Zookeeper特性与节点数据类型详解
CAP&Base理论
CAP理论
cap理论是指对于一个分布式计算系统来说,不可能满足以下三点:
一致性 : 在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的
特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统
在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
可用性: 每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
分区容错性: 分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对
外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
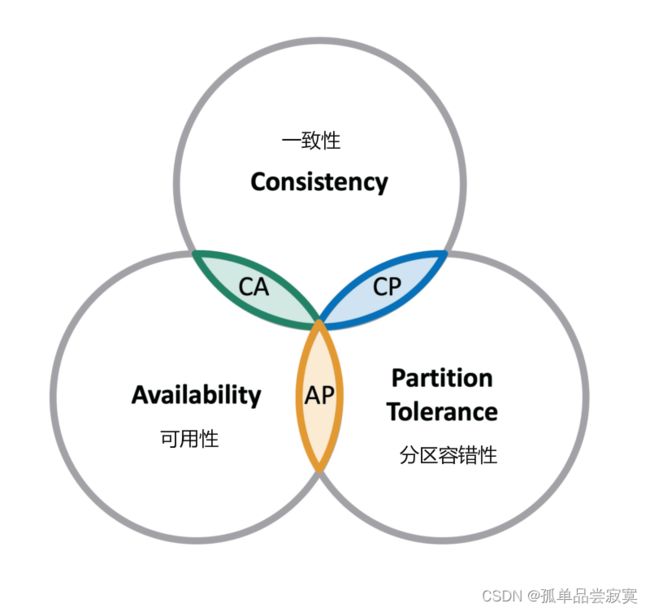
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区 容错性(Partition tolerance)这三项中的两项。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择, zookeeper 保证的是 CP ,对比 spring cloud 系统中的注册中心 eureka实现的是 AP
思考:zookeeper是强一致性吗?
答 : Zookeeper写入是强一致性,读取是顺序一致性。
BASE 理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最 终一致性) 三个短语的缩写。
基本可用: 在分布式系统出现故障,允许损失部分可用性(服务降级、页面降 级)。
软状态: 允许分布式系统出现中间状态。 而且中间状态不影响系统的可用性。这 里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出 现延时的最终一致性。
最终一致性: data replications 经过一段时间达到一致性。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是: 我 们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到 最终一致性。
强一致性:又称线性一致性(linearizability )
1.任意时刻,所有节点中的数据是一样的,
2.一个集群需要对外部提供强一致性,所以只要集群内部某一台服务器的数据发生了改变,那么就
需要等待集群内其他服务器的数据同步完成后,才能正常的对外提供服务
3.保证了强一致性,务必会损耗可用性
弱一致性:
1.系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值。
2.即使过了不一致时间窗口,后续的读取也不一定能保证一致。
最终一致性:
1.弱一致性的特殊形式,不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁 移,不同节点上的同一份数据总是在向趋同的方向变化
2.存储系统保证在没有新的更新的条件下,最终所有的访问都是最后更新的值
顺序一致性:
1.任何一次读都能读到某个数据的最近一次写的数据。
2.对其他节点之前的修改是可见(已同步)且确定的,并且新的写入建立在已经达成同步的基础上
Zookeeper介绍
ZooKeeper是一个分布式的, 开放源码的 分布式应用程序协调服务,是 Google的Chubby一个开源的实现,是 Hadoop和 Hbase的重要组件。
ZooKeeper本质上是一个分布式的小文件存储系统(Zookeeper=文件系统+监听机 制)。 提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效 管理,从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,从而可 以达到基于数据的集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式 锁、分布式协调等功能。
Zookeeper从设计模式角度来理解: 是一个基于观察者模式设计的分布式服务管理框 架 ,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发 生变化,Zookeeper 就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反 应。
Zookeeper实战
Zookeeper安装
下载地址: https://zookeeper.apache.org/releases.html
运行环境:jdk8
1)修改配置文件
解压安装包后进入conf目录,复制zoo_sample.cfg,修改为zoo.cfg
修改 zoo.cfg 配置文件,将 dataDir=/tmp/zookeeper 修改为指定的data目录
zoo.cfg中参数含义:

2)启动zookeeper server
# 可以通过 bin/zkServer.sh 来查看都支持哪些参数
# 默认加载配置路径conf/zoo.cfg
bin/zkServer.sh start conf/zoo.cfg
# windows 直接双击zkServer.cmd
# 查看zookeeper状态
bin/zkServer.sh status
3)启动zookeeper client连接Zookeeper server
bin/zkCli.sh
# 连接远程的zookeeper server
bin/zkCli.sh ‐server ip:port 客户端命令行操作
输入命令 help 查看zookeeper支持的所有命令:
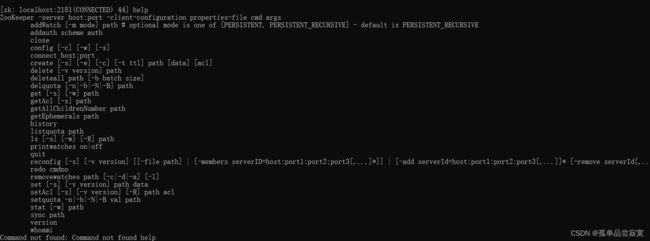
常见cli命令
ZooKeeper: Because Coordinating Distributed Systems is a Zoo
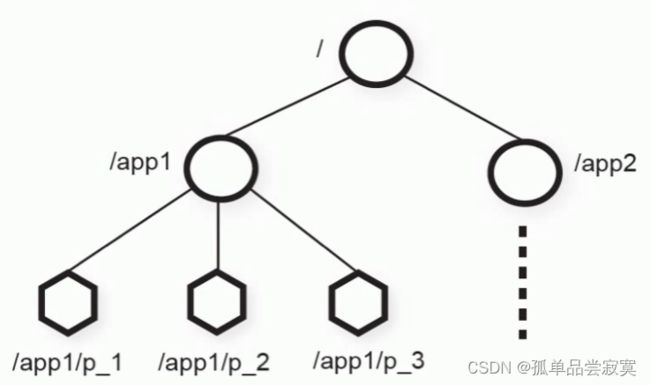
ZooKeeper数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节
点称做一个 ZNode
ZooKeeper的数据模型是层次模型 ,层次模型常见于文件系统。 层次模型和key-value模型 是两种主流的数据模型。 ZooKeeper使用文件系统模型主要基于以下两点考虑:
1. 文件系统的树形结构便于表达数据之间的层次关系
2. 文件系统的树形结构便于为不同的应用分配独立的命名空间( namespace )
ZooKeeper的层次模型称作Data Tree,Data Tree的每个节点叫作Znode。 不同于文件系 统, 每个节点都可以保存数据 ,每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识,每个节点都有一个版本(version),版本从0开始计数。
节点分类
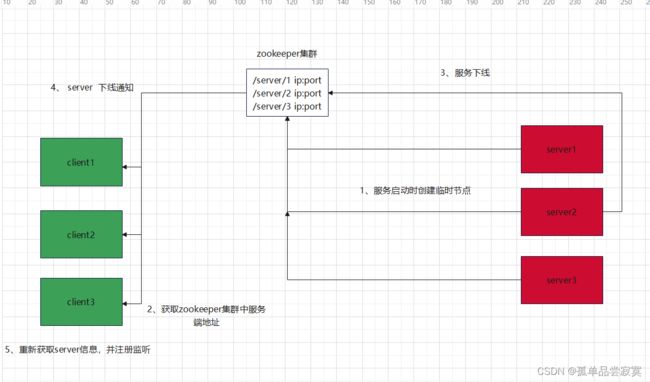
一个znode可以使持久性的,也可以是临时性的:
1. 持久节点(PERSISTENT): 这样的znode在创建之后即使发生ZooKeeper集群宕机或 者client宕机也不会丢失。
2. 临时节点(EPHEMERAL ): client宕机或者client在指定的timeout时间内没有给 ZooKeeper集群发消息,这样的znode就会消失。
如果上面两种znode具备顺序性,又有以下两种znode :
3. 持久顺序节点(PERSISTENT_SEQUENTIAL): znode除了具备持久性znode的特点之 外,znode的名字具备顺序性。
4. 临时顺序节点(EPHEMERAL_SEQUENTIAL): znode除了具备临时性znode的特点之 外,zorde的名字具备顺序性。
zookeeper主要用到的是以上4种节点。
5. Container节点 (3.5.3版本新增):Container容器节点,当容器中没有任何子节点, 该容器节点会被zk定期删除(定时任务默认60s 检查一次)。 和持久节点的区别是 ZK 服务 端启动后,会有一个单独的线程去扫描,所有的容器节点,当发现容器节点的子节点数量为 0 时,会自动删除该节点。可以用于 leader 或者锁的场景中
6. TTL节点: 带过期时间节点,默认禁用, 需要在zoo.cfg中添加 extendedTypesEnabled=true 开启。 注意:ttl不能用于临时节点
#创建持久节点
create /servers xxx
#创建临时节点
create ‐e /servers/host xxx
#创建临时有序节点
create ‐e ‐s /servers/host xxx
#创建容器节点
create ‐c /container xxx
# 创建ttl节点
create ‐t 10 /ttl 节点状态信息
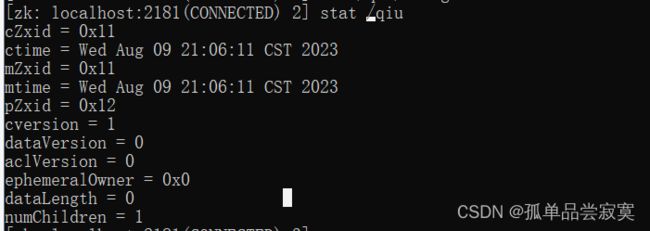
cZxid :Znode创建的事务id。
ctime:节点创建时的时间戳。
mZxid :Znode被修改的事务id,即每次对znode的修改都会更新mZxid。
对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction
Id),通过zxid,可以确定更新操作的先后顺序。 例如,如果zxid1小于zxid2,说明zxid1 操作先于zxid2发生,zxid对于整个zk都是唯一的,即使操作的是不同的znode。 pZxid: 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节 点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID( 注意: 只有子节 点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid )
mtime:节点最新一次更新发生时的时间戳.
cversion :子节点的版本号。当znode的子节点有变化时,cversion 的值就会 增加1。
dataVersion:数据版本号,每次对节点进行set操作,dataVersion的值都会增 加1(即使设置的是相同的数据), 可有效避免了数据更新时出现的先后顺序问题。 ephemeralOwner:如果该节点为临时节点, ephemeralOwner值表示与该节点 绑定的session id。如果不是, ephemeralOwner值为0(持久节点)。 在client和server通信之前,首先需要建立连接,该连接称为session。连接建立后,如果发生连 接超时、授权失败,或者显式关闭连接,连接便处于closed状态, 此时session结束。
dataLength : 数据的长度 numChildren :子节点的数量(只统计直接子节点的数量)
监听通知(watcher)机制
一个Watch事件是一个一次性的触发器 ,当被设置了Watch的数据发生了改变的 时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
Zookeeper采用了 Watcher机制实现数据的发布订阅功能 ,多个订阅者可同时 监听某一特定主题对象,当该主题对象的自身状态发生变化时例如节点内容改变、节 点下的子节点列表改变等,会实时、主动通知所有订阅者。 watcher机制事件上与观察者模式类似,也可看作是一种观察者模式在分布式场 景下的实现方式。
watcher的过程:
1. 客户端向服务端注册watcher
2. 服务端事件发生触发watcher
3. 客户端回调watcher得到触发事件情况
注意:Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触 发监听,通知给客户端。
支持的事件类型:
None: 连接建立事件
NodeCreated : 节点创建
NodeDeleted : 节点删除
NodeDataChanged :节点数据变化
NodeChildrenChanged :子节点列表变化
DataWatchRemoved :节点监听被移除
ChildWatchRemoved :子节点监听被移除

注 : addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE
命令可以创建永久监听
# 监听节点数据的变化
get ‐ w path
stat ‐ w path
# 监听子节点增减的变化
ls ‐ w path
创建监听:

使用 stat 创建的是一次性监听,set 的第一条数据才会返回监听信息,第二条不会

监听到有对 /qiu/xang节点进行过操作
Zookeeper 节点特性总结
1. 同一级节点 key 名称是唯一的

已存在/lock节点,再次创建会提示已经存在
2.创建节点时,必须要带上全路径
3.session 关闭,临时节点清除
4.自动创建顺序节点
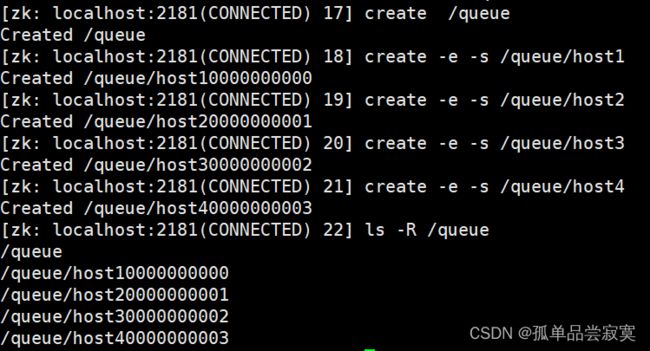
5.watch 机制,监听节点变化
事件监听机制类似于观察者模式,watch 流程是客户端向服务端某个节点路径上注册一watcher,同时客户端也会存储特定的 watcher,当节点数据或子节点发生变化时,服务端 通知客户端,客户端进行回调处理。 特别注意:监听事件被单次触发后,事件就失效了。
6.delete 命令只能一层一层删除。 提示:新版本可以通过 deleteall 命令递归删除。
应用场景
ZooKeeper适用于存储和协同相关的关键数据,不适合用于大数据量存储。
有了上述众多节点特性,使得 zookeeper 能开发不出不同的经典应用场景,比如:
注册中心
数据发布/订阅(常用于实现配置中心)
负载均衡
命名服务
分布式协调/通知
集群管理
Master选举
分布式锁
分布式队列
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
例如:IP不容易记住,而域名容易记住。
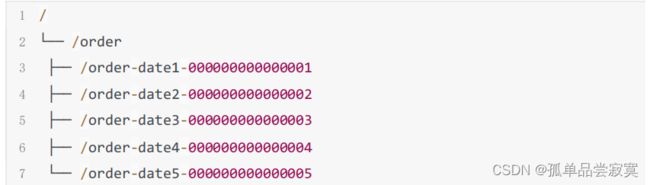
利用 ZooKeeper 顺序节点的特性,制作分布式的序列号生成器,或者叫 id 生成器。(分 布式环境下使用作为数据库 id,另外一种是 UUID(缺点:没有规律)),ZooKeeper 可 以生成有顺序的容易理解的同时支持分布式环境的编号
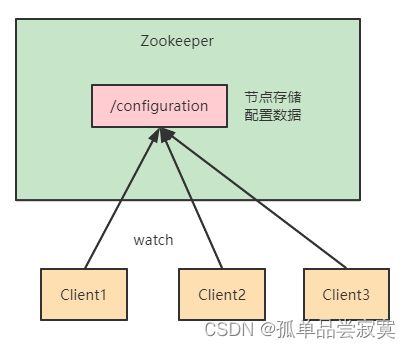
数据发布/订阅
数据发布/订阅的一个常见的场景是配置中心,发布者把数据发布到 ZooKeeper 的一个或 一系列的节点上,供订阅者进行数据订阅,达到动态获取数据的目的。
配置信息一般有几个特点:
1. 数据量小的KV
2. 数据内容在运行时会发生动态变化
3. 集群机器共享,配置一致
ZooKeeper 采用的是推拉结合的方式。
1. 推: 服务端会推给注册了监控节点的客户端 Watcher 事件通知
2. 拉: 客户端获得通知后,然后主动到服务端拉取最新的数据
统一集群管理
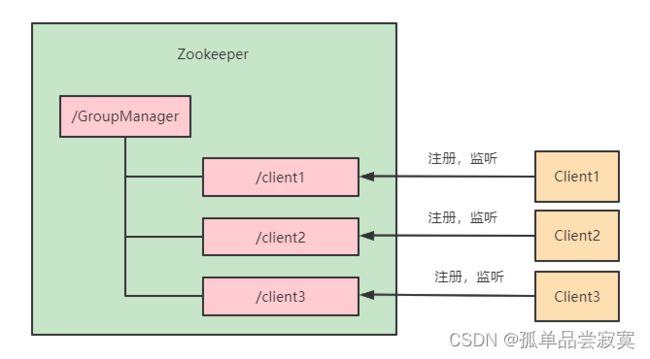
分布式环境中,实时掌握每个节点的状态是必要的,可根据节点实时状态做出一些调整。
ZooKeeper可以实现实时监控节点状态变化: 可将节点信息写入ZooKeeper上的一个ZNode。
监听这个ZNode可获取它的实时状态变化。
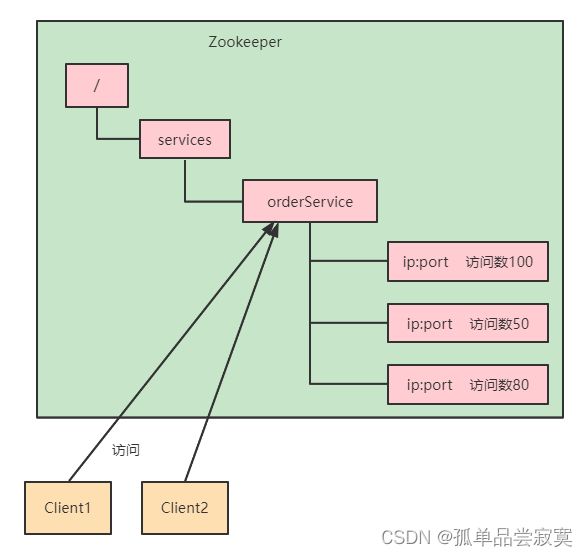
负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请 求