【Spring专题】Spring之底层架构核心概念解析
目录
- 前言
- 前置知识
- 课程内容
-
- 一、BeanDefinition:图纸
- 二、BeanDefinitionReader:图纸读取器——Spring工厂基础设施之一
-
- 2.1 AnnotatedBeanDefinitionReader
- 2.2 XmlBeanDefinitionReader
- 2.3 ClassPathBeanDefinitionScanner
- 三、BeanFactory:生产流水线——Spring基础设施之一
- *四、ApplicationContext:生产车间——Spring基础设施之一
-
- 4.1 AnnotationConfigApplicationContext
- 4.2 ClassPathXmlApplicationContext
- 五、国际化
- 六、资源加载
- 七、获取运行时环境
- 八、事件发布
- 九、类型转化
-
- 9.1 PropertyEditor
- 9.2 ConversionService
- 9.3 TypeConverter
- 十、OrderComparator
- *特别声明
- *十一、BeanPostProcessor:Spring重要的拓展点
-
- 基本介绍
- 应用场景
- 简单使用示例
- *十二、BeanFactoryPostProcessor:Spring重要的拓展点
-
- 基本介绍
- 应用场景
- 简单使用示例
- 十三、FactoryBean
- 十四、ExcludeFilter和IncludeFilter
- 十五、MetadataReader、ClassMetadata、AnnotationMetadata
- 学习总结
前言
本节课的内容,是后续看Spring源码所必备的概念、类精讲,防止后续看源码的过程中,遇到不会的、看不懂的还得单独跳出来学习。所以,大家好好理解一下这些概念,可以大大地帮助后学源码阅读。
另外还有一点需要特别声明:
接口的作用,有时候是用来约束、规范行为的。像Spring这种优秀的源码,更是会按照接口说明执行。所以,通过看接口注释,可以帮我们理解某个类的能力!
切记!
切记!
切记!
切记!
切记!
切记!
前置知识
可以先看看前面这两篇文章,个人认为是Spring源码学习启蒙
一、《【Spring专题】Spring底层核心原理解析》
二、《【Spring专题】手写简易Spring容器过程分析》
课程内容
一、BeanDefinition:图纸
BeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特征。比如:
- class,表示Bean类型
- scope,表示Bean作用域,单例或原型等
- lazyInit:表示Bean是否是懒加载
- initMethodName:表示Bean初始化时要执行的方法
- destroyMethodName:表示Bean销毁时要执行的方法
- 还有很多…
在Spring中,我们经常会通过以下几种方式来定义Bean:
- xml中的
标签 - 注解式@Bean
- @Component系列注解(@Service,@Controller)
以上这些,我们称之为:【申明式定义Bean】
我们还可以【编程式定义Bean】,那就是直接通过BeanDefinition,比如:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
// 生成一个BeanDefinition对象,并设置beanClass为User.class,并注册到ApplicationContext中
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition();
beanDefinition.setBeanClass(User.class);
context.registerBeanDefinition("user", beanDefinition);
System.out.println(context.getBean("user"));
我们还可以通过BeanDefinition设置一个Bean的其他属性:
beanDefinition.setScope("prototype"); // 设置作用域
beanDefinition.setInitMethodName("init"); // 设置初始化方法
beanDefinition.setLazyInit(true); // 设置懒加载
总之不管通过何种方式定义的Bean,最终都会被Spring解析为对应的BeanDefinition对象,并放入Spring容器中。
为了方便大家理解这个玩意的存在,我举个通俗的例子,如下:
BeanDefinition的存在更像是一份家具定制的图纸,Bean是具体的某个家具。而Spring里面,在后面我们会学到的ApplicationContext,则是生产家具的厂家。这样类比的话,你应该能想明白,为什么需要BeanDefinition了吧。
总结一句话:ApplicationContext厂家根据BeanDefinition图纸生成具体的某个家具Bean(PS:ApplicationContext 包含 BeanFactory,它们都是Bean工厂)
二、BeanDefinitionReader:图纸读取器——Spring工厂基础设施之一
BeanDefinitionReader,直译过来:BeanDefinition读取器。这些BeanDefinitionReader在我们使用Spring时用得少,但在Spring源码中用得多,相当于Spring源码的基础设施。它是一个接口,提供了多种实现类。

就像我们说的,BeanDefinitionReader是一个图纸读取器,但因为画图纸的工具多种多样,所以,读取器也多种多样,下面给大家简单介绍一下。
(PS:优秀源码当是如此,看名字就知道作用,赏心悦目)
2.1 AnnotatedBeanDefinitionReader
可以直接把某个类转换为BeanDefinition,并且会解析该类上的注解,比如:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
AnnotatedBeanDefinitionReader annotatedBeanDefinitionReader = new AnnotatedBeanDefinitionReader(context);
// 将User.class解析为BeanDefinition
annotatedBeanDefinitionReader.register(User.class);
System.out.println(context.getBean("user"));
注意:它能解析的注解是:@Conditional,@Scope、@Lazy、@Primary、@DependsOn、@Role、@Description
2.2 XmlBeanDefinitionReader
可以解析
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
XmlBeanDefinitionReader xmlBeanDefinitionReader = new XmlBeanDefinitionReader(context);
int i = xmlBeanDefinitionReader.loadBeanDefinitions("spring.xml");
System.out.println(context.getBean("user"));
2.3 ClassPathBeanDefinitionScanner
ClassPathBeanDefinitionScanner是扫描器,但是它的作用和BeanDefinitionReader类似,它可以进行扫描,扫描某个包路径,对扫描到的类进行解析。比如,扫描到的类上如果存在@Component注解,那么就会把这个类解析为一个BeanDefinition,比如:
(这里是一个容易混淆的点,我第一次学习的时候也觉得奇怪,为什么名字不同,但是作用却相似?按照Spring的规范,似乎不应该呀,但事实确实如此。这东西跟Reader结尾的类不同,Reader通常是由Spring内部自己调用的,而ClassPathBeanDefinitionScanner不同,它是提供给【用户】显式调用scanner.scan()的。如下所示)
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.refresh();
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(context);
scanner.scan("com.zhouyu");
System.out.println(context.getBean("userService"));
三、BeanFactory:生产流水线——Spring基础设施之一
BeanFactory表示Bean工厂,所以很明显,BeanFactory会负责创建Bean,并且提供获取Bean的API。而ApplicationContext是BeanFactory的一种,后面会有介绍。
在Spring源码中,BeanFactory接口存在一个非常重要的实现类是:DefaultListableBeanFactory,也是非常核心的。具体重要性,随着后续课程会感受更深。
所以,我们可以直接来使用DefaultListableBeanFactory,而不用使用ApplicationContext的某个实现类,比如:
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
// 注册一个Bean定义
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition();
beanDefinition.setBeanClass(User.class);
beanFactory.registerBeanDefinition("user", beanDefinition);
// 生产
System.out.println(beanFactory.getBean("user"));
DefaultListableBeanFactory是非常强大的,支持很多功能,可以通过查看DefaultListableBeanFactory的类继承实现结构来看:

这部分现在看不懂没关系,源码熟悉一点后回来再来看都可以。它实现了很多接口,表示,它拥有很多功能:
- AliasRegistry:支持别名功能,一个名字可以对应多个别名
- BeanDefinitionRegistry:可以注册、保存、移除、获取某个BeanDefinition
- BeanFactory:Bean工厂,可以根据某个bean的名字、或类型、或别名获取某个Bean对象
- SingletonBeanRegistry:可以直接注册、获取某个单例Bean
- SimpleAliasRegistry:它是一个类,实现了AliasRegistry接口中所定义的功能,支持别名功能
- ListableBeanFactory:在BeanFactory的基础上,增加了其他功能,可以获取所有BeanDefinition的beanNames,可以根据某个类型获取对应的beanNames,可以根据某个类型获取{类型:对应的Bean}的映射关系
- HierarchicalBeanFactory:在BeanFactory的基础上,添加了获取父BeanFactory的功能
- DefaultSingletonBeanRegistry:它是一个类,实现了SingletonBeanRegistry接口,拥有了直接注册、获取某个单例Bean的功能
- ConfigurableBeanFactory:在HierarchicalBeanFactory和SingletonBeanRegistry的基础上,添加了设置父BeanFactory、类加载器(表示可以指定某个类加载器进行类的加载)、设置Spring EL表达式解析器(表示该BeanFactory可以解析EL表达式)、设置类型转化服务(表示该BeanFactory可以进行类型转化)、可以添加BeanPostProcessor(表示该BeanFactory支持Bean的后置处理器),可以合并BeanDefinition,可以销毁某个Bean等等功能
- FactoryBeanRegistrySupport:支持了FactoryBean的功能
- AutowireCapableBeanFactory:是直接继承了BeanFactory,在BeanFactory的基础上,支持在创建Bean的过程中能对Bean进行自动装配
- AbstractBeanFactory:实现了ConfigurableBeanFactory接口,继承了FactoryBeanRegistrySupport,这个BeanFactory的功能已经很全面了,但是不能自动装配和获取beanNames
- ConfigurableListableBeanFactory:继承了ListableBeanFactory、AutowireCapableBeanFactory、ConfigurableBeanFactory
- AbstractAutowireCapableBeanFactory:继承了AbstractBeanFactory,实现了AutowireCapableBeanFactory,拥有了自动装配的功能
- DefaultListableBeanFactory:继承了AbstractAutowireCapableBeanFactory,实现了ConfigurableListableBeanFactory接口和BeanDefinitionRegistry接口,所以DefaultListableBeanFactory的功能很强大
*四、ApplicationContext:生产车间——Spring基础设施之一
ApplicationContext是个接口,实际上也是一个BeanFactory,不过比BeanFactory更加强大。
在Spring的源码实现中,当我们new一个ApplicationContext时,其底层会new一个BeanFactory出来,当使用ApplicationContext的某些方法时,比如getBean(),底层调用的是BeanFactory的getBean()方法。它的定义如下:
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory,
MessageSource, ApplicationEventPublisher, ResourcePatternResolver {
...
}
PS:通过上面这点,大家应该能大概知道ApplicationContext跟BeanFactory的区别了吧?这个可是Spring面试考点之一哦。
显然,ApplicationContext具有BeanFactory的能力,并且具有更丰富的功能。具体如下:
- HierarchicalBeanFactory:拥有获取父BeanFactory的功能
- ListableBeanFactory:拥有获取beanNames的功能
- ResourcePatternResolver:资源加载器,可以一次性获取多个资源(文件资源等等)
- EnvironmentCapable:可以获取运行时环境(没有设置运行时环境功能)
- ApplicationEventPublisher:拥有广播事件的功能(没有添加事件监听器的功能)
- MessageSource:拥有国际化功能
具体的功能演示,后面会有。
我们先来看ApplicationContext两个比较重要的实现类:
- AnnotationConfigApplicationContext
- ClassPathXmlApplicationContext
4.1 AnnotationConfigApplicationContext

如上图,AnnotationConfigApplicationContext继承了上述这些类,所以他理所应当地具有了上述类的能力。分别如下:
- ConfigurableApplicationContext:继承了ApplicationContext接口,增加了,添加事件监听器、添加BeanFactoryPostProcessor、设置Environment,获取ConfigurableListableBeanFactory等功能
- AbstractApplicationContext:实现了ConfigurableApplicationContext接口
- GenericApplicationContext:继承了AbstractApplicationContext,实现了BeanDefinitionRegistry接口,拥有了所有ApplicationContext的功能,并且可以注册BeanDefinition,注意这个类中有一个属性(DefaultListableBeanFactory beanFactory)
- AnnotationConfigRegistry:可以单独注册某个为类为BeanDefinition(可以处理该类上的**@Configuration注解**,已经可以处理**@Bean注解**),同时可以扫描
- AnnotationConfigApplicationContext:继承了GenericApplicationContext,实现了AnnotationConfigRegistry接口,拥有了以上所有的功能
4.2 ClassPathXmlApplicationContext
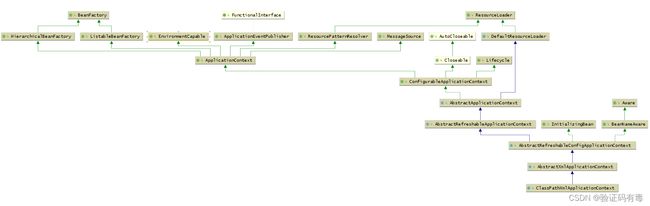
它也是继承了AbstractApplicationContext,但是相对于AnnotationConfigApplicationContext而言,功能没有AnnotationConfigApplicationContext强大,比如不能注册BeanDefinition
五、国际化
先定义一个MessageSource:
@Bean
public MessageSource messageSource() {
ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource();
messageSource.setBasename("messages");
return messageSource;
}
有了这个Bean,你可以在你任意想要进行国际化的地方使用该MessageSource。
同时,因为ApplicationContext也拥有国家化的功能,所以可以直接这么用:
context.getMessage("test", null, new Locale("en_CN"))
六、资源加载
ApplicationContext还拥有资源加载的功能,比如,可以直接利用ApplicationContext获取某个文件的内容:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Resource resource = context.getResource("file://D:\\IdeaProjects\\spring-framework\\luban\\src\\main\\java\\com\\luban\\entity\\User.java");
System.out.println(resource.contentLength());
你可以想想,如果你不使用ApplicationContext,而是自己来实现这个功能,就比较费时间了。
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Resource resource = context.getResource("file://D:\\IdeaProjects\\spring-framework-5.3.10\\tuling\\src\\main\\java\\com\\zhouyu\\service\\UserService.java");
System.out.println(resource.contentLength());
System.out.println(resource.getFilename());
Resource resource1 = context.getResource("https://www.baidu.com");
System.out.println(resource1.contentLength());
System.out.println(resource1.getURL());
Resource resource2 = context.getResource("classpath:spring.xml");
System.out.println(resource2.contentLength());
System.out.println(resource2.getURL());
还可以一次性获取多个:
Resource[] resources = context.getResources("classpath:com/zhouyu/*.class");
for (Resource resource : resources) {
System.out.println(resource.contentLength());
System.out.println(resource.getFilename());
}
七、获取运行时环境
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Map<String, Object> systemEnvironment = context.getEnvironment().getSystemEnvironment();
System.out.println(systemEnvironment);
System.out.println("=======");
Map<String, Object> systemProperties = context.getEnvironment().getSystemProperties();
System.out.println(systemProperties);
System.out.println("=======");
MutablePropertySources propertySources = context.getEnvironment().getPropertySources();
System.out.println(propertySources);
System.out.println("=======");
System.out.println(context.getEnvironment().getProperty("NO_PROXY"));
System.out.println(context.getEnvironment().getProperty("sun.jnu.encoding"));
System.out.println(context.getEnvironment().getProperty("zhouyu"));
注意,可以利用@PropertySource("classpath:spring.properties")来使得某个properties文件中的参数添加到运行时环境中
八、事件发布
Spring内部自己实现一个事件发布器。用于在Spring异步启动的时候,监听某个事件,然后作出响应。比如一个经典的例子就是,Spring启动成功之后会发布一个ContextRefreshedEvent事件。然后,我们可以在自己的业务代码里面实现implements ApplicationListener,然后就可以通过实现onApplicationEvent()方法完成自定义的业务了。
使用示例:
先定义一个事件监听器:
@Bean
public ApplicationListener applicationListener() {
return new ApplicationListener() {
@Override
public void onApplicationEvent(ApplicationEvent event) {
System.out.println("接收到了一个事件");
}
};
}
然后发布事件:
public class MyApplicationTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
context.publishEvent("kkk");
}
}

第一个红框就是我们提到的,Spring启动之后内部自己发布的事件;第二个则是我们自己手动调用的,被包装成了PayloadApplicationEvent。
九、类型转化
在Spring源码中,有可能需要把String转成其他类型,所以在Spring源码中提供了一些技术来更方便的做对象的类型转化,关于类型转化的应用场景,后续看源码的过程中会遇到很多。
9.1 PropertyEditor
这其实是JDK中提供的类型转化工具类。
自定义的类型转换器:
public class StringToUserPropertyEditor extends PropertyEditorSupport implements PropertyEditor {
@Override
public void setAsText(String text) throws IllegalArgumentException {
User user = new User();
user.setName(text);
this.setValue(user);
}
}
向Spring中注册PropertyEditor:
@Bean
public CustomEditorConfigurer customEditorConfigurer() {
CustomEditorConfigurer customEditorConfigurer = new CustomEditorConfigurer();
Map<Class<?>, Class<? extends PropertyEditor>> propertyEditorMap = new HashMap<>();
// 表示StringToUserPropertyEditor可以将String转化成User类型,在Spring源码中,如果发现当前对象是String,而需要的类型是User,就会使用该PropertyEditor来做类型转化
propertyEditorMap.put(User.class, StringToUserPropertyEditor.class);
customEditorConfigurer.setCustomEditors(propertyEditorMap);
return customEditorConfigurer;
}
测试Bean:
@Component
public class UserService {
@Value("深哥")
private User user;
public void test() {
System.out.println(user);
}
}
调用:
public class MyApplicationTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Object userService = context.getBean("userService");
System.out.println(userService);
}
}
最后debug如下:

9.2 ConversionService
直译:转换装置、转换服务。Spring中提供的类型转化服务,它比PropertyEditor更强大
自定义的类型转换器:
public class StringToUserConverter implements ConditionalGenericConverter {
@Override
public boolean matches(TypeDescriptor sourceType, TypeDescriptor targetType) {
return sourceType.getType().equals(String.class) && targetType.getType().equals(User.class);
}
@Override
public Set<ConvertiblePair> getConvertibleTypes() {
return Collections.singleton(new ConvertiblePair(String.class, User.class));
}
@Override
public Object convert(Object source, TypeDescriptor sourceType, TypeDescriptor targetType) {
User user = new User();
user.setName((String)source);
return user;
}
}
向Spring中注册ConversionService:
@Bean
public ConversionServiceFactoryBean conversionService() {
ConversionServiceFactoryBean conversionServiceFactoryBean = new ConversionServiceFactoryBean();
conversionServiceFactoryBean.setConverters(Collections.singleton(new StringToUserConverter()));
return conversionServiceFactoryBean;
}
测试Bean:
@Component
public class UserService {
@Value("深哥")
private User user;
public void test() {
System.out.println(user);
}
}
调用:
public class MyApplicationTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
Object userService = context.getBean("userService");
System.out.println(userService);
}
}
最后debug如下:
9.3 TypeConverter
TypeConverter整合了PropertyEditor和ConversionService的功能,是Spring内部用的:
SimpleTypeConverter typeConverter = new SimpleTypeConverter();
typeConverter.registerCustomEditor(User.class, new StringToUserPropertyEditor());
//typeConverter.setConversionService(conversionService);
User value = typeConverter.convertIfNecessary("1", User.class);
System.out.println(value);
十、OrderComparator
OrderComparator是Spring所提供的一种比较器,可以用来根据@Order注解或实现Ordered接口来执行值进行笔记,从而可以进行排序。比如:
public class A implements Ordered {
@Override
public int getOrder() {
return 3;
}
@Override
public String toString() {
return this.getClass().getSimpleName();
}
}
public class B implements Ordered {
@Override
public int getOrder() {
return 2;
}
@Override
public String toString() {
return this.getClass().getSimpleName();
}
}
public class Main {
public static void main(String[] args) {
A a = new A(); // order=3
B b = new B(); // order=2
OrderComparator comparator = new OrderComparator();
System.out.println(comparator.compare(a, b)); // 1
List list = new ArrayList<>();
list.add(a);
list.add(b);
// 按order值升序排序
list.sort(comparator);
System.out.println(list); // B,A
}
}
另外,Spring中还提供了一个OrderComparator的子类:AnnotationAwareOrderComparator,它支持用@Order来指定order值。比如:
@Order(3)
public class A {
@Override
public String toString() {
return this.getClass().getSimpleName();
}
}
@Order(2)
public class B {
@Override
public String toString() {
return this.getClass().getSimpleName();
}
}
public class Main {
public static void main(String[] args) {
A a = new A(); // order=3
B b = new B(); // order=2
AnnotationAwareOrderComparator comparator = new AnnotationAwareOrderComparator();
System.out.println(comparator.compare(a, b)); // 1
List list = new ArrayList<>();
list.add(a);
list.add(b);
// 按order值升序排序
list.sort(comparator);
System.out.println(list); // B,A
}
}
*特别声明
接口的作用,有时候是用来约束、规范行为的。像Spring这种优秀的源码,更是会按照接口说明执行。所以,通过看接口注释,可以帮我们理解某个类的能力!
切记!
切记!
切记!
切记!
切记!
切记!
另外,下面将要介绍的BeanPostProcessor跟BeanFactoryPostProcessor,由于个人在第一次阅读的时候,发现理解它们会比较困难,所以想提前给大家分享一下我遇到的理解难点,毕竟大家应该【菜的都一个样】。
- 他们在Spring作者注释中,被译为:Hook,钩子。钩子、钩子函数在我们的程序设计中,语义是:当条件成立时,增加或者改变系统原有的行为!。所以,我们基本可以知道,这两个后置处理器就是Spring提供给我们,在某个时机改变某个对象、甚至系统的行为、特征等;
BeanPostProcessor作用的对象是Bean,BeanFactoryPostProcessor作用的对象是BeanFactory
*十一、BeanPostProcessor:Spring重要的拓展点
基本介绍
BeanPostProcessor,直译为:Bean的后置处理器(PS:说实在这个命名第一次接触会比较抽象。只能解释为,从new Bean()开始,Bean就存在了,只不过不完整而已)。我们来看看接口定义方法:
/**
* 工厂钩子。
* 允许自定义修改新bean实例的工厂钩子——例如,检查标记接口或用代理包装bean。
* 通常,通过标记接口或类似的方式填充bean的后处理器将实现postProcessBeforeInitialization,而用代理包装bean的后处理器通常将实现postProcessAfterInitialization。
* 登记
* ApplicationContext可以在其bean定义中自动检测BeanPostProcessor bean,并将这些后处理程序应用于随后创建的任何bean。普通的BeanFactory允许对后处理器进行编程注册,将它们应用于通过bean工厂创建的所有bean。
* 订购
* 在ApplicationContext中自动检测到的BeanPostProcessor bean将根据org.springframework.core. priorityorordered和org.springframework.core.Ordered语义进行排序。相反,通过BeanFactory以编程方式注册的BeanPostProcessor bean将按照注册的顺序应用;通过实现priityordered或Ordered接口表达的任何排序语义将被编程注册的后处理器忽略。此外,@Order注释没有考虑到BeanPostProcessor bean。
* 自:
* 10.10.2003
* 参见:
* InstantiationAwareBeanPostProcessor, DestructionAwareBeanPostProcessor, ConfigurableBeanFactory。addBeanPostProcessor, BeanFactoryPostProcessor
* 作者:
* 于尔根·霍勒,山姆·布兰南
*/
public interface BeanPostProcessor {
/**
* 在任何bean初始化回调(如InitializingBean的afterPropertiesSet或自定义初始化方法)之前,将此BeanPostProcessor应用于给定的新bean实例。这个bean已经被属性值填充了。返回的bean实例可能是原始bean实例的包装器。
* 默认实现按原样返回给定的bean。
* 参数:
* Bean——新的Bean实例
* beanName—bean的名称
* 返回:
* 要使用的bean实例,无论是原始的还是包装的;如果为空,则不会调用后续的BeanPostProcessors
* 抛出:
* BeansException -在错误的情况下
*/
default Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean;
}
/**
* 在任何bean初始化回调(如InitializingBean的afterPropertiesSet或自定义init-method)之后,将此BeanPostProcessor应用于给定的新bean实例。这个bean已经被属性值填充了。返回的bean实例可能是原始bean实例的包装器。
* 对于FactoryBean,将为FactoryBean实例和由FactoryBean创建的对象调用这个回调(从Spring 2.0开始)。后处理器可以通过相应的FactoryBean instanceof检查来决定是应用于FactoryBean还是已创建的对象,或者两者都应用。
* 这个回调也将在由InstantiationAwareBeanPostProcessor触发的短路之后被调用。postProcessBeforeInstantiation方法,与所有其他BeanPostProcessor回调相反。
* 默认实现按原样返回给定的bean。
* 参数:
* Bean——新的Bean实例
* beanName—bean的名称
* 返回:
* 要使用的bean实例,无论是原始的还是包装的;如果为空,则不会调用后续的BeanPostProcessors
* 抛出:
* BeansException -在错误的情况下
* 参见:
* org.springframework.beans.factory.InitializingBean。afterPropertiesSet, org.springframework.beans.factory.FactoryBean
* 以上翻译结果来自有道神经网络翻译(YNMT)· 通用场景
*/
default Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}
总结一下:BeanPostProcessor是一个接口,提供了两个方法(拓展时机),分别作用于【初始化前】【初始化后】
应用场景
通过阅读注释,基本可以确定【AOP】过程的【代理创建】的实现就是基于这个拓展点(我小小的翻了一下源码,基本确认是)
简单使用示例
下面,我们定义一个BeanPostProcessor示例耍耍看:
@Component
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("userService")) {
System.out.println("userService初始化前");
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("userService")) {
System.out.println("userService初始化后");
}
return bean;
}
}
通过上述手段,我们可以通过定义BeanPostProcessor来干涉Spring创建Bean的过程。
*十二、BeanFactoryPostProcessor:Spring重要的拓展点
基本介绍
BeanFactoryPostProcessor,直译:Bean工厂的后置处理器,其实和BeanPostProcessor类似。只不过BeanPostProcessor是干涉Bean的创建过程,而BeanFactoryPostProcessor是干涉BeanFactory的创建过程。看一下接口定义:
/**
* 工厂钩子。
* 允许自定义修改应用程序上下文的bean定义,调整上下文的底层bean工厂的bean属性值。
* 对于针对系统管理员的自定义配置文件非常有用,这些配置文件覆盖在应用程序上下文中配置的bean属性。有关解决此类配置需求的开箱即用解决方案,请参阅propertyresourcecconfigururer及其具体实现。
* BeanFactoryPostProcessor可以与bean定义交互和修改,但不能与bean实例交互。这样做可能会导致过早的bean实例化,违反容器并导致意想不到的副作用。如果需要bean实例交互,请考虑实现BeanPostProcessor。
* 登记
* ApplicationContext在其bean定义中自动检测BeanFactoryPostProcessor bean,并在创建任何其他bean之前应用它们。BeanFactoryPostProcessor也可以通过编程方式注册到ConfigurableApplicationContext中。
* 订购
* 在ApplicationContext中自动检测到的BeanFactoryPostProcessor bean将根据org.springframework.core. priorityorordered和org.springframework.core.Ordered语义进行排序。与此相反,BeanFactoryPostProcessor bean是通过ConfigurableApplicationContext以编程方式注册的,它将按照注册的顺序应用;通过实现priityordered或Ordered接口表达的任何排序语义将被编程注册的后处理器忽略。此外,@Order注释不会被BeanFactoryPostProcessor bean考虑在内。
* 自:
* 06.07.2003
* 参见:
* BeanPostProcessor, PropertyResourceConfigurer
* 作者:
* 于尔根·霍勒,山姆·布兰南
*/
@FunctionalInterface
public interface BeanFactoryPostProcessor {
/**
* 在标准初始化之后修改应用程序上下文的内部bean工厂。所有的bean定义都已加载,但还没有实例化任何bean。这允许覆盖或添加属性,甚至是对急于初始化的bean。
* 参数:
* beanFactory——应用程序上下文使用的bean工厂
* 抛出:
* BeansException -在错误的情况下
*/
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}
总结一下:BeanFactoryPostProcessor 是一个接口,提供了一个方法(拓展时机),允许我们:在所有bean实例化之前进行应用,提供给开发者修改bean定义,以达到bean实例的生成按照自己的方式来生成的目的。
应用场景
看类注释以及实现类,@Configuration注解就是使用了这个拓展时机,也许@Bean的支持,也在这里
另外,似乎【AOP】过程中的【织入】是在这个拓展点实现的
简单使用示例
比如,我们可以这样定义一个BeanFactoryPostProcessor:
@Component
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("加工beanFactory");
}
}
我们可以在postProcessBeanFactory()方法中对BeanFactory进行加工。
十三、FactoryBean
上面提到,我们可以通过BeanPostPorcessor来干涉Spring创建Bean的过程,但是如果我们想一个Bean完完全全由我们来创造,也是可以的,比如通过FactoryBean:
@Component
public class ZhouyuFactoryBean implements FactoryBean {
@Override
public Object getObject() throws Exception {
UserService userService = new UserService();
// 属性赋值
return userService;
}
@Override
public Class<?> getObjectType() {
return UserService.class;
}
}
通过上面这段代码,我们自己创造了一个UserService对象,并且它将成为Bean。但是通过这种方式创造出来的UserService的Bean,只会经过初始化后,其他Spring的生命周期步骤是不会经过的,比如依赖注入。
有同学可能会想到,通过@Bean也可以自己生成一个对象作为Bean,那么和FactoryBean的区别是什么呢?其实在很多场景下他俩是可以替换的,但是站在原理层面来说的,区别很明显,@Bean定义的Bean是会经过完整的Bean生命周期的。
十四、ExcludeFilter和IncludeFilter
这两个Filter是Spring扫描过程中用来过滤的。ExcludeFilter表示排除过滤器,IncludeFilter表示包含过滤器。
比如以下配置,表示扫描com.zhouyu这个包下面的所有类,但是排除UserService类,也就是就算它上面有@Component注解也不会成为Bean。
@ComponentScan(value = "com.zhouyu",
excludeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)}.)
public class AppConfig {
}
再比如以下配置,就算UserService类上没有@Component注解,它也会被扫描成为一个Bean。
@ComponentScan(value = "com.zhouyu",
includeFilters = {@ComponentScan.Filter(
type = FilterType.ASSIGNABLE_TYPE,
classes = UserService.class)})
public class AppConfig {
}
FilterType分为:
- ANNOTATION:表示是否包含某个注解
- ASSIGNABLE_TYPE:表示是否是某个类
- ASPECTJ:表示否是符合某个Aspectj表达式
- REGEX:表示是否符合某个正则表达式
- CUSTOM:自定义
Spring的扫描逻辑中,默认会添加一个AnnotationTypeFilter给includeFilters,表示默认情况下Spring扫描过程中会认为类上有@Component注解的就是Bean。
十五、MetadataReader、ClassMetadata、AnnotationMetadata
在Spring中需要去解析类的信息,比如类名、类中的方法、类上的注解,这些都可以称之为类的元数据,所以Spring中对类的元数据做了抽象,并提供了一些工具类。MetadataReader的接口定义如下:
/**
* Simple facade for accessing class metadata,
* as read by an ASM {@link org.springframework.asm.ClassReader}.
*
* @author Juergen Hoeller
* @since 2.5
*/
public interface MetadataReader {
/**
* Return the resource reference for the class file.
*/
Resource getResource();
/**
* Read basic class metadata for the underlying class.
*/
ClassMetadata getClassMetadata();
/**
* Read full annotation metadata for the underlying class,
* including metadata for annotated methods.
*/
AnnotationMetadata getAnnotationMetadata();
}
MetadataReader表示类的元数据读取器,默认实现类为SimpleMetadataReader。比如:
public class MySpringApplicationTest {
public static void main(String[] args) throws IOException {
SimpleMetadataReaderFactory simpleMetadataReaderFactory = new SimpleMetadataReaderFactory();
// 构造一个MetadataReader
MetadataReader metadataReader = simpleMetadataReaderFactory.getMetadataReader("org.example.spring.bean.UserService");
// 得到一个ClassMetadata,并获取了类名
ClassMetadata classMetadata = metadataReader.getClassMetadata();
System.out.println(classMetadata.getClassName());
// 获取一个AnnotationMetadata,并获取类上的注解信息
AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata();
for (String annotationType : annotationMetadata.getAnnotationTypes()) {
System.out.println(annotationType);
}
}
}
需要注意的是,SimpleMetadataReader去解析类时,使用的ASM技术。
为什么要使用ASM技术,Spring启动的时候需要去扫描,如果指定的包路径比较宽泛,那么扫描的类是非常多的,那如果在Spring启动时就把这些类全部加载进JVM了,这样不太好,所以使用了ASM技术。