关于MySQL中的binlog
介绍
undo log 和 redo log是由Inno DB存储引擎生成的。
在MySQL服务器架构中,分为三层:连接层、服务层(server层)、执行层(存储引擎层)
bin log 是 binary log的缩写,即二进制日志。
MySQL在完成一次DML操作后,Server层还会生成一条binlog,等事务提交之后, 还会将该事务执行过程中产生的所有binlog统一写入到binlog日志文件中
binlog日志文件中保存了所有数据库的所有表结构的变化和表数据的变化
bin log的作用
bin log主要用于下面两个方面:
- 主从复制
对于”双11“这种级别的千万级高并发,单台数据库服务器是扛不住的!
为了提供并发处理的能力,一般会部署多态MySQL服务器,这些服务器中维护着相同的数据副本。这些MySQL服务器组成一个MySQL集群
一个非常典型的部署方案就是一主多从, 在这些MySQL服务器中,有一个主服务器Master和多台从服务器Slave
主服务器只负责数据变更,而从服务器负责查询,在大部分情况下,查询是最耗时的,因为多台从服务器负责查询操作,分担了并发压力。
对于DDL、DML请求,将就给主服务器去执行
对于查询Select请求,就交给从服务器,因为每个服务器中都维护着相同的数据副本,所以交给任意一个从服务器即可
为了让各个从服务器中存储的数据 和主服务器中的数据保持一致,每当我们改变了主服务器中的表结构或者表数据,就需要将这些变更信息同步给各个从服务器,此时bin log就发挥作用了
bin log中保存了所有数据库的所有表的变化信息,从服务器只需要读取主服务器的bin log,就能完成主从服务器之间的数据同步
- 系统备份恢复
如果不小心把整个数据库的数据都删除了,能使用redo log日志恢复数据吗?
当然不能,因为redo log是Inno DB产生的日志文件,Inno DB是表级别的(在创建表时指定表的存储引擎),当直接删除了整个数据库,那么这些redo log日志也不会存在了,即使这些redo log存在,也并不能将这个表的所有数据都恢复,因为redo log日志文件存在复用的情况,对于哪些已经刷新到磁盘的redo log,redo log已经没有存在的必要性了所以会覆盖掉,新写的redo log会覆盖掉之前的旧的redo log,因此redo log只能保证恢复在事务提交之前的部分数据
因为 redo log 文件是循环写,是会边写边擦除日志的,只记录未被刷入磁盘的数据的物理日志,已经刷入磁盘的数据都会从 redo log 文件里擦除。
此时又轮到binlog发挥作用了
因为bin log记录了所有库的所有表的变更信息,所以可以借助binlog来完成数据恢复
配置使用binlog
查看MySQL服务器是否开启了bin log
show variables like 'log_bin';
- 查询到的值是
ON,代表当前服务器已开启binlog日志功能 - 如果为
OFF,代表当前服务器没有开启bin log功能
如果当前服务器没有开启bin log,需要手动开启。
关闭服务器,重新启动服务器时添加此启动配置项
--log-bin [=base_name]base_name是用来记录bin log日志文件的基名称
bin log日志文件会保存在MySQL的数据目录下,bin log日志文件不是一个文件,而是一组文件,这一组文件的命名规则是这样的
basename.000001
basename.000002
basename.000003
basename.000004
....
以basename作为基名称,后面的序号递增。
如果需要修改bin log文件的基名称,可以利用启动项参数修改
--log-bin [=basename]
如果没有指定基名称,那么MySQL服务器会默认以主机名-bin作为binlog日志文件的基名称。
MySQL 8.x 会默认以binlog作为基名称
binlog.000001
binlog.000002
....
查看binlog中的内容
binlog日志文件并不能直接查看,因为是二进制文件。
binlog中记录数据库发生变更的各种事件,事件类型非常多,其实并不需要刻意关注binlog中的内容。
如果真的想要查看binlog的内容,则可以借助MySQL提供的mysqlbinlog工具
mysqlbinlog工具作为可执行文件,存放在MySQL安装目录的bin目录下
将需要查看的binlog日志文件作为mysqlbinlog命令的参数
mysqlbinlog ./data/binlog.0000001
binlog日志文件格式
随着MySQL版本的更新,binlog文件格式也有不同的版本,在此以v4最新版本的文件格式来讲解。
一个binlog日志文件的基本格式主要由两部分组成:
- 文件固定头部
- 事件
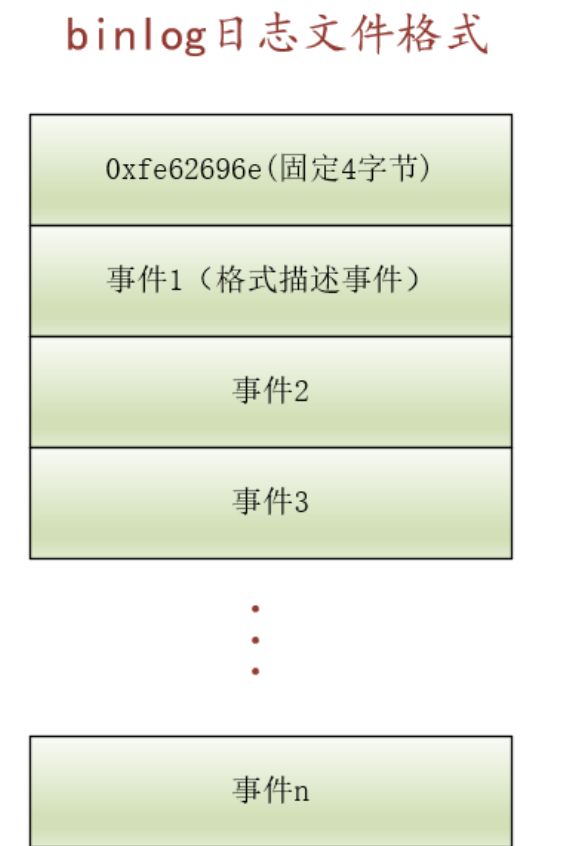
- 每个binlog日志文件的前4个字节都是固定的,用来作为此文件的一个标识,不用关心。
- 每个binlog日志文件都有若干个事件组成,这些事件就是对数据库表的变更事件。
每个事件又可以分为两部分:
- 事件头 event header,用来对这个事件进行描述的信息
- 真实数据 data
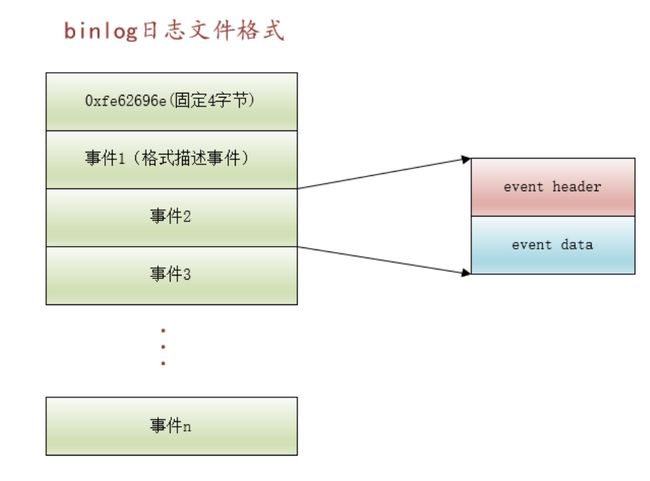
好了,这就是binlog日志文件的基本格式,知道这么多就行了。
两种binlog
binlog日志文件中存储的事件就是对数据库变更的信息,那么如何描述这个事件又有两种方式。
一条sql语句,如果binlog-format不同,那么可能生成不同类型的binlog事件,大致就可以分为基于语句Statement和基于行row两种类型的binlog
-
当以启动选项
--binlog-format=STATEMENT启动MySQL服务器时,生成的binlog称作基于语句的日志。此时只会将一条SQL语句将会被完整的记录到binlog中,而不管该语句影响了多少记录。 -
当以启动选项
--binlog-format=ROW启动MySQL服务器时,生成的binlog称作基于行的日志。此时会将该语句所改动的记录的全部信息都记录上。 -
当以启动选项
--binlog-format=MIXED启动MySQL服务器时,生成的binlog称作基于行的日志。此时在通常情况下采用 基于语句的日志 ,在某些特殊情况下会自动转为基于行的日志
简单总结:
- 基于语句的binlog 只将更新语句是什么记录下来了。
- 基于行的binlog 将更新语句执行过程中每一条记录更新前后的值都记录下来了
基于语句的binlog可能会导致主从数据不一致的情况,例如下面这条语句
INSERT INTO t(c) SELECT c FROM other_table;
这条语句是从其他表中查询数据并插入到一张表中。
但是对于这条子查询SELECT c FROM other_table;,可能由于不同服务器版本、不同的系统变量导致同一条语句的结果顺序不同,那么在插入时,自动生成主键,不同的顺序最终生成的记录的主键值不同。
原因是在基于语句的binlog中,只会记录这条sql语句,从库去执行这条sql语句,并不会关心更新前后的记录值。
但是在基于行的binlog中,还保存了这条记录更新前后的值,从库在执行完sql语句后,还会将这条记录调整到一致的状态,从而保证主从数据一致性。
redo、undo、buffer pool、binlog的执行顺序
当执行一条UPDATE语句时,redo、undo、binlog的写入顺序是怎样的?
具体的一条记录的更新流程如下:
-
现在B+树中定位到该记录(锁定读),如果该数据所在的页面不再Buffer pool中,则先将这一页数据从磁盘加载到buffer pool中
-
读取到记录后,判断记录更新前后是否一样,一样的话就跳过,不用更新了
-
首先更新聚簇索引记录
更新聚簇索引记录时:
- 首先向undo页面写入undo日志,因为这是在修改页面,所以修改undo页面前需要先记录这次的redo日志
- 真正的更新记录,在更新前记录响应的redo日志
-
更新其他的二级索引
至此,一条记录更新完成
redo 和 bin log的区别
- 适用对象不同
- binlog是MySQL的Server层实现的日志,是整个MySQL服务器级别的
- redo log是InnoDB存储引擎实现的日志,是表级别的
-
文件格式不同
-
写入方式不同
- binlog是追加写,写满一个文件,就会新创建一个文件,不会覆盖以前的文件
- redo log是循环写,日志空间的大小是固定的,写满了就会从头开始写,覆盖掉之前的redo Log内容
- 用途不同
- binlog 主要用于主从复制、备份恢复
- redo log主要用于发生故障时,表脏数据的恢复
主从复制
前面已经介绍过主从复制,MySQL的主从复制依赖于bin log
复制过程就是将binlog中的数据从主库传输到从库
这个过程是异步的,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rLPw0Yy5-1691478160467)(https://cdn.xiaolincoding.com/gh/xiaolincoder/mysql/how_update/%E4%B8%BB%E4%BB%8E%E5%A4%8D%E5%88%B6%E8%BF%87%E7%A8%8B.drawio.png?image_process=watermark,text_5YWs5LyX5Y-377ya5bCP5p6XY29kaW5n,type_ZnpsdHpoaw,x_10,y_10,g_se,size_20,color_0000CD,t_70,fill_0)]
MySQL主从复制的三个步骤:
- Master 写入binlog:主服务器写binlog日志,提交事务
- Slave 同步 binlog:把binlog复制到所有从库上,每个从库把binlog保存到暂存日志中
- 回访binlog:从服务器执行完数据的更新后,记录到自己的bin log日志文件中
具体的过程:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
- 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
- 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
从服务器的数量是不是越多越好?这样分担下来的流量不就更小,每个数据库的压力更小吗?
不是的
从服务器数量增加,对于主服务器来说,IO连接的数量越多,对于每一个从服务器的连接,主服务器都需要创建一个log dump线程来专门负责与这个从服务器的请求。从服务器的数量越多,对主服务器的资源消耗越多,同时还要受限于主库的网络带宽。
在实际使用中,一般遵循一主一副多从的设计,也就是一个主服务器,一个备用的主服务器(在主服务器崩溃后担任主服务器),2-3个从服务器
巨人的肩膀
- 小林Coding——MySQL日志
- 《MySQL是怎么运行的》