K8s(kubernetes)介绍以及原理解析
K8s(kubernetes)
云原生
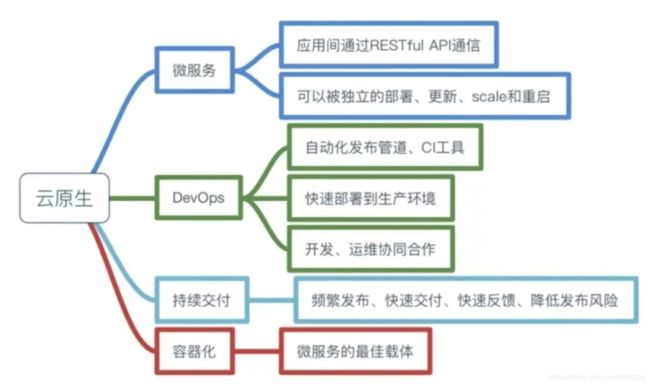
服务部署模式
物理机模式–>虚拟化模式–>云端模式(云原生模式)
K8s简介及架构
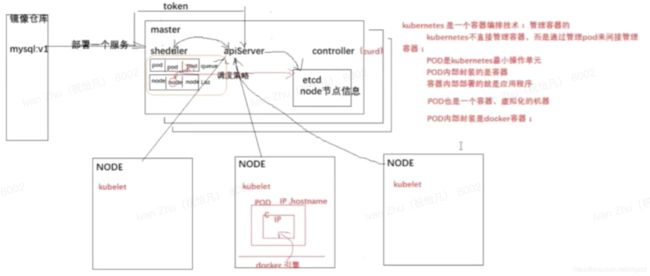
容器编排技术,用来管理容器
但是不直接管理容器,通过管理pod来间接管理容器
pod是k8s最小操作单元
pod内部封装的是容器
容器内部部署的就是应用程序
pod也是一个容器,虚拟化的机器
pod内部封装的是docker
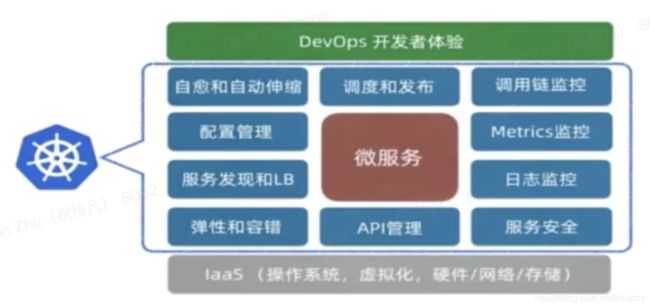
K8s解决的问题
部署
指令部署
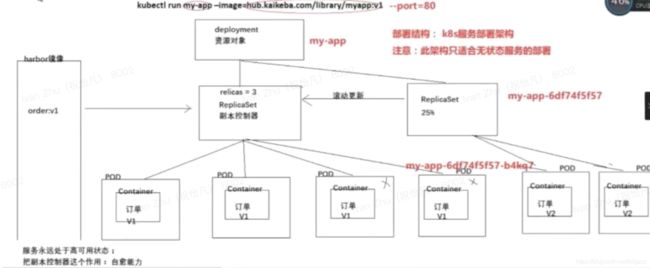
kubectl run my-app --image=hub.kaikeba.com/library/myapp:v1 -port=80
yaml文件部署
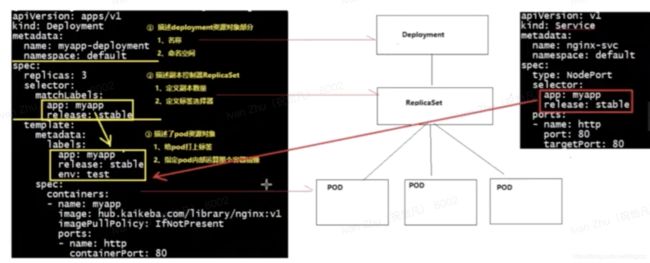
deployment.yaml
apiVersion: app/v1
kind: Depolyment
metadata:
name: myapp-deployment
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stable
template:
metadata:
labels:
app: myapp
release: stable
env: test
spec:
containers:
- name: myapp
image: hub.kaikeba.com/library/nginx:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stable
ports:
- name: http
port: 80
targetPort: 80
yaml文件解析
简单命令
#查看当前所有pod,查看pod详细信息
kubectl get pod (-o wide)
#查看当前所有svc即服务
kubectl get svc
#查看资源对象
kubectl get deployment
#查看副本
kubectl get rs
#查看描述信息
kubectl describe pod xxx
#查看命名空间
kubectl get ns
#单个容器登陆
kubectl exec -it podname -sh
#多个容器登陆
kubectl exec -it podName -c containerName -sh
#查询容器日志
kubectl logs -f podName
#根据yaml文件创建pod或svc
kubectl apply -f xxx.yaml
#根据yaml文件删除pod或svc
kubectl delete -f xxx.yaml
#将副本扩容3份
kubectl scaled deployment my-app --replicas=3
#删除pod
kubectl delete pod xxxx
#创建服务
kubectl expose deployment my-app --port=80 --target-port=80
#修改service文件
kubectl edit svc my-app
#滚动更新
kubectl set image depoloyment/my-app my-app=hub.kaikeba.com/library/myapp:v2
#帮助文档
kubectl --help
K8s架构原理及核心组件运作机制
副本控制器(ReplicaSet)
控制副本数量,保证副本数量永远和预期设定的数量一致(自愈能力)
服务永远处于高可用状态

部署对象(deployment)
资源对象,支持服务的滚动更新
部署说明
有状态服务
有实时的数据需要存储
集群服务中,拿走一个服务,一段时间后放回去,对服务集群有影响(影响数据完整性,数据一致性)
无状态服务
与有状态服务相反
负载均衡
不能使用的方式

Openresty、nginx都不具备服务发放能力,也就是PodIP地址、hostname发生了变化,但是Openresty、nginx仅是一个静态配置,无法动态发现PodIP已经发生了变化,因此这两个无法实现访问pod这个负载均衡的方案
解决方案:使用service资源对象,此对象是由k8s创建的
使用的方式
复制多个pod实现负载均衡,使用service资源对象,实现多个pod之间的请求转发
通过标签选择器来选择属于它的pod,从而知道应该把请求发给那些pod
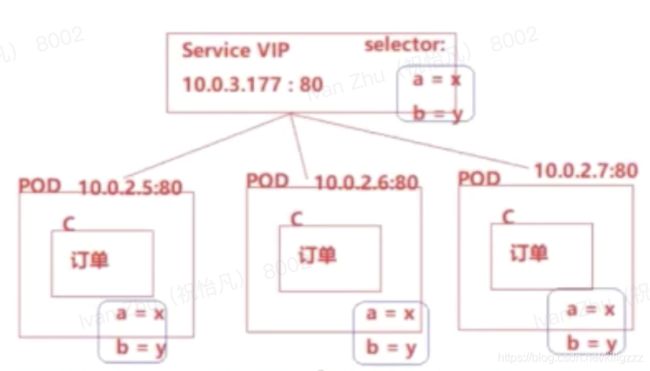
Tcp 转发,service的ip端口对应三个pod的ip端口,采用轮询策略
访问服务原理
通过dns域名解析出ip地址,实现服务的访问
pod内网访问
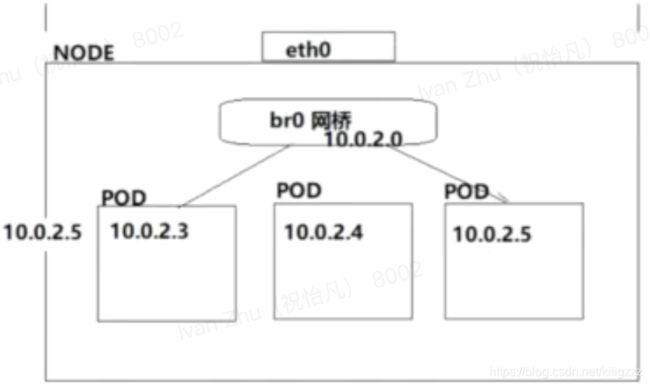
pod跨物理访问
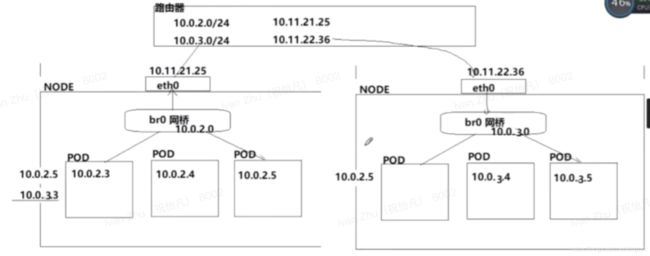
pod外网访问

开辟一个物理端口,此端口必须和service端口做一个映射,当外网请求来临时,先发给物理机,再由物理机转发给service,再由service将请求转发给内部pod服务
看见的service的ip地址是局域网ip地址,不能对外网提供访问,需要将serviceIp类型由ClusterIP修改为NodePort(会在每一个node节点都开辟一个相同的端口)
访问方式:物理机IP:物理机端口
Pod详解
Pod是什么
pod是容器(相当于一台独立的机器,独立沙箱环境)
pod内部封装的是docker容器
pod有自己的ip地址和hostname
pod相当于是一台物理机(服务器),实际上pod是一个虚拟化的容器(以进程模式运行在操作系统内部),在物理节点上,pod和pod之间相互隔离的一个沙箱环境

Pod能干什么
官方:服务上线部署的时候,pod通常被用来部署一组相关的服务,访问链路上属于上下游的访问关系,就叫一组相关的服务,但是,为了让k8s更好的管理服务,因此通常一个pod内部只部署一个服务
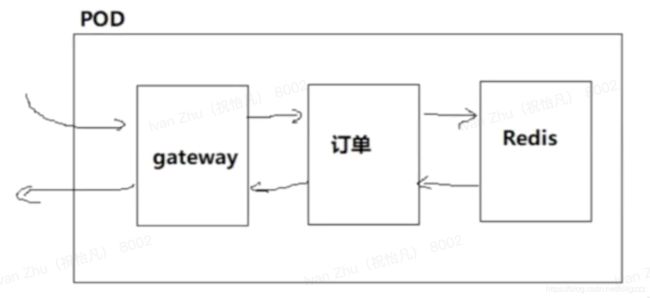
Pod核心原理
业务容器共享虚拟网络栈和数据卷

Pod数据卷
Volume数据卷是容器共享的数据卷,当容器宕机后,volume数据卷不会消失
Volume数据卷生命周期是随着pod的变化而变化的,因此pod宕机,volume数据卷就消失了
Service VIP
Service就是k8s的资源对象(service是一个运行在node节点进程),Service有自己的IP地址,有自己的端口,一旦创建IP不变
Service相当于服务网关一样,所有的请求都必须经过service拦截,然后对请求进行转发
设计Service的原因:屏蔽底层因pod异常,宕机等等发生ip、hostname变化所造成的一个影响,使得用户不需要关心底层pod到底是如何变化的,或者不需要关心PodIP地址、hostname的变化
一组业务pod对应一个service对象,一个service对象将会根据标签选择器匹配属于这个service控制的pod业务组
service不存在单点故障,service资源对象会在每个node节点都存储一份,service Vip资源高可用是由etcd来保障的
Service解析图

K8s利用endpoints controller控制器调用watch接口来发现pod服务变化,及时更新在etcd中维护的service对应的PodIP地址的关系
Service VIP产生
- 服务部署的时候人工创建的
K8s网络解析
DNS+ClusterIP
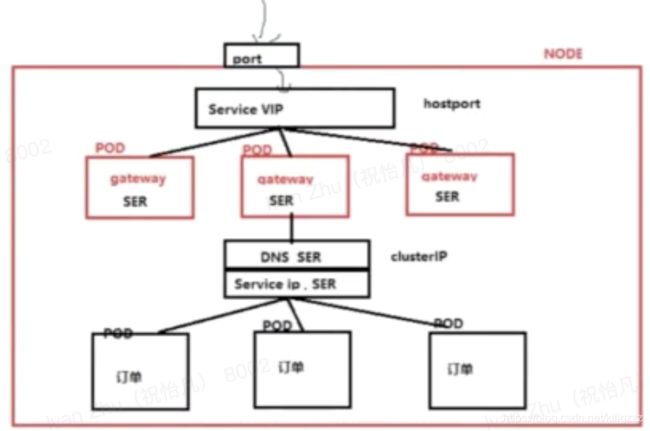
集群内网访问外部服务
直接访问

通过endpoints转发
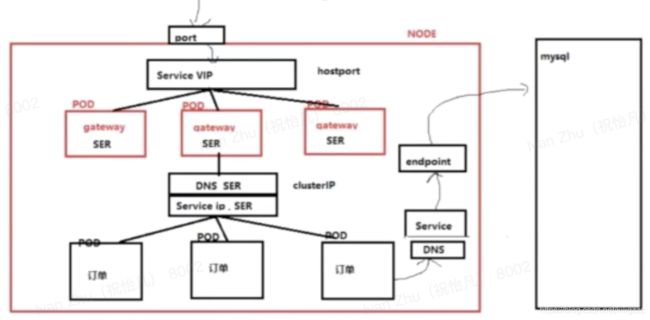
外网访问集群内网服务
nodeport
hostport
load balance
HPA
它可以根据当前pod资源的使用率(如CPU、磁盘、内存等),进行副本数的动态的扩容与缩容,以便减轻各个pod的压力。
Ingress
其实就是一组基于DNS名称(host)或URL路径把请求转发到指定的Service资源的规则。用于将集群外部的请求流量转发到集群内部完成的服务发布。我们需要明白的是,Ingress资源自身不能进行“流量穿透”,仅仅是一组规则的集合,这些集合规则还需要其他功能的辅助,比如监听某套接字,然后根据这些规则的匹配进行路由转发,这些能够为Ingress资源监听套接字并将流量转发的组件就是Ingress Controller。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-myapp
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: myapp.magedu.com
http:
paths:
- path:
backend:
serviceName: myapp
servicePort: 80
Ingress资源时基于HTTP虚拟主机或URL的转发规则,需要强调的是,这是一条转发规则。它在资源配置清单中的spec字段中嵌套了rules、backend和tls等字段进行定义。如下示例中定义了一个Ingress资源,其包含了一个转发规则:将发往myapp.magedu.com的请求,代理给一个名字为myapp的Service资源。
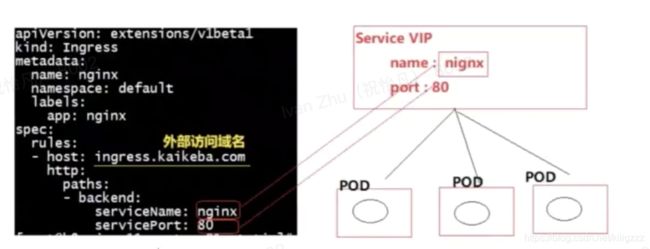
创建后端服务->创建Ingress服务
多域名服务
即配置多个- host
同一域名访问多个服务
annotations:
nginx.ingress.kubernetes.io/rewrite-target:/ #请求重写
配置两个- path
-path: /nginx
-path: /tomcat
https方式
云原生环境部署
部署秒杀系统:
- deployment
- service
- hpa(扩容)
- ingress(外网访问)
动态扩容