluon 0.8.2 documentation
流程:training、prediction、evaluation
(2)Multimodal(多模式)
一个函数MultiModalPredictor
例子参看:AutoGluon Multimodal - Quick Start - AutoGluon 0.8.2 documentation
流程:training、prediction、evaluation
(3)Time Series(时间序列)
两个函数TimeSeriesDataFrame, TimeSeriesPredictor
例子参看:AutoGluon Time Series - Forecasting Quick Start - AutoGluon 0.8.2 documentation
流程:training、prediction、evaluation
该模型支持:GPU
3、进阶
(1)Tabular
目标:完成分类和回归任务
以分类为例,下图是基本实现流程:
from autogluon.tabular import TabularDataset, TabularPredictor
#准备数据
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
subsample_size = 500 # subsample subset of data for faster demo, try setting this to much larger values
train_data = train_data.sample(n=subsample_size, random_state=0)
train_data.head()
#测试集数据
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
y_test = test_data[label] # values to predict
test_data_nolab = test_data.drop(columns=[label]) # delete label column to prove we're not cheating
test_data_nolab.head()
#标签值
label = 'class'
print("Summary of class variable: \n", train_data[label].describe())
#模型训练和保存
save_path = 'agModels-predictClass' # specifies folder to store trained models
predictor = TabularPredictor(label=label, path=save_path).fit(train_data)
#加载模型,预测评估
predictor = TabularPredictor.load(save_path) # unnecessary, just demonstrates how to load previously-trained predictor from file
y_pred = predictor.predict(test_data_nolab)
print("Predictions: \n", y_pred)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
#在测试集评估模型性能
predictor.leaderboard(test_data, silent=True)此外,还可进行调参:
from autogluon.common import space
nn_options = { # specifies non-default hyperparameter values for neural network models
'num_epochs': 10, # number of training epochs (controls training time of NN models)
'learning_rate': space.Real(1e-4, 1e-2, default=5e-4, log=True), # learning rate used in training (real-valued hyperparameter searched on log-scale)
'activation': space.Categorical('relu', 'softrelu', 'tanh'), # activation function used in NN (categorical hyperparameter, default = first entry)
'dropout_prob': space.Real(0.0, 0.5, default=0.1), # dropout probability (real-valued hyperparameter)
}
gbm_options = { # specifies non-default hyperparameter values for lightGBM gradient boosted trees
'num_boost_round': 100, # number of boosting rounds (controls training time of GBM models)
'num_leaves': space.Int(lower=26, upper=66, default=36), # number of leaves in trees (integer hyperparameter)
}
hyperparameters = { # hyperparameters of each model type
'GBM': gbm_options,
'NN_TORCH': nn_options, # NOTE: comment this line out if you get errors on Mac OSX
} # When these keys are missing from hyperparameters dict, no models of that type are trained
time_limit = 2*60 # train various models for ~2 min
num_trials = 5 # try at most 5 different hyperparameter configurations for each type of model
search_strategy = 'auto' # to tune hyperparameters using random search routine with a local scheduler
hyperparameter_tune_kwargs = { # HPO is not performed unless hyperparameter_tune_kwargs is specified
'num_trials': num_trials,
'scheduler' : 'local',
'searcher': search_strategy,
} # Refer to TabularPredictor.fit docstring for all valid values
predictor = TabularPredictor(label=label, eval_metric=metric).fit(
train_data,
time_limit=time_limit,
hyperparameters=hyperparameters,
hyperparameter_tune_kwargs=hyperparameter_tune_kwargs,
)模型集成(stacking/bagging):
predictor = TabularPredictor(label=label, eval_metric=metric).fit(train_data,
num_bag_folds=5, num_bag_sets=1, num_stack_levels=1,
hyperparameters = {'NN_TORCH': {'num_epochs': 2}, 'GBM': {'num_boost_round': 20}}, # last argument is just for quick demo here, omit it in real applications
)核心参数是num_bag_folds和num_stack_levels等,但是会增加训练时间和内存占用,num_bag_sets控制k-fold进程的时间,auto_stack自动进行stack操作
特征工程是常见操作,对数据处理,缺失值,任务类型判断等任务进行相应操作。详见:AutoGluon Tabular - Feature Engineering - AutoGluon 0.8.2 documentation
(2)Multimodal Prediction
MultiModal是基于Huggingface,实现任务如下图:

(3)Time Series
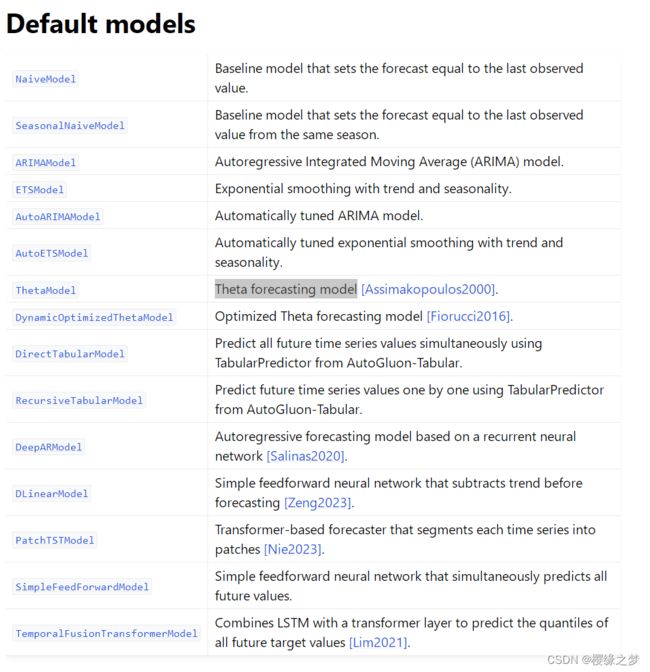
时间序列支持的模型
- 简单预测模型:ARIMA,ETS,Theta
- 深度学习模型:DeepAR, Temporal Fusion Transformer
- 树模型:LightGBM
- 集成模型
特征工程:
(1)静态变量
可以在数据集增加静态变量,例如位置信息(国家、州、城市)、产品的性质(品牌、颜色、大小、重量等)
(2)跟时间相关的变量
已知变量(known covariates):例如假期、工作日、周末等
过去变量(past covariates):促销信息、售卖产品信息等
Backtesting:
使用多窗口滑动测试
4、 总结
具体详细用法可以查看官方文档