深入解析C++虚函数机制
1、虚函数的语义
C++中的函数默认是不会出发动态绑定的,要触发C++的动态绑定机制,从而实现运行时多态,需要在使我们的程序满足以下两个条件:第一是必须使用基类类型的指针或者引用来进行函数调用的操作;第二是只有指定为虚函数的成员函数才能进行动态绑定。
从派生类到基类的转换
有以下代码段:
double print_total(const Item_base& ,size_t); Item_base item; print_total(item,10); Item_base *p=&item; Bulk_item bulk; print_total(bulk,10); p=&bulk;
这段代码使用同一基类类型的指针指向基类类型的对象和派生类类型的对象,还传递基类类型和派生类类型的对象来调用需要基类类型引用的函数。因为可以使用基类类型的指针或引用来引用派生类对象,所以使用基类类型的引用或指针时,不知道指针或者引用所绑定的对象的类型。无论实际对象具有什么类型,编译器都把它当作是基类类型对象。
可以在运行时确定virtual函数的调用
对象的实际类型可能不同于该对象引用或指针的静态类型,这是C++中动态绑定的关键。通过指针或者引用调用虚函数时,编译器将生成代码,在运行时确定调用哪个函数,被调用的是与动态类型相对应的函数。
有以下代码段:
void print_total(ostream &os,const Item_base &item,size_t n)
{
os<<”ISBN:”<<item.book()<<item.net_price(n)<<endl;
}
因为item形参是一个引用且net_price是一个虚函数,item.net_price(n)所调用的net_price版本取决于在运行时绑定到item形参item的实参类型。
Item_base base; Bulk_item derived; print_total(cout,base,10); print_total(cout,derived,10);
很明显,第一个函数调用基类版本,第二个函数调用派生类版本。引用和指针的动态类型和静态类型可以不同,这是C++支持多态性的基础。
在编译时确定非virtual调用
非虚函数总是在编译时根据调用该函数的对象,引用或指针的类型而确定的。调用的函数版本和该对象,引用或指针的类型保持一致。
虚函数与默认实参
虚函数可以有默认实参。默认实参将在编译时确定,如果一个调用省略了具有默认值的实参,则所用的值由调用该函数的类型定义,与对象的动态类型无关。默认实参的值将与调用该虚函数的指针或引用的类型保持一致。在同一个虚函数中的基类版本和派生类版本中使用不同的默认实参几乎总是会引起错误,因为C++有动态绑定的功能。
2、虚函数表的实现机制
虚函数机制的实现是通过一张叫做虚函数表实现的。虚函数表简单的来说是一张类的虚函数的地址表,它就像地图一样,指明了实际所应该调用的函数。C++编译器应该保证虚函数表的指针存在于对象实例中最前面的位置。借此可以由对象实例得到虚函数表的地址,然后遍历其中的函数指针,调用对应的函数。
对于下面的代码段,我们来详述虚函数表的实现:
class Base
{
public:
virtual void f(){cout<<”Base:f”<<endl;}
virtual void f(){cout<<”Base:f”<<endl;}
virtual void f(){cout<<”Base:f”<<endl;}
}
由于虚函数主要是通过继承来实现多态的,所以接下来我们从不同的继承方法来研究虚函数表,部分内容来自他人博客。在文章最后会给出参考的博客链接:
一般继承:
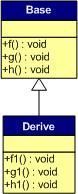
由简单的类图可以发现,子类没有重载父类的函数,那么在派生类实例中,其虚函数表如下,注意是在派生类实例的前提下。
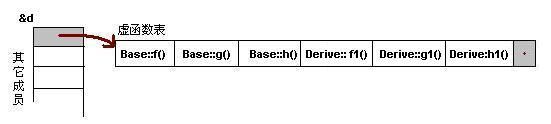
虚函数按照其声明顺序存放在虚函数表中,父类的虚函数在子类的虚函数前面。
一般继承,有函数重载;
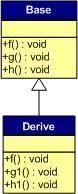
子类重载了基类的f函数,我们看看虚函数表发生了什么变化:

覆盖的f函数被放到了虚函数表中原来基类的虚函数的位置,其他的虚函数的位置保持不变。
Base *b=new Derive();
b->f();
由于b绑定了派生类对象,所以b所指的内存中的虚函数表的f的位置已经被派生类的函数地址所代替,于是实际调用,派生类的f函数被调用了。
多重继承;
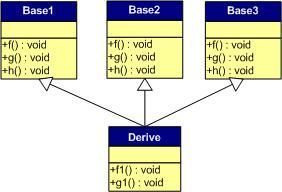
派生类实例对应的虚函数表如下:

每个基类的都有自己的虚函数表,派生类的成员函数被放到了第一个基类的虚函数表中。
多重继承,有重载的时候:
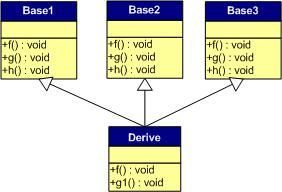
派生类覆盖了基类的f函数,此时虚函数表变为:
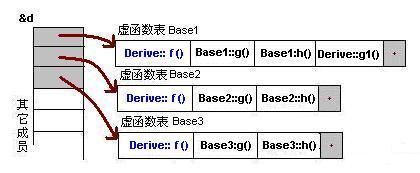
三个基类的虚函数表中的f函数的位置被替换为了派生类的f函数的地址。这样我们可以使用任一基类的对象的指针或引用来调用派生类对象的
3、线程安全的C++代码和内联函数的讨论
如果我们要开发一个线程安全的string类,使得这个类可以在win32环境下被并发线程安全的使用。在这种情况下,有多种用户模式级的同步方法可以使用。C++中的同步机制。分为用户模式的线程同步和内核对象的线程同步两大类。用户模式的同步方法,有原子访问和临界区等。内核对象的线程同步主要由事件,等待定时器,信号量等构成。使用时必须将线程从用户模式切换到内核模式。
临界区:通过对多线程的串行化来访问公共资源或一段代码。
临界区的两个操作原语:EnterCriticalSection()进去临界区,LeaveCriticalSection()离开临界区。只能用来同步本进程内的线程,而不能用来同步多个进程中的线程。
互斥量:为协调对一个共享资源的单独访问而设计的。
互斥对象只有一个,因此在任何情况此共享资源都不会同时被多个线程访问,互斥量比临界区复杂,因为使用互斥可以实现在不同的应用程序的线程之间实现资源的安全共享。
CreateMutex() 创建一个互斥量
OpenMutex()打开一个互斥量
ReleaseMutex()释放互斥量
WaitForSinglObjects()等待互斥量。
信号量:为控制一个具有有限数量的用户资源而设计。
信号量允许多个线程同时使用共享资源,它指出了同时访问共享资源的的线程的最大数目。
事件:用来通知线程有一些事情已经发生,从而启动后继任务的开始。
线程局部存储 (TLS),同一进程中的所有线程共享相同的虚拟地址空间。不同的线程中的局部变量有不同的副本,但是static和globl变量是同一进程中的所有线程共享的。使用TLS技术可以为static和globl的变量,根据当前进程的线程数量创建一个array,每个线程可以通过array的index来访问对应的变量,这样也就保证了static和global的变量为每一个线程都创建不同的副本。
了解了C++的线程同步方法,我们有以下三种设计方法可以实现线程安全的string 类:
硬编码:
可以从string类中派生出三个独立类:CriticalSectionString、MutexString和SemaphoreString。每个类实现各自的同步机制。
继承:
可以派生出单一的ThreadSafeString类,它包含了指向Locker对象的指针。在运行期间通过多态机制选择特定的同步机制。
模板:
基于模板的string类,该类由Locker类型参数化后得到。
这里着重介绍基于模板的方法,避免继承实现时由于虚函数调用lock()和unlock()仅在执行期间解析,因此不能实现内联。
template<class LOCKER>
class ThreadSafeString:public string{
public:
ThreadSafeString(const char *s):string(s){}
int length();
private:
LOCKER lock;
}
length函数的实现策略:
template<class LOCKER>
inline
int ThreadSafeString<LOCKER>::length()
{
lock.lock();
int len=string::length();
lock.unlock();
return len;
}
在具体调用的时候,只要传入相应的参数如CriticalSectionString或者MutexLock即可。这样的做的好处了是避免了对lock和unlock的虚函数调用,编译器可以解析这两个虚函数并内联他们。虚函数的代价在于无法内联函数调用,因为虚函数的调用实在运行时动态绑定的。唯一潜在的问题的效率问题是从内联获取的速度。但是对于内联对性能的贡献,我们还需要从新讨论,下面对内联是否能对效率有贡献做一个简单的讨论,后续专题中会对内联进行详细的解释。
内联的作用:编译时就可以将这个函数的拷贝直接放在每个使用这个函数的地方,避免函数 调用的发生。
内联函数会提高效率吗?
:不一定。
:首先需要问清你所指的效率是什么?是程序体积、内存占用、执行时间还是开发速度还是编译时间。
程序体积:如果编译器为了执行函数调用而不得不生成的代码的体积比内联函数的体积还小,此时会减小车工虚体积。
内存占用:对内存的使用几乎没有影响或者有很少影响。
执行时间:如果这个函数不是被频繁调用的时候,整个程序的执行时间通常不会有明显的改善,有可能还会适得其反,如果内联增加了函数调用的体积,它会降低调用者的引用局部性,如果调用者的内部指令循环不再和高速缓存的大小想匹配,整个程序的执行时间实际上会降低,大多数程序的瓶颈在与IO,带宽。
开发速度和编译时间:被内联的代码必须对调用者可见,调用者必须依赖与被内联代码的内部细节,这就增加了模块之间的耦合性。普通函数被修改时只需要重新链接即可,内联函数被修改时,必须要重新编译。
4、虚继承和对象类型探索
学习了上述的理论后,这里区分几个概念问题:
静态成员函数不能是虚函数,为什么?
因为静态成员函数是在编译时确定的,为这个函数分配共享的内存位置。而虚函数一般是用于C++的多态中是要进行动态绑定的。是在运行时确定的。
内联函数也不能是虚函数,因为内联函数也是在编译时确定的。
在编译时就能够确定哪个重载函数被调用的情况叫做先期联编,而在系统运行时,能够根据其类型确定哪个重载的成员函数被调用,则成为多态性,叫做滞后联编。
下面来学习一下虚继承,先来一个简单虚继承的实例程序:
class A:
{
public:
void fun();
protected:
int a;
};
class B: virtual public A
{
protected:
int b;
};
class C: virtual pulic A
{
protected:
int c;
};
class D: public B, public C
{
public:
int g();
protected:
int d;
};
对于上述代码,不同继承路径上的虚基类子对象在派生类中被合并成一个子对象了。在内存中,虚基类子对象是村放在派生类对象的所占内存块的尾部。
虚基类的构造函数:
初始化派生类的对象的时候,派生类的构造函数需要调用基类的构造函数。由于派生类对象中只有一个虚基类子对象,所以虚基类的构造函数只能被调用一次。如果继承层次很深,那么把真正创建对象的类称为最派生类。虚基类子对象是由最派生类通过调用虚基类的构造函数进行初始化的。如果一个派生类有一个直接或简间接的虚基类,那么派生类的构造函数成员初始化列表中必须列出对虚基类构造函数的调用,如果没有列出,则表示使用该虚基类的缺省构造函数来初始化派生类对象中 的虚基类子对象。
从虚基类直接或间接继承的派生类的成员初始化列表中必须列出对该虚基类构造函数的调用,但是只有真正用与创建该对象的那个最派生类的构造函数才会真正调用虚基类的构造函数。而该派生类的基类中所列出的对这个虚基类的构造函数的调用在实际执行中被忽略,这样就保证对虚基类的子对象只初始化一次。
C++又规定:在一个成员初始化列表中同时出现对虚基类和非虚基类的构造函数的调用时,则虚基类的构造函数限于非虚基类的构造函数被执行。由于只有在最派生生中才会真正调用虚基类的构造函数,所以在虚基类中一般不要生命任何数据成员,避免某些上层子类得到的某些虚基类子对象不是自己真正需要的。所以虚基类一般做为接口生命。
关于C++的对象类型的构造,将会在一些高级主题中提到。
5、习题自测
有如下代码,分析其执行结果:
#include "stdafx.h"
#include "stdio.h"
#include "string.h"
class Father
{
public:
name()
{printf("father name\n");};
virtual call()
{printf("father call\n");};
};
class Son: public Father
{
public:
name()
{printf("Son name\n");};
virtual call()
{printf("Son call\n");};
};
main()
{
Son *Son1=new Son();
Father *father1=(Father *)Son1;
father1->call();
father1->name();
((Son *)(father1))->call();
((Son *)(father1))->name();
Father *f2=new Father();
Son *s2=(Son*)f2;
s2->call();
s2->name();
((Father *)(s2))->call();
((Father *)(s2))->name();
}
虚函数的调用是通过虚函数指针调用,如果new的对象是Son的,则不管他转换成什么指针,他的指针都是Son内部的,与指针类型无关,只与指针地址有关。
非虚函数的调用则是由指针类型决定的。
执行结果:
son call
:father1指向的是son1的指针,在虚函数表中位置不变。
father name
:son1指针转换为了Father类型,则调用基类类型的非虚函数。
son call
:这个指针依然是son1类型的。
son name
:但是指针类型转换为派生类对象了,则调用子类的函数。
father call
:f2是基类类型的
Son name
:s2转换为派生类类型了
father call
:依然是基类类型
father name
:转换为基类类型。
理解上述运算结果,不仅要知道虚函数在继承层次下的的动态绑定特性和非虚函数的调用特征,还需要掌握在继承层次下类类型指针的类型转换规则和内部实现。
在C++中,指针的类型转换是经常发生的事情。需要把派生类指针转换为基类指针,将基类指针转换为派生类指针。指针的本质是一个整数,用以记录虚拟内存空间中的地址编号,而指针的类型决定了编译器对其指向的内存空间的解释方式。
#include <iostream>
using namespace std;
class CBaseA
{
public:
char m_A[32];
};
class CBaseB
{
public:
char m_B[64];
};
class CDerive : public CBaseA, public CBaseB
{
public:
char m_D[128];
};
int main()
{
auto pD = new CDerive;
auto pA = (CBaseA *)pD;
auto pB = (CBaseB *)pD;
cout << pA << '\n' << pB << '\n' << pD << endl;
cout << (pD == pB) << endl;
}
0x9f1080
0x9f10a0
0x9f1080
1
可以看出,指向同一个堆上new出来的对象指针,经过类型转换之后,其值会发生改变。其原因是由C++中多重继承的内存布局说起。new Cderive执行之后,生成的内存布局如下:
则pD针只想这段内存的起始位置,而pB与pD的差值正好是CBaseA占用的内存大小32字节。而pA与pD都指向了同一段地址。:将一个派生类的指针转换为某一个基类的指针,编译器会将指针的值偏移到该基类在对象内存中的起始位置。
可是为什么pB和pD做等运算后,却输出的值是1呢?这是因为当编译器发现一个指向派生类的指针和指向某个基类的指针进行==运算时,会自动将指针做隐士类型提升已屏蔽多重继承带来的指针差异,只要两个指针指向同一个内存实例。就认为他们两个是相等的。
此时再回过头来解释那个虚函数那个题目。
6、区分const char*, char const* and char *const 的区别
这三个概念很容易混淆。Bjarne在他的The C++ Programming Language里面给出一种方法,把一个声明从右向左读。
char *const cp; (*都成pointer to)
cp is a const pointer to char
const char *p;
p is a pointer to const char;
C++标准规定,const关键字放在类型或者变量名之前是等价的。
第三种情况和第二种情况一样。
Const int n=5; 和int const m=10;是等价的。
参考资料:
C++ Primer
深入探索C++对象模型
提高C++编程性能的技术
http://blog.csdn.net/haoel/article/details/1948051/
http://www.cnblogs.com/yangyh/archive/2011/06/04/2072393.html
http://destiny6.blog.163.com/blog/static/34241669201072524612781/