干货 | ICLR 2023:针对对比学习的无差别数据投毒攻击
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

何昊
麻省理工博士生,研究方向为机器学习与健康医疗

内容简介
无差别的数据投毒攻击对于监督学习非常有效。然而,人们对于其对无监督对比学习(CL)的影响知之甚少。本文首次考虑对比学习的无差别的投毒攻击。我们提出对比投毒(CP),这是对CL的第一个有效的此类攻击。我们的经验表明,对比投毒不仅极大地降低了CL算法的性能,而且还攻击监督学习模型,使其成为最普遍的无差别的投毒攻击。我们还证明了带有动量编码器的CL算法对于无差别的投毒具有更强的鲁棒性,并提出了一种基于矩阵补全的新对策。
代码链接:
https://github.com/kaiwenzha/contrastive-poisoning
论文链接:
https://arxiv.org/abs/2202.11202
网页链接:
https://contrastive-poisoning.csail.mit.edu
Background
机器学习的快速发展使得其在众多领域都有着惊人的表现。在学术界和产业界的共同推动下,机器学习已经被应用到社会生活中的方方面面,应用的门槛也逐渐降低,任何有一定编程基础及计算资源的用户都有能力自己独立训练非常强大的问题。尽管它给我们的生活带来了便利,也会在一定程度上引起数据隐私的问题,这就需要有一种方法去保护我们的数据,使得他们不被非法使用。
Data Poisoning:Why and What
Data Poisoning名为“投毒”,但实际上是为了保护私有数据。“投毒者”实际上是数据的拥有者,他希望对数据进行一些操作,使得这些数据既可以被正常使用,又不会被机器学习模型所训练学习。假如有人收集到被“下毒”的数据训练模型,那么最终模型的训练效果也是非常差的。

数据投毒可以被细分成两类“Targeted”和“Indiscriminate”。“Targeted”是有目标的,比如人脸识别模型可以识别特定目标的人群。“Indiscriminate”是无差别的,比如人脸识别模型完全不起作用,对任意人群都无法识别。在该篇工作中,我们主要聚焦于无差别的数据投毒。

Prior Works
State of the art
经过过去几年的发展,数据投毒技术已经有了很大的提升。以CIFAR-10上的图片分类任务为例,从2019年的tensorClog到2021年的unlearnable example以及adversarial poisoning 被攻击的准确率下降了非常多。

Limitations
但是之前的工作中都忽略了一个重要问题,他们只考虑了第三方使用监督学习的情况,而现在有各种各样的机器学习算法可供第三方使用,这会导致之前的数据投毒的方法很容易被破解。
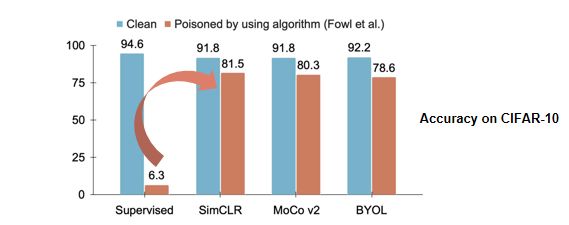
下图以一个例子简单说明。假设使用对比学习做一个无监督的representation learning表示学习,基于学到的表示再用标注去学习一个线性分类器,这样的思路可以很容易破解掉之前的数据投毒算法。

我们的实验结果显示,可以使用任何的对比学习框架,比如SimCLR、MoCo、BYOL,能够将在有毒数据上学到的准确率从6%提升到80%,使得前期的“投毒”基本失效。所以在该篇工作中,我们想要探索设计一个针对对比学习也能够有效的数据投毒算法。
Our Work
Motivation
为了实现让对比学习模型也能中毒的目标,我们的思路是扰动数据使其成为对比学习的“捷径”。具体来讲,即我们尝试往数据中加入一些肉眼难以察觉的图案,使得模型可以通过他们完成对比学习的任务,同时又无需真正从数据中学习到任何语义信息。而对比学习的任务具体说来就是对于同一张图片,模型需要将它的不同的views映射到同一个Embedding中,然后将不同的图片映射到不同的表示。综上,我们的研究动机是希望在训练有毒的数据之后,模型能够根据扰动过后的纹理将图片对其到嵌入空间中,而不会关注图片真正的语义信息。这样,即使模型的输入是一张干净的图片,模型也无法正确地将其投射到嵌入空间中。

Method
为了实现上述想法,我们提出了一个新的数据投毒算法——对比投毒(Contrastive Posioning)。我们的研究目标是训练一种数据扰动,它需要满足以下两个条件:第一,模长不能太大,即扰动不能太明显;第二,它需要帮助神经网络模型快速减少对比学习的损失函数。所以我们最终要做的是同时训练“扰动”和神经网络模型来共同减少对比学习的损失函数。

Contrastive Poisoning
在这其中,有两个重点的技术细节。
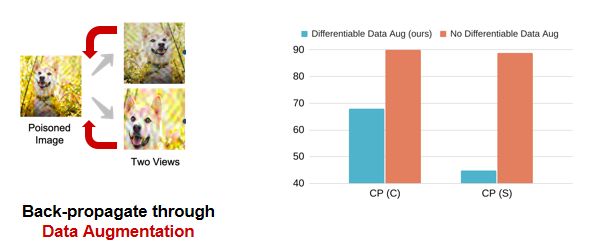
第一,数据增强。之前的工作中只考虑监督学习而忽略了数据增强,但是对比学习却在很大程度上依赖于数据增强。所以我们的具体做法是对所有数据增强的算子求导,然后更新数据扰动。
如下的柱状图是在CIFAR-10数据集上的实验结果,蓝色柱状是对数据增强求导的结果,红色柱状是忽略该步骤得到的结果。由图可以看出,如果忽略数据增强这一步骤,会导致攻击完全失效,模型的准确率接近90%。
第二,设计一个动量编码器。动量编码器可以看作一个动态变化的、更慢的、稳定版的编码器,而经前人发现,在对比学习的过程中引入动量编码器可以使得训练过程更加稳定,收敛效果更好。而在通常的对比学习训练过程中,动量编码器是不需要求导的。但是我们发现,如果需要学习一个好的数据扰动攻击对比学习框架,就需要对动量编码器求导。如下图所示,我们在CIFAR-10数据集上的实验结果显示,如果没有对动量编码器进行求导,那么学习到的数据扰动攻击效能就会显著下降6到20个百分点。

Experiments
Same Contrastive Learning Algorithm
我们研究了两种不同类型的数据扰动。第一种是Sample-wise Poisoning,每一个数据都有自己的扰动。它的优点是扰动更强,攻击效果更强,缺点是训练成本高。第二种是Class-wise Poisoning,针对同一个类别的数据使用同一种扰动。它的优点是扰动成本低,鲁棒性更强,缺点是攻击效果相对较弱。
我们分别在三个不同的对比学习框架SimCLR、MoCo v2、BYOL与三个不同的数据集CIFAR-10、CIFAR-100、ImageNet-100上进行实验,结果显示Sample-wise与Class-wise的攻击效果都是很显著的。
此外,我们还发现MoCo v2与BYOL相对于SimCLR来讲更难被攻击。我们猜测这与动量编码器的设计有关。因为对于SimCLR,数据扰动只需要对编码器有效,但是对于MoCo v2与BYOL而言,数据扰动需要同时对编码器、动量编码器都有效,这就增加了攻击的难度。

Cross Contrastive Learning Algorithms
在第二个实验中,我们探索了对比投毒攻击的迁移性。如下图所示最后一行蓝色标注的结果,在BYOL上学习过的扰动数据,再用SimCLR、MoCo v2、BYOL中的任何一种算法学习,使用我们的算法攻击可以将准确率下降到60%左右,这充分说明我们的算法具有很强的迁移性能。

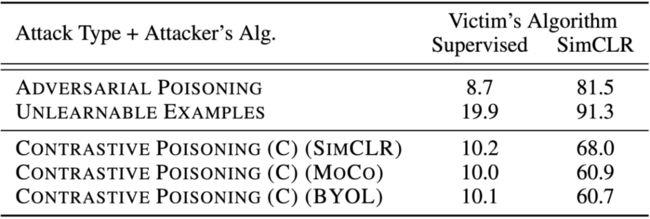
此外,我们的算法不仅可以攻击对比学习,同时也能攻击监督学习。如下方的表格所示,当恶意用户使用监督学习的时候,Class-wise数据扰动依然可以将CIFAR-10的准确率下降到10%。这表明我们的算法可以很强地投毒无标注的数据,这些数据即使花费大量人力进行标注,也无法学习到很好的模型。
Different Poisoning Ratio
下图展示攻击效能与投毒比例的关系,可以看到,随着投毒比例的下降,准确率有所上升。由红线可以观察到,Class-wise扰动在投毒比例下降的过程中,还是保持一定的攻击效能,准确率缓慢上升。而黄线是删除中毒数据,仅使用部分干净数据训练的结果。红线比黄线低,即表示部分投毒的作用等价于从数据集中删除了被投毒的数据。

从投毒比例的角度来看,我们的算法是更加鲁棒的。由下图的绿线可以看到,将投毒比例从100减少到90,攻击基本就没有显著的效果了,准确率从6%上升到85%。

Summary
在我们的工作中,我们提出了新的问题:如何针对对比学习做数据投毒。其次,我们提出一种新的数据投毒算法——Contrastive Poisoning,它可以非常有效地攻击对比学习以及监督学习,并且鲁棒性非常好,能够适用于各种不同的对比学习算法、数据集以及投毒比例。
整理:陈研
审核:何昊
提醒
点击“阅读原文”跳转至00:02:25
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 观看回放!