大厂容器云实践之路(四)
7-爱奇艺基于 Docker 的 App Engine 实践
背景
业务上
虚机承载的业务:
后台服务:25%
worker:20%
其他:55%
技术上
2014年第三季度
出发点
目标
道路曲折

用户受益
• 资源到位快
• 部署快(上线、升级)
• 扩容快
• 自动故障转移,免运维
• 完善的监控预警
• 持续集成、发布
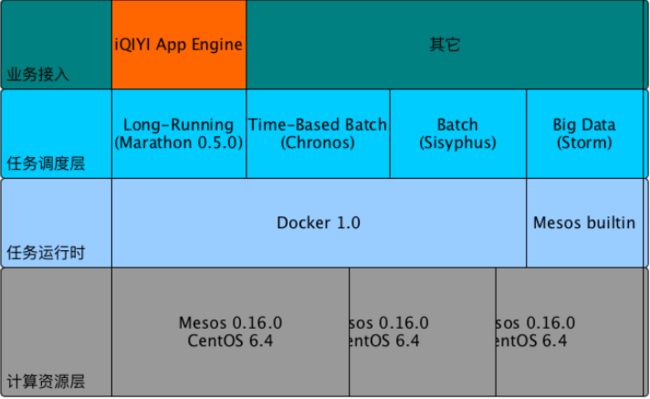
iQIYI App Engine 设计与实现
iQIYI App Engine (QAE)
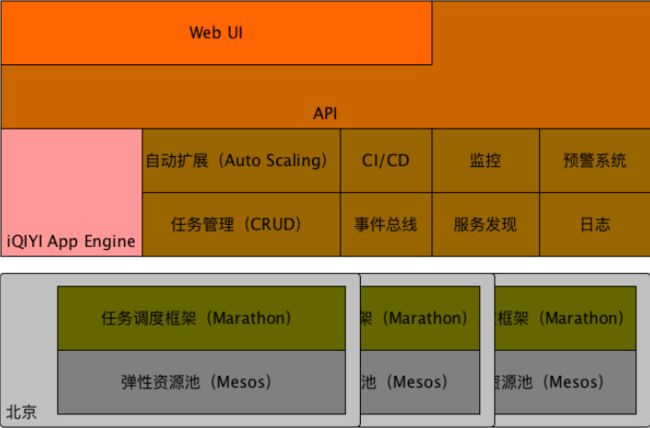
QAE — 监控和预警
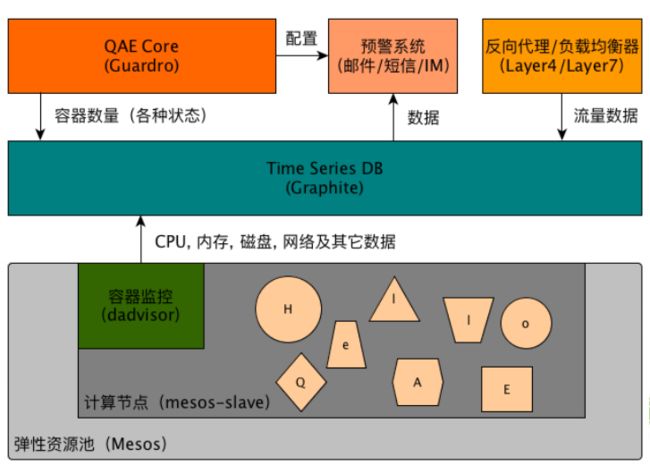
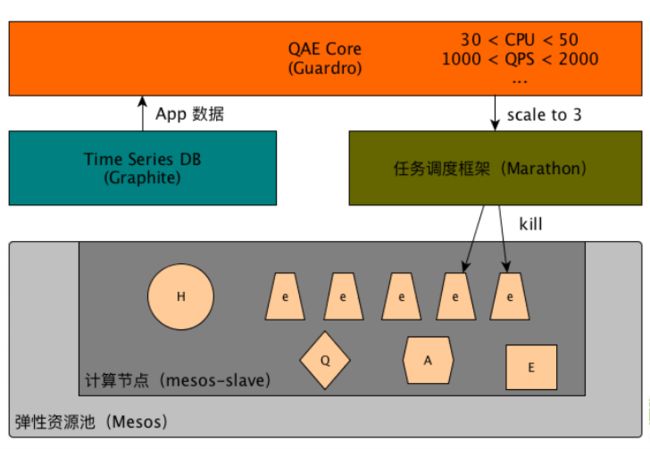
QAE — 自动扩展(Auto Scaling)
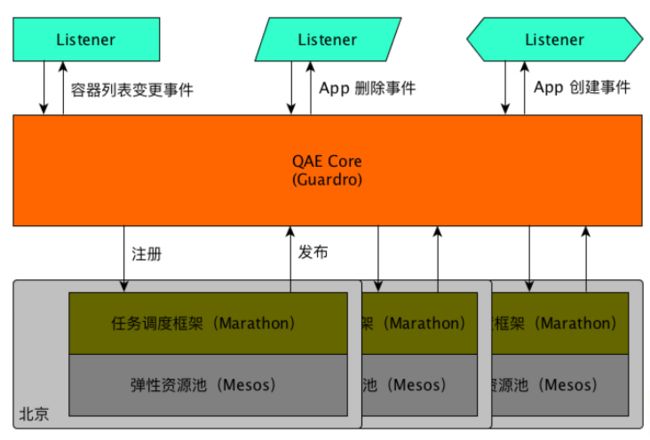
QAE — 事件总线
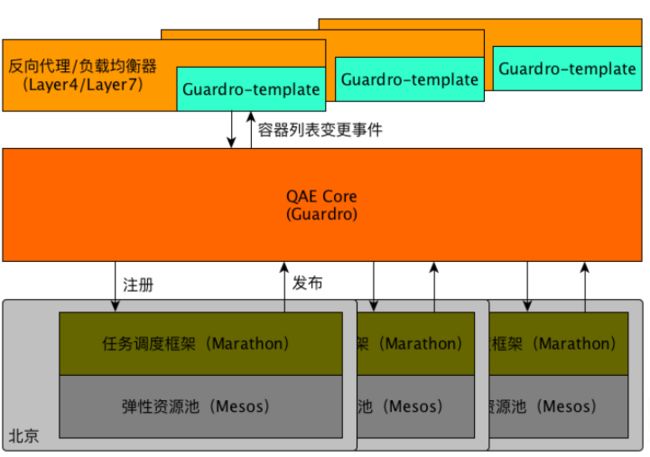
QAE — 服务发现
QAE — 日志
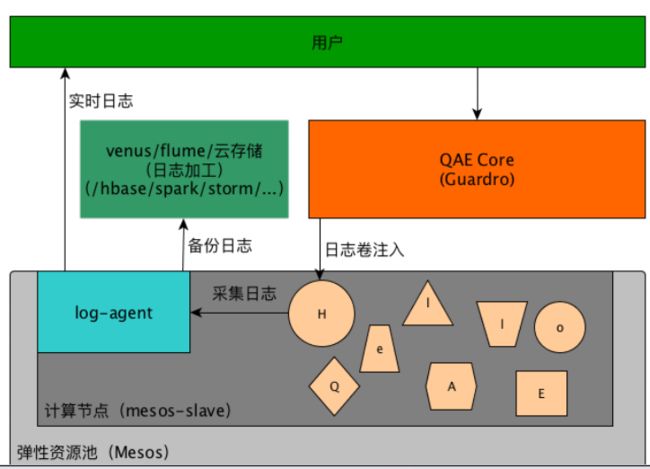
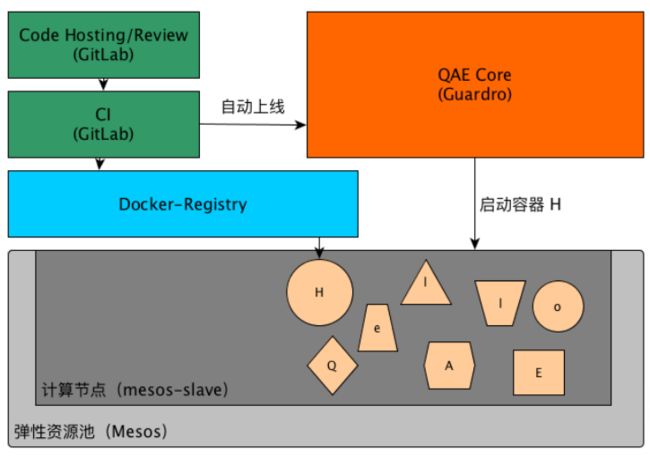
QAE — CI/CD
一些经验(坑)
容器监控 — Zabbix
• 优势
• 已有 Zabbix 基础服务
• Auto Discovery 能发现容器启动/消失事件
• 劣势
• 需要在容器内部安装 zabbix, overhead 太大
• 不是很稳定
• 数据统计比较复杂
容器监控 — cAdvisor
• 优势
• 背靠 Google 且开源
• 监控数据详尽
• 劣势
• 集群化开发成本较高,Kubernetes heapster 实现
• influxDB 而非 graphite(当时有基础服务)
容器监控 — dAdvisor
• Docker Advisor
• 采集:CPU, 内存,磁盘,网络
• 集成现有 Graphite
• 统计数据方便(Graphite 内置一些操作符)
• 呈现方便(Graphite Render URL API)
• 开发量不大
Time Series Database — Graphite
• 优势
• 老牌(Since 1999),已有服务,经过验证
• 简单、内置 aggregator,Render URL API
• 劣势
• 项目及社区已经几乎停滞
• 集群化配置复杂,需要详细规划
• 缺乏多用户认证,授权机制,黑白名单太单薄
• 数据删除缺少 API
服务发现(Service Discovery)
• 负载均衡/反向代理方案
• HAProxy:Marathon 支持,用户少
• Nginx:大量用户
• 服务发现
• Flask 推送,SSH,不可靠,不安全
• Ansible 推送,SSH,不可靠,不安全
• event bus + guardro-template
日志
• ELK (Elasticsearch + Logstash + Kibana)
• 延时较高(分钟级)
• 只支持格式化后的日志(for machine)
• 用户诉求
• 低延时(秒级),准实时
• 裸日志(for real person)
• 备份日志(Apache Flume)
现状与展望
现状
• 处于活跃开发状态
• 接入了几十个业务
• 主要业务类型:服务型,RPC,Worker
• 服务型业务 QPS 大于 10 万
• 4 个数据中心
展望
• 支持短任务
• Quota 和计费
• Web Console
• 内置典型服务(如:Tomcat)数据统计
• Docker 持久化卷和跨主机通信
• 支持更多类型服务:Cache, DB, MQ 等
8-蘑菇街基于Docker的私有云实践
做私有云的原因
1、越来越多的机器,集群管理,基础平台的建设
2、提高资源的利用率
3、服务化,平台化,可视化
4、提升发布和部署的效率
5、实现业务的弹性,水平扩展
Docker的优势
1、轻量,秒级的启动速度
2、简单,易用,活跃的社区
3、标准统一的打包/部署/运行方案
4、镜像支持增量分发,易于部署
5、易于构建,良好的REST API,也很适合自动化测试和持续集成
6、性能,尤其是内存和IO的开销
简单易用
docker run -d
--net=none
--name=$name
-h $name
-v /var -v $tmpdir/resolv.conf:/etc/resolv.conf -v $tmpdir/hosts:/etc/
hosts
--cpuset="$cpuset"
-m ${mem}m
--privileged=true
$image
劣势
1、资源调度/集群管理还在春秋战国时期
2、隔离性-仅用cgroup/namespace够吗
3、网络/存储支持完善吗
4、不支持热迁移-CRIU
5、各种坑
Docker@蘑菇街
1、2014年圣诞节期间上线,OpenStack IceHouse + Docker1.3.2。经历过5次+大促,包括双11/双12,线上运行稳定。
2、Machine Container或“胖容器”,用supervisord管理容器中的多进程。
3、每个机房一个OpenStack集群,一个Docker Registry。每个集群可以同时管理KVM,Docker。
4、支持OpenvSwitch VLAN和Linux Bridge两种网络模式,不用Docker原生的NAT网络模式,other_args="--bridge=none"。
5、自研了基于OpenStack的PaaS平台,虚拟化交付系统,虚拟化管理控制台。
为什么都把Docker当成虚拟机

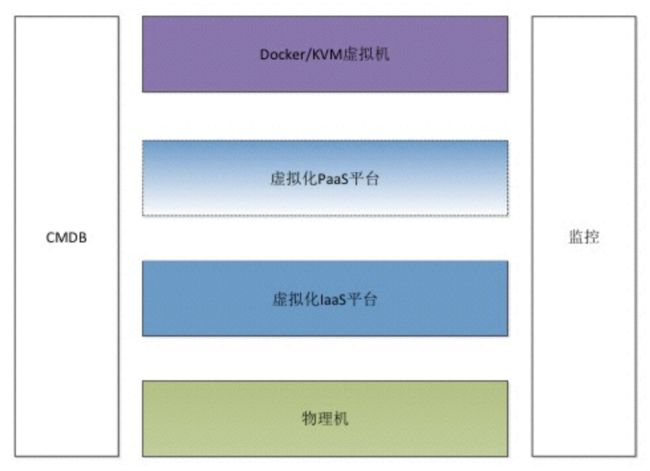
只有Docker是不够的
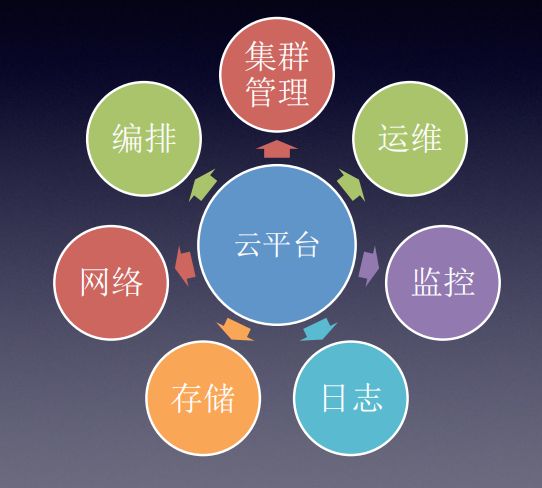
集群管理
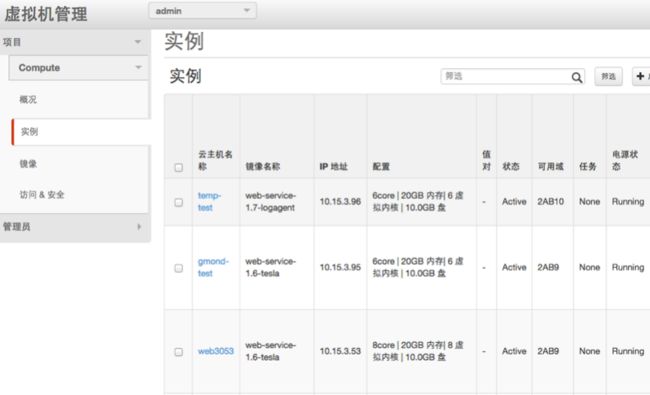
逻辑架构图
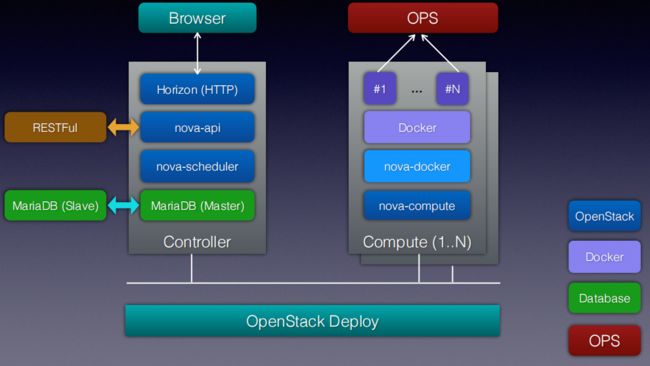
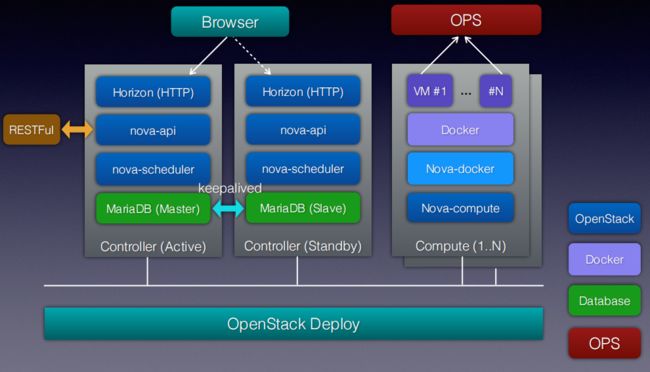
nova-docker
• spawn: create -> start -> post_start docker
• 容器启动前做的事情:
• 根据ip段的规则来生成容器的hostname
• 动态添加ip:hostname映射到/etc/hosts
• 启动docker实例时指定CPU set/weight
• 自定义需要mount的folder/file volume
• 扩展OpenStack API,通过cgroup限制磁盘IO和网络IO
• 和Linux bridge/Openvswitch对接网络
• 实现快照方式的冷迁移
https://github.com/openstack/nova-docker/
监控
和已有监控系统的深度集成
实时监控和阈值报警:节点存活性/语义监控,关键进程,内核日志,实时pid数量,网络连接跟踪数,容器oom报警
阈值报警:短信报警,IM报警等多种形式
健康检查:部署环境/配置的一致性检查
container-tools:
参考内核算法实现容器内load值的计算
替换了uptime,top,free,df,类似docker stats。

Container-tools
• mount /cgroup 到容器内
• 容器启动时用docker exec创建一个文件记录每个容器使用的cpuset,实例uuid等信息
• 修改uptime,top,free,df,tsar等源码,读取 /cgroup下的cpu/memory/IO值信息
• 曾经尝试过lxcfs,但问题很多,限制也很多。
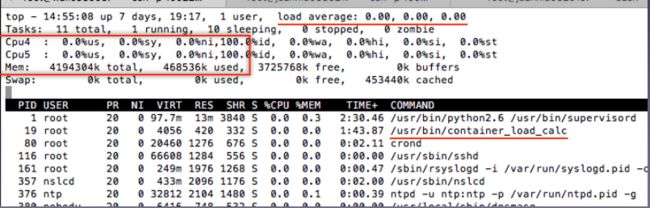
实时监控和报警
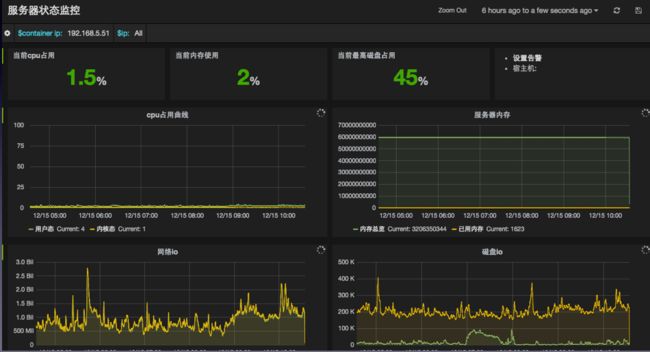
网络
• NAT-20% performance lost
• Host mode? No network isolation
• Linux bridge without iptables
• OVS VLAN without iptables
• other_args="—bridge=none"
容灾
• 离线恢复docker容器中的数据的能力
• Docker实例跨物理机的冷迁移:docker commit,docker push。
• 动态的CPUٖ内存扩容:cgroup。
• 网络IO/磁盘IO的限速: cgroup/tc。
http://mogu.io/127-127
PaaS
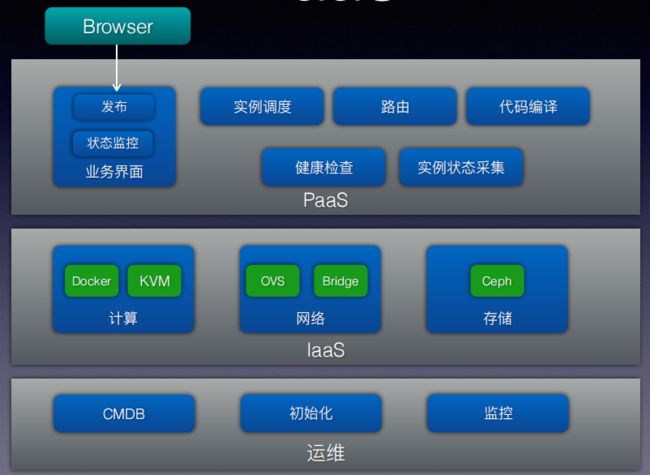
• 目标
• 快速的系统构建
• 业务的平滑部署升级
• 自动的运维管理
• 自研的轻量PaaS,实现编排能力
• 支持基于容器的持续集成:Jenkins+Docker,从编译到构建全自动化
• 概念
• App:一个应用包含一个或多个Stack
• Stack:相同的Docker实例,一个Stack中的不同实例尽量部署在不同的物理机上
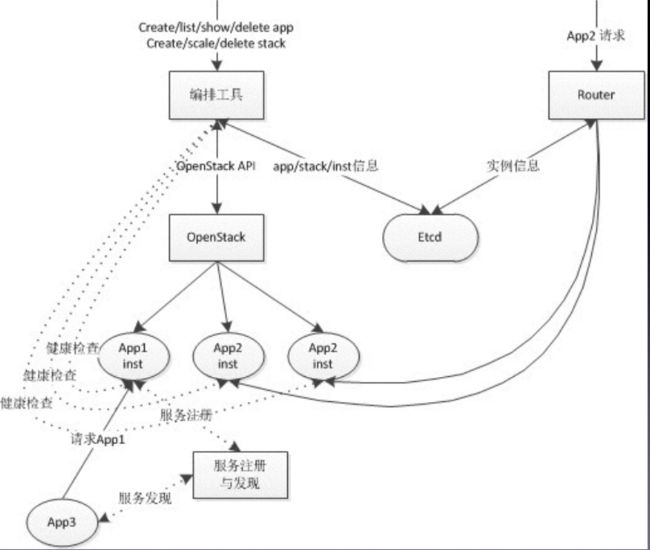
Docker Registry
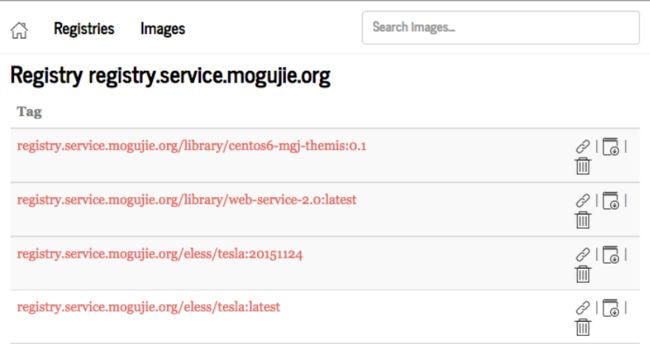
基于Docker的持续集成
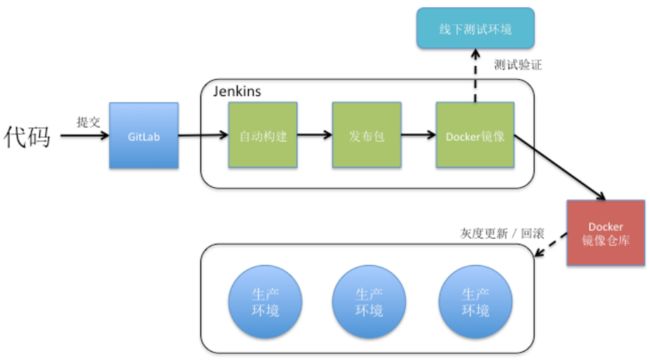
基于PaaS的业务平台
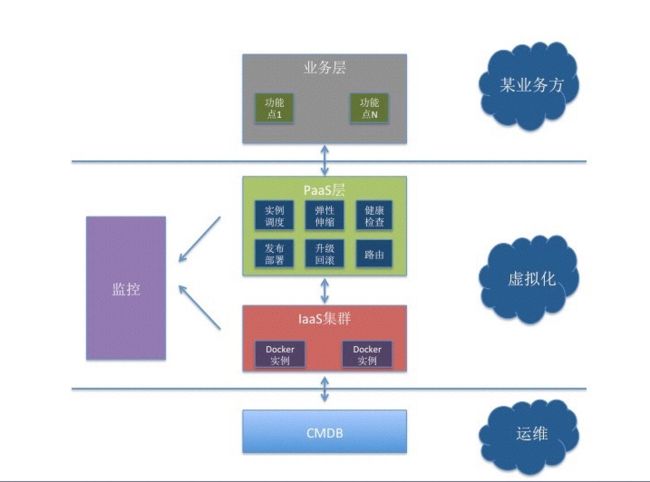
遇到的坑
• devicemapper中thin-provisioning的discard功能引起的kernel crash
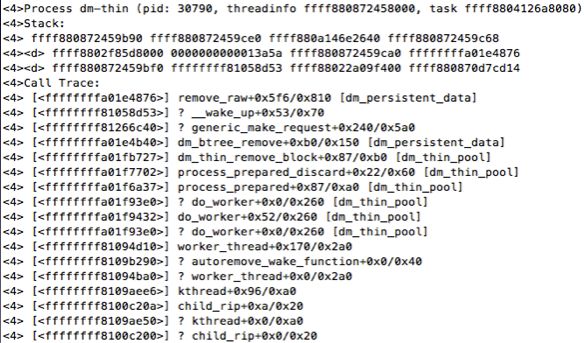
DOCKER_STORAGE_OPTIONS="--storage-opt dm.mountopt=nodiscard --storage-opt dm.blkdiscard=false"
http://mogu.io/docker_crash-79
隔离
• 物理机上无法执行命令操作。“bash: fork: Cannot allocate memory”
• 容器内如果创建大量的进程,并且不回收,是会导致系统内核的pid_max达到上限
• ٖ内核中的pid_max(/proc/sys/kernel/pid_max)是全局共享的
• Process Number Controller:
• 仅最新的4.3-rc1支持,pid-max per containers̶
• https://www.kernel.org/doc/Documentation/cgroups/pids.txt
• 容器内的内存值计算不准确,比实际低一个量级
• /cgroup/memory/docker/id/memory.usage_in_bytes
Docker目前的局限
• 系统/内核层面的隔离性
• 缺乏成熟的集群管理(K8S/Swarm/Mesos)
• 业务无感知的升级,Docker daemon live upgrade
未来的畅想
• PaaS + App Container + CI/CD
• Kubernetes/Swarm/Mesos
• 更高效更便捷的运维
• 统一的部署方式,弹性的资源交付
• 公有云平台