Redis BitMap/HyperLogLog/GEO/布隆过滤器案例
面试问题:
- 抖音电商直播,主播介绍的商品有评论,1个商品对应了1系列的评论,排序+展现+取前10条记录
- 用户在手机App上的签到打卡信息:1天对应1系列用户的签到记录,新浪微博、钉钉打卡签到,来没来如何统计?
- 应用网站上的网页访问信息:1个网页对应1系列的访问点击,淘宝网首页,每天有多少人浏览首页?
- 你们公司系统上线后,说一下UV、PV、DAU分别是多少?
- ......
记录对集合中的数据进行统计:
- 在移动应用中,需要统计每天的新增用户数和第2天的留存用户数;
- 在电商网站的商品评论中,需要统计评论列表中的最新评论;
- 在签到打卡中,需要统计一个月内连续打卡的用户数;
- 在网页访问记录中,需要统计独立访客(Unique Visitor,UV)量。
痛点:
- 类似今日头条、抖音、淘宝这样的额用户访问级别都是亿级的,请问如何处理?
统计类型
聚合统计
统计多个集合元素的聚合结果,就是前面讲解过的交差并等集合统计;交并差集和聚合函数的应用。

排序统计
问题:
抖音短视频最新评论留言的场景,请你设计一个展现列表。考察你的数据结构和设计思路。
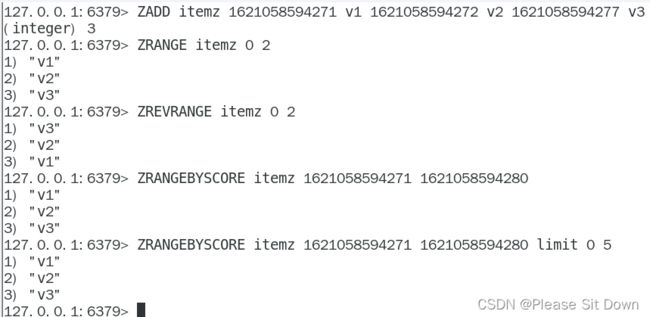
以抖音vcr最新的留言评价为案例,所有评论需要两个功能,按照时间排序(正序、反序)+分页显示,能够排序+分页显示的redis数据结构是什么合适?
设计案例和回答思路:
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用ZSet。
二值统计
集合元素的取值就只有0和1两种。见bitmap。
在钉钉上班签到打卡的场景中,我们只用记录有签到(1)或没签到(0)。
基致统计
指统计一个集合中不重复的元素个数。见hyperloglog。
HyperLogLog
名词记录
什么是UV?
答:Unique Visitor,独立访客,一般理解为客户端IP;需要去重考虑。
什么是PV?
答:Page View,页面浏览量;不用去重。
什么是DAU?
答:Daily Active User,日活跃用户量;常见登录或者使用了某个产品的用户数(去重复登录的用户),常用于反映网站、互联网应用或者网络游戏的运营情况。
什么是MAU?
答:Monthly Active User,月活跃用户量。
HyperLogLog需求
很多计数类场景,比如 每日注册 IP 数、每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
统计单日一个页面的访问量(PV),单次访问就算一次。统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。
多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
是什么
详情可见:Redis 7 十大数据类型_Please Sit Down的博客-CSDN博客
什么是基数:是一种数据集,去重复后的真实个数。

去重复统计功能的基数估计算法-就是HyperLogLog

基数统计:用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算 。(去重脱水后的真实数据)
基本命令:

HyPerLogLog如何演化出来的?
去重复统计你先会想到哪些方式?
答:HashSet、BitMap
使用BitMap思考?
如果数据显较大亿级统计,使用bitmap同样会有这个问题。bitmap是通过用位bit数组来表示各元素是否出现,每个元素对应一位,所需的总内存为N个bit。
基数计数则将每一个元素对应到bit数组中的其中一位,比如bit数组010010101(按照从零开始下标,有的就是1、4、6、8)。新进入的元素只需要将已经有的bit数组和新加入的元素进行按位或计算就行。这个方式能大大减少内存占用且位操作迅速。
But,假设一个样本案例就是一亿个基数位值数据,一个样本就是一亿。如果要统计1亿个数据的基数位值,大约需要内存100000000/8/1024/1024约等于12M,内存减少占用的效果显著。这样得到统计一个对象样本的基数值需要12M。
如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用bitmaps还是不适用大数据量下(亿级)的基数计数场景,但是bitmaps方法是精确计算的。
结论:
样本元素越多内存消耗急剧增大,难以管控+各种慢,对于亿级统计不太合适,大数据害死人,o(π...π)o(量变引起质变)
办法:
使用概率算法,通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。HyperLogLog就是一种概率算法的实现。
原理说明:
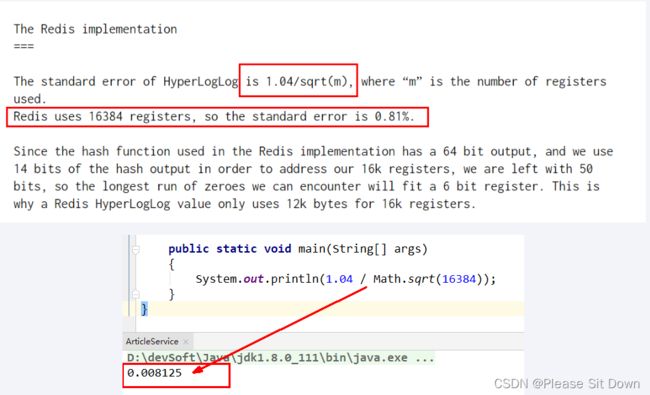
只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容。有误差,Hyperloglog提供不精确的去重计数方案,牺牲准确率来换取空间,误差仅仅只是0.81%左右。
这个误差如何来的?论文地址和出处
地址:Redis new data structure: the HyperLogLog -
Redis之父安特雷兹回答:
淘宝网站首页亿级UV的Redis统计方案
需求:
- UV的统计需要去重,一个用户一天内的多次访问只能算作一次
- 淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
- 每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加入
方案:
1、使用mysql(绝对不允许)
2、用redis的hash结构存储

说明:redis——hash =
按照ipv4的结构来说明,每个ipv4的地址最多是15个字节(ip = "192.168.111.1",最多xxx.xxx.xxx.xxx),某一天的1.5亿 * 15个字节= 2G,一个月60G,redis死定了。o(╥﹏╥)o
3、使用hyperloglog
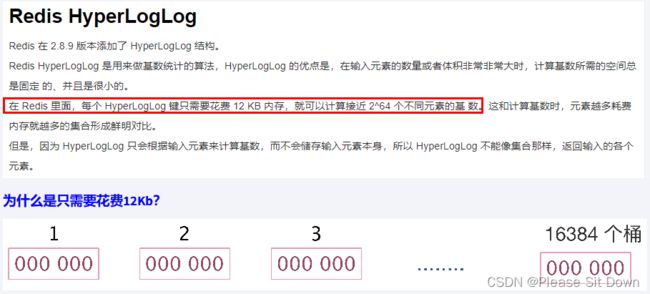
Redis使用了2^14=16384个桶,按照上面的标准差,误差为0.81%,精度相当高。Redis使用一个long型哈希值的前14个比特用来确定桶编号,剩下的50个比特用来做基数估计。而2^6=64,所以只需要用6个比特表示下标值,在一般情况下,一个HLL数据结构占用内存的大小为16384*6/8=12kB,Redis将这种情况称为密集(dense)存储。
代码:
HyperLogLogService.java
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@Service
@Slf4j
public class HyperLogLogService{
@Resource
private RedisTemplate redisTemplate;
/**
* 模拟后台有用户点击首页,每个用户来自不同ip地址
*/
@PostConstruct
public void init() {
log.info("------模拟后台有用户点击首页,每个用户来自不同ip地址");
new Thread(() -> {
String ip = null;
for (int i = 1; i <=200; i++) {
Random r = new Random();
ip = r.nextInt(256) + "." + r.nextInt(256) + "." + r.nextInt(256) + "." + r.nextInt(256);
Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip);
log.info("ip={},该ip地址访问首页的次数={}",ip,hll);
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
}
},"t1").start();
}
}
HyperLogLogController.java
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@Api(description = "淘宝亿级UV的Redis统计方案")
@RestController
@Slf4j
public class HyperLogLogController{
@Resource
private RedisTemplate redisTemplate;
@ApiOperation("获得IP去重后的首页访问量")
@RequestMapping(value = "/uv",method = RequestMethod.GET)
public long uv() {
//pfcount
return redisTemplate.opsForHyperLogLog().size("hll");
}
}GEO
面试问题
移动互联网时代LBS应用越来越多,交友软件中附近的小姐姐、外卖软件中附近的美食店铺、打车软件附近的车辆等等。那这种附近各种形形色色的XXX地址位置选择是如何实现的?
会有什么问题呢?
- 1.查询性能问题,如果并发高,数据量大这种查询是要搞垮mysql数据库的
- 2.一般mysql查询的是一个平面矩形访问,而叫车服务要以我为中心N公里为半径的圆形覆盖。
- 3.精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差,mysql不合适。
命令复习
详情可见:Redis 7 十大数据类型_Please Sit Down的博客-CSDN博客
中文乱码如何处理:

1、GEOADD添加经纬度坐标

GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
2、GEOPOS返回经纬度
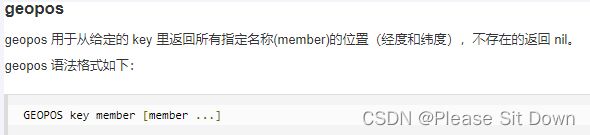
GEOPOS city 天安门 故宫
3、GEOHASH返回坐标的geohash表示(geohash算法生成的base32编码值)


GEOHASH city 天安门 故宫 长城 
4、GEODIST两个位置之间距离

GEODIST city 天安门 长城 km 
后面参数是距离单位:
m 米
km 千米
ft 英尺
mi 英里
5、GEORADIUS以半径为中心,查找附近的X
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 descWITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
COUNT 限定返回的记录数。
当前位置(116.418017 39.914402),我在王府井

6、GEORADIUSBYMEMBER


美团地图位置附近的酒店推送
需求分析:
- 美团app附近的酒店
- 摇个妹子,附近的妹子
- 高德地图附近的人或者一公里以内的各种营业厅、加油站、理发店、超市…
- 找个单车
- ......

命令:
官网地址 - geoadd 命令 -- Redis中国用户组(CRUG)

代码实现:
GeoController.java
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.geo.*;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Api(tags = "美团地图位置附近的酒店推送GEO")
@RestController
@Slf4j
public class GeoController{
@Resource
private GeoService geoService;
@ApiOperation("添加坐标geoadd")
@RequestMapping(value = "/geoadd",method = RequestMethod.GET)
public String geoAdd() {
return geoService.geoAdd();
}
@ApiOperation("获取经纬度坐标geopos")
@RequestMapping(value = "/geopos",method = RequestMethod.GET)
public Point position(String member) {
return geoService.position(member);
}
@ApiOperation("获取经纬度生成的base32编码值geohash")
@RequestMapping(value = "/geohash",method = RequestMethod.GET)
public String hash(String member) {
return geoService.hash(member);
}
@ApiOperation("获取两个给定位置之间的距离")
@RequestMapping(value = "/geodist",method = RequestMethod.GET)
public Distance distance(String member1, String member2) {
return geoService.distance(member1,member2);
}
@ApiOperation("通过经度纬度查找北京王府井附近的")
@RequestMapping(value = "/georadius",method = RequestMethod.GET)
public GeoResults radiusByxy() {
return geoService.radiusByxy();
}
@ApiOperation("通过地方查找附近,本例写死天安门作为地址")
@RequestMapping(value = "/georadiusByMember",method = RequestMethod.GET)
public GeoResults radiusByMember() {
return geoService.radiusByMember();
}
}
GeoService.java
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.geo.Distance;
import org.springframework.data.geo.GeoResults;
import org.springframework.data.geo.Metrics;
import org.springframework.data.geo.Point;
import org.springframework.data.geo.Circle;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class GeoService {
public static final String CITY ="city";
@Autowired
private RedisTemplate redisTemplate;
public String geoAdd() {
Map map= new HashMap<>();
map.put("天安门",new Point(116.403963,39.915119));
map.put("故宫",new Point(116.403414 ,39.924091));
map.put("长城" ,new Point(116.024067,40.362639));
redisTemplate.opsForGeo().add(CITY,map);
return map.toString();
}
public Point position(String member) {
//获取经纬度坐标
List list= this.redisTemplate.opsForGeo().position(CITY,member);
return list.get(0);
}
public String hash(String member) {
//geohash算法生成的base32编码值
List list= this.redisTemplate.opsForGeo().hash(CITY,member);
return list.get(0);
}
public Distance distance(String member1, String member2) {
//获取两个给定位置之间的距离
Distance distance= this.redisTemplate.opsForGeo().distance(CITY,member1,member2, RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
public GeoResults radiusByxy() {
//通过经度,纬度查找附近的,北京王府井位置116.418017,39.914402
Circle circle = new Circle(116.418017, 39.914402, Metrics.KILOMETERS.getMultiplier());
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
GeoResults> geoResults= this.redisTemplate.opsForGeo().radius(CITY,circle, args);
return geoResults;
}
public GeoResults radiusByMember() {
//通过地方查找附近
String member="天安门";
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
//半径10公里内
Distance distance=new Distance(10, Metrics.KILOMETERS);
GeoResults> geoResults= this.redisTemplate.opsForGeo().radius(CITY,member, distance,args);
return geoResults;
}
}
BitMap
面试问题
- 日活统计
- 连续签到打卡
- 最近一周的活跃用户
- 统计指定用户一年之中的登陆天数
- 某用户按照一年365天,哪几天登陆过?哪几天没有登陆?全年中登录的天数共计多少?
是什么
由0和1状态表现的二进制位的bit数组。

说明:用String类型作为底层数据结构实现的一种统计二值状态的数据类型。
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(2^32 = 4294967296)。
能干嘛
用于状态统计:Y、N,类似AtomicBoolean
看需求:
- 用户是否登陆过Y、N,比如京东每日签到送京豆
- 电影、广告是否被点击播放过
- 钉钉打卡上下班,签到统计
- ......
京东签到领取京豆
需求说明:

小厂方法,传统mysql方式:
建表SQL:
CREATE TABLE user_sign(
keyid BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT,
user_key VARCHAR(200),#京东用户ID
sign_date DATETIME,#签到日期(20210618)
sign_count INT #连续签到天数
)
INSERT INTO user_sign(user_key,sign_date,sign_count) VALUES ('20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx','2020-06-18 15:11:12',1);
SELECT
sign_count
FROM
user_sign
WHERE
user_key = '20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
AND sign_date BETWEEN '2020-06-17 00:00:00' AND '2020-06-18 23:59:59'
ORDER BY
sign_date DESC
LIMIT 1;困难和解决思路:
方法正确但是难以落地实现,o(╥﹏╥)o。 签到用户量较小时这么设计能行,但京东这个体量的用户(估算3000W签到用户,一天一条数据,一个月就是9亿数据)。对于京东这样的体量,如果一条签到记录对应着当日用记录,那会很恐怖......
如何解决这个痛点?
- 一条签到记录对应一条记录,会占据越来越大的空间。
- 一个月最多31天,刚好我们的int类型是32位,那这样一个int类型就可以搞定一个月,32位大于31天,当天来了位是1没来就是0。
- 一条数据直接存储一个月的签到记录,不再是存储一天的签到记录。
大厂方法,基于Redis的Bitmaps实现签到日历:
建表->按位->redis bitmap
在签到统计时,每个用户一天的签到用1个bit位就能表示,一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型。
命令复习
命令复习:Redis 7 十大数据类型_Please Sit Down的博客-CSDN博客
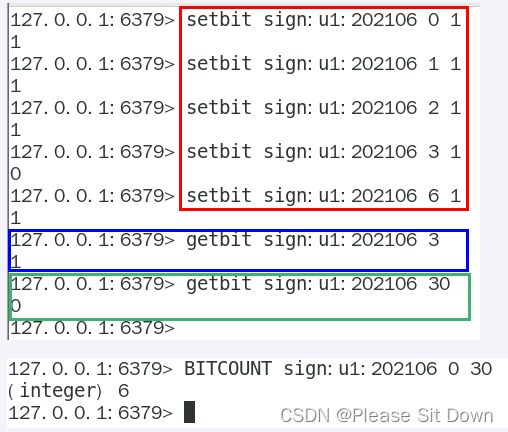
1、setbit
命令:setbit key offset value
setbit键偏移位只能0或者1,Bitmap的偏移量是从零开始算的。

2、getbit
命令:getbit key offset
setbiti和getbit案例说明:
按照天
按照年
按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。假如是亿级的系统,每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
bitmap的底层编码说明,get命令操作如何:
实质是二进制的ascii编码对应,redis里用type命令看看bitmap实质是什么类型???
man ascii
设置命令
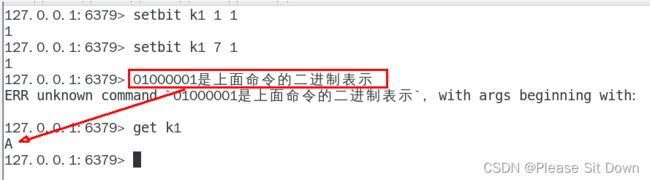
两个setbit命令对k1进行设置后,对应的二进制串就是0100 0001
二进制串就是0100 0001对应的10进制就是65,所以见下图:

3、strlen
解释:统计字节数占用多少

不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容。
4、bitcount
全部键里面含有1的有多少个?
一年365天,全年天天登陆占用多少字节


5、bitop
连续2天都签到的用户
加入某个网站或者系统,它的用户有1000W,做个用户id和位置的映射
比如0号位对应用户id:uid-092iok-lkj
比如1号位对应用户id:uid-7388c-xxx
。。。。。。

布隆过滤器BloomFilter
面试问题
- 判断是否存在,布隆过滤器了解过吗?
- 安全连接网址,全球数10亿的网址判断
- 黑名单校验,识别垃圾邮件
- 白名单校验,识别出合法用户进行后续处理
- ......
现有50亿个电话号码,现有10万个电话号码,如何要快速准确的判断这些电话号码是否已经存在?
我让你判断在50亿记录中有没有,不是让你存。 有就返回1,没有返回零。
1、通过数据库查询-------实现快速有点难。
2、数据预放到内存集合中:50亿*8字节大约40G,内存太大了。
是什么
由一个初值都为零的bt数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。

设计思想:本质就是判断具体数据是否存在于一个大的集合中。
目的:减少内存占用
方式:不保存数据信息,只是在内存中做一个是否存在的标记flag
简介:
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生。

【备注】:布隆过滤器是一种类似set的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美。
能干嘛
高效地插入和查询,占用空间少,返回的结果是不确定性+不够完美。布隆过滤器可以添加元素,但是不能删除元素,由于涉及hashcode判断依据,删掉元素会导致误判率增加。
一个元素判断结果:存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。
小总结:有,是可能有;无,是肯定无,可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中。
布隆过滤器原理
布隆过滤器实现原理和数据结构
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
添加key时:
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时:
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
hash冲突导致数据不精准:
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。

查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了,如果这些点,有任何一个为零则被查询变量一定不在,如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图3号坑两个对象都1)

哈希函数
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。
如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
Java中hash冲突java案例
public class HashCodeConflictDemo {
public static void main(String[] args) {
Set hashCodeSet = new HashSet<>();
for (int i = 0; i <200000; i++) {
int hashCode = new Object().hashCode();
if(hashCodeSet.contains(hashCode)) {
System.out.println("出现了重复的hashcode: "+hashCode+"\t 运行到"+i);
break;
}
hashCodeSet.add(hashCode);
}
System.out.println("Aa".hashCode());
System.out.println("BB".hashCode());
System.out.println("柳柴".hashCode());
System.out.println("柴柕".hashCode());
}
} 使用3步骤
1、初始化bitmap
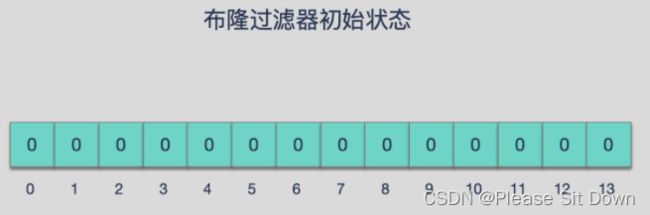
布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0。

2、添加占坑位
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
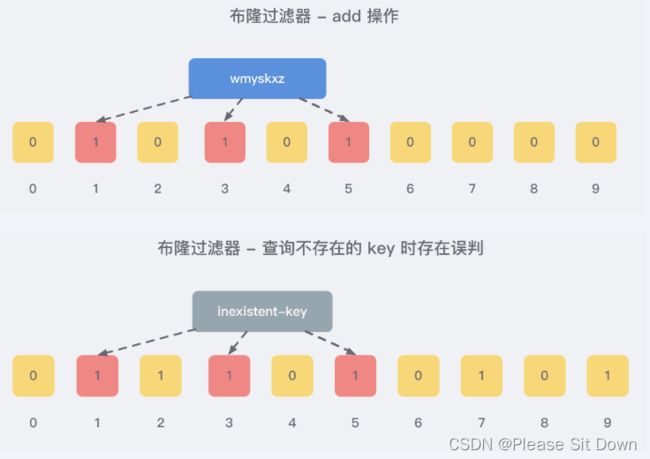
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位。

3、判断是否存在
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了......笔记见最下面
布隆过滤器误判率,为什么不要删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
特性:布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
小总结
是否存在:有,是很可能有;无,是肯定无,100%无。
使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容。当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add进行。
布隆过滤器的使用场景
1、解决缓存穿透的问题,和redis结合bitmap使用
缓存穿透是什么?
- 一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
- 当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
- 缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
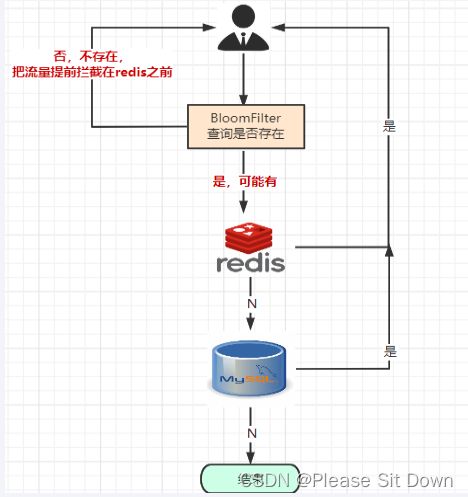
可以使用布隆过滤器解决缓存穿透的问题,把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。当有新的请求时,先到布隆过滤器中查询是否存在;如果布隆过滤器中不存在该条数据则直接返回;如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则再查询Mysql数据库。
2、黑名单校验,识别垃圾邮件
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
3、安全连接网址,全球上10亿的网址判断
尝试手写布隆过滤器
整体架构:

步骤设计
redis的setbit/getbit
setBit的构建过程
1、@PostConstruct初始化白名单数据
2、计算元素的hash值
3、通过上一步hash值算出对应的二进制数组的坑位
4、将对应坑位的值的修改为数字1,表示存在
getBiti查询是否存在
1、计算元素的hash值
2、通过上一步hash值算出对应的二进制数组的坑位
3、返回对应坑位的值,零表示无,1表示存在
构建工程
1、表结构
CREATE TABLE `t_customer` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`cname` varchar(50) NOT NULL,
`age` int(10) NOT NULL,
`phone` varchar(20) NOT NULL,
`sex` tinyint(4) NOT NULL,
`birth` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_cname` (`cname`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;2、pom.xml
4.0.0
com.atguigu.redis7
redis7_study
1.0-SNAPSHOT
org.springframework.boot
spring-boot-starter-parent
2.6.10
UTF-8
1.8
1.8
4.12
1.2.17
1.16.18
org.springframework.boot
spring-boot-starter-web
redis.clients
jedis
4.3.1
org.springframework.boot
spring-boot-starter-data-redis
org.apache.commons
commons-pool2
io.springfox
springfox-swagger2
2.9.2
io.springfox
springfox-swagger-ui
2.9.2
mysql
mysql-connector-java
5.1.47
com.alibaba
druid-spring-boot-starter
1.1.10
com.alibaba
druid
1.1.16
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.0
cn.hutool
hutool-all
5.2.3
javax.persistence
persistence-api
1.0.2
tk.mybatis
mapper
4.1.5
org.springframework.boot
spring-boot-autoconfigure
junit
junit
${junit.version}
org.springframework.boot
spring-boot-starter-test
test
log4j
log4j
${log4j.version}
org.projectlombok
lombok
${lombok.version}
true
org.springframework.boot
spring-boot-maven-plugin
3、yaml
server.port=7777
spring.application.name=redis7_study
# ========================logging=====================
logging.level.root=info
logging.level.com.atguigu.redis7=info
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger- %msg%n
logging.file.name=D:/mylogs2023/redis7_study.log
logging.pattern.file=%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger- %msg%n
# ========================swagger=====================
spring.swagger2.enabled=true
#在springboot2.6.X结合swagger2.9.X会提示documentationPluginsBootstrapper空指针异常,
#原因是在springboot2.6.X中将SpringMVC默认路径匹配策略从AntPathMatcher更改为PathPatternParser,
# 导致出错,解决办法是matching-strategy切换回之前ant_path_matcher
spring.mvc.pathmatch.matching-strategy=ant_path_matcher
# ========================redis单机=====================
spring.redis.database=0
# 修改为自己真实IP
spring.redis.host=192.168.111.185
spring.redis.port=6379
spring.redis.password=111111
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
# ========================alibaba.druid=====================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false
# ========================mybatis===================
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.atguigu.redis7.entities
# ========================redis集群=====================
#spring.redis.password=111111
## 获取失败 最大重定向次数
#spring.redis.cluster.max-redirects=3
#spring.redis.lettuce.pool.max-active=8
#spring.redis.lettuce.pool.max-wait=-1ms
#spring.redis.lettuce.pool.max-idle=8
#spring.redis.lettuce.pool.min-idle=0
##支持集群拓扑动态感应刷新,自适应拓扑刷新是否使用所有可用的更新,默认false关闭
#spring.redis.lettuce.cluster.refresh.adaptive=true
##定时刷新
#spring.redis.lettuce.cluster.refresh.period=2000
#spring.redis.cluster.nodes=192.168.111.185:6381,192.168.111.185:6382,192.168.111.172:6383,192.168.111.172:6384,192.168.111.184:6385,192.168.111.184:63864、主启动类
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import tk.mybatis.spring.annotation.MapperScan;
@SpringBootApplication
@MapperScan("com.atguigu.redis7.mapper") //import tk.mybatis.spring.annotation.MapperScan;
public class Redis7Study7 {
public static void main(String[] args) {
SpringApplication.run(Redis7Study7777.class,args);
}
}5、Customer
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;
import java.util.Date;
@Table(name = "t_customer")
public class Customer implements Serializable {
@Id
@GeneratedValue(generator = "JDBC")
private Integer id;
private String cname;
private Integer age;
private String phone;
private Byte sex;
private Date birth;
public Customer() { }
public Customer(Integer id, String cname){
this.id = id;
this.cname = cname;
}
/**
* @return id
*/
public Integer getId() {
return id;
}
/**
* @param id
*/
public void setId(Integer id) {
this.id = id;
}
/**
* @return cname
*/
public String getCname() {
return cname;
}
/**
* @param cname
*/
public void setCname(String cname) {
this.cname = cname;
}
/**
* @return age
*/
public Integer getAge() {
return age;
}
/**
* @param age
*/
public void setAge(Integer age) {
this.age = age;
}
/**
* @return phone
*/
public String getPhone() {
return phone;
}
/**
* @param phone
*/
public void setPhone(String phone) {
this.phone = phone;
}
/**
* @return sex
*/
public Byte getSex() {
return sex;
}
/**
* @param sex
*/
public void setSex(Byte sex) {
this.sex = sex;
}
/**
* @return birth
*/
public Date getBirth() {
return birth;
}
/**
* @param birth
*/
public void setBirth(Date birth) {
this.birth = birth;
}
@Override
public String toString() {
return "Customer{" +
"id=" + id +
", cname='" + cname + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", sex=" + sex +
", birth=" + birth +
'}';
}
}6、mapper
import com.atguigu.redis7.entities.Customer;
import tk.mybatis.mapper.common.Mapper;
public interface CustomerMapper extends Mapper {
} 7、mapper - sql文件
8、CustomerSerivce
import com.atguigu.redis7.entities.Customer;
import com.atguigu.redis7.mapper.CustomerMapper;
import com.atguigu.redis7.utils.CheckUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
@Service
@Slf4j
public class CustomerSerivce {
public static final String CACHE_KEY_CUSTOMER = "customer:";
@Resource
private CustomerMapper customerMapper;
@Resource
private RedisTemplate redisTemplate;
public void addCustomer(Customer customer){
int i = customerMapper.insertSelective(customer);
if(i > 0) {
//到数据库里面,重新捞出新数据出来,做缓存
customer=customerMapper.selectByPrimaryKey(customer.getId());
//缓存key
String key=CACHE_KEY_CUSTOMER+customer.getId();
//往mysql里面插入成功随后再从mysql查询出来,再插入redis
redisTemplate.opsForValue().set(key,customer);
}
}
public Customer findCustomerById(Integer customerId){
Customer customer = null;
//缓存key的名称
String key=CACHE_KEY_CUSTOMER+customerId;
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if(customer==null){
//2 从mysql查出来customer
customer=customerMapper.selectByPrimaryKey(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;
}
}9、CustomerController
import com.atguigu.redis7.entities.Customer;
import com.atguigu.redis7.service.CustomerSerivce;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Random;
import java.util.Date;
import java.util.concurrent.ExecutionException;
@Api(tags = "客户Customer接口+布隆过滤器讲解")
@RestController
@Slf4j
public class CustomerController{
@Resource
private CustomerSerivce customerSerivce;
@ApiOperation("数据库初始化2条Customer数据")
@RequestMapping(value = "/customer/add", method = RequestMethod.POST)
public void addCustomer() {
for (int i = 0; i < 2; i++) {
Customer customer = new Customer();
customer.setCname("customer"+i);
customer.setAge(new Random().nextInt(30)+1);
customer.setPhone("1381111xxxx");
customer.setSex((byte) new Random().nextInt(2));
customer.setBirth(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
customerSerivce.addCustomer(customer);
}
}
@ApiOperation("单个用户查询,按customerid查用户信息")
@RequestMapping(value = "/customer/{id}", method = RequestMethod.GET)
public Customer findCustomerById(@PathVariable int id) {
return customerSerivce.findCustomerById(id);
}
}10、启动测试Swagger是否OK
地址:http://localhost:7777/swagger-ui.html
新增布隆过滤器案例
1、白名单类BloomFilterInit
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
/**
* 布隆过滤器白名单初始化工具类,一开始就设置一部分数据为白名单所有,
* 白名单业务默认规定:布隆过滤器有,redis也有。
*/
@Component
@Slf4j
public class BloomFilterInit{
@Resource
private RedisTemplate redisTemplate;
//初始化白名单数据,故意差异化数据演示效果......
@PostConstruct
public void init() {
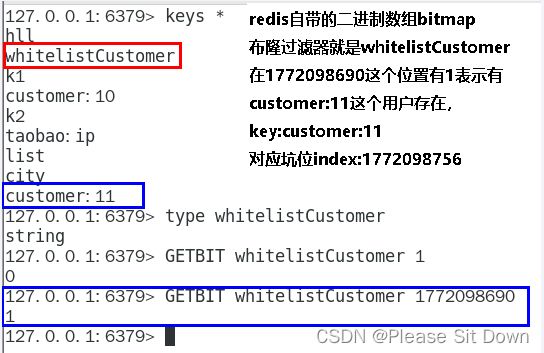
//白名单客户预加载到布隆过滤器
String uid = "customer:12";
//1 计算hashcode,由于可能有负数,直接取绝对值
int hashValue = Math.abs(uid.hashCode());
//2 通过hashValue和2的32次方取余后,获得对应的下标坑位
long index = (long) (hashValue % Math.pow(2, 32));
log.info(uid+" 对应------坑位index:{}",index);
//3 设置redis里面bitmap对应坑位,该有值设置为1
redisTemplate.opsForValue().setBit("whitelistCustomer",index,true);
}
}2、CheckUtils
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
@Component
@Slf4j
public class CheckUtils{
@Resource
private RedisTemplate redisTemplate;
public boolean checkWithBloomFilter(String checkItem,String key) {
int hashValue = Math.abs(key.hashCode());
long index = (long) (hashValue % Math.pow(2, 32));
boolean existOK = redisTemplate.opsForValue().getBit(checkItem, index);
log.info("----->key:"+key+"\t对应坑位index:"+index+"\t是否存在:"+existOK);
return existOK;
}
}3、CustomerSerivce
import com.atguigu.redis7.entities.Customer;
import com.atguigu.redis7.mapper.CustomerMapper;
import com.atguigu.redis7.utils.CheckUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
@Service
@Slf4j
public class CustomerSerivce{
public static final String CACHE_KEY_CUSTOMER = "customer:";
@Resource
private CustomerMapper customerMapper;
@Resource
private RedisTemplate redisTemplate;
@Resource
private CheckUtils checkUtils;
public void addCustomer(Customer customer){
int i = customerMapper.insertSelective(customer);
if(i > 0){
//到数据库里面,重新捞出新数据出来,做缓存
customer=customerMapper.selectByPrimaryKey(customer.getId());
//缓存key
String key=CACHE_KEY_CUSTOMER+customer.getId();
//往mysql里面插入成功随后再从mysql查询出来,再插入redis
redisTemplate.opsForValue().set(key,customer);
}
}
public Customer findCustomerById(Integer customerId){
Customer customer = null;
//缓存key的名称
String key=CACHE_KEY_CUSTOMER+customerId;
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if(customer==null){
//2 从mysql查出来customer
customer=customerMapper.selectByPrimaryKey(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;
}
/**
* BloomFilter → redis → mysql
* 白名单:whitelistCustomer
* @param customerId
* @return
*/
@Resource
private CheckUtils checkUtils;
public Customer findCustomerByIdWithBloomFilter (Integer customerId){
Customer customer = null;
//缓存key的名称
String key = CACHE_KEY_CUSTOMER + customerId;
//布隆过滤器check,无是绝对无,有是可能有
//===============================================
if(!checkUtils.checkWithBloomFilter("whitelistCustomer",key)){
log.info("白名单无此顾客信息:{}",key);
return null;
}
//===============================================
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if (customer == null) {
//2 从mysql查出来customer
customer = customerMapper.selectByPrimaryKey(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key, customer);
}
}
return customer;
}
}4、CustomerController
import com.atguigu.redis7.entities.Customer;
import com.atguigu.redis7.service.CustomerSerivce;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Random;
import java.util.Date;
import java.util.concurrent.ExecutionException;
@Api(tags = "客户Customer接口+布隆过滤器讲解")
@RestController
@Slf4j
public class CustomerController{
@Resource
private CustomerSerivce customerSerivce;
@ApiOperation("数据库初始化2条Customer数据")
@RequestMapping(value = "/customer/add", method = RequestMethod.POST)
public void addCustomer() {
for (int i = 0; i < 2; i++) {
Customer customer = new Customer();
customer.setCname("customer"+i);
customer.setAge(new Random().nextInt(30)+1);
customer.setPhone("1381111xxxx");
customer.setSex((byte) new Random().nextInt(2));
customer.setBirth(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
customerSerivce.addCustomer(customer);
}
}
@ApiOperation("单个用户查询,按customerid查用户信息")
@RequestMapping(value = "/customer/{id}", method = RequestMethod.GET)
public Customer findCustomerById(@PathVariable int id) {
return customerSerivce.findCustomerById(id);
}
@ApiOperation("BloomFilter案例讲解")
@RequestMapping(value = "/customerbloomfilter/{id}", method = RequestMethod.GET)
public Customer findCustomerByIdWithBloomFilter(@PathVariable int id) throws ExecutionException, InterruptedException {
return customerSerivce.findCustomerByIdWithBloomFilter(id);
}
}
5、测试三个功能
布隆过滤器有,redis有
布隆过滤器有,redis无
布隆过滤器无,直接返回,不再继续走下去
布隆过滤器优缺点
优点:高效地插入和查询,内存占用bit空间少
缺点:
1、不能刚除元素。因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。
2、存在误判,不能精准过滤。有,是很可能有;无,是肯定无,100%无。
布谷鸟过滤器(了解)
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。
论文:《Cuckoo Filter:Better Than Bloom》

作者将布谷鸟过滤器和布隆过滤器进行了深入的对比,有兴趣的同学可以自己看看。