(七)解析Streamlit的数据元素:探索st.dataframe、st.data_editor、st.column_config、st.table、st.metric和st.json的神奇之处
文章目录
- 1 前言
- 2 解锁 Streamlit 中的 st.dataframe 功能
- 3 使用st.data_editor进行数据编辑
- 4 定制数据编辑器 - 使用 st.column_config
-
- 4.1 使用 st.column_config.Column 定制数据编辑器的列
- 4.2 使用 st.column_config.TextColumn 定制数据编辑器的文本列
- 4.3 使用 st.column_config.NumberColumn 定制数据编辑器的数字列
- 4.4 使用 st.column_config.CheckboxColumn 定制数据编辑器的复选框列
- 4.5 使用 st.column_config.SelectboxColumn 定制数据编辑器的下拉框列
- 4.6 使用 st.column_config.DatetimeColumn 定制数据编辑器的日期时间列
- 4.7 使用 st.column_config.DateColumn 定制数据编辑器的日期列
- 4.8 使用 st.column_config.TimeColumn 定制数据编辑器的时间列
- 4.9 使用 st.column_config.ListColumn 定制数据编辑器的列表列
- 4.10 使用 st.column_config.LinkColumn 定制数据编辑器的链接列
- 4.11 使用 st.column_config.ImageColumn 定制数据编辑器的图片列
- 4.12 使用 st.column_config.LineChartColumn 定制数据编辑器的折线图列
- 4.13 使用 st.column_config.BarChartColumn 定制数据编辑器的柱状图列
- 4.14 使用 st.column_config.ProgressColumn 定制数据编辑器的进度条列
- 5 使用 st.table 展示数据框
- 6 使用 st.metric 展示指标数据
-
- 6.1 使用 st.columns 和 st.metric 创建单个指标数据显示
- 6.2 使用 st.columns 和 st.metric 创建多个指标数据显示
- 6.3 控制增量指示器的颜色和显示
- 7 使用 st.json 展示 JSON 数据
- 8 结语

1 前言
欢迎来到我的博客!今天我将向大家介绍 Streamlit 中一系列令人惊叹的数据元素!如果你是一个数据分析师、机器学习工程师或者只是对数据处理和可视化感兴趣的朋友,那么你来对地方了!在这篇博客中,我们将探索 Streamlit 为我们提供的一些核心组件,包括 st.dataframe、st.data_editor、st.column_config、st.table、st.metric 和 st.json。准备好了吗?我们马上就要起航啦!⛵️
Streamlit 作为一个基于 Python 的开源框架,旨在使数据科学家和开发者能够快速简单地构建数据驱动的应用程序。它不仅仅是一个强大的工具,还是一个友好的社区,致力于提供用于构建令人惊叹的数据可视化应用程序的解决方案。在本文中,我们将重点关注 Streamlit 提供的一些核心数据元素,它们将帮助我们更好地理解和展示数据。无论你是需要展示一个数据表格、调整数据编辑器、创建指标度量,还是展示 JSON 数据,Streamlit 都为你提供了简单又强大的工具。
让我们一起探索这些令人兴奋的数据元素,看看它们如何帮助我们轻松地打造出美观、交互性强的数据应用程序。准备好了吗?让我们开始吧!
2 解锁 Streamlit 中的 st.dataframe 功能
st.dataframe 是 Streamlit 提供的一个功能强大的组件,它允许我们以易读且美观的方式展示数据框(Dataframe)。无论是处理小型数据集还是庞大的数据表,st.dataframe 都能让数据的展示变得轻而易举。它能够自动适应屏幕宽度,使得数据在任何设备上都能得到清晰的展示。不仅如此,st.dataframe 还支持水平或垂直滚动,确保你能方便地浏览整个数据集。
让我们来看一个示例,以便更好地理解 st.dataframe 的用法和效果。下面是一个简单的代码段:
import streamlit as st
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.random.randn(50, 20),
columns=('col %d' % i for i in range(20)))
st.dataframe(df) # Same as st.write(df)

上述示例中,我们使用了 pd.DataFrame 和 np.random.randn 创建了一个随机的数据框 df,然后通过 st.dataframe(df) 将数据呈现在界面上。这一行代码等同于 st.write(df),可以看到结果非常简单而直观。
st.dataframe 不仅提供了基本的数据展示功能,还支持对数据进行排序、筛选和搜索等操作。
我们已经介绍了如何使用 st.dataframe 来展示普通的数据框。现在,让我们将 st.dataframe 的功能提升到一个全新的水平!你知道吗?你甚至可以使用 Pandas Styler 对象来改变呈现的数据框的样式。这是不是很酷?
让我们来看一个示例,展示了如何使用 Pandas Styler 对象来改变数据框 df 的样式:
import streamlit as st
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.random.randn(10, 20),
columns=('col %d' % i for i in range(20)))
st.dataframe(df.style.highlight_max(axis=0))
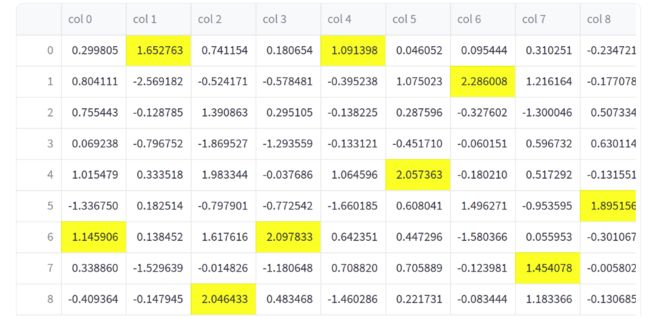
上述示例中,我们使用 np.random.randn 创建了一个 10 行 20 列的数据框 df,然后使用 df.style.highlight_max(axis=0) 方法来对数据框的最大值进行突出显示。通过将 Styler 对象传递给 st.dataframe,我们可以以更加引人注目的方式展示数据。这在数据分析和可视化中非常有用,尤其是当你想要突出显示一些重要的数据特征时。
除了 highlight_max,Pandas Styler 还提供了其他许多内置的样式方法,如 highlight_min、background_gradient 等等。你可以根据需要选择适合你数据框的样式效果。
通过将 st.dataframe 与 Pandas Styler 结合使用,你可以轻松地打造出具有个性化视觉效果的数据展示。这样,不仅可以提高数据的可读性,还能够让你的数据应用程序更加引人注目和专业。
我们已经了解到如何使用 Pandas Styler 对象来改变数据框的样式。现在,让我们继续探索 st.dataframe 的更多高级用法!你知道吗?你还可以通过 column_config、hide_index 或 column_order 来自定义展示的数据框。这样,你可以根据自己的需求定制数据框的表现形式。让我们来看一个示例:
import random
import pandas as pd
import streamlit as st
df = pd.DataFrame(
{
"name": ["Roadmap", "Extras", "Issues"],
"url": ["https://roadmap.streamlit.app", "https://extras.streamlit.app", "https://issues.streamlit.app"],
"stars": [random.randint(0, 1000) for _ in range(3)],
"views_history": [[random.randint(0, 5000) for _ in range(30)] for _ in range(3)],
}
)
st.dataframe(
df,
column_config={
"name": "App name",
"stars": st.column_config.NumberColumn(
"Github Stars",
help="Number of stars on GitHub",
format="%d ⭐",
),
"url": st.column_config.LinkColumn("App URL"),
"views_history": st.column_config.LineChartColumn(
"Views (past 30 days)", y_min=0, y_max=5000
),
},
hide_index=True,
)
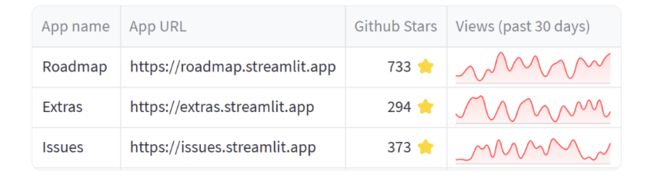
上述示例中,我们使用了一个简单的数据框 df,其中包含了应用的名称、URL、GitHub 的星数以及过去 30 天的访问历史。通过传递 column_config 参数,我们可以自定义每列的显示方式。在示例代码中,我们定义了以下配置:
- “name” 列被重命名为 “App name”;
- “stars” 列被定义成了一个 st.column_config.NumberColumn 对象,可以显示带有 GitHub
星数的标题,并指定了格式为整数 “%d ⭐”; - “url” 列被定义成了一个 st.column_config.LinkColumn 对象,将单元格的内容作为链接展示;
- “views_history” 列被定义成了一个 st.column_config.LineChartColumn
对象,生成了一个折线图,显示过去 30 天的访问历史,并指定了 Y 轴的最小值和最大值。
另外,我们还设置了 hide_index=True,将索引隐藏起来。
通过使用 column_config、hide_index 和 column_order,我们可以根据自己的需求灵活地定制数据框的展示方式,使得数据的表达更加清晰和有针对性。
我们已经介绍了如何使用 st.dataframe 来展示数据框。现在,让我们进一步探索 st.dataframe 的功能!你知道吗?你可以使用 use_container_width 参数来让数据框自动适应容器的宽度。这非常有用,特别是当你希望以更大的尺寸展示数据框时。让我们来看一个示例:
import pandas as pd
import streamlit as st
# 使用缓存加载数据框,这样只会加载一次
@st.cache_data
def load_data():
return pd.DataFrame(
{
"第一列": [1, 2, 3, 4],
"第二列": [10, 20, 30, 40],
}
)
# 使用会话状态变量存储用于调整数据框尺寸的布尔值
st.checkbox("使用容器宽度", value=False, key="use_container_width")
df = load_data()
# 根据复选框的值,显示数据框并允许用户根据容器宽度调整数据框尺寸
st.dataframe(df, use_container_width=st.session_state.use_container_width)
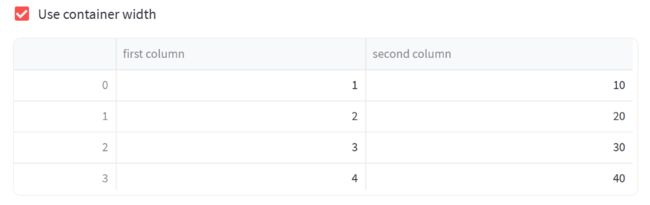
上述示例中,我们首先定义了一个加载数据的函数 load_data,并使用 @st.cache_data 装饰器缓存数据框,以便只加载一次。
然后,我们通过使用 st.checkbox 创建一个复选框来控制是否使用容器的宽度来展示数据框。复选框的初始值被设置为 False。
接下来,我们调用 load_data 函数加载数据框 df。
最后,我们使用 st.dataframe 来展示数据框,并通过将 use_container_width 参数设置为 st.session_state.use_container_width 来根据复选框的值来调整数据框的尺寸。如果复选框选中,数据框将会完全展开,适应容器的宽度;如果复选框未选中,数据框将以默认宽度展示。
通过使用 use_container_width,你可以轻松地将数据框的宽度调整为适合当前容器的大小,提供更好的可视化效果。
3 使用st.data_editor进行数据编辑
在这一章中,我们将介绍 Streamlit 提供的一个强大工具 - st.data_editor,它可以让你直接在 Streamlit 应用中编辑数据。通过使用 st.data_editor,你可以轻松地修改和更新数据并实时查看结果。
st.data_editor 是 Streamlit 中的一个函数,它允许你以交互的方式编辑数据框。当你在应用中使用 st.data_editor 时,会出现一个可编辑的表格,你可以直接在其中修改数据,而无需编写任何代码。
使用 st.data_editor 有几个主要的作用:
- 数据修改和更新:你可以直接在 st.data_editor 提供的编辑器中修改和更新数据,比如增加、删除或修改行和列的值。
- 实时反馈:修改数据之后,st.data_editor 会实时更新,并将更改后的数据显示出来,让你可以即时查看操作的结果。
- 交互性和易用性:通过简单的交互操作,你可以直观地对数据进行编辑,而无需编写复杂的代码。
下面是一个示例,展示如何使用 st.data_editor 编辑数据框:
import streamlit as st
import pandas as pd
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
edited_df = st.data_editor(df)
favorite_command = edited_df.loc[edited_df["rating"].idxmax()]["command"]
st.markdown(f"Your favorite command is **{favorite_command}** ")

在上述示例中,我们首先创建了一个简单的数据框 df,包含了不同命令、评分和小部件信息。然后,我们使用 st.data_editor 来编辑这个数据框,并将结果存储在 edited_df 中。
接着,我们将使用编辑后的数据框 edited_df,找到评分最高的命令,并输出该命令。
通过这个示例,你可以看到 st.data_editor 的交互性和便利之处。你只需要调用函数,即可获得一个可编辑的表格,并可以直接在表格中进行数据修改。
另外,你还可以通过将 num_rows 设置为 “dynamic”,让用户添加和删除行:
import streamlit as st
import pandas as pd
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
edited_df = st.data_editor(df, num_rows="dynamic")
favorite_command = edited_df.loc[edited_df["rating"].idxmax()]["command"]
st.markdown(f"Your favorite command is **{favorite_command}** ")
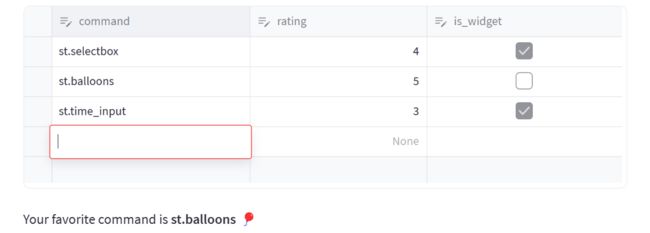
在上述示例中,我们创建了一个名为 df 的数据框。然后,我们使用 st.data_editor 通过将 num_rows 参数设置为 “dynamic” 来展示可编辑的数据框。这样,用户可以添加和删除行,以适应他们的需求。
最后,我们使用编辑后的数据框 edited_df 找到评分最高的命令,并输出该命令。
通过使用 num_rows=“dynamic”,你可以将行的数量设置为动态的,并允许用户在编辑器中动态地添加和删除行。这为用户提供了更大的灵活性,并且可以轻松地根据需要调整数据表的大小。
另外,你还可以通过使用 column_config、hide_index、column_order 或 disabled 来自定义数据编辑器:
import pandas as pd
import streamlit as st
df = pd.DataFrame(
[
{"command": "st.selectbox", "rating": 4, "is_widget": True},
{"command": "st.balloons", "rating": 5, "is_widget": False},
{"command": "st.time_input", "rating": 3, "is_widget": True},
]
)
edited_df = st.data_editor(
df,
column_config={
"command": "Streamlit Command",
"rating": st.column_config.NumberColumn(
"Your rating",
help="How much do you like this command (1-5)?",
min_value=1,
max_value=5,
step=1,
format="%d ⭐",
),
"is_widget": "Widget ?",
},
disabled=["command", "is_widget"],
hide_index=True,
)
favorite_command = edited_df.loc[edited_df["rating"].idxmax()]["command"]
st.markdown(f"Your favorite command is **{favorite_command}** ")

在上述示例中,我们首先创建了一个名为 df 的数据框。然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过以下方式进行自定义:
- column_config:通过指定新的列名和自定义控件的方式,我们将 “command” 列的名称改为 “Streamlit
Command”,将 “rating” 列的控件类型改为数字输入框,并添加帮助文本、最小值、最大值、步长和格式化选项。 - disabled:我们禁用了 “command” 和 “is_widget” 列的编辑功能,使它们成为只读。
- hide_index:我们隐藏了索引列,只展示了数据内容。
用户可以通过编辑器进行交互,并根据提供的自定义配置进行编辑。在编辑完成后,我们找到评分最高的命令,并输出该命令。
通过使用这些参数,你可以进一步自定义数据编辑器的外观和行为。这让你能够根据特定需求提供灵活的编辑界面,并增加用户体验。
4 定制数据编辑器 - 使用 st.column_config
4.1 使用 st.column_config.Column 定制数据编辑器的列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"widgets": ["st.selectbox", "st.number_input", "st.text_area", "st.button"],
}
)
st.data_editor(
data_df,
column_config={
"widgets": st.column_config.Column(
"Streamlit Widgets",
help="Streamlit **widget** commands ",
width="medium",
required=True,
)
},
hide_index=True,
num_rows="dynamic",
)

在本章中,我们将介绍如何使用 st.column_config.Column 来定制数据编辑器的列。
在上述示例中,我们首先创建了一个名为 data_df 的数据框,其中包含了一个名为 “widgets” 的列,存储了几个 Streamlit 的小部件命令。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过使用 column_config 参数对列进行定制。我们的目标是定制 “widgets” 列。
我们为 “widgets” 列创建了一个 st.column_config.Column 对象,并指定了以下参数:
- title:设置列的标题为 “Streamlit Widgets”。
- help:提供帮助文本,以解释该列是关于 Streamlit 小部件命令的。
- width:指定列的宽度为 “medium”,对于长文本或宽列,可以使用不同的宽度选项。
- required:将该列标记为必填项,使用户必须填写该列的值。
通过使用 st.column_config.Column,我们能够对数据编辑器中的列进行更精细的控制和定制。这样,我们可以根据实际需求来设置列的显示样式、帮助文本、宽度以及是否为必填项。
4.2 使用 st.column_config.TextColumn 定制数据编辑器的文本列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"widgets": ["st.selectbox", "st.number_input", "st.text_area", "st.button"],
}
)
st.data_editor(
data_df,
column_config={
"widgets": st.column_config.TextColumn(
"Widgets",
help="Streamlit **widget** commands ",
default="st.",
max_chars=50,
validate="^st\.[a-z_]+$",
)
},
hide_index=True,
)
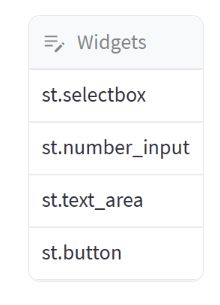
在上述示例中,我们继续介绍了 st.column_config 的另一个类 st.column_config.TextColumn,可以用来定制数据编辑器的文本列。
我们仍然使用之前的数据框 data_df,其中包含一个名为 “widgets” 的列,存储了几个 Streamlit 的小部件命令。
使用 st.data_editor 来展示可编辑的数据框,通过使用 column_config 参数对列进行定制。本次我们针对 “widgets” 列使用 st.column_config.TextColumn 进行定制。
我们为 “widgets” 列创建了一个 st.column_config.TextColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Widgets”。
- help:提供帮助文本,以解释该列是关于 Streamlit 小部件命令的。
- default:设置默认值为 “st.”。
- max_chars:限制输入文本的最大字符数为 50。
- validate:使用正则表达式进行验证,确保值符合 “st.” 以及小写字母和下划线的规则。
通过使用 st.column_config.TextColumn,我们可以对文本列进行更细致的控制和限制。可以设置标题、帮助文本、默认值、字符数限制和输入验证规则,以确保用户提供有效的值。
通过定制文本列,我们可以增强数据编辑器的功能和用户体验,允许用户更轻松地输入和处理数据。
4.3 使用 st.column_config.NumberColumn 定制数据编辑器的数字列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"price": [20, 950, 250, 500],
}
)
st.data_editor(
data_df,
column_config={
"price": st.column_config.NumberColumn(
"Price (in USD)",
help="The price of the product in USD",
min_value=0,
max_value=1000,
step=1,
format="$%d",
)
},
hide_index=True,
)
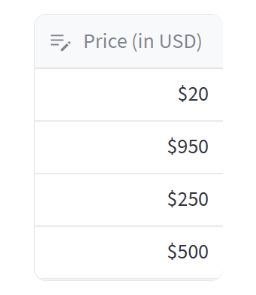
在本节中,我们将介绍如何使用 st.column_config.NumberColumn 来定制数据编辑器的数字列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “price” 的列,存储了一些产品的价格。
然后,使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “price” 列使用了 st.column_config.NumberColumn 进行定制。
我们为 “price” 列创建了一个 st.column_config.NumberColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Price (in USD)”。
- help:提供帮助文本,说明该列存储的是产品的美元价格。
- min_value:设置最小值为 0,限制输入值不能小于 0。
- max_value:设置最大值为 1000,限制输入值不能大于 1000。
- step:设置步长为 1,控制数字输入的增减间隔。
- format:我们使用 “$%d” 的格式来显示价格,让输入值自动前面添加美元符号。
通过使用 st.column_config.NumberColumn,我们可以对数字列进行更精细的控制和格式化。可以设置标题、帮助文本、最小值、最大值、步长和显示格式,以确保用户提供有效的数字输入。
使用定制的数字列,我们可以更好地管理和处理与数字相关的数据,增强数据编辑器的功能和用户体验。
4.4 使用 st.column_config.CheckboxColumn 定制数据编辑器的复选框列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"widgets": ["st.selectbox", "st.number_input", "st.text_area", "st.button"],
"favorite": [True, False, False, True],
}
)
st.data_editor(
data_df,
column_config={
"favorite": st.column_config.CheckboxColumn(
"Your favorite?",
help="Select your **favorite** widgets",
default=False,
)
},
disabled=["widgets"],
hide_index=True,
)
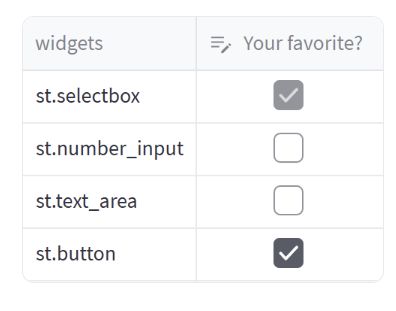
在本节中,我们将介绍如何使用 st.column_config.CheckboxColumn 来定制数据编辑器的复选框列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含两列:一个名为 “widgets”,存储了几个 Streamlit 的小部件命令;另一个名为 “favorite”,存储了用户对小部件的喜好情况。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “favorite” 列使用了 st.column_config.CheckboxColumn 进行定制。
我们为 “favorite” 列创建了一个 st.column_config.CheckboxColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Your favorite?”。
- help:提供帮助文本,以解释该列是关于用户对小部件的喜好情况的选择复选框。
- default:设置默认值为 False,即未选中复选框。
通过使用 st.column_config.CheckboxColumn,我们可以对复选框列进行定制和控制。可以设置标题、帮助文本和默认值,以提供更好的用户体验和数据交互性。
注意,我们还通过将 “widgets” 列添加到 disabled 参数中来禁用了该列的编辑。这样,用户将无法编辑 “widgets” 列的值。
使用定制的复选框列,我们可以更好地了解用户对特定选项的喜好与意见。这在收集用户反馈、偏好调查等场景中非常有用。
4.5 使用 st.column_config.SelectboxColumn 定制数据编辑器的下拉框列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"category": [
" Data Exploration",
" Data Visualization",
" LLM",
" Data Exploration",
],
}
)
st.data_editor(
data_df,
column_config={
"category": st.column_config.SelectboxColumn(
"App Category",
help="The category of the app",
width="medium",
options=[
" Data Exploration",
" Data Visualization",
" LLM",
],
)
},
hide_index=True,
)
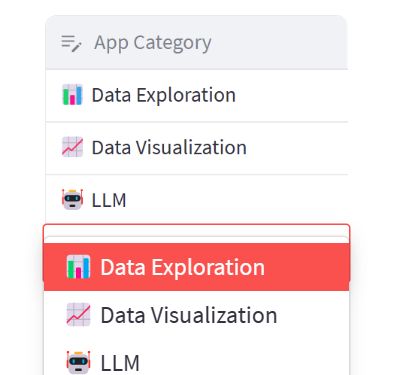
在本节中,我们将介绍如何使用 st.column_config.SelectboxColumn 来定制数据编辑器的下拉框列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “category” 的列,存储了应用的分类信息。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “category” 列使用了 st.column_config.SelectboxColumn 进行定制。
我们为 “category” 列创建了一个 st.column_config.SelectboxColumn 对象,并指定了以下参数:
- title:设置列的标题为 “App Category”。
- help:提供帮助文本,解释该列是关于应用分类的下拉框。
- width:设置下拉框的宽度为 “medium”,使其具有中等宽度。
- options:设置下拉框的选项为 [“ Data Exploration”, “ Data Visualization”,
“ LLM”],即用户可以从这些选项中选择。
通过使用 st.column_config.SelectboxColumn,我们可以对下拉框列进行定制和控制。可以设置标题、帮助文本、宽度和选项,以便用户能够从预定义的选项中进行选择。
在数据编辑器中使用定制的下拉框列,可以提供更好的数据交互性和用户体验,尤其对于需要从特定选项中选择的数据字段来说。
4.6 使用 st.column_config.DatetimeColumn 定制数据编辑器的日期时间列
from datetime import datetime
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"appointment": [
datetime(2024, 2, 5, 12, 30),
datetime(2023, 11, 10, 18, 0),
datetime(2024, 3, 11, 20, 10),
datetime(2023, 9, 12, 3, 0),
]
}
)
st.data_editor(
data_df,
column_config={
"appointment": st.column_config.DatetimeColumn(
"Appointment",
min_value=datetime(2023, 6, 1),
max_value=datetime(2025, 1, 1),
format="D MMM YYYY, h:mm a",
step=60,
),
},
hide_index=True,
)
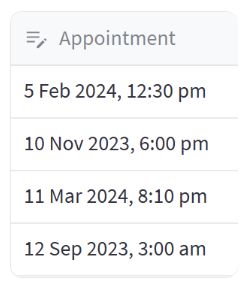
在本节中,我们将介绍如何使用 st.column_config.DatetimeColumn 来定制数据编辑器的日期时间列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “appointment” 的列,存储了预约的日期和时间。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “appointment” 列使用了 st.column_config.DatetimeColumn 进行定制。
我们为 “appointment” 列创建了一个 st.column_config.DatetimeColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Appointment”。
- min_value:设置最小日期时间为 datetime(2023, 6, 1),即2023年6月1日之后的日期时间可选择。
- max_value:设置最大日期时间为 datetime(2025, 1, 1),即2025年1月1日之前的日期时间可选择。
- format:设置日期时间的显示格式为 “D MMM YYYY, h:mm a”,例如 “5 Feb 2024, 12:30 PM”。
- step:设置步长为 60 分钟,即每次改变日期时间时以 60 分钟为单位递增或递减。
通过使用 st.column_config.DatetimeColumn,我们可以对日期时间列进行定制和控制。可以设置标题、最小和最大日期时间、显示格式和步长,以便用户能够在指定的范围内选择合适的日期时间。
在数据编辑器中使用定制的日期时间列,可以方便地进行日期时间的选择和编辑,适用于需要与日期时间相关的数据字段。
4.7 使用 st.column_config.DateColumn 定制数据编辑器的日期列
from datetime import date
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"birthday": [
date(1980, 1, 1),
date(1990, 5, 3),
date(1974, 5, 19),
date(2001, 8, 17),
]
}
)
st.data_editor(
data_df,
column_config={
"birthday": st.column_config.DateColumn(
"Birthday",
min_value=date(1900, 1, 1),
max_value=date(2005, 1, 1),
format="DD.MM.YYYY",
step=1,
),
},
hide_index=True,
)

在本节中,我们将介绍如何使用 st.column_config.DateColumn 来定制数据编辑器的日期列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “birthday” 的列,存储了生日信息。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “birthday” 列使用了 st.column_config.DateColumn 进行定制。
我们为 “birthday” 列创建了一个 st.column_config.DateColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Birthday”。
- min_value:设置最小日期为 date(1900, 1, 1),即1900年1月1日之后的日期可选择。
- max_value:设置最大日期为 date(2005, 1, 1),即2005年1月1日之前的日期可选择。
- format:设置日期的显示格式为 “DD.MM.YYYY”,例如 “01.01.1980”。
- step:设置步长为 1 天,即每次改变日期时以 1 天为单位递增或递减。
通过使用 st.column_config.DateColumn,我们可以对日期列进行定制和控制。可以设置标题、最小和最大日期、显示格式和步长,以便用户能够在指定的范围内选择合适的日期。
在数据编辑器中使用定制的日期列,可以方便地进行日期的选择和编辑,适用于需要与日期相关的数据字段。
4.8 使用 st.column_config.TimeColumn 定制数据编辑器的时间列
from datetime import time
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"appointment": [
time(12, 30),
time(18, 0),
time(9, 10),
time(16, 25),
]
}
)
st.data_editor(
data_df,
column_config={
"appointment": st.column_config.TimeColumn(
"Appointment",
min_value=time(8, 0, 0),
max_value=time(19, 0, 0),
format="hh:mm a",
step=60,
),
},
hide_index=True,
)
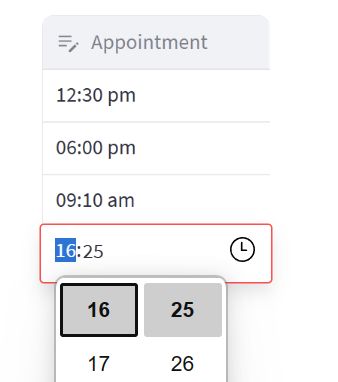
在本节中,我们将介绍如何使用 st.column_config.TimeColumn 来定制数据编辑器的时间列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “appointment” 的列,存储了预约的时间信息。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “appointment” 列使用了 st.column_config.TimeColumn 进行定制。
我们为 “appointment” 列创建了一个 st.column_config.TimeColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Appointment”。
- min_value:设置最小时间为 time(8, 0, 0),即每天从早上8点之后的时间可选择。
- max_value:设置最大时间为 time(19, 0, 0),即每天到晚上7点之前的时间可选择。
- format:设置时间的显示格式为 “hh:mm a”,例如 “12:30 PM”。
- step:设置步长为 60 分钟,即每次改变时间时以 60 分钟为单位递增或递减。
通过使用 st.column_config.TimeColumn,我们可以对时间列进行定制和控制。可以设置标题、最小和最大时间、显示格式和步长,以便用户能够在指定的范围内选择合适的时间。
在数据编辑器中使用定制的时间列,可以方便地进行时间的选择和编辑,适用于需要与时间相关的数据字段。
4.9 使用 st.column_config.ListColumn 定制数据编辑器的列表列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"sales": [
[0, 4, 26, 80, 100, 40],
[80, 20, 80, 35, 40, 100],
[10, 20, 80, 80, 70, 0],
[10, 100, 20, 100, 30, 100],
],
}
)
st.data_editor(
data_df,
column_config={
"sales": st.column_config.ListColumn(
"Sales (last 6 months)",
help="The sales volume in the last 6 months",
width="medium",
),
},
hide_index=True,
)
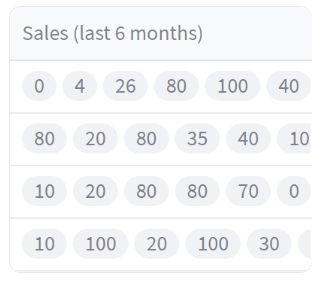
在本节中,我们将介绍如何使用 st.column_config.ListColumn 来定制数据编辑器的列表列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “sales” 的列,存储了过去6个月的销售数据。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “sales” 列使用了 st.column_config.ListColumn 进行定制。
我们为 “sales” 列创建了一个 st.column_config.ListColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Sales (last 6 months)”。
- help:提供对该列的帮助信息,为 “The sales volume in the last 6 months”。
- width:设置列的宽度为 “medium”。
通过使用 st.column_config.ListColumn,我们可以对列表列进行定制和控制。可以设置标题、帮助信息和列宽度,以便用户能够更好地了解和操作列表列的数据。
在数据编辑器中使用定制的列表列,可以方便地查看和编辑列表数据,适用于需要存储和处理多个值的数据字段。
4.10 使用 st.column_config.LinkColumn 定制数据编辑器的链接列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"apps": [
"https://roadmap.streamlit.app",
"https://extras.streamlit.app",
"https://issues.streamlit.app",
"https://30days.streamlit.app",
],
}
)
st.data_editor(
data_df,
column_config={
"apps": st.column_config.LinkColumn(
"Trending apps",
help="The top trending Streamlit apps",
validate="^https://[a-z]+\.streamlit\.app$",
max_chars=100,
)
},
hide_index=True,
)
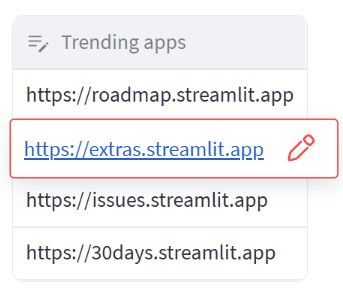
在本节中,我们将介绍如何使用 st.column_config.LinkColumn 来定制数据编辑器的链接列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “apps” 的列,存储了不同的 Streamlit 应用链接。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “apps” 列使用了 st.column_config.LinkColumn 进行定制。
我们为 “apps” 列创建了一个 st.column_config.LinkColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Trending apps”。
- help:提供对该列的帮助信息,为 “The top trending Streamlit apps”。
- validate:设置正则表达式模式,用于验证链接的格式,该模式为
“^https://[a-z]+.streamlit.app$”,表示链接必须以 “https://” 开头,以
“.streamlit.app” 结尾,并且中间部分只能包含小写字母。 - max_chars:设置链接显示的最大字符数为 100。
通过使用 st.column_config.LinkColumn,我们可以对链接列进行定制和控制。可以设置标题、帮助信息、验证格式和显示的最大字符数,以便用户能够更好地理解和操作链接列的数据。
在数据编辑器中使用定制的链接列,可以方便地点击链接查看相关内容,适用于需要存储和展示链接数据的字段。
4.11 使用 st.column_config.ImageColumn 定制数据编辑器的图片列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"apps": [
"https://storage.googleapis.com/s4a-prod-share-preview/default/st_app_screenshot_image/5435b8cb-6c6c-490b-9608-799b543655d3/Home_Page.png",
"https://storage.googleapis.com/s4a-prod-share-preview/default/st_app_screenshot_image/ef9a7627-13f2-47e5-8f65-3f69bb38a5c2/Home_Page.png",
"https://storage.googleapis.com/s4a-prod-share-preview/default/st_app_screenshot_image/31b99099-8eae-4ff8-aa89-042895ed3843/Home_Page.png",
"https://storage.googleapis.com/s4a-prod-share-preview/default/st_app_screenshot_image/6a399b09-241e-4ae7-a31f-7640dc1d181e/Home_Page.png",
],
}
)
st.data_editor(
data_df,
column_config={
"apps": st.column_config.ImageColumn(
"Preview Image", help="Streamlit app preview screenshots"
)
},
hide_index=True,
)
在本节中,我们将介绍如何使用 st.column_config.ImageColumn 来定制数据编辑器的图片列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “apps” 的列,存储了不同 Streamlit 应用的预览图片链接。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “apps” 列使用了 st.column_config.ImageColumn 进行定制。
我们为 “apps” 列创建了一个 st.column_config.ImageColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Preview Image”。
- help:提供对该列的帮助信息,为 “Streamlit app preview screenshots”。
通过使用 st.column_config.ImageColumn,我们可以对图片列进行定制和控制。可以设置标题和帮助信息,以便用户能够更好地了解和操作图片列的数据。
在数据编辑器中使用定制的图片列,可以方便地查看和编辑图片链接,适用于需要存储和展示图片链接数据的字段。
4.12 使用 st.column_config.LineChartColumn 定制数据编辑器的折线图列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"sales": [
[0, 4, 26, 80, 100, 40],
[80, 20, 80, 35, 40, 100],
[10, 20, 80, 80, 70, 0],
[10, 100, 20, 100, 30, 100],
],
}
)
st.data_editor(
data_df,
column_config={
"sales": st.column_config.LineChartColumn(
"Sales (last 6 months)",
width="medium",
help="The sales volume in the last 6 months",
y_min=0,
y_max=100,
),
},
hide_index=True,
)
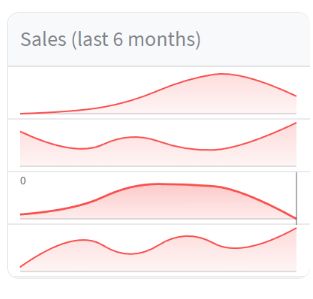
在本节中,我们将介绍如何使用 st.column_config.LineChartColumn 来定制数据编辑器的折线图列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “sales” 的列,该列包含了过去6个月的销售数据。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “sales” 列使用了 st.column_config.LineChartColumn 进行定制。
我们为 “sales” 列创建了一个 st.column_config.LineChartColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Sales (last 6 months)”。
- width:设置折线图的宽度为 “medium”,可以根据需求设置合适的宽度。
- help:提供对该列的帮助信息,为 “The sales volume in the last 6 months”。
- y_min:设置折线图的 Y 轴最小值为 0。
- y_max:设置折线图的 Y 轴最大值为 100。
通过使用 st.column_config.LineChartColumn,我们可以对折线图列进行定制和控制。可以设置标题、宽度、帮助信息以及 Y 轴的取值范围,以便用户更好地理解和操作折线图列的数据。
在数据编辑器中使用定制的折线图列,可以方便地查看和编辑折线图数据,适用于需要存储和展示趋势数据的字段。
4.13 使用 st.column_config.BarChartColumn 定制数据编辑器的柱状图列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"sales": [
[0, 4, 26, 80, 100, 40],
[80, 20, 80, 35, 40, 100],
[10, 20, 80, 80, 70, 0],
[10, 100, 20, 100, 30, 100],
],
}
)
st.data_editor(
data_df,
column_config={
"sales": st.column_config.BarChartColumn(
"Sales (last 6 months)",
help="The sales volume in the last 6 months",
y_min=0,
y_max=100,
),
},
hide_index=True,
)
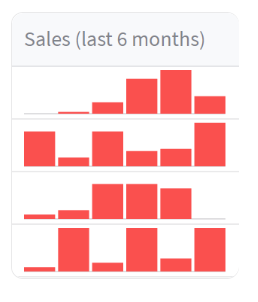
在本节中,我们将介绍如何使用 st.column_config.BarChartColumn 来定制数据编辑器的柱状图列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “sales” 的列,该列包含了过去6个月的销售数据。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “sales” 列使用了 st.column_config.BarChartColumn 进行定制。
我们为 “sales” 列创建了一个 st.column_config.BarChartColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Sales (last 6 months)”。
- help:提供对该列的帮助信息,为 “The sales volume in the last 6 months”。
- y_min:设置柱状图的 Y 轴最小值为 0。
- y_max:设置柱状图的 Y 轴最大值为 100。
通过使用 st.column_config.BarChartColumn,我们可以对柱状图列进行定制和控制。可以设置标题、帮助信息以及 Y 轴的取值范围,以便用户更好地理解和操作柱状图列的数据。
在数据编辑器中使用定制的柱状图列,可以方便地查看和编辑柱状图数据,适用于需要存储和展示分类数据的字段。
4.14 使用 st.column_config.ProgressColumn 定制数据编辑器的进度条列
import pandas as pd
import streamlit as st
data_df = pd.DataFrame(
{
"sales": [200, 550, 1000, 80],
}
)
st.data_editor(
data_df,
column_config={
"sales": st.column_config.ProgressColumn(
"Sales volume",
help="The sales volume in USD",
format="$%f",
min_value=0,
max_value=1000,
),
},
hide_index=True,
)
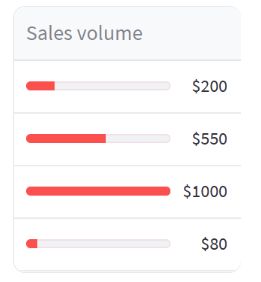
在本节中,我们将介绍如何使用 st.column_config.ProgressColumn 来定制数据编辑器的进度条列。
在上述示例中,我们创建了一个名为 data_df 的数据框,其中包含一个名为 “sales” 的列,该列包含了销售数据的数值。
然后,我们使用 st.data_editor 来展示可编辑的数据框,并通过 column_config 参数对列进行定制。这次我们针对 “sales” 列使用了 st.column_config.ProgressColumn 进行定制。
我们为 “sales” 列创建了一个 st.column_config.ProgressColumn 对象,并指定了以下参数:
- title:设置列的标题为 “Sales volume”。
- help:提供对该列的帮助信息,为 “The sales volume in USD”。
- format:设置数值的格式为 “$%f”,这样数值会以美元符号开头并保留两位小数。
- min_value:设置进度条的最小值为 0。
- max_value:设置进度条的最大值为 1000。
通过使用 st.column_config.ProgressColumn,我们可以对进度条列进行定制和控制。可以设置标题、帮助信息、数值格式以及进度条的取值范围,以便用户更好地理解和操作进度条列的数据。
在数据编辑器中使用定制的进度条列,可以方便地查看和编辑数值数据的进度,适用于需要存储和展示进度数据的字段。
5 使用 st.table 展示数据框
import streamlit as st
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.random.randn(10, 5),
columns=('col %d' % i for i in range(5)))
st.table(df)
在本章中,我们将介绍如何使用 st.table 来展示数据框。
在上述示例中,我们创建了一个名为 df 的数据框,其中包含了随机生成的 10 行 5 列的数据。
然后,我们使用 st.table 来展示这个数据框。st.table 是 Streamlit 提供的一个用于展示数据框的方法,可以直接在网页上以表格的形式展示数据。
通过使用 st.table,我们可以方便地查看和分析数据框的内容。它提供了表格的形式展示数据,并支持排序、筛选和搜索功能,使得数据的浏览和分析更加直观和便捷。
在展示数据框时,st.table 会自动根据数据框的大小调整表格的布局,保证内容的可见性和易读性。
6 使用 st.metric 展示指标数据
6.1 使用 st.columns 和 st.metric 创建单个指标数据显示
import streamlit as st
st.metric(label="Temperature", value="70 °F", delta="1.2 °F")
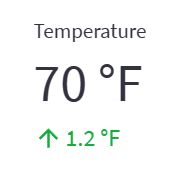
在本章中,我们将介绍如何使用 st.metric 来展示指标数据。
在上述示例中,我们使用 st.metric 来展示温度的指标数据。st.metric 是 Streamlit 提供的一个方法,用于展示具有标签、值和增量的指标数据。
在 st.metric 方法中,我们可以设置以下参数:
- label:表示指标的名称或标签,例如 “Temperature”。
- value:表示指标的值,例如 “70 °F”。
- delta:表示指标的增量或变化量,例如 “1.2 °F”。
通过使用 st.metric,我们可以直观地展示指标数据,使其更易读和易理解。指标数据通常用于表示某个事物的状态或性能,并可以显示其当前值和变化量,方便用户进行比较和分析。
在展示指标数据时,st.metric 会根据提供的值和增量来自动着色和显示符号,以便更清晰地传达数据的含义。
6.2 使用 st.columns 和 st.metric 创建多个指标数据显示
import streamlit as st
col1, col2, col3 = st.columns(3)
col1.metric("Temperature", "70 °F", "1.2 °F")
col2.metric("Wind", "9 mph", "-8%")
col3.metric("Humidity", "86%", "4%")

在本章中,我们将介绍如何使用 st.columns 和 st.metric 结合起来创建多个指标数据的显示。
在上述示例中,我们使用了 st.columns 方法创建了一个具有 3 列的布局,然后在每一列中使用了 st.metric 来展示不同的指标数据。
首先,我们使用 st.columns(3) 创建了 col1、col2 和 col3 三个列。然后,我们分别在这三个列中使用 st.metric 方法来展示不同的指标数据。
对于每个 st.metric,我们都提供了以下信息:
- label:指标的名称或标签,例如 “Temperature”、“Wind” 和 “Humidity”。
- value:指标的值,例如 “70 °F”、“9 mph” 和 “86%”。
- delta:指标的增量或变化量,例如 “1.2 °F”、“-8%” 和 “4%”。
通过结合使用 st.columns 和 st.metric,我们可以在不同的列中展示多个指标数据,使之更直观和易于比较。
6.3 控制增量指示器的颜色和显示
import streamlit as st
st.metric(label="Gas price", value=4, delta=-0.5,
delta_color="inverse")
st.metric(label="Active developers", value=123, delta=123,
delta_color="off")
在本章中,我们将介绍如何控制增量指示器的颜色和显示。
在上述示例中,我们使用 st.metric 展示了两个不同的指标数据,并通过设置 delta_color 参数来控制增量指示器的颜色和显示。
在第一个指标数据中,我们设置 delta_color=“inverse”,这将导致增量指示器的颜色反转,即当增量为负数时,指示器将显示为绿色,而不是默认的红色。
在第二个指标数据中,我们设置 delta_color=“off”,这将关闭增量指示器的显示,即不显示增量指示器。
通过控制增量指示器的颜色和显示,我们可以更加灵活地呈现指标数据,使其更符合特定需求和场景。
7 使用 st.json 展示 JSON 数据
import streamlit as st
st.json({
'foo': 'bar',
'baz': 'boz',
'stuff': [
'stuff 1',
'stuff 2',
'stuff 3',
'stuff 5',
],
})

在本章中,我们将介绍如何使用 st.json 来展示 JSON 数据。
在上述示例中,我们使用 st.json 来展示一个简单的 JSON 对象。st.json 是 Streamlit 提供的一个方法,用于展示 JSON 数据。
我们将一个 JSON 对象传递给 st.json 方法进行展示。JSON 对象可以包含键值对,键可以是字符串,值可以是字符串、数字、布尔值、列表或嵌套的 JSON 对象。
通过使用 st.json,我们可以以格式化的形式展示 JSON 数据,使其更易读和理解。展示的 JSON 数据可以包含多层嵌套,方便查看和分析复杂的结构。
8 结语
在本文中,我们学习了如何使用 Streamlit 提供的各种方法来展示和呈现指标数据和 JSON 数据。无论是单独展示一个指标数据,还是创建多个指标数据的布局,亦或是控制增量指示器的颜色和显示,Streamlit 提供了简单而强大的工具来帮助我们呈现数据。此外,通过使用 st.json 方法,我们还可以以可视化和易读的方式展示复杂的 JSON 数据。通过掌握这些方法,我们可以轻松地创建交互式和可视化的数据展示应用,提供更好的用户体验和数据理解。无论是在数据科学、可视化还是产品展示中,Streamlit 都是一个非常有用的工具。期待读者继续深入学习和探索 Streamlit,创造出令人印象深刻的应用!
