flink on yarn指定第三方jar包
1. 背景
我们在将flink任务提交到yarn上是,通常的做法是将所有需要用到的jar包使用shade插件将其打包到一个大的jar包内,然后通过flink run命令来将其提交到yarn上。但是如果经常有代码改动,或者是小组内很多同事都需要在同一个项目中开发多个业务模块,而依赖很少改动时,每个业务的模块都打包成一个特别大的jar包,上传最终的任务jar时,就会变得非常麻烦。
因此,我们需要将第三方jar包放到服务器上,然后每次只需上传用户的thin-jar即可启动对应flink任务,可大大减少数据传输消耗的时间。
2. 参数
指定第三方jar包,需要在flink run命令后添加两个参数:-yt和-C。
- -yt:上传指定目录下的所有文件到flink任务对应的hdfs目录,之后flink任务运行时,会将hdfs上的整个目录拷贝到TM所在机器的本地目录。可以通过flink ui界面找到TM所在机器,然后使用 jps 命令找到对应任务的 pid ,然后跳转到 /proc/进程号/fd 目录,查看该目录下所有的文件,就可以看到进程运行时需要的所有jar包。
- -C:同时指定driver和taskManager运行的java程序的classpath。该命令指定的文件路径必须URI格式的,本地文件以file:///开头,注意不能使用文件通配符“*”。如果是相对路径(相对于运行flink run命令的目录),则以 flink: 开头即可。
但是,现在flink程序中用到了很多第三方jar包,这可怎么办呢?
比如说我用到了30个第三方jar包,-yt参数还好,可以指定目录,但是-C参数只能指定一个文件,难道要我使用30次-C参数么,那未免也太麻烦了吧。
其实这个问题很好解决。
将自己的项目写成多模块项目,项目的pom文件中的所有第三方依赖的scope标签都设置为provided,然后新建一个模块,将所有需要上传到服务器的jar包都放到该模块的pom文件中,并且不指定scope范围,表示打包时将其打包到最终jar包内。
多模块项目,项目pom文件内容:
4.0.0
com.baishancloud.log
thunderfury-flink-maven
1.0
thunderfury-flink-maven
common
streaming-directories-aggregate
streaming-fm-single-machine-statistics
streaming-netease-analyzer
streaming-bilibili-quality
streaming-icbc-report
streaming-live
streaming-miguict-audit
streaming-murloc
streaming-302-traffic
third-part-package
pom
UTF-8
1.8
1.8
1.13.3
2.12.15
2.12
junit
junit
4.13.2
test
org.scala-lang
scala-library
${scala.version}
provided
org.apache.flink
flink-streaming-java_${scala.package.version}
${flink.version}
provided
scala-library
org.scala-lang
slf4j-api
org.slf4j
commons-io
commons-io
org.apache.flink
flink-streaming-scala_${scala.package.version}
${flink.version}
provided
scala-library
org.scala-lang
org.apache.flink
flink-runtime-web_${scala.package.version}
${flink.version}
provided
org.apache.flink
flink-clients_${scala.package.version}
${flink.version}
provided
org.apache.flink
flink-statebackend-rocksdb_${scala.package.version}
${flink.version}
provided
org.apache.flink
flink-connector-kafka_${scala.package.version}
${flink.version}
provided
snappy-java
org.xerial.snappy
slf4j-api
org.slf4j
org.apache.flink
flink-connector-elasticsearch7_${scala.package.version}
${flink.version}
provided
log4j-api
org.apache.logging.log4j
commons-codec
commons-codec
httpclient
org.apache.httpcomponents
httpcore
org.apache.httpcomponents
com.starrocks
flink-connector-starrocks_${scala.package.version}
1.1.14_flink-${flink.version}
provided
com.baishancloud.log
log-format-scala_${scala.package.version}
3.1.43
provided
scala-library
org.scala-lang
cn.hutool
hutool-all
5.7.15
provided
org.apache.logging.log4j
log4j-slf4j-impl
2.12.1
provided
slf4j-api
org.slf4j
org.apache.maven.plugins
maven-surefire-plugin
2.22.2
true
org.apache.maven.plugins
maven-shade-plugin
3.2.4
package
shade
com.google.code.findbugs:jsr305
org.slf4j:*
log4j:*
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
org.apache.maven.plugins
maven-compiler-plugin
3.8.1
compile
compile
net.alchim31.maven
scala-maven-plugin
3.2.2
compile
testCompile
${scala.version}
-target:jvm-1.8
src/main/resources
*
alimaven
aliyun maven
https://maven.aliyun.com/nexus/content/repositories/central/
用来打包第三方jar包的模块pom文件
4.0.0
third-part-package
1.0
com.baishancloud.log
thunderfury-flink-maven
1.0
org.apache.flink
flink-statebackend-rocksdb_${scala.package.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.package.version}
${flink.version}
snappy-java
org.xerial.snappy
slf4j-api
org.slf4j
org.apache.flink
flink-connector-elasticsearch7_${scala.package.version}
${flink.version}
log4j-api
org.apache.logging.log4j
commons-codec
commons-codec
httpclient
org.apache.httpcomponents
httpcore
org.apache.httpcomponents
com.starrocks
flink-connector-starrocks_${scala.package.version}
1.1.14_flink-${flink.version}
com.baishancloud.log
log-format-scala_${scala.package.version}
3.1.43
scala-library
org.scala-lang
cn.hutool
hutool-all
5.7.15
2.1. 示例
通过DS将flink jar提交到yarn上。
先将第三方jar包依赖上传到DS上。
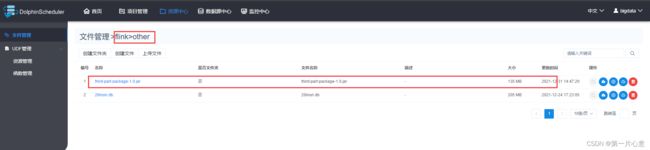
我将项目用到的所有第三方jar包打包之后的jar包上传到了DS的flink/other目录下。
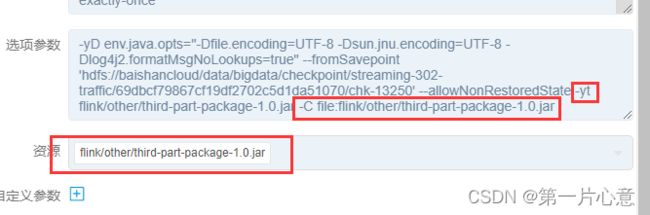
之后在flink任务的提交参数设置中,在选项参数中指定-yt和-C命令,均为相对路径(相对于运行flink run命令)。资源中勾选刚才上传到flink/other目录下的jar包。
然后启动该任务,观察启动日志。
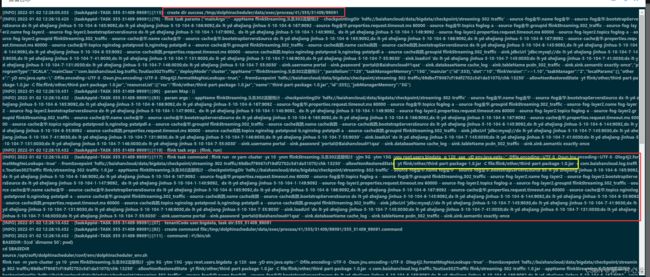
观察日志可以看到,首先在启动任务的机器上创建了临时的启动目录,然后将启动命令写到一个.command脚本中。启动命令中就包含了刚才指定的-yt和-C参数。
然后登录到DS启动任务的具体集群上,切换到临时的启动目录,然后就可以观察到jar包被下载到了临时启动目录中。
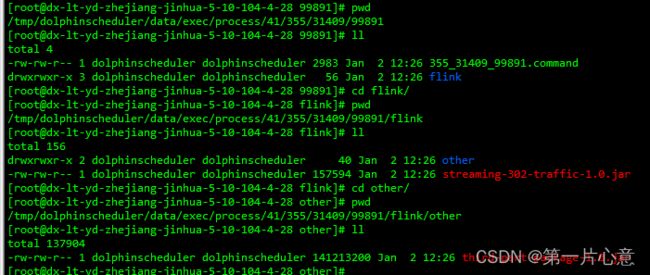
查看hdfs对应flink on yarn启动之后的yid对应的目录下的文件。
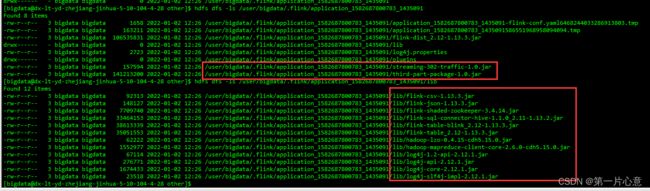
可以看到,我们在DS中的上传的文件和flink自己的lib下的文件都被上传到了hdfs中。
然后去查看TM对应的机器上的文件情况。
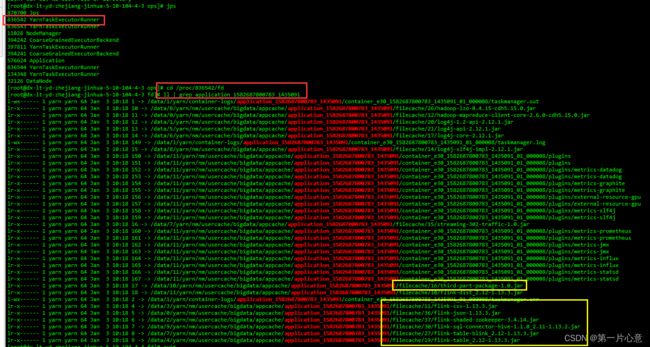
可以看到运行该yarn任务的进程使用到的所有的jar包,其中就有我们指定的第三方jar包打包之后的jar包。
3. 总结
-yt是将指定的本地目录下所有文件上传到hdfs,之后flink on yarn任务运行时,会通过-C,将指定的文件拷贝到运行TM的机器上(也是运行container的机器),之后运行flink TM时,TM就能直接读取机器的本地jar包。
大家可以去看看 StreamPark 这个平台,是 flink 任务的一站式解决方案,非常方便使用,本人也有幸在其中贡献了一些代码。