C语言描述数据结构 —— 单链表OJ题
1.移除链表元素
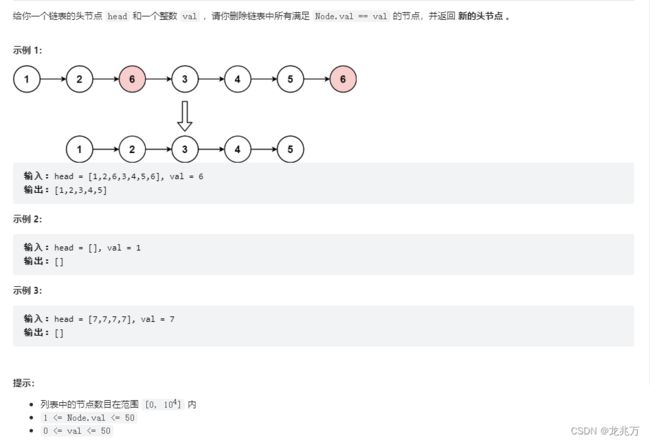
对于这个题,我们有两种解题方法:
方法一:我们要删除指定数值的结点,我们可以定义一个指针 cur ,这个指针用来负责遍历指定数值的结点,也是遍历结束的条件。那么还需要一个指针 prev ,这个指针负责指向 cur ,负责串联链表。如果没有 prev 指针,当指定数值的结点释放后,链表就“断”了。
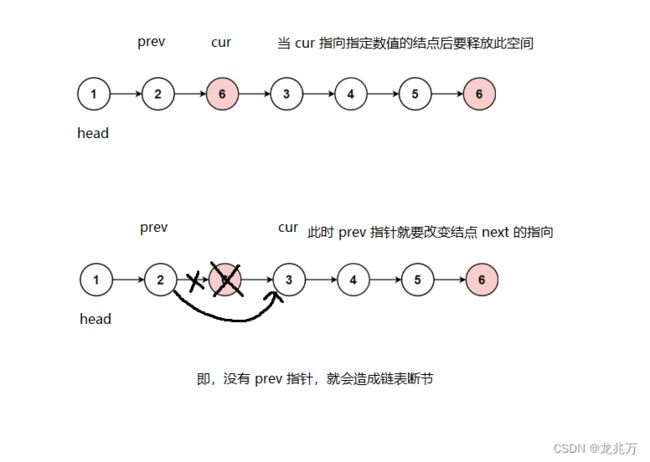
我们的代码就可以这样写:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* cur=head;
struct ListNode* prev=NULL;
while(cur)
{
if(cur->val == val)
{
//头删
if(cur == head)
{
head = head->next;
free(cur);
cur=head;
}
//非头删
else
{
cur=cur->next;
free(prev->next);
prev->next=cur;
}
}
else
{
prev=cur;
cur=cur->next;
}
}
return head;
}方法二:我们像操作数组那样,将不是指定数值结点复制到新的链表当中。这种思路无疑是最容易想到的。那么我们就需要一个新链表 newnode ,并且满足复制的结点都是尾插,为了方便尾插我们还需要一个用来存储尾结点地址的指针 tail ,这个方法我们在介绍单链表时说明过。那么我们就直接上代码了:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* newhead = NULL;//新链表的头
struct ListNode* tail=NULL;//尾
struct ListNode* cur=head;//遍历指定数值结点、结束条件
while(cur)
{
//不是指定数值结点就尾插到新链表
if(cur->val != val)
{
if(newhead == NULL)
{
newhead = tail = cur;
}
else
{
tail->next=cur;
tail=tail->next;
}
cur=cur->next;
}
//如果是指定链表的结点就释放结点
else
{
struct ListNode* del = cur;
cur=cur->next;
free(del);
}
}
//如果测试用例提供的链表是空链表,没有 if 的话,就会报对空指针解引用的错误
if(tail)
tail->next=NULL;
return newhead;
}不过我们一定要注意野指针的问题,因为如果指定数值的结点在链表的最后一个结点,那么新链表的最后一个结点的指针指向的并不是一个空指针。

那么对于方法二,我们可以在上面代码的基础上再简化一下代码。只不过我们需要使用一个新的链表,带头单链表,这个头也叫哨兵卫,是一个结点,这个结点是不存储任何有效数据的。那我们简化的代码就可以这么写:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* guard = (struct ListNode*)calloc(1,sizeof(struct ListNode));
struct ListNode* cur=head;
struct ListNode* tail=guard;
while(cur)
{
if(cur->val != val)
{
tail->next=cur;
tail=tail->next;
cur=cur->next;
}
else
{
struct ListNode* del = cur;
cur=cur->next;
free(del);
}
}
if(tail)
tail->next=NULL;
head = guard->next;
free(guard);
return head;
}2.合并两个有序链表
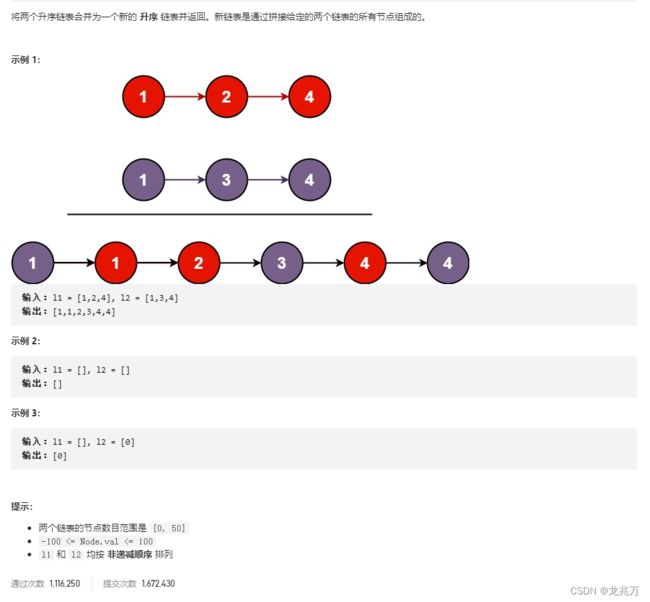
在解这个题之前我们先来了解一个算法,这个算法无论是顺序表还是链表都可以用。假设我们有两组数字,一组是 1、2、4,另一组是 1、3、4,我们现在要将他们合并,并且合并之后的顺序是升序排列。我们便可以这样做:

我们有了这个算法理论基础,就可以对链表进行操作了。我们需要注意,我们将使用带头单向链表来完成这个题目,因为带有哨兵卫的链表可以少一个判空的环节,一定程度上减少了代码量。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* guard = (struct ListNode*)calloc(1,sizeof(struct ListNode));
guard->next=NULL;//针对两个链表都是空链表的情况,避免野指针
struct ListNode* cur1=list1;
struct ListNode* cur2=list2;
struct ListNode* tail = guard;
while(cur1 && cur2)
{
if(cur1->val < cur2->val)
{
tail->next=cur1;
tail=tail->next;
cur1=cur1->next;
}
else
{
tail->next=cur2;
tail=tail->next;
cur2=cur2->next;
}
}
//不管是哪个链表的数据没有放完
if(cur1)
tail->next=cur1;
if(cur2)
tail->next=cur2;
struct ListNode* head=guard->next;
free(guard);
return head;
}3.反转链表
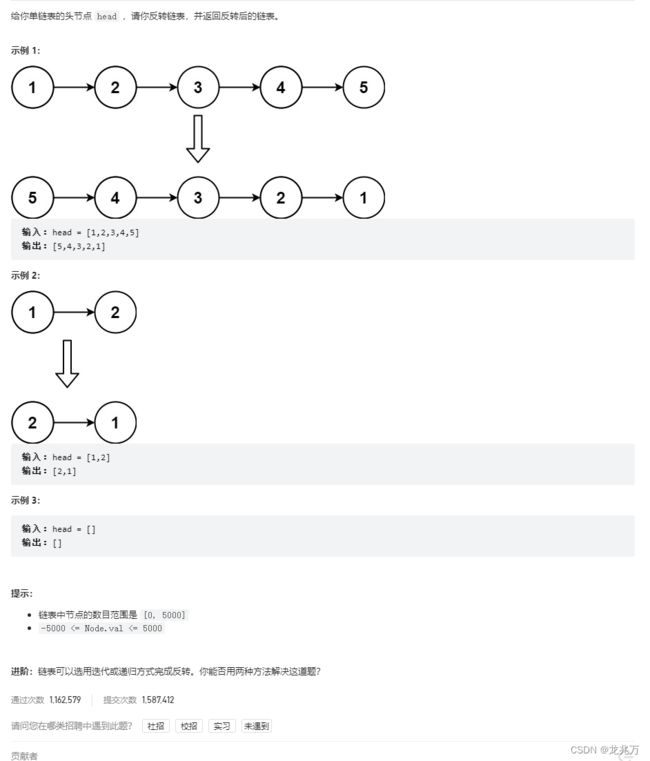
这道题我们也可以有两个思路,那么对于我们来说,最容易想到的就是直接改变箭头的方向。那么实现这样的操作也非常简单,我们看图来分析这个算法的原理。

struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* n1=NULL;
struct ListNode* n2=head;
struct ListNode* n3=NULL;
while(n2)
{
n3=n2->next;
n2->next=n1;
//迭代
n1=n2;
n2=n3;
}
return n1;
}那么另一种思路更加巧妙,在我们之前介绍单链表了解了头插,那么对于这个题我们也可以使用头插。

struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* cur = head;
struct ListNode* next=NULL;
struct ListNode* newhead = NULL;
while(cur)
{
next = cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
return newhead;
}4.链表的中间结点

对于这题,我们一般都会这么去想,先遍历一遍链表,计算有多少个结点,然后除以 2 ,即可得到中间结点距离头结点有多远,然后再回到头结点再次遍历一遍链表,只不过这次遍历的长度是计算的距离。这个算法是比较差的,虽然简单,但是毕竟它遍历了两遍链表。那么现在我们介绍一个算法,即快慢指针,只需要遍历一遍,就可以得到中间结点的位置。

struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* slow=head;
struct ListNode* fast=head;
while(fast && fast->next)
{
slow=slow->next;
fast=fast->next->next;
}
return slow;
}5.链表中倒数第k个结点

这个题与上一道题类似,我们可以采用遍历两边的方法来解决这道题。但是我们说了,没有必要。我们同样可以使用快慢指针的方法来解决这道题。

struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
// write code here
struct ListNode* fast=pListHead;
struct ListNode* slow=pListHead;
while(k--)
{
if(fast == NULL)//如果是空链表就直接返回空
return fast;
fast=fast->next;
}
while(fast)
{
fast=fast->next;
slow=slow->next;
}
return slow;
}6.链表分割

我们学习过单链表的增删查改,那么这道题的关键就在于不能改变原来的数据顺序。如果我们定义一条新的链表的话,尾插就不会改变原来的数据顺序。而且上面介绍过带有哨兵卫的链表,那么这道题也可以使用这种链表。我们通过画图的形式来表达我的想法:

我们有了想法之后,就可以用代码表达出来
ListNode* partition(ListNode* pHead, int x)
{
// write code here
struct ListNode* guard1 = (ListNode*)calloc(1,sizeof(ListNode));
struct ListNode* guard2 = (ListNode*)calloc(1,sizeof(ListNode));
struct ListNode* tail1=guard1;
struct ListNode* tail2=guard2;
struct ListNode* cur = pHead;
//初始化,参数如果是空链表,避免野指针的问题
tail1->next = NULL;
tail2->next = NULL;
while(cur)
{
if(cur->val < x)
{
tail1->next=cur;
tail1=tail1->next;
}
else
{
tail2->next=cur;
tail2=tail2->next;
}
cur=cur->next;
}
tail1->next = guard2->next;//链接
tail2->next=NULL;//手动置空
pHead = guard1->next;
free(guard1);
free(guard2);
return pHead;
}7.链表的回文结构

这道题就是典型的判断回文,回文就是从前读和从后读的数据是一样的,比如 1、2、3、2、1,1、6、6、1 等。那么对于链表来说也是可以这样去读的。我们需要一个原链表逆置后的新链表,这个新链表再与原链表对比即可。
struct ListNode* CreateNode(int val)
{
struct ListNode* newnode=(struct ListNode*)malloc(sizeof(struct ListNode));
newnode->val=val;
newnode->next=NULL;
return newnode;
}
bool isPail(struct ListNode* head ) {
// write code here
struct ListNode* newhead=NULL;
struct ListNode* cur=head;
//建立新的反转链表。若不建立则会改变原链表的结构
while(cur)
{
struct ListNode* newnode=CreateNode(cur->val);
if(newhead == NULL)
{
newhead=newnode;
}
else
{
newnode->next=newhead;
newhead=newnode;
}
cur=cur->next;
}
while(head && newhead)
{
if(head->val != newhead->val)
{
return false;
}
head=head->next;
newhead=newhead->next;
}
return true;
}8.相交链表

这道题的整体思路还是快慢指针,我们可以这样看相交链表:


struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
struct ListNode* curA = headA;
struct ListNode* curB = headB;
int lenA=0;
int lenB=0;
while(curA)
{
lenA++;
curA=curA->next;
}
while(curB)
{
lenB++;
curB=curB->next;
}
//计算链表长度后指针位置归位
curA=headA;
curB=headB;
//curA始终是长链表
if(lenA < lenB)
{
struct ListNode* tmp =curA;
curA=curB;
curB=tmp;
}
//计算长链表先走几步
int gap=abs(lenA-lenB);
while(gap--)
{
curA=curA->next;
}
//找相交点
while(curA != curB)
{
curA=curA->next;
curB=curB->next;
}
return curA;
}9.环形链表
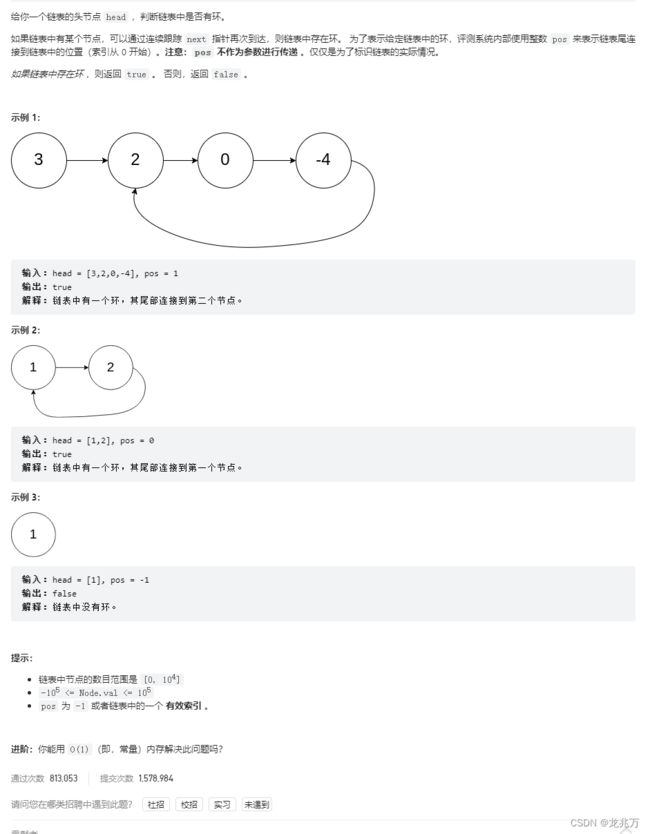
这道题目的要求是判断是否为环,我们最容易想到的方法是找到入环点然后在环绕一圈看环内是否有入环点。但事实上这种方法效率非常低,而且代码也比较复杂。正确的思路应该是快慢指针,将它看成一个追赶问题。我们引出这样一个问题:

我们就运用这个思维,建立两个快慢指针。这两个指针一直在链表上走,那么必定会形成上面的问题,只要两个指针相遇,就可以证明链表有环。

bool hasCycle(struct ListNode *head)
{
struct ListNode* fast=head;
struct ListNode* slow=head;
//如果不是环,那么必定有空
while(fast && fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast == slow)
return true;
}
return false;
}那么我们衍生一个问题,如果快指针的速度为 3 会怎么样?那么此时的相对速度就是 2 ,也就是每次行动,快指针会每次走两步,但是如果环的长度是一个奇数,那么最近的一次必定会是 1 ,但是快指针每次只走两步,此时快指针是永远不可能与慢指针重叠的。但如果环的长度是偶数,那么就必定会重叠。这是一个数学问题,大家仔细分析就能得到其中的逻辑。
10.环形链表的相交结点
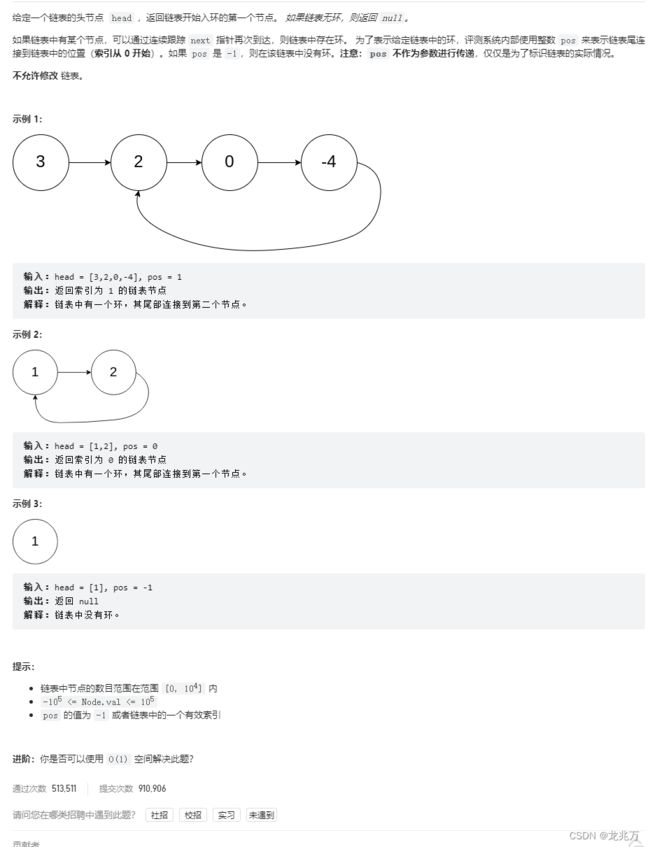
这道题是上一道题的衍生,上一道题让我们证明环形链表,这道题让我们求环形链表的环入口。我们可以通过数学公式来分析,最后用代码实现。

struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* fast = head;
struct ListNode* slow = head;
struct ListNode* ret=NULL;//定义相遇点的新指针
while(fast && fast->next)
{
fast = fast->next->next;
slow=slow->next;
//找到相遇点
if(fast == slow)
{
ret = fast;
while(ret && ret->next)
{
//先判断,再同时走,因为相遇点也可能是环的入口点
if(ret == head)
return ret;
ret = ret->next;
head = head->next;
}
}
}
return NULL;
}那如果我们脑子并没有这么灵活,公式法想不到怎么办?我们还有另外一种方法,把这个问题转换为相交链表问题。这个思路简单,但是代码比较复杂。
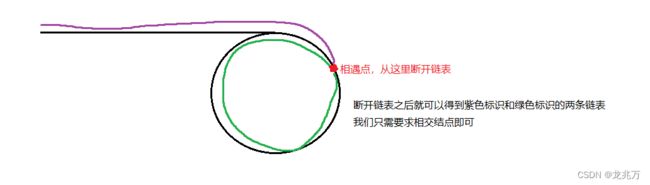
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* fast = head;
struct ListNode* slow = head;
struct ListNode* Next=NULL;//新链表
while(fast && fast->next)
{
fast = fast->next->next;
slow=slow->next;
//找到相遇点
if(fast == slow)
{
Next=fast->next;//新链表的起始位置
fast->next=NULL;//断开链表
}
}
struct ListNode* curA=head;
struct ListNode* curB=Next;
int lenA=0;
int lenB=0;
while(curA)
{
lenA++;
curA=curA->next;
}
while(curB)
{
lenB++;
curB=curB->next;
}
if(lenAnext;
}
while(head != Next)
{
head=head->next;
Next=Next->next;
}
return head;
return NULL;
} 11.复制带随机指针的链表

可以发现,这道题的难点不在于复制,而是确定随机指针的指向位置。我们有两个思路,我们先谈谈第一个思路,这个思路可以说是一种暴力的解题方法。
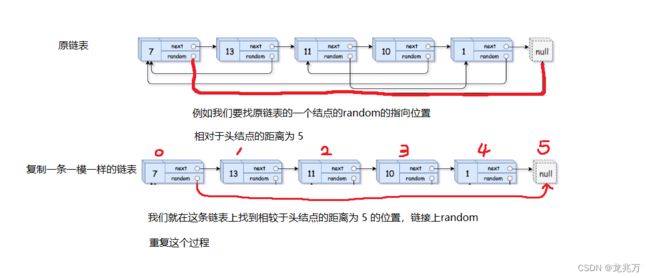
那么用代码描述也不困难:
struct Node* copyRandomList(struct Node* head) {
struct Node* cur=head;
struct Node* tail=NULL;
struct Node* newhead=NULL;
//复制一条一模一样的链表
while(cur)
{
struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));
newnode->val=cur->val;
newnode->next=NULL;
//尾插法复制结点
if(tail == NULL)
{
tail = newnode;
newhead=newnode;
}
else
{
tail->next=newnode;
tail=tail->next;
}
//迭代
cur = cur->next;
}
cur=head;//归位
struct Node* copy=newhead;//记录新链表的头结点
while(cur)
{
int num=0;
struct Node* newcur=head;
struct Node* tmp=newhead;
//找每个结点random指向的位置相较于头结点的距离
while(cur->random != newcur)
{
num++;
newcur=newcur->next;
}
//在新链表中找到这个距离的位置
while(num--)
{
tmp=tmp->next;
}
copy->random=tmp;
//下一个结点
copy=copy->next;
cur=cur->next;
}
return newhead;
}但是大家要明白一个点,这个算法的效率是非常低的,时间复杂度是 O(N^2) 。所以我们还有另外一种算法。
那么另一种算法呢,极为巧妙,也是对上一种算法的优化,时间复杂度只有 O(N) 。效率大大提升,并且代码可读性也相对较高。那么现在我们就来分析一下这个算法。
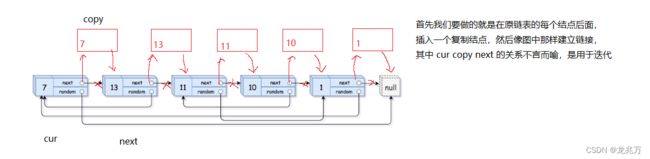


struct Node* copyRandomList(struct Node* head) {
struct Node* cur=head;
struct Node* copy = NULL;
struct Node* next=NULL;
//在结点后插入结点
while(cur)
{
copy = (struct Node*)malloc(sizeof(struct Node));
next=cur->next;
cur->next=copy;
copy->next=next;
copy->val=cur->val;
//迭代
cur=next;
}
//建立random链接
cur=head;
while(cur)
{
copy=cur->next;
next=copy->next;
if(cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
//迭代
cur=next;
}
//分解链表
struct Node* newhead=NULL;
struct Node* newtail=NULL;
cur=head;
while(cur)
{
copy=cur->next;
next=copy->next;
if(newtail == NULL)
{
newhead = newtail = copy;
}
else
{
newtail->next=copy;
newtail=newtail->next;
}
cur->next=next;
cur=next;
}
return newhead;
}