Redis(CentOS)
6379默认端口号
命令大全:
https://redis.io/commands/set/
安装与开启
#使⽤yum安装Redis
yum -y install redis
#查看是否启动
ps -ef|grep redis
#启动redis:
redis-server /etc/redis.conf &
#停⽌Redis
redis-cli shutdown
#或者直接杀掉进程(kill -9 强制杀掉, kill -15优雅退出)
kill -9 PID

操作Redis
redis-cli


(存放一个key,获取key)
开启隧道
Xshell 配置隧道
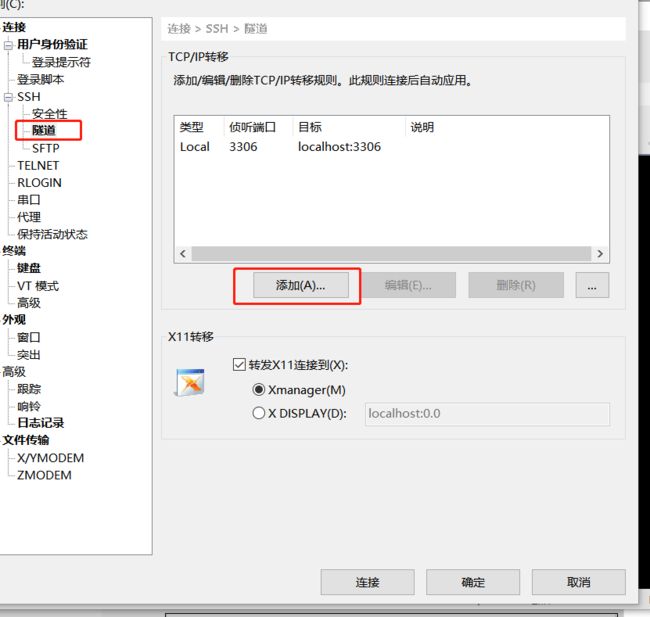

全部配置之后, 需要重新关闭连接, 打开连接才可以
后续访问云服务器的Redis, 就可以使⽤ 127.0.0.1 6379端⼝号(上图中配置的端⼝号) 来访问
可视化客户端连接

如果报Stream On Error: NOAUTH Authentication required.错误,把密码填上(123456)

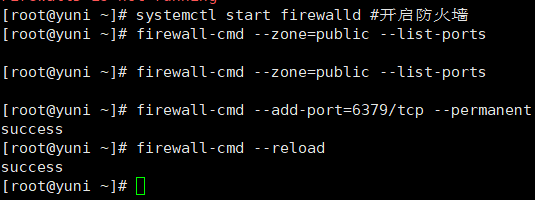
开启防⽕墙
#开启防火墙
systemctl start firewalld
//查询已开放的端⼝
firewall-cmd --zone=public --list-ports
//如果没有6379, 则开启
firewall-cmd --add-port=6379/tcp --permanent
//重载⼊添加的端⼝
firewall-cmd --reload
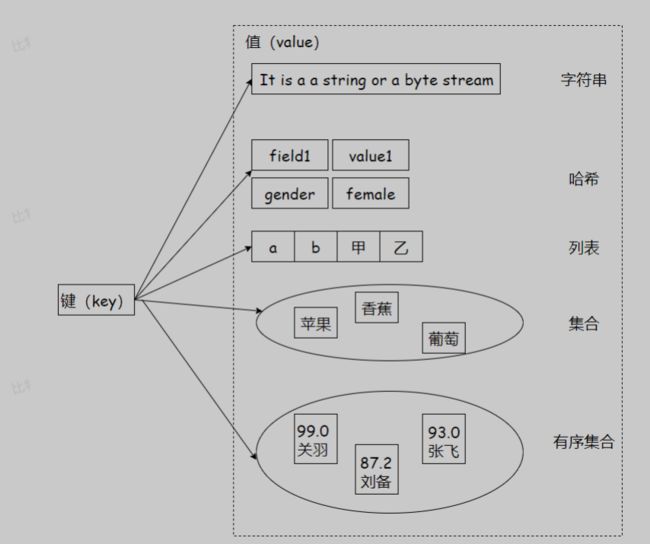
Redis 常⻅数据类型
– string 字符串
– hash 哈希
– list 列表
– set 集合
– zset 有序集合
Redis 有 5 种数据结构,但它们都是键值对种的值,对于键来说有⼀些通⽤的命令。

set 一个存在的key会把之前的key对应的value覆盖

KEYS
返回所有满⾜样式(pattern)的 key。⽀持如下统配样式。
语法:KEYS pattern
h?llo 匹配 hello, hallo 和 hxllo
h*llo 匹配 hllo 和heeeello
h[ae]llo 匹配hello 和hallo 但不匹配 hillo
h[^e]llo 匹配hallo, hbllo, ... 但不匹配 hello
h[a-b]llo 匹配hallo 和 hbllo
EXISTS
判断某个 key 是否存在。
语法:EXISTS key [key …]

DEL
删除指定的 key

EXPIRE
为指定的 key 添加秒级的过期时间(Time To Live TTL)
TTL
获取指定 key 的过期时间,秒级。
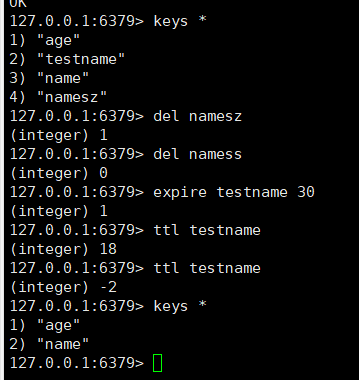
-1表示没有设置有效期,-2表示过期了
TYPE
返回 key 对应的数据类型。

数据结构
type 命令实际返回的就是当前键的数据结构类型
- string(字符串)
- list(列表)
- hash(哈希)
- set(集合)
- zset(有序集合)
SpringBoot 集成Redis
添加Redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
或者

配置
#数据库索引
spring.redis.database=1
#端⼝号
spring.redis.port=6379
#IP
spring.redis.host=43.143.223.50
#连接池最⼩空闲连接数
spring.redis.lettuce.pool.min-idle=5
#连接池最⼤空闲连接数
spring.redis.lettuce.pool.max-idle=10
#连接池最⼤连接数
spring.redis.lettuce.pool.max-active=8
#最⼤等待时间
spring.redis.lettuce.pool.max-wait=1ms
#关闭超时时间
#spring.redis.lettuce.shutdown-timeout=100ms
spring:
redis:
database: 1
port: 6379
host: 139.159.150.152
password: 123456
lettuce:
pool:
min-idle: 5
max-idle: 10
max-active: 8
max-wait: 1ms
操作string
@RequestMapping("/redis")
@RestController
public class RedisController {
@Autowired
private RedisTemplate stringRedisTemplate;
@RequestMapping("/setStr")
public String setStr(String key,String value){
if (!StringUtils.hasLength(key) || !StringUtils.hasLength(value)){
return "failed";
}
stringRedisTemplate.opsForValue().set(key,value);
//hash
stringRedisTemplate.opsForHash().put("hashKey","k1","v1");
stringRedisTemplate.opsForHash().put("hashKey","k2","v2");
//list
stringRedisTemplate.opsForList().leftPush("listKey","l1");
stringRedisTemplate.opsForList().leftPush("listKey","l2");
//set
stringRedisTemplate.opsForSet().add("setKey","s1","s2","s3");
//zset
stringRedisTemplate.opsForZSet().add("zsetKey","z1",80);
stringRedisTemplate.opsForZSet().add("zsetKey","z2",90);
stringRedisTemplate.opsForZSet().add("zsetKey","z3",10);
return "success";
}
}
Spring Session 持久化
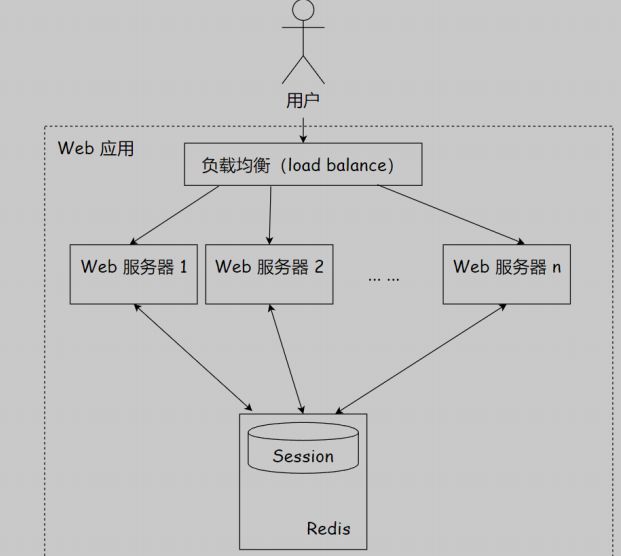
Http协议是⽆状态的,这样对于服务端来说,没有办法区分是新的访客还是旧的访 客。但是,有些业务场景,需要追踪⽤户多个请求,此时就需要Session.
⼀个Web应⽤, 可能部署在不同的服务器上, 通过Nginx等进⾏负载均衡. 此时, 来⾃同⼀个⽤户的Http请求就会被分发到不同的服务器上. 这样就会出现Session信息不同步的问题. 当⽤户刷新⼀次访问是可能会发现需要重新登录,这个问题是⽤户⽆法容忍的
为了解决这个问题,可以使⽤ Redis 将⽤户的 Session 信息进⾏集中管理,如下图所示,在这种模式下,只要保证 Redis 是⾼可⽤和可扩展性的,⽆论⽤户被均衡到哪台 Web 服务器上,都集中从 Redis 中查询、更新 Session 信息。
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
配置
spring:
redis:
database: 0
port: 6379
host: 127.0.0.1
password: 123456
session:
store-type: redis
redis:
flush-mode: on_save
namespace: spring:session
server:
servlet:
session:
timeout: 30m
操作
@RequestMapping("/session")
@RestController
public class SessionController {
@RequestMapping("/login")
public String login(String name, Integer age, HttpSession session) throws JsonProcessingException {
//模拟,不登录, 只存session
User user = new User();
user.setName(name);
user.setAge(age);
ObjectMapper mapper = new ObjectMapper();
session.setAttribute("user_session",mapper.writeValueAsString(user));
return "success";
}
@RequestMapping("/getSess")
public String getSess(HttpServletRequest request){
HttpSession session = request.getSession(false);
if (session!=null && session.getAttribute("user_session")!=null){
return (String) session.getAttribute("user_session");
}
return null;
}
}
@Data
class User{
private String name;
private Integer age;
}
运行,观察Session存储结果
⽤前缀配置来⾃于spring配置项: spring.session.redis.namespace
spring:session:sessions:expires+sessionId 对应⼀个空值, 判断session是否存在
spring:session:sessions: sessionId: 对应⼀个hash数据结构, 存储session相关的属性, 包括有效期, 创建时间等
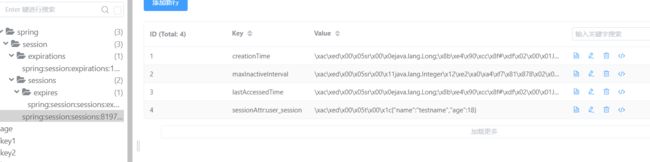
lastAccessedTime: 系统字段-最后访问时间
maxInactiveInterval: 系统字段-session失效的间隔时⻓
sessionAttr:session_user_key: ⽤户存⼊session中的数据
creationTime: 系统字段-创建时间
spring:session:expirations+时间戳(过期时间): 对应的是⼀个set数据结构. 存储待
过期的sessionid列表

Redis 典型应⽤ - 缓存(cache)
缓存 (cache) 是计算机中的⼀个经典的概念. 在很多场景中都会涉及到.
核⼼思路就是把⼀些常⽤的数据放到触⼿可及(访问速度更快)的地⽅, ⽅便随时读取.
使⽤Redis 做缓存
在⼀个⽹站中, 我们经常会使⽤关系型数据库 (⽐如 MySQL) 来存储数据.
关系型数据库虽然功能强⼤, 但是有⼀个很⼤的缺陷, 就是性能不⾼. (换⽽⾔之, 进⾏⼀次查询操作消耗的系统资源较多).
为什么说关系型数据库性能不⾼?
- 数据库把数据存储在硬盘上, 硬盘的 IO 速度并不快. 尤其是随机访问.
- 如果查询不能命中索引, 就需要进⾏表的遍历, 这就会⼤⼤增加硬盘 IO 次数.
- 关系型数据库对于 SQL 的执⾏会做⼀系列的解析, 校验, 优化⼯作.
- 如果是⼀些复杂查询, ⽐如联合查询, 需要进⾏笛卡尔积操作, 效率更是降低很多
因此, 如果访问数据库的并发量⽐较⾼, 对于数据库的压⼒是很⼤的, 很容易就会使数据库服务器宕机.
为什么并发量⾼了就会宕机?
服务器每次处理⼀个请求, 都是需要消耗⼀定的硬件资源的. 所谓的硬件资源包括
不限于 CPU, 内存, 硬盘, ⽹络带宽…
⼀个服务器的硬件资源本身是有限的. ⼀个请求消耗⼀份资源, 请求多了, ⾃然把
资源就耗尽了. 后续的请求没有资源可⽤, ⾃然就⽆法正确处理. 更严重的还会导
致服务器程序的代码出现崩溃
如何让数据库能够承担更⼤的并发量呢? 核⼼思路主要是两个:
- 开源: 引⼊更多的机器, 部署更多的数据库实例, 构成数据库集群. (主从复制, 分库分表等…)
- 节流: 引⼊缓存, 使⽤其他的⽅式保存经常访问的热点数据, 从⽽降低直接访问数据库的请求数量.
实际开发中, 这两种⽅案往往是会搭配使⽤的.
Redis 就是⼀个⽤来作为数据库缓存的常⻅⽅案.
Redis 访问速度⽐ MySQL 快很多. 或者说处理同⼀个访问请求, Redis 消耗的系
统资源⽐ MySQL 少很多. 因此 Redis 能⽀持的并发量更⼤.
- Redis 数据在内存中, 访问内存⽐硬盘快很多.
- Redis 只是⽀持简单的 key-value 存储, 不涉及复杂查询的那么多限制规则.
Redis 就是⼀个⽤来作为数据库缓存的常⻅⽅案.
Redis 访问速度⽐ MySQL 快很多. 或者说处理同⼀个访问请求, Redis 消耗的系
统资源⽐ MySQL 少很多. 因此 Redis 能⽀持的并发量更⼤.
- Redis 数据在内存中, 访问内存⽐硬盘快很多.
- Redis 只是⽀持简单的 key-value 存储, 不涉及复杂查询的那么多限制规则.
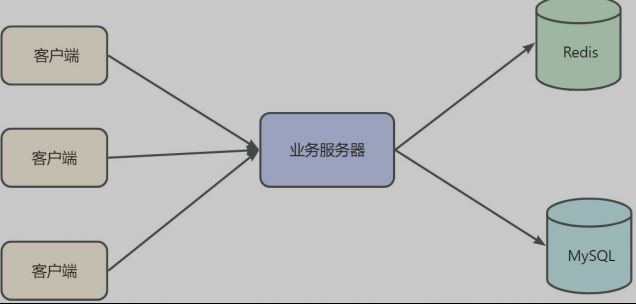
客户端访问业务服务器, 发起查询请求.
- 业务服务器先查询 Redis, 看想要的数据是否在 Redis 中存在.
- 如果已经在 Redis 中存在了, 就直接返回. 此时不必访问 MySQL 了.
- 如果在 Redis 中不存在, 再查询 MySQL, 同时存在保存在Redis中
缓存穿透, 缓存雪崩 和 缓存击穿
缓存穿透 (Cache penetration)
什么是缓存穿透?
访问的 key 在 Redis 和 数据库中都不存在. 此时这样的 key 不会被放到缓存上, 后续如果仍然在访问该 key, 依然会访问到数据库.
这就会导致数据库承担的请求太多, 压⼒很⼤.
这种情况称为 缓存穿透.
为何产⽣?
原因可能有⼏种:
● 业务设计不合理. ⽐如缺少必要的参数校验环节, 导致⾮法的 key 也被进⾏查询了.
● 开发/运维误操作. 不⼩⼼把部分数据从数据库上误删了.
● ⿊客恶意攻击.
如何解决?
● 针对要查询的参数进⾏严格的合法性校验. ⽐如要查询的 key 是⽤户的⼿机 号, 那么就需要校验当前 key 是否满⾜⼀个合法的⼿机号的格式.
● 针对数据库上也不存在的 key , 也存储到 Redis 中, ⽐如 value 就随便设成⼀ 个 “”. 避免后续频繁访问数据库.
● 使⽤布隆过滤器先判定 key 是否存在, 再真正查询.
关于缓存雪崩 (Cache avalanche)
什么是缓存雪崩
短时间内⼤量的 key 在缓存上失效, 导致数据库压⼒骤增, 甚⾄直接宕机.
15本来 Redis 是 MySQL 的⼀个护盾, 帮 MySQL 抵挡了很多外部的压⼒. ⼀旦护盾突然失效了, MySQL ⾃身承担的压⼒骤增, 就可能直接崩溃.
为何产⽣?
⼤规模 key 失效, 可能性主要有两种:
● Redis 挂了.
● Redis 上的⼤量的 key 同时过期.
为啥会出现⼤量的 key 同时过期?
这种和可能是短时间内在 Redis 上缓存了⼤量的 key, 并且设定了相同的过期时间.
如何解决?
● 部署⾼可⽤的 Redis 集群, 并且完善监控报警体系.
● 不给 key 设置过期时间 或者 设置过期时间的时候添加随机时间因⼦.
关于缓存击穿 (Cache breakdown)
什么是缓存击穿?
相当于缓存雪崩的特殊情况. 针对热点 key , 突然过期了, 导致⼤量的请求直接访问到数据库上, 甚⾄引起数据库宕机.
如何解决?
● 基于统计的⽅式发现热点 key, 并设置永不过期.
● 访问数据库的时候使⽤分布式锁, 限制同时请求数据库的并发数.