Mysql练习——建立一张员工信息表employees,字段包括员工姓名、员工号、所属部门、职位、奖金(可为空)、每月薪资。
文章目录
- 一、建立一张员工信息表employees,字段包括员工姓名、员工号、所属部门、职位、奖金(可为空)、每月薪资。
- 二、数据查询
-
- 查询指定列
- 查询全部列
- 消除取值重复的行
- 比较大小
- 确定范围
- 确定集合
- 涉及空值的查询
- 多重条件查询
- order by子句
- group by子句
- 聚集函数
- 验证
- count用法
一、建立一张员工信息表employees,字段包括员工姓名、员工号、所属部门、职位、奖金(可为空)、每月薪资。
建立数据表employees
create table employees(
em_name varchar(255) not null comment '员工姓名',
em_id int primary key comment '员工号',
em_part int comment '所属部门',
em_job varchar(255) comment '职位',
em_salary int not null comment '奖金',
math_salary int not null comment '每月薪资'
);

- 查询员工号为5的员工的姓名和部门号和年薪。年薪=每月薪资*12
SELECT 员工姓名, 所属部门, 每月薪资*12 AS 年薪
FROM employees
WHERE 员工号 = 5;
- 选择工资不在5000到12000的员工的姓名和工资
SELECT 员工姓名, 每月薪资 AS 工资
FROM employees
WHERE 每月薪资 NOT BETWEEN 5000 AND 12000;
- 选择在20或50号部门工作的员工姓名和部门号
SELECT 员工姓名, 所属部门
FROM employees
WHERE 所属部门 IN (20, 50);
- 选择姓名中有字母a和e的员工姓名
SELECT 员工姓名
FROM employees
WHERE 员工姓名 LIKE '%a%' AND 员工姓名 LIKE '%e%';
- 显示出表employees部门编号在80-100之间的姓名﹑职位。
SELECT 员工姓名, 职位
FROM employees
WHERE 所属部门 BETWEEN 80 AND 100;
- 将姓名中包含e字符的年薪和姓名显示出来,并且按年薪进行降序。
SELECT 员工姓名, 每月薪资*12 AS 年薪
FROM employees
WHERE 员工姓名 LIKE '%e%'
ORDER BY 年薪 DESC;
- 显示所有有奖金的员工姓名﹑奖金,按奖金从低到高排序。
SELECT 员工姓名, 奖金
FROM employees
WHERE 奖金 IS NOT NULL
ORDER BY 奖金 ASC;
- 按部门编号升序,部门内按工资降序排列。
SELECT 员工姓名, 所属部门, 每月薪资 AS 工资
FROM employees
ORDER BY 所属部门 ASC, 工资 DESC;
- 显示所有有奖金的员工姓名﹑奖金,按奖金从低到高排序。
SELECT 员工姓名, 奖金
FROM employees
WHERE 奖金 IS NOT NULL
ORDER BY 奖金 ASC;
- 按部门编号升序,部门内按工资降序排列。
SELECT 员工姓名, 所属部门, 每月薪资 AS 工资
FROM employees
ORDER BY 所属部门 ASC, 工资 DESC;
- 查询各部门中员工工资的最大值、最小值、平均值、工资和
SELECT 所属部门,
MAX(每月薪资) AS 最高工资,
MIN(每月薪资) AS 最低工资,
AVG(每月薪资) AS 平均工资,
SUM(每月薪资) AS 工资总和
FROM employees
GROUP BY 所属部门;
- 在上一题题的基础上,按照部门编号升序返回结果
SELECT 所属部门,
MAX(每月薪资) AS 最高工资,
MIN(每月薪资) AS 最低工资,
AVG(每月薪资) AS 平均工资,
SUM(每月薪资) AS 工资总和
FROM employees
GROUP BY 所属部门
ORDER BY 所属部门 ASC;
- 查询各部门中有奖金的员工的最低工资,其中最低工资不能低于3000
SELECT 所属部门, MIN(每月薪资) AS 最低工资
FROM employees
WHERE 奖金 IS NOT NULL AND 每月薪资 >= 3000
GROUP BY 所属部门;
- 查询所有部门的编号,员工数量和工资平均值,并按平均工资降序
SELECT 所属部门, COUNT(*) AS 员工数量, AVG(每月薪资) AS 平均工资
FROM employees
GROUP BY 所属部门
ORDER BY 平均工资 DESC;
- 查询部门编号为2、职位为经理的人员信息
SELECT *
FROM employees
WHERE 所属部门 = 2 AND 职位 = '经理';
- 查询属于2号、4号、5号部门的员工信息
SELECT *
FROM employees
WHERE 所属部门 IN (2, 4, 5);
或者
SELECT *
FROM employees
WHERE 所属部门 = 2 OR 所属部门 = 4 OR 所属部门 = 5;
二、数据查询
语句格式
select [all|distinct]
from <表名或视图名>|(select语句) [as]<别名>
[where <条件表达式>]
[group by <列名1>[having <条件表达式>]]
[order by <列名2>[asc|desc]]
●SELECT子句︰指定要显示的属性列
●FROM子句:指定查询对象(基本表或视图)
●WHERE子句:指定查询条件
●GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。
●HAVING短语:只有满足指定条件的组才予以输出
●ORDERBY子句:对查询结果表按指定列值的升序或降序排序
查询指定列
查询全体学生的学号与姓名。
select 学号,姓名
from 表名;
查询全部列
select 姓名,性别,年龄,学号
from 表名;
或
select *from 表名;
消除取值重复的行
如果没有指定distinct关键词,则缺少为all
select 字段名 from 表名;
等价于
select all 字段名 from 表名;
指定distinct关键词,去掉表中重复的行
select distinct 字段名 from 表名;
distinct后不准带括号;
比较大小
查询考试成绩有不及格的学生的学号
select distinct 学号
from 表名
where 成绩<60;
确定范围
between…and…
not between…and…
查询年龄在20-23(包括20-23岁)之间的学生的姓名、系别、年龄
select 姓名,系别,年龄
from 表名
where 年龄 between 20 and 30;
确定集合
in<>
not in<>
查询计算机科学系,数学系和信息系学生的姓名和性别
select 姓名,性别
from student
where 系别 in('计算机科学系','数学系','信息系');
涉及空值的查询
is null或is not null
is 不能用 = 代替
某些学生选修课程后没有参加考试,所以有选课记录,但没 有考试成绩。查询缺少成绩的学生的学号和相应的课程号
SELECT 学号,课程号
FROM 表名
WHERE 成绩 IS NULL
多重条件查询
and 的优先级高于or
可以用括号改变优先级
查询计算机系年龄在20岁以下的学生姓名
SELECT 字段名
FROM 表名
WHERE 系别= '计算机系' AND 年龄<20;
order by子句
可以按一个或多个属性列排序
升序asc,降序desc
查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列
SELECT *
FROM 表名
ORDER BY 系别, 年龄 DESC;
group by子句
- 如果未对查询结果分组,聚集函数将作用于整个查询结果
- 对查询结果分组后,聚集函数将分别作用于每个组
- 按指定的一列或多列值分组,值相等的为一组
having短语与where子句的区别:
- 作用对象不同
- WHERE子句作用于基表或视图,从中选择满足条件的元组
- HAVING短语作用于组,从中选择满足条件的组
聚集函数
- 统计元组个数
COUNT(*) - 统计一列中值的个数
COUNT([DISTINCT|ALL] <列名>) - 计算一列值的总和(此列必须为数值型)
SUM([DISTINCT|ALL] <列名>) - 计算一列值的平均值(此列必须为数值型)
AVG([DISTINCT|ALL] <列名>) - 求一列中的最大值和最小值
MAX([DISTINCT|ALL] <列名>)
MIN([DISTINCT|ALL] <列名>)
验证
验证一下如果查新长度为2的姓名 以洋结尾
前面应该是一个下划线还是俩
因为一个下划线代表一个字符
一个汉字占两个字符
验证:
select *from test where name like '_洋';
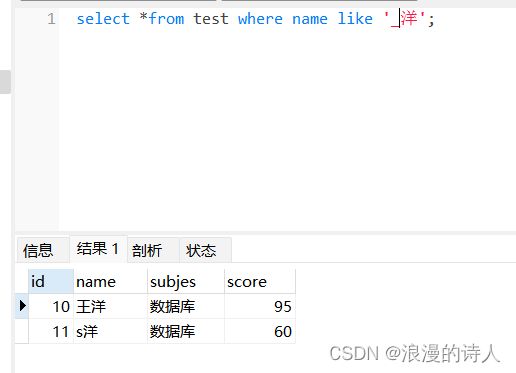
select *from test where name like '__洋';

count用法
- count(*)
返回表中的记录数(包括所有列),相当于统计表的行数(不会忽略列值为NULL的记录)
- count(1)
忽略所有列,1表示一个固定值,也可以用count(2)、count(3)代替(不会忽略列值为NULL的记录)
- count(列名)
返回列名指定列的记录数,在统计结果的时候,会忽略列值为NULL的记录(不包括空字符串和0),即列值为NULL的记录不统计在内
- count(distinct 列名)
只包括列名指定列,返回指定列的不同值的记录数,在统计结果的时候,在统计结果的时候,会忽略列值为NULL的记录(不包括空字符串和0),即列值为NULL的记录不统计在内。