卷积神经网络
文章目录
- 1.什么是卷积神经网络
- 2.卷积神经网络详解
-
- 2.1.卷积层的作用
- 2.2.池化层的作用
- 2.3.平坦层处理
- 2.4.全连接层处理
- 3.卷积神经网络是如何训练的
主要介绍卷积神经网络(CNN)的相关知识。
1.什么是卷积神经网络
感受野(Receptive Field):每一个视觉神经元只会处理一小块区域的视觉图像。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定眼前的物体的形状是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。对于不同的物体,人类视觉也是通过这样逐层分级来进行认知的:最底层特征基本上是类似的,就是各种边缘;越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等);到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确地区分不同的物体。
卷积神经网络的卷积层完成的操作(抽取局部特征(Local Feature)),可以认为是受局部感受野概念的启发,而池化层(抽象和容错)主要是为了降低数据维度。
卷积神经网络是一种多层神经网络,擅长处理图像尤其是大图像的相关机器学习问题。
卷积神经网络通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
2.卷积神经网络详解
典型的卷积神经网络由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。

用卷积神经网络识别图片,一般需要如下的4个步骤:
- 步骤01 卷积层初步提取特征。
- 步骤02 池化层提取主要特征。
- 步骤03 全连接层将各部分特征汇总。
- 步骤04 产生分类器,进行预测识别。
2.1.卷积层的作用
卷积层的作用就是提取图片中每个小部分里具有的特征。
卷积就是一种提取图像特征的方式,特征提取依赖于卷积运算,其中运算过程中用到的矩阵被称为卷积核。
卷积核的大小一般小于输入图像的大小,因此卷积提取出的特征会更多地关注局部。
每个神经元没有必要对全局图像进行感知,只需要对局部图像进行感知,然后在更高层将局部的信息综合起来,就得到了全局的信息。
假定 我们有一个尺寸为6×6的图像,每一个像素点里都存储着图像的信息。我们再定义一个卷积核(相当于权重),用来从图像中提取一定的特征。卷积核与数字矩阵对应位相乘再相加,得到卷积层输出结果。
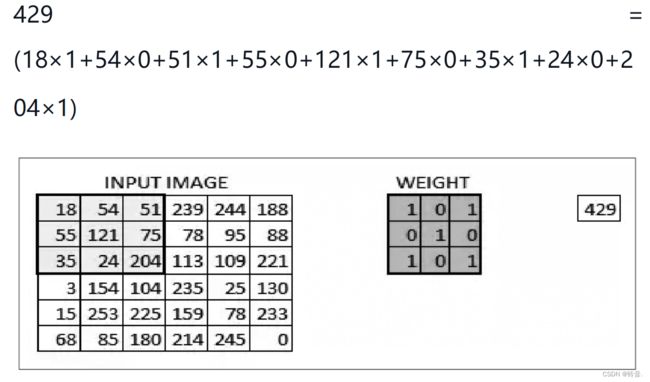
卷积核的取值在没有学习经验的情况下,可由函数随机生成,再逐步训练调整,当所有的像素点都至少被覆盖一次后,就可以产生一个卷积层的输出。

卷积层在训练时通过不断地改变所使用的卷积核,来从中选取出与图片特征最匹配的卷积核(卷积核对该特征有很高的输出值),进而在图片识别过程中,利用这些卷积核的输出来确定对应的图片特征。
卷积层:使用一个或多个卷积核对输入进行卷积操作。通过不断地改变卷积核,来确定能初步表征图片特征的、有用的卷积核是哪些,再得到与相应的卷积核相乘后的输出矩阵。
卷积操作会导致图像变小(损失图像边缘):常用的一种做法是人为地在卷积操作之前对图像边缘进行填充。可保证卷积后图像大小与原图一致。
2.2.池化层的作用
池化层的目的是减少输入图像的大小,去除次要特征,保留主要特征。它的目标是对输入(图片、隐藏层、输出矩阵等)进行下采样(Downsampling),来减小输入的维度,并且包含局部区域的特征。
常用的池化方法:最大池化(Max Pooling,输出的是选择区域内数值的最大值)、最小池化(Min Pooling)和平均池化(Average Pooling,平均池化输出的是选择区域内数值的平均值)。
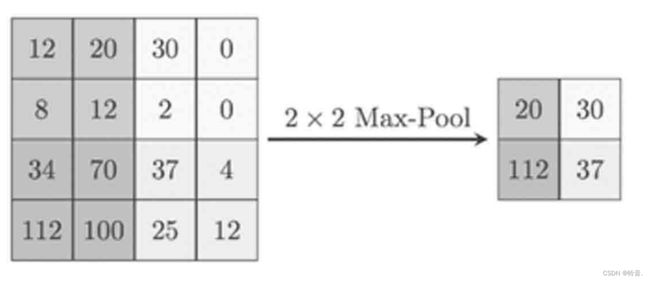
最大池化大小为2×2,步长为2。将4×4的区域池化成2×2的区域,这样使数据的敏感度大大降低,同时也在保留数据信息的基础上降低了数据的计算复杂度。
2.3.平坦层处理
平坦层(Flatten Layer)是用来将一个二阶张量(矩阵)或三阶张量展开成一个一阶张量(向量),即用来将输入“压平”,把多维的输入一维化,常用在从卷积层到全连接层的过渡。
2.4.全连接层处理
全连接层利用这些有用的图像特征进行分类,利用激活函数对汇总的局部特征进行一些非线性变换,得到输出结果。
简单地说,这一层处理输入内容后会输出一个n维向量,N是该程序必须选择的分类数量。
n维向量中的每一个数字都代表某一特定类别的概率。例如,某一数字分类程序的结果向量是[0, .1, .1, .75, 0, 0, 0, 0, 0, .05],则代表该图片有10%的概率是1,10%的概率是2,75%的概率是3,5%的概率是9。
完全连接层观察上一层的输出(其表示了更高级特征的激活映射)并确定这些特征与哪一分类最为吻合。例如,程序预测某一图像的内容为狗,那么激活映射中的高数值便会代表一些爪子或四条腿之类的高级特征。
3.卷积神经网络是如何训练的
因为卷积核实际上就是如3×3、5×5这样的权值矩阵,网络要学习的,或者说要确定下来的,就是这些权值的数值。
卷积神经网络的实质就是更新卷积核参数权值,即一直更新所提取到的图像特征,以得到可以把图像正确分类的最合适的特征。
训练过程:
- 步骤01 网络进行权值的初始化。
- 步骤02 输入数据经过卷积层、下采样层、全连接层的前向传播得到输出值。
- 步骤03 求出网络的输出值与目标值之间的误差。
- 步骤04 当误差大于我们的期望值时,将误差传回网络中,依次求得全连接层、下采样层、卷积层的误差。各层的误差可以理解为对于网络的总误差,网络应承担多少;当误差等于或小于我们的期望值时,结束训练。
- 步骤05 根据求得的误差,按极小化误差的方法调整权值矩阵,进行权值更新,然后再进入到第2步。