kubernetes pod 资源限制 探针
资源限制
当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。
当为 Pod 中的容器指定了 request 资源时,代表容器运行所需的最小资源量,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还为容器指定了 limit 资源时,kubelet 就会确保运行的容器不会使用超出所设的 limit 资源量。kubelet 还会为容器预留所设的 request 资源量, 供该容器使用。
如果 Pod 运行所在的节点具有足够的可用资源,容器可以使用超出所设置的 request 资源量。不过,容器不可以使用超出所设置的 limit 资源量。
如果给容器设置了内存的 limit 值,但未设置内存的 request 值,Kubernetes 会自动为其设置与内存 limit 相匹配的 request 值。 类似的,如果给容器设置了 CPU 的 limit 值但未设置 CPU 的 request 值,则 Kubernetes 自动为其设置 CPU 的 request 值 并使之与 CPU 的 limit 值匹配。
官网示例:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
资源限制 总结
limit与request区别【重中之重】
spec.containers.resources.requests.cpu|memory 设置Pod容器创建时需要预留的资源量 容器应用最低配置 <= requests <= limits
spec.containers.resources.limits.cpu|memory 设置Pod容器能够使用的资源量上限,如果容器进程内存使用量超过limits.memory会引发OOM资源单位
CPU资源量单位: cpu个数 1 2 0.1 0.5 0.25 毫核 100m 250m 1000m 1500m
内存资源量单位:整数(默认单位为字节) 2的底数单位(Ki Mi Gi Ti) 10的底数单位(K M G T)kubectl describe -n 命名空间 pod查看Pod中每个容器的资源量限制 kubectl describe node 查看Node节点中的每个Pod或总的资源限制使用情况
Pod 和 容器 的资源请求和限制
spec.containers[].resources.requests.cpu //定义创建容器时预分配的CPU资源 spec.containers[].resources.requests.memory //定义创建容器时预分配的内存资源 spec.containers[].resources.limits.cpu //定义 cpu 的资源上限 spec.containers[].resources.limits.memory //定义内存的资源上限
CPU 资源单位
CPU 资源的 request 和 limit 以 cpu 为单位。Kubernetes 中的一个 cpu 相当于1个 vCPU(1个超线程)。
Kubernetes 也支持带小数 CPU 的请求。spec.containers[].resources.requests.cpu 为 0.5 的容器能够获得一个 cpu 的一半(cpu中一个核的一半。多核需要乘以核数) CPU 资源(类似于Cgroup对CPU资源的时间分片)。表达式 0.1 等价于表达式 100m(毫核),表示每 1000 毫秒内容器可以使用的 CPU 时间总量为 0.1*1000 毫秒。
Kubernetes 不允许设置精度小于 1m 的 CPU 资源。内存 资源单位
内存的 request 和 limit 以字节为单位。可以以整数表示,或者以10为底数的指数的单位(E、P、T、G、M、K)来表示, 或者以2为底数的指数的单位(Ei、Pi、Ti、Gi、Mi、Ki)来表示。
如:1KB=10^3=1000,1MB=10^6=1000000=1000KB,1GB=10^9=1000000000=1000MB
1KiB=2^10=1024,1MiB=2^20=1048576=1024KiB
示例1:
apiVersion: v1 kind: Pod metadata: name: frontend spec: containers: - name: app image: images.my-company.example/app:v4 env: #MySQL必须要有这个环境变量 并且内存至少1G - name: MYSQL_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" - name: log-aggregator image: images.my-company.example/log-aggregator:v6 resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
此例子中的 Pod 有两个容器。每个容器的 request 值为 0.25 cpu 和 64MiB 内存,每个容器的 limit 值为 0.5 cpu 和 128MiB 内存。
那么可以认为该 Pod 的总的资源 request 为 0.5 cpu 和 128 MiB 内存,总的资源 limit 为 1 cpu 和 256MiB 内存。
MySQL需要的内存至少1G,这里可能会报错OOM不停重启。实例2将修改内存限制

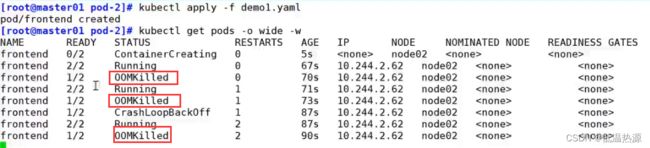
示例2:cpu限制的简便写法,并放宽内存限制
vim pod2.yaml apiVersion: v1 kind: Pod metadata: name: frontend spec: containers: - name: web image: nginx env: - name: WEB_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" - name: db image: mysql env: - name: MYSQL_ROOT_PASSWORD value: "abc123" resources: requests: memory: "512Mi" cpu: "0.5" limits: memory: "1Gi" cpu: "1"kubectl apply -f pod2.yaml kubectl describe pod frontendkubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES frontend 2/2 Running 5 15m 10.244.2.4 node02kubectl describe nodes node02 #由于当前虚拟机有2个CPU,所以Pod的CPU Limits一共占用了50% Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE --------- ---- ------------ ---------- --------------- ------------- --- default frontend 500m (25%) 1 (50%) 128Mi (3%) 256Mi (6%) 16m kube-system kube-flannel-ds-amd64-f4pbp 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%) 19h kube-system kube-proxy-pj4wp 0 (0%) 0 (0%) 0 (0%) 0 (0%) 19h Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 600m (30%) 1100m (55%) memory 178Mi (4%) 306Mi (7%) ephemeral-storage 0 (0%) 0 (0%)
重启策略(restartPolicy)
当 Pod 中的容器退出时通过节点上的 kubelet 重启容器。适用于 Pod 中的所有容器。
- Always:当容器终止退出后,总是重启容器,默认策略
- OnFailure:当容器异常退出(退出状态码非0)时,重启容器;正常退出则不重启容器
- Never:当容器终止退出,从不重启容器。
#注意:K8S 中不支持重启 Pod 资源,只有删除重建。
在用 yaml 方式创建 Deployment 和 StatefulSet 类型时,restartPolicy 只能是 Always,kubectl run 创建 Pod 可以选择 Always,OnFailure,Never 三种策略kubectl edit deployment nginx-deployment ...... restartPolicy: Always
//示例 命令每过30s退出,但是根据重启策略默认always会不断重启
vim pod3.yaml apiVersion: v1 kind: Pod metadata: name: foo spec: containers: - name: busybox image: busybox args: - /bin/sh - -c - sleep 30; exit 3kubectl apply -f pod3.yaml//查看Pod状态,等容器启动后30秒后执行exit退出进程进入error状态,就会重启次数加1
kubectl get pods -w NAME READY STATUS RESTARTS AGE foo 0/1 ContainerCreating 0 7s foo 1/1 Running 0 21s foo 0/1 Error 0 50s foo 1/1 Running 1 66s foo 0/1 Error 1 97s foo 0/1 CrashLoopBackOff 1 111s foo 1/1 Running 2 2m7s foo 0/1 Error 2 2m37s foo 0/1 CrashLoopBackOff 2 2m52s foo 1/1 Running 3 3m23s foo 0/1 Error 3 3m53s foo 0/1 CrashLoopBackOff 3 4m7s foo 1/1 Running 4 5m foo 0/1 Error 4 5m30s foo 0/1 CrashLoopBackOff 4 5m43s foo 1/1 Running 5 6m51s foo 0/1 Error 5 7m21s foo 0/1 CrashLoopBackOff 5 7m36s foo 1/1 Running 6 10m foo 0/1 Error 6 10mkubectl delete -f pod3.yaml更改为从不重启
vim pod3.yaml apiVersion: v1 kind: Pod metadata: name: foo spec: containers: - name: busybox image: busybox args: - /bin/sh - -c - sleep 30; exit 3 restartPolicy: Never#注意:跟container同一个级别
kubectl apply -f pod3.yaml//容器进入error状态不会进行重启
kubectl get pods -w
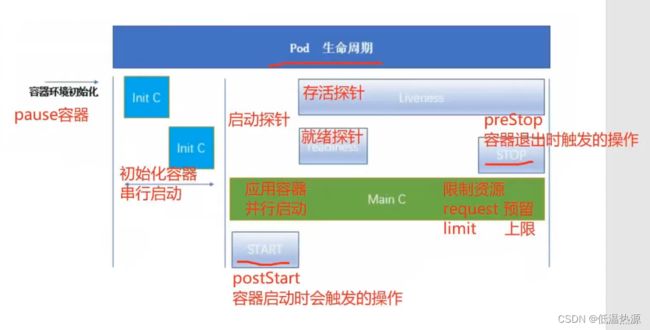
健康检查:又称为探针(Probe)
探针是由kubelet对容器执行的定期诊断。
官网示例:
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
Pod 容器的 3 种探针(健康检查)
- 存活探针(livenessProbe):探测是否正常运行。如果探测失败则kubelet杀掉容器(Pod容器会根据重启策略决定是否重启)
- 就绪探针(readinessProbe):探测Pod是否进入就绪状态(ready状态栏1/1),并做好接收service请求的准备。如果探测失败则Pod会变成未就绪状态(ready状态栏0/1),service资源会删除所关联的端点(endpoints),并不再转发请求给就绪探测失败的Pod
- 启动探针(startupProbe):探测容器内的应用是否启动成功。在启动探针探测成功之前,存活探针和就绪探针都会暂时处于禁用状态,直到启动探针探测成功
探针的 3 种探测方式
- exec:在command字段中指定在容器内执行的Linux命令来进行探测,如果命令返回码为0则认为探测成功,如果返回码为非0则认为探测失败
- tcpSocket:向指定的Pod容器端口发送tcp连接请求,如果端口正确且tcp连接成功则认为探测成功,如果tcp连接失败则认为探测失败
- httpGet:向指定的Pod容器端口和URL路径发送http get请求,如果http响应状态码为2XX 3XX则认为探测成功,如果响应状态码为4XX 5XX则认为探测失败
探针参数
initialDelaySeconds:指定容器启动后延迟几秒开始探测
periodSeconds:每天探测的间隔时间(秒数)
failureThreshold:探测连续失败几次后判断探测失败
timeoutSeconds:指定探测超时等待时间(秒数)
How to know the args probe have?
kubectl explain pod.spec.containers 查看有哪些探针 kubectl explain pod.spec.containers.livenessprobe #查看具体探针参数
//示例1:exec方式 根据命令行执行结果判断
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: k8s.gcr.io/busybox args: - /bin/sh - -c #容器运行命令 创建文件夹 30秒后删除。 - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60 livenessProbe: exec: command: #探针命令,检查文件夹是否存在。由于30s删除,30s后存活探针失效,重启容器 - cat - /tmp/healthy failureThreshold: 1 initialDelaySeconds: 5 periodSeconds: 5 initialDelaySeconds: 指定 kubelet 在执行第一次探测前应该等待5秒,即第一次探测是在容器启动后的第6秒才开始执行。默认是 0 秒,最小值是 0。 periodSeconds: 指定了 kubelet 应该每 5 秒执行一次存活探测。默认是 10 秒。最小值是 1。 failureThreshold: 当探测失败时,Kubernetes 将在放弃之前重试的次数。 存活探测情况下的放弃就意味着重新启动容器。 就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。 timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。 (在 Kubernetes 1.20 版本之前,exec 探针会忽略 timeoutSeconds 探针会无限期地 持续运行,甚至可能超过所配置的限期,直到返回结果为止。)可以看到 Pod 中只有一个容器。kubelet 在执行第一次探测前需要等待 5 秒,kubelet 会每 5 秒执行一次存活探测。kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。 当到达第 31 秒时,这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
.
编写测试yaml文件(与上面那段原理无太大区别,命令格式稍作修改)
vim exec.yaml apiVersion: v1 kind: Pod metadata: name: liveness-exec namespace: default spec: containers: - name: liveness-exec-container image: busybox imagePullPolicy: IfNotPresent command: ["/bin/sh","-c","touch /tmp/live ; sleep 30; rm -rf /tmp/live; sleep 3600"] livenessProbe: exec: command: ["test","-e","/tmp/live"] initialDelaySeconds: 1 periodSeconds: 3kubectl create -f exec.yaml30秒后删除文件,导致存活探针认为寄寄,重启容器
kubectl describe pods liveness-exec -w Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 5m13s default-scheduler Successfully assigned default/liveness-exec to node1 Normal Killing 2m17s (x3 over 4m35s) kubelet Container liveness-exec-container failed liveness probe, will be restarted Normal Pulled 107s (x4 over 5m13s) kubelet Container image "busybox" already present on machine Normal Created 107s (x4 over 5m13s) kubelet Created container liveness-exec-container Normal Started 107s (x4 over 5m13s) kubelet Started container liveness-exec-container Warning Unhealthy 5s (x13 over 4m41s) kubelet Liveness probe failed:kubectl get pods -w NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 4 5m45s liveness-exec 1/1 Running 5 5m45s若容器是NGINX等,用创建文件再检测的方法太蠢了,可以直接命令行检测,指定必定存在的文件 (如index.html)
注意不要混淆,并不是一定通过检测文件存在性,其本质原理是根据命令行执行结果返回值判断。

示例2:httpGet方式
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-http spec: containers: - name: liveness image: k8s.gcr.io/liveness args: - /server livenessProbe: httpGet: path: /healthz #原理为通过8080端口 发送http get请求 get /healthz 查看返回的状态码 port: 8080 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 3 periodSeconds: 3在这个配置文件中,可以看到 Pod 也只有一个容器。initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。kubelet 会向容器内运行的服务(服务会监听 8080 端口)发送一个 HTTP GET 请求来执行探测。如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。如果处理程序返回失败代码,则 kubelet 会杀死这个容器并且重新启动它。
任何大于或等于 200 并且小于 400 的返回代码标示成功,其它返回代码都标示失败。
编写测试yaml文件
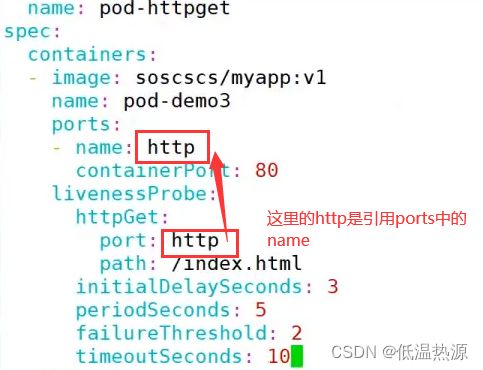
vim httpget.yaml apiVersion: v1 kind: Pod metadata: name: liveness-httpget namespace: default spec: containers: - name: liveness-httpget-container image: nginx imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 livenessProbe: httpGet: port: http path: /index.html initialDelaySeconds: 1 periodSeconds: 3 timeoutSeconds: 10
kubectl create -f httpget.yaml 创建podkubectl get pods -w #-w实时更新 NAME READY STATUS RESTARTS AGE liveness-httpget 1/1 Running 1 2m44s再开个终端,执行删除
kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html -- 为免交互不进入容器执行命令 去容器里删除探针指向的主页文件,这样探针不通过,容器重启
只会重启一次,因为删除了文件,容器重启,根据镜像又生成了这个文件。

示例3:tcpSocket方式
apiVersion: v1 kind: Pod metadata: name: goproxy labels: app: goproxy spec: containers: - name: goproxy image: k8s.gcr.io/goproxy:0.1 ports: - containerPort: 8080 readinessProbe: #就绪探针,效果是node显示notready,不会重启容器 tcpSocket: port: 8080 #与8080端口 进行tcp三次握手 检测 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: #存活探针,不通过重启容器 tcpSocket: port: 8080 initialDelaySeconds: 15 periodSeconds: 20这个例子同时使用 readinessProbe 和 livenessProbe 探测。kubelet 会在容器启动 5 秒后发送第一个 readinessProbe 探测。这会尝试连接 goproxy 容器的 8080 端口。如果探测成功,kubelet 将继续每隔 10 秒运行一次检测。除了 readinessProbe 探测,这个配置包括了一个 livenessProbe 探测。kubelet 会在容器启动 15 秒后进行第一次 livenessProbe 探测。就像 readinessProbe 探测一样,会尝试连接 goproxy 容器的 8080 端口。如果 livenessProbe 探测失败,这个容器会被重新启动。
编写测试yaml
vim tcpsocket.yaml apiVersion: v1 kind: Pod metadata: name: probe-tcp spec: containers: - name: nginx image: nginx livenessProbe: initialDelaySeconds: 5 timeoutSeconds: 1 tcpSocket: port: 8080 #监听8080口 但是由于NGINX提供80端口服务,所以存活探针会重启容器 periodSeconds: 10 failureThreshold: 2kubectl create -f tcpsocket.yamlkubectl exec -it probe-tcp -- netstat -natp -- 为免交互不进入容器执行命令 Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1/nginx: master pro监听8080口 但是由于NGINX提供80端口服务,所以存活探针会重启容器
kubectl get pods -w NAME READY STATUS RESTARTS AGE probe-tcp 1/1 Running 0 1s probe-tcp 1/1 Running 1 25s #第一次是 init(5秒) + period(10秒) * 2 probe-tcp 1/1 Running 2 45s #第二次是 period(10秒) + period(10秒) 重试了两次 probe-tcp 1/1 Running 3 65s若要通过探针测试,将探针监听端口改为NGINX的80口,就不会在重启容器。
示例4:存活探针 就绪探针 启动探针 合集
vim readiness-httpget.yaml apiVersion: v1 kind: Pod metadata: name: readiness-httpget namespace: default spec: containers: - name: readiness-httpget-container image: nginx imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 startupProbe: #启动探针 /index2.html存在,才会将检测权限交给 存活探针 就绪探针 httpGet: port: http path: /index2.html failureThreshold: 30 periodSeconds: 10 livenessProbe: #存活探针 /index.html存在,不会重启 httpGet: port: http path: /index.html initialDelaySeconds: 1 periodSeconds: 3 timeoutSeconds: 10 readinessProbe: #就绪探针 /index1.html存在,才会ready httpGet: port: http path: /index1.html initialDelaySeconds: 1 periodSeconds: 3因为有启动探针 应用最多有5分钟的( failureThreshold * periodSeconds =30*10=300s )的时间完成启动
一旦成功一次,存活探针和就绪探针就会接管对容器的检测
若启动探针一直没有成功,容器在300s后被杀死,并且根据重启策略进行重启。
根据配置文件创建pod资源kubectl create -f readiness-httpget.yaml
启动探针部分
kubectl describe pod readiness-httpget 查看错误详细信息目前是启动探针出错(启动探针完成后才会把后续探测权限交给 存活和就绪探针)
进入容器,创建启动探针需要的文件
kubectl exec -it readiness-httpget -- touch /usr/share/nginx/html/index2.html -- 为免交互不进入容器执行命令启动探针条件满足,此时步进到就绪探针无文件
kubectl describe pod readiness-httpget 查看错误详细信息
就绪探针部分
//readiness就绪探针探测失败,无法进入READY状态
kubectl get pods NAME READY STATUS RESTARTS AGE readiness-httpget 0/1 Running 0 18s进入容器,满足就绪探针需求
kubectl exec -it readiness-httpget sh cd /usr/share/nginx/html/ ls 50x.html index.html echo 123 > index1.html exit ········································ 或者免交互命令 kubectl exec -it readiness-httpget -- touch /usr/share/nginx/html/index1.html就绪探针满足,pod就绪
kubectl get pods NAME READY STATUS RESTARTS AGE readiness-httpget 1/1 Running 0 2m31s
存活探针部分
若此时再删除存活探针指向的文件(http get不到index.html 容器重启)
kubectl exec -it readiness-httpget -- rm -rf /usr/share/nginx/html/index.html -- 为免交互不进入容器执行命令kubectl get pods -w NAME READY STATUS RESTARTS AGE readiness-httpget 1/1 Running 0 4m10s readiness-httpget 0/1 Running 1 4m15s


//示例5:同一pod内 多容器就绪检测 查看ready与service相关信息
vim readiness-myapp.yaml apiVersion: v1 kind: Pod metadata: name: myapp1 labels: app: myapp spec: containers: - name: myapp image: nginx ports: - name: http containerPort: 80 #三个一样的容器,一样的就绪探针和条件,测试多就绪探针显示 readinessProbe: httpGet: port: 80 path: /index.html initialDelaySeconds: 5 periodSeconds: 5 timeoutSeconds: 10 --- apiVersion: v1 kind: Pod metadata: name: myapp2 labels: app: myapp spec: containers: - name: myapp image: nginx ports: - name: http containerPort: 80 readinessProbe: httpGet: port: 80 path: /index.html initialDelaySeconds: 5 periodSeconds: 5 timeoutSeconds: 10 --- apiVersion: v1 kind: Pod metadata: name: myapp3 labels: app: myapp spec: containers: - name: myapp image: nginx ports: - name: http containerPort: 80 readinessProbe: httpGet: port: 80 path: /index.html initialDelaySeconds: 5 periodSeconds: 5 timeoutSeconds: 10 --- apiVersion: v1 kind: Service metadata: name: myapp spec: selector: app: myapp type: ClusterIP ports: - name: http port: 80 targetPort: 80kubectl create -f readiness-myapp.yamlkubectl get pods,svc,endpoints -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/myapp1 1/1 Running 0 66s 10.244.1.33 node1pod/myapp2 1/1 Running 0 66s 10.244.2.34 node2 pod/myapp3 1/1 Running 0 66s 10.244.2.33 node2 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.96.0.1 443/TCP 2d8h service/myapp ClusterIP 10.111.198.14 80/TCP 66s app=myapp service/nginx-service666 NodePort 10.96.38.38 80:31537/TCP 6h2m app=nginx NAME ENDPOINTS AGE endpoints/kubernetes 192.168.80.101:6443 2d8h endpoints/myapp 10.244.1.33:80,10.244.2.33:80,10.244.2.34:80 66s endpoints/nginx-service666 6h2m 删除 myapp1 就绪探针指向的文件
kubectl exec -it pod/myapp1 -- rm -rf /usr/share/nginx/html/index.html//readiness探测失败,Pod 无法进入READY状态,且端点控制器将从 endpoints 中剔除删除该 Pod(myapp1 ) 的 IP 地址
kubectl get pods,svc,endpoints -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/myapp1 0/1 Running 0 2m48s 10.244.1.33 node1pod/myapp2 1/1 Running 0 2m48s 10.244.2.34 node2 pod/myapp3 1/1 Running 0 2m48s 10.244.2.33 node2 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.96.0.1 443/TCP 2d8h service/myapp ClusterIP 10.111.198.14 80/TCP 2m48s app=myapp service/nginx-service666 NodePort 10.96.38.38 80:31537/TCP 6h4m app=nginx NAME ENDPOINTS AGE endpoints/kubernetes 192.168.80.101:6443 2d8h endpoints/myapp 10.244.2.33:80,10.244.2.34:80 2m48s endpoints/nginx-service666 6h4m
启动、退出动作
启动 退出 动作,不像command一样会把镜像内的默认命令覆盖掉。
而是在容器启动和结束时执行。
Pod 应用容器生命周期的启动动作和退出动作
spec.containers.lifecycle.postStart 配置子字段 exec.command 设置 Pod 容器启动时额外的命令操作
spec.containers.lifecycle.preStop 配置子字段 exec.command 设置 Pod 容器运行中被kubelet杀掉退出时所执行的命令操作(不包含容器自行退出的情况)
vim post.yaml apiVersion: v1 kind: Pod metadata: name: lifecycle-demo spec: containers: - name: lifecycle-demo-container image: nginx lifecycle: #此为关键字段 postStart: #执行完init所需要的内容后创建容器,先执行poststart exec: command: ["/bin/sh", "-c", "echo Hello from the postStart handler >> /var/log/nginx/message"] preStop: #在容器结束时候执行prestop exec: command: ["/bin/sh", "-c", "echo Hello from the poststop handler >> /var/log/nginx/message"] volumeMounts: #由于容器结束,日志会随一并消失,所以加上挂载卷,存放日志。 - name: message-log mountPath: /var/log/nginx/ readOnly: false #可读可写 initContainers: #init容器在普通容器之前执行完毕,用于提供容器依赖项。所以第一个执行。 - name: init-myservice image: nginx command: ["/bin/sh", "-c", "echo 'Hello initContainers' >> /var/log/nginx/message"] volumeMounts: - name: message-log mountPath: /var/log/nginx/ readOnly: false volumes: #定义一个存储卷,让容器挂载,存放日志 - name: message-log hostPath: #宿主机路径 path: /data/volumes/nginx/log/ type: DirectoryOrCreate #不存在就创建kubectl apply -f post.yaml查看在哪个节点上 (因为虽然pod可以随地查看,但是挂载的宿主机目录在对应宿主机上)
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES lifecycle-demo 1/1 Running 0 2m8s 10.244.2.28 node02免交互查看容器内输出
kubectl exec -it lifecycle-demo -- cat /var/log/nginx/message Hello initContainers Hello from the postStart handler//在 node02 节点(宿主机)上查看
cd /data/volumes/nginx/log/ ls access.log error.log message cat message Hello initContainers Hello from the postStart handler #由上可知,init Container先执行,然后当一个主容器启动后,Kubernetes 将立即发送 postStart 事件。//删除 pod 后,再在 node02 节点上(宿主机)查看
kubectl delete pod lifecycle-demo[root@node02 log]# cat message Hello initContainers Hello from the postStart handler Hello from the poststop handler
#由上可知,当在容器被终结之前, Kubernetes 将发送一个 preStop 事件。并且无论是kubectl delete结束pod(容器),还是由于存活探针不满足导致kubelet将容器重启(删除),都不会影响prestop的执行。
但是!如果是容器执行完命令自行退出(无论容器内执行 exit 0 正常退出还是执行 exit 3 异常退出),不会执行prestop。
概括一下就是,只有在容器 运行时 被第三方 退出 才会执行prestop。