【升职加薪秘籍】我在服务监控方面的实践(3)-机器监控
大家好,我是蓝胖子,关于性能分析的视频和文章我也大大小小出了有一二十篇了,算是已经有了一个系列,之前的代码已经上传到github.com/HobbyBear/performance-analyze,接下来这段时间我将在之前内容的基础上,结合自己在公司生产上构建监控系统的经验,详细的展示如何对线上服务进行监控,内容涉及到的指标设计,软件配置,监控方案等等你都可以拿来直接复刻到你的项目里,这是一套非常适合中小企业的监控体系。
在前一节我们搭建好了监控组件,今天我们就来完成机器这一层次的监控。目前已经有现有的暴露系统指标的软件node-exporter ,并且我们在上一节已经搭建完毕, 在这一节里,我将会讲解如何利用暴露出来的这些指标构建一个自定义的系统监控模板。
本节构建的自定义的监控模板文件已经上传到github,可直接导入使用
github.com/HobbyBear/easymonitor/blob/main/grafanadashbord/system_dashboard.json
监控指标
如何选择node-exporter暴露的监控指标,我们可以按照四大黄金指标给出的维度进行筛选,并且promql语句也不用我们从头写,已经有现有的监控模板可使用。 我们只需要搭建好prometheus ,grafana后导入模板即可。我们用到的监控模板是node exporter full。
导入导出模板的步骤网上很多教程,我就不再重复造轮子了。
由于node exporter full模板里的监控面板实在太多,我们只需要选取其中的某些面板即可。
注意下,虽然使用的是别人已经写好的监控模板,但是我们仍然是以四大黄金指标为指导,选择监控的维度以及监控面板。四大黄金指标分别是延迟,流量,饱和度,错误数。
cpu
接着我们来挨个分析下需要用到的监控指标,首先我们来看下对cpu的监控。一般硬件指标是没有延迟这个维度,所以我们看流量,饱和度,错误数。**针对cpu而言,其实主要就是看饱和度和错误数,饱和度也就是cpu的使用率,如果cpu的使用率越高,说明cpu越趋于饱和。
cpu的使用率是通过读取proc文件系统获取的。一般会将cpu的使用率按用途进行分类,用top命令也可以看到cpu使用率的分类情况
%Cpu(s): 2.4 us, 1.0 sy, 0.0 ni, 96.2 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
我们挨个看下各种分类的含义:
1, us 代表用户态进程消耗的cpu。
2,sy 代表 内核态程序消耗的cpu。
3,ni 代表低优先级的进程消耗的cpu,当我们使用renice命令调低某个用户进程的优先级时,该用户进程cpu占用率会从us里分到ni里。这样当一批非常吃CPU的进程被调整nice值后,调整的人就能非常清楚的知道,这些进程现在占用多少CPU了。
4,id 代表代表空闲cpu的占用率。
5,wa 代表进程等待cpu执行所花的时间占cpu周期的时长。
6, hi 代表处理硬件中断的cpu占用率。
7,si 代表软中断的cpu使用率,在linux上,会运行一个特定的进程ksoftirqd 处理软中断的逻辑,软中断你可以把它理解成也是一段程序,不过这段程序运行特点的某些软中断的任务,linux内核为了方便观察这些任务的耗时,专门在cpu使用率里分出一个类别来记录这些软中断的任务运行的cpu占用率。 软中断的任务有多种类型,比如定时器,网络数据包的处理等。
8,st 代表从其他操作系统那里偷取到的cpu,一般在虚拟化环境比如物理主机上部署多台虚拟机或者云主机的条件下,一台虚拟机能够从另一台虚拟机那里抢占cpu,st就代表抢占cpu的时长。
在node exporter full里我们选用了一个cpu的面板,把上述cpu的使用率及其分类后的使用率表现了出来。
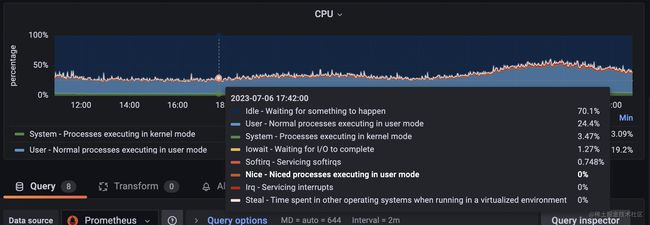
其中用到的prometheus的查询语句promql有8个,分别对应8种cpu使用率的分类,其中irq就是我们说的硬件中断cpu占用率,其余分类都是我们刚刚介绍的分类的完整名称。
拿其中一个计算cpu内核态程序cpu使用率的promql举例:
sum by(instance) (irate(node_cpu_seconds_total{instance="$node",job="$job", mode="system"}[$__rate_interval])) / on(instance) group_left sum by (instance)((irate(node_cpu_seconds_total{instance="$node",job="$job"}[$__rate_interval])))
node_cpu_seconds_total 指标是我们部署的node-exporter 服务暴露给prometheus服务器的指标,指标类型是counter类型。__rate_interval 是grafana的内置变量,grafana会根据样本的抓取间隔和面板筛选的时间范围自动算出一个合适的值作为rate函数的参数,以便我们得到合适的曲线。
整个promql语句代表的含义就是看 内核态程序在过去__rate_interval 时间内的cpu使用周期占cpu过去__rate_interval 时间内 总的周期时长 的百分比作为内核态程序cpu的占用率。
其余分类的cpu使用率和这个例子的promql语句类似,就不一一分析了。
内存
再来看看内存的指标是怎么样的, 对于内存而言,没有流量以及延迟 饱和度是内存使用空间大小,错误数我们主要看缺页错误以及oom kill的次数 。
内存占用空间大小
看内存使用空间,我们拿top命令输出的内容举例
KiB Mem : 24521316 total, 327428 free, 18130784 used, 6063104 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 4672160 avail Mem
第一行分别代表了total 总内存字节,free 空闲内存字节数,used已经使用的内存字节数,buff/cache 缓存的内存字节数,buff/cache 一般是指读写磁盘或者读写文件时,内核为了平衡写入内存与写入磁盘的速率差引入的缓冲区。
第二行代表的是交换空间的信息,交换空间是指内核为了防止进程突增的内存超过系统内存引入的一片磁盘空间,它能够在内存不足时 将内存中的信息交换到磁盘,在内存空闲时,将磁盘中的信息换回到内存里。
total代表交换空间总的大小,free是交换空间可用的字节大小,used代表使用了的交换空间字节数,avail Mem代表可以交换到磁盘上的物理内存大小,当物理内存不足时,会将这部分内存交换到磁盘上。
内存的监控面板同样我们也是从node exporter full 里找一个就行。
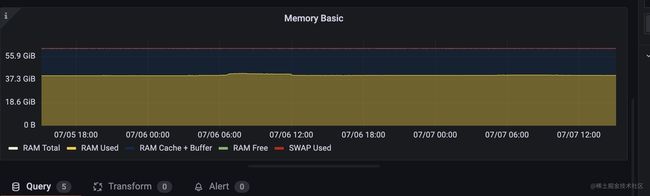
由于内存是可增可减的,所以是个guage类型的指标,相应的指标信息也是从proc文件系统获取到的,其路径是 /proc/meminfo ,对应的promql语句不用使用什么函数只需要将对应的指标值加减即可,比较容易理解,我就不具体分析,下面是其中一个时间线的查询语句:
node_memory_Cached_bytes{instance="$node",job="$job"} + node_memory_Buffers_bytes{instance="$node",job="$job"} + node_memory_SReclaimable_bytes{instance="$node",job="$job"}
page fault 和oom kill次数
其中page fault分major fault和minor fault 。
major fault是指在分配内存时,内存地址即不在虚拟地址空间也不在物理内存中的情况,这种情况需要将数据从磁盘读到物理内存里并建立映射关系。
minor fault 是指分配内存时,内存地址不在虚拟地址空间,但是已经在物理内存中了,这种情况只需要将虚拟地址和物理地址建立映射就行,比如多个进程共享内存的情况,可能某些进程还没有建立起映射关系,所以访问时会出现minor page fault。
监控面板如下:
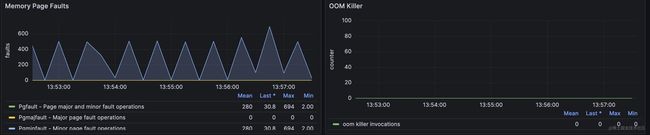
oom killer 显示的就是进程由于内存溢出被系统内核kill掉的次数。
这两个指标都是递增的,索引是counter类型,我们可以使用irate或者rate函数就能构建其随时间变化的速率了,具体promql语句我就不再解释了。
磁盘
紧接着,我们来看看对磁盘的监控,磁盘可以通过磁盘的iops,吞吐量显示流量,通过磁盘的空间反映饱和度,通过等待读写磁盘请求的时间来侧面反应延迟情况。
涉及到几个指标具体含义如下:
1,磁盘的使用空间 : 这个很容易理解,当磁盘要满了,就必然存不进新的数据了。
2, iops : 这个指标是指磁盘每秒读写请求的次数,一般我们在云服务商那里都能看到对应磁盘的这个值,当达到峰值时,会影响磁盘的读写性能。
3, 吞吐量: 这个值代表磁盘每秒写入写出的流量,也就是每秒读写了多少字节数,这个值也是不同磁盘有不同的极限值,当磁盘吞吐量达到最大值后,也会影响到磁盘的性能。
4, 等待时间: 磁盘的读写请求本质上也是排队进行的,它们在队列中会有一个等待时间。
同样的,我们从node exporter full这个模板里选择4个面板来监控它们,
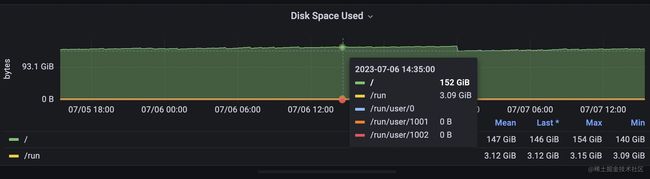
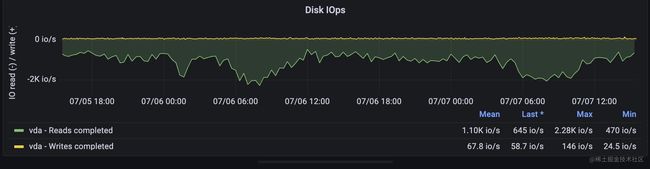
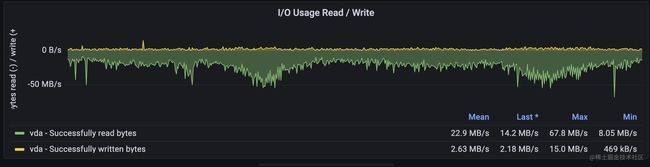
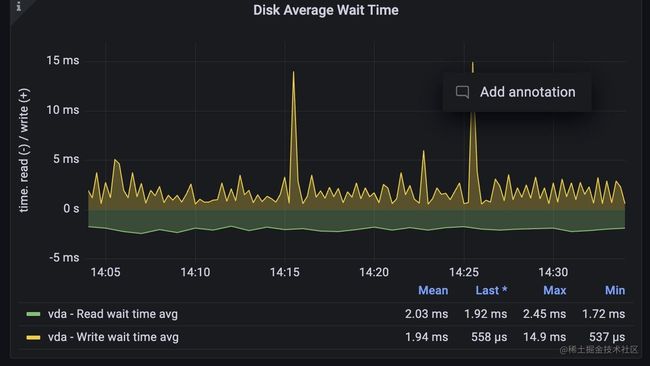
磁盘空间是一个guage类型的指标,而iops和吞吐量,等待时长都是一个counter类型用irate函数取的速率,promql语句比较简单,这里就不再继续展开了。
网络
接着,我们看下在网络方面应该对哪些指标进行监控,网络数据包的发送涉及到网卡的能力,网卡能力也是有极限的,网络的延迟一般体现在接口上,我们不用在系统层面展示,流量可以用pps来表示,饱和度可以用带宽来表示,错误数可以通过网卡以及tcp层面暴露的错误信息来表示 ,涉及到的指标含义如下:
1,带宽 :这个和磁盘吞吐量比较类似,是单位时间内传输的字节数,不过单位一般是bit/s 和字节的换算 8 * bit/s = 1 B/s
2, pps : 每秒的收发包数量。
这两个值也是在你购买不同规格的网络时有不同的极限值,我们需要注意监控指标是否和极限值比较接近的情况,达到极限值后会影响网络的性能。
这两个指标同样能够从监控模板里找到对应的面板,
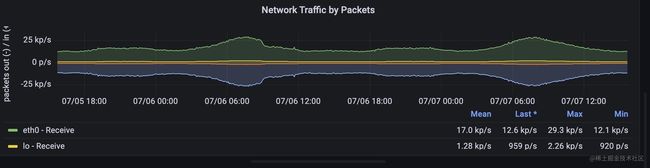
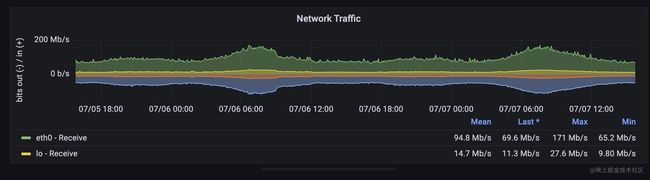
两个指标都是counter类型,promql表达式用rate或者irate取值既可以看到pps或者流量速率了。
网卡层面和tcp层面暴露的错误信息
网卡层面暴露的错误原理和ifconfig 看到网卡的错误次数一致, RX errors 和 TX errors分别代表读写发生错误的次数。
// ifconfig 输出结果
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.94 netmask 255.255.255.0 broadcast 192.168.0.255
ether fa:16:3e:ed:d6:94 txqueuelen 1000 (Ethernet)
RX packets 218761044009 bytes 151837637636460 (138.0 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 198948059963 bytes 110561548482730 (100.5 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tcp 层面错误统计原理是从/proc/net/netstat读取到相关信息。
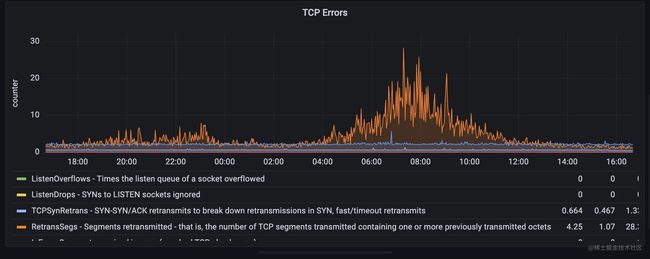
我们可以从监控面板中直接看出tcp出现错误最多的地方,在我这个面板里,目前是高峰期出现重传的情况比较多。
对连接的监控
但是仅仅用上面的监控只是从宏观上看到网络的拥塞情况。我们有时可能更需要考虑在tcp层的饱和情况。
所以我们在此基础上又加了连接数的监控。
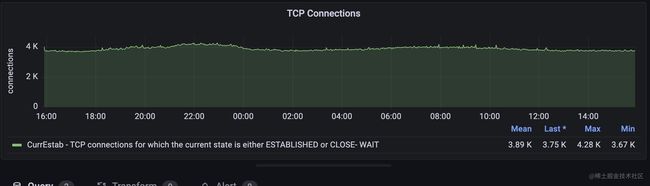
这个面板能够展示tcp当前链接数,当前链接是处于 ESTABLISHED 和 CLOSE-WAIT 状态的 TCP 连接数。
下面这个面板是展示了主动建立连接和被动建立连接的情况
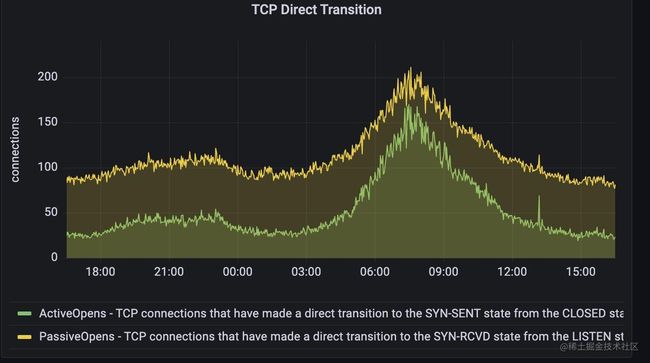
上述指标和用netstat -s 看tcp的信息是一致的,node exporter服务也是采用用netstat工具类似的原理,从proc文件系统的/proc/net/netstat 目录读取到相关信息。
对进程状态的监控
除了上述监控指标外,我们还加上了对整个系统内部进程状态的监控,这是鉴于之前某些服务会产生异常子进程的情况才考虑添加的。主要对系统内各个时刻的进程状态进行监控计数。

系统资源限制监控
除了上述监控外,系统内部还有一些资源不是无限的,也需要记录下系统当前使用这些资源的情况,比如已经使用的文件描述符,pid号,连接表nf_conntrack的大小(这个表满了会产生丢包),线程数等等,我都统一归纳为资源限制监控了。具体面板就不在这里粘贴了。这些资源限制资源以后是我们创建报警时重点关注的指标。
总结
在这一节,我们通过node exporter 建立起了对机器层级的监控,涉及cpu,内存,磁盘,网络,其中涉及的监控面板来自于现有的监控模板node exporter full,不过由于node exporter full 数量实在太多,我们挑选了一些组成了最终的监控模版,模版的json文件已经放到了文章开头, 你完全可以将它直接导入到你的grafana项目里,建立起对机器层级的监控。
在万千人海中,相遇就是缘分,为了这份缘分,给作者点个赞不过分吧。