数据库操作系列-Mysql, Postgres常用sql语句总结
文章目录
-
- 1.如果我想要写一句sql语句,实现 如果存在则更新,否则就插入新数据,如何解决?
-
- MySQL数据库实现方案: ON DUPLICATE KEY UPDATE
-
- 写法
- Postgres数据库实现方案:
-
- 方案1:
- 方案2:
- 关于更新:如何实现,当app_name数据存在,就更新details呢??
- 2.模糊查询+不区分大小写
- 3. 查询某个字段是否属于多个值中的一个,或者说,等于多个值中的一个就筛选出来
- 4. 时间范围查询
- 5. Postgres数据库如何使用dbever批量添加字段,设置类型
-
- 1. 新建一张表
- 2. 打开一个sql编辑器
- 3. 编写sql语句,下面给大家一些参考句子
- 4. 执行语句
- 5. 建表成功
- 6. 一些常用的Mysql简单指令
-
- 丢弃指定的数据库,如果存在的话
- 创建新的数据库
- 进入数据库tangdoudou
- 创建表
- 向表中插入数据
- 查询表中所有数据
- 修改数据
- 删除数据
- 一些常用栗子:
-
- 丢弃指定的数据库tangdoudou,如果存在
- 创建一个新的数据库
- 进入数据库tangdoudou
- 创建保存学生数据的表(编号、姓名、性别、分数);
- 往学生表中插入数据
- 修改编号为2的学员成绩为100,姓名为lucy;
- 删除编号为3的学员数据
- 查询学生表内容
- 待继续补充
-
- 欢迎路过的小哥哥小姐姐们提出更好的意见哇~~
1.如果我想要写一句sql语句,实现 如果存在则更新,否则就插入新数据,如何解决?
MySQL数据库实现方案: ON DUPLICATE KEY UPDATE
在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与
表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表
中记录的唯一索引或者主键不重复,则执行新记录插入操作。
简而言之:数据存在则更新,无则创建
写法
INSERT INTO 表名
(字段名1, 字段名2 )
VALUES
(字段值1, 字段值2)
ON DUPLICATE KEY UPDATE
字段名1 = VALUES(字段名1),
字段名2 = VALUES(字段名2)
Postgres数据库实现方案:
注意事项:
- ON CONFLICT 只在 PostgreSQL 9.5 以上可用。
- 做判断的字段必须有索引约束。例如Unique唯一索引做约束
方案1:
假如我们有这个app表,现在把其中一列name设置为unique

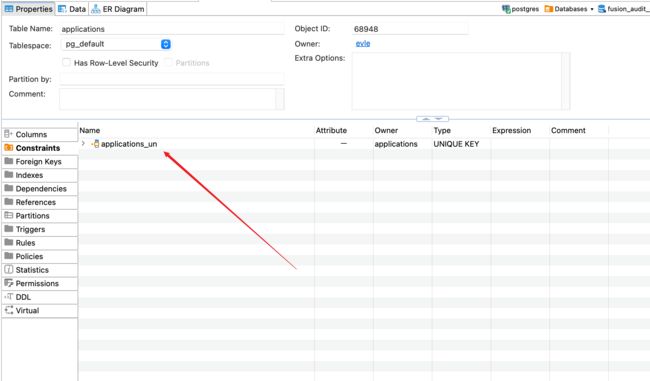
ALTER TABLE public.applications ADD CONSTRAINT applications_un UNIQUE (name);
然后我们去写代码

这个语句: 当数据存在时,什么都不做(DO NOTING)
const insertApp = await client.query(`INSERT INTO applications
(app_name, details )
VALUES
('${appName}', '${appDetail}')
ON CONFLICT ON CONSTRAINT applications_un
DO NOTHING;
`);
方案2:
下面的语句有一样的效果,区别在于使用的是 name 字段,而不是约束的名字
INSERT INTO customers (app_name, details)
VALUES
(
'AAA',
'BBBBBB'
)
ON CONFLICT (name)
DO NOTHING;
关于更新:如何实现,当app_name数据存在,就更新details呢??
INSERT INTO customers (app_name, details)
VALUES
(
'AAA',
'BBBBBB'
)
ON CONFLICT (name)
DO
UPDATE
SET email = 'CCCCCCCC';
upsert
使用相同变量,多次执行这段逻辑,我们会发现只创建了一条,所以是成功的~~~
2.模糊查询+不区分大小写
举个栗子:从users表里查询details信息和user_name信息包含字母’xiaojin’
select * from users where lower(details) like '%xiaojin%' or lower(user_name) like '%xiaojin%'
3. 查询某个字段是否属于多个值中的一个,或者说,等于多个值中的一个就筛选出来
举个栗子: 从users表查询type类型为Admin 或者 Super Admin
select * from users where "type" in ('Admin', 'Super Admin')
4. 时间范围查询
举个栗子: 我想查询users表created_at字段从2023-08-01 00:00:00.000 到2023-08-10 00:00:00.000范围内的数据
select * from users where created_at between '2023-08-01 00:00:00.000' and '2023-08-10 00:00:00.000'
5. Postgres数据库如何使用dbever批量添加字段,设置类型
1. 新建一张表
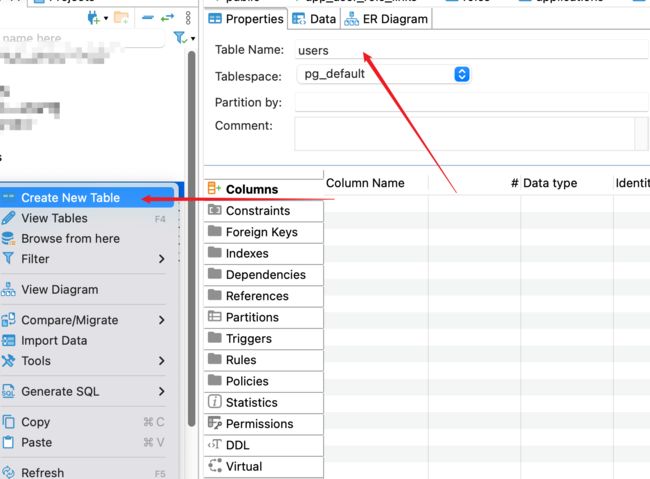
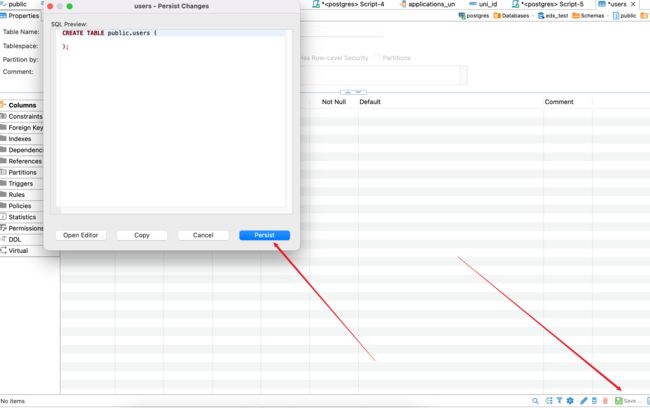
2. 打开一个sql编辑器
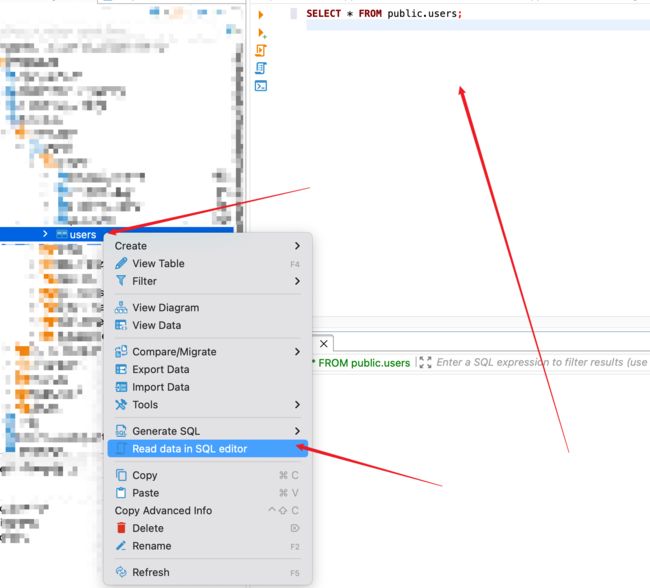
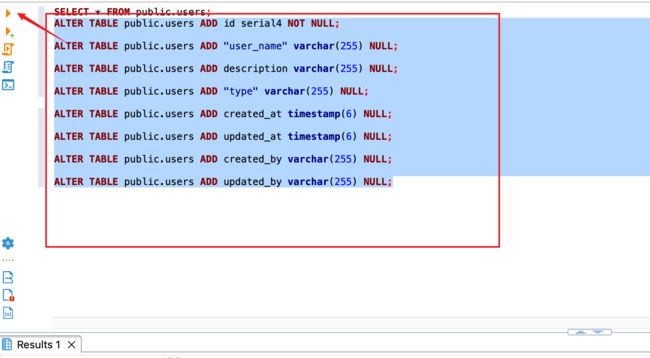
3. 编写sql语句,下面给大家一些参考句子
ALTER TABLE public.users ADD id serial4 NOT NULL;
ALTER TABLE public.users ADD "user_name" varchar(255) NULL;
ALTER TABLE public.users ADD description varchar(255) NULL;
ALTER TABLE public.users ADD "type" varchar(255) NULL;
ALTER TABLE public.users ADD created_at timestamp(6) NULL;
ALTER TABLE public.users ADD updated_at timestamp(6) NULL;
ALTER TABLE public.users ADD created_by varchar(255) NULL;
ALTER TABLE public.users ADD updated_by varchar(255) NULL;
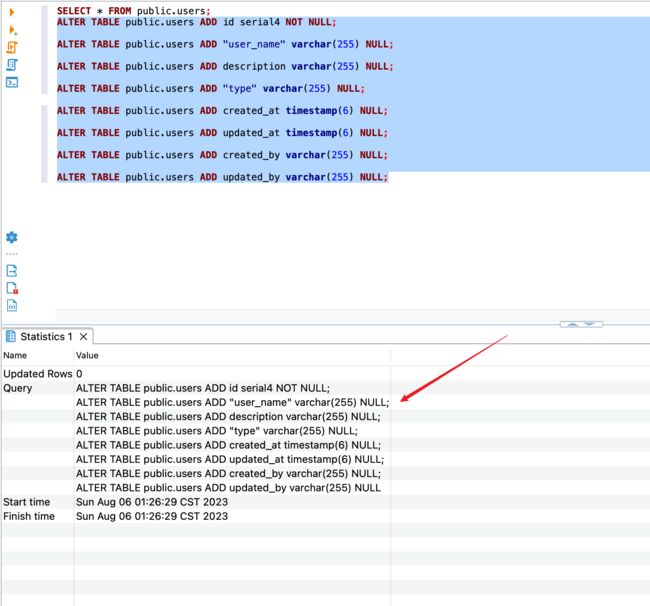
4. 执行语句
5. 建表成功
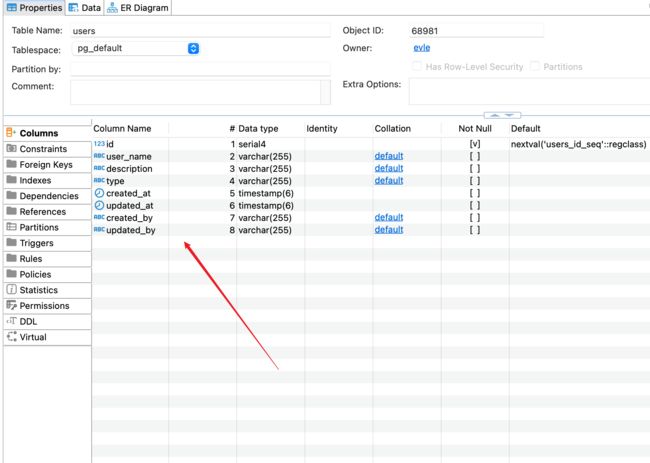
6. 一些常用的Mysql简单指令
丢弃指定的数据库,如果存在的话
DROP DATABASE IF EXISTS tangdoudou;
创建新的数据库
CREATE DATABASE tangdoudou;
进入数据库tangdoudou
USE tangdoudou;
创建表
CREATE TABLE student (
sid INT, # integer 整形
name VARCHAR(8), # variable character可变字符
sex VARCHAR(1), # m->男 f->女
score INT
);
向表中插入数据
INSERT INTO student VALUES('1','tom','F','95');
查询表中所有数据
SELECT * FROM student;
修改数据
UPDATE student SET name='lucy',score='100' WHERE sid='2';
删除数据
DELETE FROM student WHERE sid='3';
一些常用栗子:
丢弃指定的数据库tangdoudou,如果存在
DROP DATABASE IF EXISTS tangdoudou;
创建一个新的数据库
CREATE DATABASE tangdoudou;
DROP DATABASE IF EXISTS tangdoudou;
进入数据库tangdoudou
USE tangdoudou;
创建保存学生数据的表(编号、姓名、性别、分数);
DROP TABLE IF EXISTS student;
CREATE TABLE student (
sid INT, # integer 整形
name VARCHAR(8), # variable character可变字符
sex VARCHAR(1),# m->男 f->女
score INT
);
往学生表中插入数据
INSERT INTO student VALUES('1','tom','m','85');
INSERT INTO student VALUES('2','kate','f','92');
INSERT INTO student VALUES('3','king','m','74');
修改编号为2的学员成绩为100,姓名为lucy;
UPDATE student SET name='lucy' WHERE sid='2';
UPDATE student SET score='100' WHERE sid='2';
删除编号为3的学员数据
DELETE FROM student WHERE sid='3';
查询学生表内容
SELECT * FROM student;
待继续补充
- 今天就写到这里啦~小伙伴们,( ̄ω ̄( ̄ω ̄〃 ( ̄ω ̄〃)ゝ我们明天再见啦~~
- 大家要天天开心哦
欢迎大家指出文章需要改正之处~
学无止境,合作共赢
