【目标检测系列】YOLOV1解读
前言
从R-CNN到Fast-RCNN,之前的目标检测工作都是分成两阶段,先提供位置信息在进行目标分类,精度很高但无法满足实时检测的要求。
而YoLo将目标检测看作回归问题,输入为一张图片,输出为S*S*(5*B+C)的三维向量。该向量结果既包含位置信息,又包含类别信息。可通过损失函数,将目标检测与分类同时进行,能够满足实时性要求。
接下来给出YOLOV1的网络结构图

核心思想
YOLO将目标检测问题作为回归问题。会将输入图像分为S*S的网格,如果一个物体的中心点落到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,同时会生成B个预测框。
对于每个cell:
-
含有B个预测边界框,这些框大小尺寸等等都随便,只有一个要求,就是生成框的中心点必须在cell中,每个框都有一个置信度分数(confidence score)。这些框的置信度分数反映了该模型对某个框内是否含有目标的置信度,以及它对自己的预测的准确度的估量。
-
每个cell还预测了C类的条件概率,即每个单元格只存在一组类别概率,而不考虑框B的数量。
-
每个预测边界框包含5个元素:(x,y,w,h, c) 其中 x,y,w,h表示该框中心位置, c为该框的置信度
-
不管框B的数量多少,该cell只负责预测一个目标
综上,S*S个网格,每个网格要预测B个bounding box,还要预测C个类。网络输出为S*S*(5*B+C)。 (S*S个网络,每个网络都有B个预测框,每个框又有五个参数,在加上每个网格都有C个类别)

最终的预测特征由边界框位置、边框的置信度得分以及类别概率,即S*S*(5*B+C), 这里是 7*7*(2*5+20)
训练过程
对于一个网络模型,损失函数的目的是要缩小预测值和标签之间的差距。对于YOLOV1网络来说,每个cell含有5*B+C个预测值,我们在训练过程中该如何获得与之对应的label.
这5*B+C个预测值的含义在上面已经给出(S*S个网络,每个网络都有B个预测框,每个框又有五个参数,在加上每个网格都有C个类别),因此我们实际需要给出的label为每个预测框的四个坐标及其置信度,和每个cell对应的类别。
-
每个预测框的四个坐标(x, y, w, h)的label为该预测框所在cell中目标物体的坐标
-
每个预测框的置信度c,反映了该模型对某个框内是否含有目标的置信度,以及它对自己的预测的准确度的估量,是让网络学会自我评价候选框的功能。因此它所对应的label计算相对复杂。我们将置信度定义为
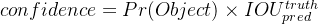 。 Pr(Object)=[0, 1], 如果该单元格内不存在目标(即Pr(Object)=0),则置信度分数为0。 如果单元格内存在目标,即(Pr(Object)=1),我们希望置信度分数等于预测框和真实框之间的交并比(IOU)。
。 Pr(Object)=[0, 1], 如果该单元格内不存在目标(即Pr(Object)=0),则置信度分数为0。 如果单元格内存在目标,即(Pr(Object)=1),我们希望置信度分数等于预测框和真实框之间的交并比(IOU)。 -
每个cell对应的类别概率C,参数数量与该模型类别数量保持一致,label为one-hot编码。
-
此外,根据公式推算,我们发现用置信度*某一类别的概率=
 即得到了一个特殊的置信度分数,表示每个预测框中具体某个类别的置信度
即得到了一个特殊的置信度分数,表示每个预测框中具体某个类别的置信度
损失函数
YOLOV1的损失函数被分为坐标损失、置信度损失和网格类别损失三种
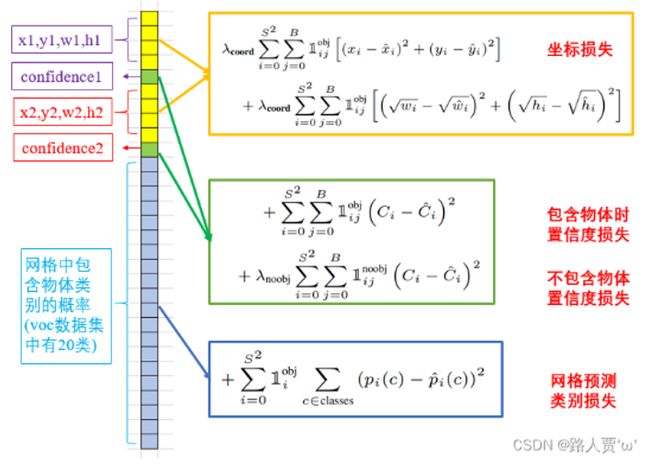
坐标损失

简要介绍下四个坐标(x,y,w,h)的含义,x,y表示预测框中心点坐标,w,h表示预测框的宽高。
![]() 表示第i个cell中的第j个预测框是否负责检测物体,同一个cell中仅有IOU值最高的一个框会负责检测物体,并约束其坐标
表示第i个cell中的第j个预测框是否负责检测物体,同一个cell中仅有IOU值最高的一个框会负责检测物体,并约束其坐标
第一行表示中心点的坐标损失,第二行表示宽高的损失,至于为何对宽高加根号,是为了消除大小框不同的影响。
举个例子,以预测框的宽度为例,不加根号的话,若目标框宽为100,预测结果为90,差值为10,误差为10%,损失为(90-100)^2 = 100; 若目标框宽10,预测结果为9,差值为1,误差为10%,损失为(9-10)^2=1。可以看出,同样的预测差值,产生了同样的损失,但是这个差值给大小框带来的误差差了10倍,而如何利用这个损失值去修正误差的话,对大的预测框来说,微调10%,对小的预测框来说,重调100%。
而加了根号之后,若目标框宽为100,预测结果为90,差值为10,误差为10%,损失为0.263;若目标框宽10,预测结果为9,差值为1,误差为10%,损失为0.0263。同样的误差,对于大小框之间的惩罚从原来的百倍差距,降为10倍差距,即提升了对小框的惩罚力度,毕竟对于小的预测框,一点点偏差都会产生很大的影响。(模型对大小框的约束能力能存在十倍差距,是否可以进一步改进)
置信度损失

![]() 表示第i个cell中的第j个预测框是否负责检测物体,
表示第i个cell中的第j个预测框是否负责检测物体, ![]() 表示第i个cell中的第j个预测框是否不负责检测物体,两个数值含义相反。 表示该预测框的真实置信度,通过上述公式计算得出, 表示模型预测的置信度,此部分损失函数是为了让模型掌握自我评价的能力,为测试过程选择最佳预测框用。
表示第i个cell中的第j个预测框是否不负责检测物体,两个数值含义相反。 表示该预测框的真实置信度,通过上述公式计算得出, 表示模型预测的置信度,此部分损失函数是为了让模型掌握自我评价的能力,为测试过程选择最佳预测框用。
第一行表示负责检测物体的框的置信度损失,第二行表示不负责检测物体的框的置信度损失 (问:两种置信度之间有什么区别)
分类损失

![]() 表示第i个cell内是否存在目标物体
表示第i个cell内是否存在目标物体
测试过程
测试过程就非常简单了,对于一次前向传播得到的S * S *B个预测框,根据各个候选框对应的置信度分数,利用非极大值自抑(NMS),最终得到所有预测结果。
非极大值自抑制(NMS):所有预测框,按照置信度分数从大到小排序。第一轮,选择置信度最高的预测框作为基准,然后所有其他预测框按顺序依次计算与基准预测框的IOU值(提前设置一个阈值,当IOU大于这个阈值,则认为两个预测框高度重合,预测的是同一个物体),对于和基准预测框重合的则直接淘汰。一轮结束后,排除上一轮的基准,重新选择新的预测框作为基准重复上述步骤。
缺点
-
每个cell只能预测一类物体,对于密度大的小物体无法预测
-
定位损失占比较大(包括坐标损失和置信度损失),致使模型更加侧重定位物体,分类能力相对较弱
-
测试时,如果同意物体的长宽比发生变化,则难以泛化。
论文链接:You Only Look Once: Unified, Real-Time Object Detection
源码地址:mirrors / alexeyab / darknet
参考内容:【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)