12、SRS4.0源代码分析之WebRTC Qos概念汇总
前言:
前面学习的WebRTC基本工作原理其实并不复杂,更多的软件处理工作在于保证音视频数据传输的实时性和传输质量。所以不夸张的说,WebRTC中大部分代码都是和QoS(服务质量)有关的。
本章主要目标是整理WebRTC中和QoS相关的一些基本概念,为深入学习WebRTC代码做准备。
一、WebRTC为什么使用UDP传输
首先,WebRTC是一个类似于传统电话服务的实时音视频通讯方案,它首先关注的是:音视频数据的实时性(延时<800毫秒)。
其次:保证音视频数据在传输过程中报文内容尽量完整以及报文的延时尽量稳定,最终用户接收数据并解码播放时有良好用户体验。
| 举个例子,假设你是一个球迷,通过电视看NBA总决赛或世界杯决赛的现场直播,在比赛的最后十分钟,突然,电视线路持续中断5分钟,5分钟后画面恢复,请问恢复的时候,大家是希望接着刚才中断的画面继续看,还是希望立即看当前最新的现场画面。毫无疑问,绝大多数人都会选择看最新的现场画面,而不是接着断开的画面看5分钟之前的历史。 |
因此,对于实时通信场景,所有的音视频数据都有时效性,超过了一定时间,数据的时效性就过期了。也就失去了在实时通信场景中的传输价值。
所以,现实中,无论是音频编码器,还是视频编码器,在最初设计这个编码理论时,都会考虑到编码后的数据经过网络传输如果丢失了一小部分,到接收端后仍然可以进行高质量的解码和播放,保证用户体验。即所有编码后的音视频数据都具备一定程度的可丢失性。
正是因为实时音视频报文的时效性和可丢失性,很多涉及实时音视频传输的场景,底层都选用UDP协议作为传输层协议。并不是说UDP协议天然比TCP协议传输快、延时低(这里别扯三步握手,扯就是你赢),而是说,实时音视频通信场景,需要优先保证低时延,允许传输层丢失一部分不太重要的数据,而UDP恰好满足允许丢失数据的需求,如果采用TCP,当遇到网络质量抖动时,任何丢包都会引起TCP协议的重传,用户无法选择按需重传,相比UDP,显得不够灵活。
| 实际上,在网络带宽有保证的前提下,UDP和TCP在传输质量上体现出来的差异几乎没有。例如,我当前的产品主要服务美国市场,所以在美国芝加哥部署了一台转发服务器,但平时做测试,编码设备和解码设备还是在国内,其中编码器从桌面抓取包含当前时间的视频流(码率大概1Mbit/s)发送到美国的转发服务器,再经过转发服务器回到国内的解码器上显示。此时,编码器桌面的当前时间比解码器显示的时间大概快了250ms,即此时整个传输的端到端延时就是250ms(这个值其实是可以通过简单的理论计算出来的,大概知道光在光纤中的传播速度是每秒20万公里就行)。 |
二、WebRTC使用UDP传输会有什么问题
WebRTC为了实现音视频数据实时通信(延时尽可能低)的目标,面临的挑战主要包括:
- 延时:按照延时产生的原因,报文的延时一般包括网络传输延时和数据处理延时。网络传输延时一般是由物理传输路径决定的,例如,太阳发出的光需要8分钟才能达到地球,这个8分钟就是传输延时,它是由光的传播速度和太阳与地球之间的距离决定的。数据处理延时是指处理数据需要花费的时间,所以减少不必要的数据处理,可以降低数据处理延时。正常情况下,传输延时影响最大,数据处理造成的延时比传输延时要小很多。
- 抖动:抖动主要体现在报文之间的传输延时不稳定,一会接收到大量数据,一会完全收不到数据。最终影响接收端解码播放的质量。产生抖动的原因包括运营商网络拥塞引入的抖动以及用户数据源的生产特性导致的抖动。例如,一个帧率为25帧/s的H264编码器,每秒钟生成25帧,帧间隔是40ms,第一个I帧的数据量可能是300KB,后续P帧的数据量可能只有几KB或几十KB,这就是典型的生成数据不均匀引入的抖动。
- 乱序:同一个用户先、后发送的数据包,经过网络中不同的传输链路到达接收端的顺序可能和发送时的顺序不一致,而UDP协议无法对乱序的报文进行纠正,导致应用程序接收到乱序的报文。
- 丢包:用户发送的报文,因为中间路由器交换机的缓存不足而直接丢包,或者传输信号受干扰产生误码导致报文内容错误最终被丢弃,而UDP协议不感知报文的丢失,导致应用程序接收到的报文数量比发送端少。
根据上面的分析可以看到,低时延是RTC(实时通信)追求的首要目标,而抖动、乱序、丢包则是追求低时延过程中出现的问题。为了减少抖动、乱序、丢包对用户体验的影响,必须增加软件处理,而这些增加的处理反过来又增加了音视频报文的延时。
上述过程在逻辑上似乎出现了一个死循环,所以,WebRTC的QoS处理,就是要在低时延和抖动、乱序、丢包之间保持一个动态平衡,防止出现无解的死循环。
三、WebRTC的QoS需要做什么
1、减少抖动
一般音频数据编码后都比较小,可以按照网络MTU的限制均匀打包并传输。而对于视频报文,例如H264编码后,无论是I帧还是P帧,都是几KB到几百KB之间,而公网UDP报文的大小一般都建议不超过1500字节(实际上,我遇到过一个日本的客户,在他的网络里,UDP报文必须小于1300字节才能正常传输),所以,每个视频帧都会被切片、封装成几十或几百个UDP报文并缓存,再通过另一个PACER线程,周期性均匀发送这些UDP报文,防止上行流量激增导致网络拥塞。显然,这种先存储再转发的PACER机制会增加报文传输的延时。
| 实际上,我曾在一个嵌入式产品上,实现过一个简单的WebRTC协议固件,用于和亚马逊Alexa服务对接,实现嵌入式产品与亚马逊echo show智能音箱之间的实时双向语音和视频传输,其中WebRTC固件在切片并封装视频帧时并没有采用上述pacer机制,而是一股脑把数据都发出去,在实际测试和应用中效果也不错,其中的原因主要是因为客户在正常使用场景下,带宽都是足够的,另外,对于这些一股脑发送出去的报文所形成的突发流量,完全可以被网络中路由器、交换机的缓存吸收,最终实现均匀转发。 |
2、乱序恢复
对于乱序问题,接收端一般通过类似于JitterBuffer或NetEQ的方式缓存一部分报文,即收到的RTP报文不会立即解码,需要缓存一定个数的RTP报文后,将报文按序列号(seq)排序后再发给解码器,可一定程度上解决乱序问题。同时这种接收端缓存方式也可以减少报文的抖动。显然,这里的接收缓存也会增加报文的延时。
3、抗丢包
WebRTC在遇到网络抖动时,为了优先保证传输音视频报文的低时延,允许丢弃一部分音视频数据包,所以底层采用UDP传输协议。但是被传输的数据中哪些报文可以丢,哪些不能丢,则只能交给应用程序决定。
1)NACK
接收端作为报文的消费者,如果认为丢失的报文很重要,则可以通过NACK(Negative Acknowledgement)方式,请求发送端将丢失的报文重发一次。
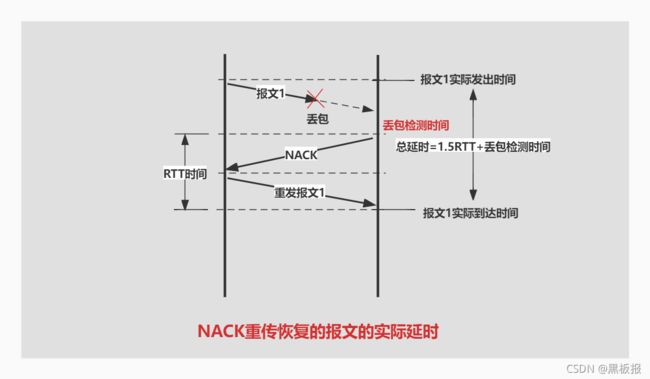
通过NACK重传恢复的报文最少的延迟时间是1.5倍的RTT时间+丢包检测时间,所以,WebRTC中对延时敏感的音频数据一般不用NACK;距离比较远,RTT比较大的场景也尽量不用NACK。
下面是chrome浏览器默认情况下生成的offer SDP信息,其中视频部分的描述都和NACK有关
a=rtpmap:102 H264/90000
a=rtcp-fb:102 goog-remb // 这里使能各种RTCP报文(remb/tcc/fir/nack/pli)
a=rtcp-fb:102 transport-cc
a=rtcp-fb:102 ccm fir // fir-rtcp报文用于请求发送端强制生成I帧
a=rtcp-fb:102 nack
a=rtcp-fb:102 nack pli // pli-rtcp报文用于请求发送端重发I帧
// 这一句是定义RTP封包方式
a=fmtp:102 level-asymmetry-allowed=1;packetization-mode=1;profile-level-id=42001f
a=rtpmap:121 rtx/90000 // 这里定义RTX重传报文类型值
a=fmtp:121 apt=102
一般NACK请求重传时,发送端使用RTX重传报文类型值封装重传包,如果没使能RTX,则发送端只是简单的重发原来的RTP包,但是这种模式会影响接收端的丢包率统计。
2)FEC
为了解决重传引入的延时问题,还可以通过FEC(前向纠错编码)方式在每个即将发送的数据包中,添加关于前一个数据包的信息,这样接收端发现某个报文没收到时,在接收到下一个报文时,也能把前一个丢失的报文恢复出来。相比NACK,FEC属于发送端主动执行的抗丢包措施,它的优点是在解决丢包问题的同时没有增加延时,缺点则是需要消耗更多的传输带宽。
WebRTC中音频报文的FEC处理
下面是chrome浏览器默认情况下生成的SDP信息,其中音频部分默认不使用NACK,且仅针对Opus启用了带内FEC(inbandfec)功能。
a=rtcp-mux
a=rtpmap:111 opus/48000/2 <--------音频opus编码,封装成RTP报文时,报文头payload type值是111
a=rtcp-fb:111 transport-cc <----------开启transport-cc
a=fmtp:111 minptime=10;useinbandfec=1 <---minptime表示最小打包时长为10ms,
<---useinbandfec表示使用opus编码器内置的fec功能
a=rtpmap:103 ISAC/16000
a=rtpmap:104 ISAC/32000
a=rtpmap:9 G722/8000
a=rtpmap:0 PCMU/8000
a=rtpmap:8 PCMA/8000
a=rtpmap:106 CN/32000
a=rtpmap:105 CN/16000
a=rtpmap:13 CN/8000
a=rtpmap:110 telephone-event/48000
a=rtpmap:112 telephone-event/32000
a=rtpmap:113 telephone-event/16000
a=rtpmap:126 telephone-event/8000
Opus音频编码器带内FEC的工作原理是:使用低码率编码前一个时刻的历史音频包数据,并作为冗余信息插入到当前时刻的音频包中。

因为带内FEC的编码和解码都是由Opus自动实现,所以用户使用起来比较简单,
1、用户可使用下面这两个函数打开和关闭Opus编码器内置的带内FEC功能
int16_t WebRtcOpus_EnableFec(OpusEncInst* inst);
int16_t WebRtcOpus_DisableFec(OpusEncInst* inst);
2、WebRTC音频接收端计算网络丢包率,并通过RR类型的RTCP报文通知发送端,下面是发送端处理丢包率信息的函数
void AudioEncoderOpusImpl::OnReceivedUplinkPacketLossFraction(
float uplink_packet_loss_fraction) {
......
packet_loss_fraction_smoother_->AddSample(uplink_packet_loss_fraction);
float average_fraction_loss = packet_loss_fraction_smoother_->GetAverage();
SetProjectedPacketLossRate(average_fraction_loss); // 内部调用Opus接口
}
3、发送端通过WebRtcOpus_SetPacketLossRate接口,将丢包率设置到Opus编码器内部用于生成冗余度合适的FEC编码,如下:
void AudioEncoderOpusImpl::SetProjectedPacketLossRate(float fraction) {
fraction = std::min(std::max(fraction, 0.0f), kMaxPacketLossFraction);
if (packet_loss_rate_ != fraction) {
packet_loss_rate_ = fraction;
RTC_CHECK_EQ(
0, WebRtcOpus_SetPacketLossRate(
inst_, static_cast<int32_t>(packet_loss_rate_ * 100 + .5)));
}
}
另外,Opus编码器内部还有DTX功能(Discontinuous Transmission:非连续传输,即安静的时候自动降低编码码率),Opus解码器内部有PLC功能(Packet Loss Concealment:丢包隐藏,即解码器通过相关性预测隐藏当前的丢包错误),它们配合带内FEC,一起保证Opus音频数据的QoS。
WebRTC中视频报文的FEC处理
视频报文的FEC编码依赖于XOR(异或)运算,它的内在数学原理可参考:谈谈网络通信中的 FEC 基础 https://zhuanlan.zhihu.com/p/104579290
这里只需要记住,如果有两个数据包A、B需要传输,首先对A、B进行异或运算得到数据包C
C = A ^ B
因为异或运算的数学原理,也同时存在
A = C ^ B
B = C ^ A
此时C作为冗余数据包和A、B一起发送,只要网络丢包率不超过30%,接收端一定可以根据收到的任意两个报文还原出第三个报文。
同理,也存在下面的运算结果,即可以对更多的数据包做NOR运算,降低FEC编码的冗余度。
D = A ^ B ^ C
A = B ^ C ^ D
B = C ^ A ^ D
C = A ^ B ^ D
关于冗余度的概念,它的计算公式如下:冗余度 = F E C 包 个 数 F E C 包 个 数 + 媒 体 包 个 数 FEC包个数 \over {FEC包个数 + 媒体包个数} FEC包个数+媒体包个数FEC包个数
WebRTC默认使用UlpFEC算法处理视频报文的FEC,其工作原理如下图:

首先将要传输的数据包先进行分组,然后为这一组包产生一个冗余包,如果这一组中某个包丢失了,就可以通过冗余包和其它包的异或操作将其找回。但是,如果同一组内出现两个以上的数据包丢失,则UlpFEC算法无法恢复丢失的数据包。
于是又有了改进的FlexFEC算法,它不仅横向做了冗余,而且纵向也做了冗余,如下图:

显然FlexFEC算法的实现更复杂,所以WebRTC默认不打开FlexFEC算法。
4、带宽估计与拥塞控制算法
上面关于抖动、乱序、丢包的处理虽然可以解决实际应用中的大部分问题,但是对于WebRTC这种互联网标准级别的解决方案显然还不够。但在继续优化之前,需要先把存在QoS问题的网络按照传输特征进行分类:
- 带宽受限型网络:这种比较好理解,比如上古时期通过电话线拨号上网,或者是一些比较便宜的家庭宽带套餐,虽然是光纤,但实际上每户的可用带宽都被运营商做了限制。
- 信道差错型网络:这种不太好理解。例如在网络中放一个丢包率为10%的网络损伤仪,此时不管实际带宽有多大,通过的报文总有10%丢包。比较典型的是存在较大干扰信号的WIFI环境。另外,我曾遇到过一个公司的网关路由器,只要打开了流控功能,其中的UDP报文就固定40%的丢包。
对于信道差错型网络,只要带宽还够用,就特别适合通过FEC算法产生冗余数据包来对抗丢包问题。
对于带宽受限型网络,必须从源头上降码率、降帧率、降分辨率甚至是主动丢包,让音视频数据流匹配网络的实际带宽。

如上图,大部分QoS问题都是网络出现劣化,实际出口带宽小于入口流量,网络退化为带宽受限型网络。首先,用户报文在网络缓存中发生堆积,此时报文的传输延时变大,如果持续一段时间,网络缓存耗尽后,则出现网络丢包。
针对这种情况,需要软件能够尽量准确的探测网络的真实带宽,自动调节音视频数据的输出码率,防止网络过度拥塞,QoS持续恶化。
一般带宽不足时,音视频流的时延、抖动、丢包率都会发生变化。所以从检测指标上看,带宽估计算法可以分为:
- 基于丢包率(loss-based)的带宽估计
- 接收端基于延时(delay-based)的带宽估计(Recv-side Delay-based BWE)也被称为REMB
- 发送端基于延时(delay-based)的带宽估计(Send-side Delay-based BWE)也被称为Transport-CC
| [A Google Congestion Control Algorithm for Real-Time Communication draft-ietf-rmcat-gcc-02 |
1、基于丢包率(loss-based )的带宽估计
1)接收端计算丢包率
- 接收端分别记录接收到RTP包的总数(transmitted)和接收到重传RTP包的数量(retransmitted)。
- T1时刻收到的有序包的数量Count1 = transmitted - retransmitted
T2时刻收到的有序包的数量Count2。其中,T1在前,T2在后。 - 两次时间间隔之间理论上应该收到的包数量 = T2时刻接收到的最大包序号 - T1时刻最大有序包序号
uint16_t exp_since_last = (received_seq_max_ - last_report_seq_max_); - 两次时间间隔之间实际接收到有序包的数量 = T2时刻收到的有序包的数量 - T1时刻收到的有序包的数量
uint32_t rec_since_last = Count2 - Count1; - 两次发送间隔之间的丢包数 = 理论上应该收到的包数量 - 实际接收到有序包的数量
int32_t missing = exp_since_last - rec_since_last;
missing即为两次发送间隔之间的丢包数量,可用于计算丢包率,也会累加得到总的累积丢包数。 - 接收端发送的RR报文中包含两个丢包信息,fraction_lost是连续两次统计之间的丢包率,cumulative_number_of_packets_lost是总的累积丢包。
其中:fraction_lost = 小数形式的丢包率 * 256,这样得到的整数结果方便放入RTCP-RR报文中传输。
2)接收端发送RR报文(Receiver Report RTCP Packet)反馈丢包率

发送端周期性发送SR报文,接收端接收SR报文并通过RR报文进行响应。
接收端总是将总的丢包数,检测周期内的丢包率和当前接收到的最大序列号,填入RR包发给发送端。RR报文各字段具体内容如下:
RTCP通用头部信息如下:
- V:RTCP的版本号,一定等于2
- P:是否存在填充信息,报文的最后一个byte用于存储填充数据的长度,也就是:
padding_size_ = payload_[payload_size_ - 1] - RC:报文净荷中ReportBlock数据块的个数
- PT:RTCP的负载类型,对于RR报文一定是201
- lenght:报文实际长度等于lenght * 4
- SSRC of packet sender:RR报文发送者的SSRC
ReportBlock信息如下:
-
SSRC_n : 32 bits,RR报文接收者的SSRC。
-
fraction lost: 8 bits,连续两次统计之间的丢包率。
-
cumulative number of packets lost: 24 bits,过程中总丢包总数。
-
extended highest sequence number received: 32 bits,低 16-bit 是收到的最新的RTP 报文序列号,高16-bit 是序列号循环的次数。
-
下面的字段内容用于计算RTT,和丢包率无关,RTT= 发送方接收到RR的时间 - RR中LSR - RR中DLSR
-
interarrival jitter: 32 bits,RTP 数据报文抵达时间的抖动。
-
last SR timestamp (LSR): 32 bits,上一个SR包的发送时间戳。
-
delay since last SR (DLSR): 32 bits,本RR发送时距离接收到上一个SR的时间间隔
3)发送端接收RR报文,并根据丢包率调整估计带宽 A s As As
As( t i ) = { 1.05As( t i − 1 ) ; [丢包率loss < 2%] As( t i − 1 ) ; [2% <= 丢包率loss <= 10%] As( t i − 1 ) (1-0.5*loss) ; [丢包率loss > 10%] \text{As(${t}_{i}$) }= \begin{cases} \text{1.05As(${t}_{i-1}$)};&\text{\space\space[丢包率loss < 2\%] } \\[5ex] \text{As(${t}_{i-1}$)};&\text{\space\space[2\% <= 丢包率loss <= 10\%]} \\[5ex] \text{As(${t}_{i-1}$) (1-0.5*loss)};&\text{\space\space[丢包率loss > 10\%]} \end{cases} As(ti) =⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧1.05As(ti−1);As(ti−1);As(ti−1) (1-0.5*loss); [丢包率loss < 2%] [2% <= 丢包率loss <= 10%] [丢包率loss > 10%]
- 如果丢包率 < 2%,估计带宽在以前的基础上增长5%;
- 如果丢包率在[2%, 10%]之间,估计带宽保持不变;
- 如果丢包率 > 10%,估计带宽在以前的基础上降低(丢包率 * 50%)。
2、接收端基于延时(delay-based)的带宽估计
在实际应用中,基于丢包的带宽评估有时候会产生误导。例如,对于前面说的那种信道差错型网络,丢包的原因是信号干扰导致报文出错,并不是流量达到带宽上限,此时更应该增加FEC,增加码率,对抗丢包,最终保证接收端音视频质量,而不是因为有丢包就降低码率。(在这种网络里,码率再小,丢包率都是固定的)
接收端基于延时的带宽估计(Recv-side Delay-based Bandwidth Estimated)也被称为REMB(Receiver Estimated Max Bitrate),它在接收端根据报文传输延时的变化趋势估算网络真实带宽,并通过RTCP-REMB报文向发送端反馈计算结果。
1)报文延时与网络拥塞的关系

如上图左1,网络正常的情况下,两组(大小相同的)报文的发送时间差应该接近或等于它们的接收时间差。如上图右2,当网络出现拥塞时,两个报文的发送时间差不变,但是接收时间差变大,且网络拥塞程度越深,则两个时间差的差值也就越大。我们称这两个时间差的差值为时延梯度,公式如下:
d 时 延 梯 度 = ( t 2 − t 1 ) − ( T 2 − T 1 ) {{d}_{时延梯度}}= {({t}_{2}-{t}_{1}) - ({T}_{2}-{T}_{1})} d时延梯度=(t2−t1)−(T2−T1)
显然,当时延梯度增加时,表示入口流量超过了出口带宽,此时需要减少入口流量;当时延梯度减小时,表示入口流量小于出口带宽,此时可以增加入口流量。所以,接下来的问题是如何测量和计算报文的时延梯度。
2)使能接收端基于延时的带宽估计功能
WebRTC总是通过SDP报文中的如下字段,协商打开接收端带宽估计(REMB)功能
a=rtcp-fb:102 goog-remb
a=extmap:3 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time
REMB算法需要普通的RTP报文带有abs-send-time扩展头,通过这个扩展头携带RTP报文发送时的系统绝对时间,具体报文格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC |M| PT | sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| synchronization source (SSRC) identifier |
+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
| contributing source (CSRC) identifiers |
| .... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0xBE | 0xDE | length=1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ID | len=2 | absolute send time |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 0XBEDE:表示 RTP报文采用one-byte扩展头格式
- length=1:表示后面Header Extension的总长度是1*4=4个字节
- ID:4bit,表示Header Extension类型(这里是abs-send-time类型)
- len=2:4bit,表示后面的absolute send time数据占用2+1=3个字节
- absolute send time:表示发送报文时的系统绝对时间(即图中的发送时间 T T T)
3)接收端使用Kalman滤波器估计带宽
接收端记录RTP报文的接收时间t和报文abs-send-time扩展头中携带的发送时间T,并根据时延梯度计算公式,可得到一系列的时延梯度的测量值,而由于系统误差的存在,导致这些测量值总是存在较大的随机波动。
卡尔曼滤波器可以将测量值中不合理的噪音数据剔除或处理,留下或得到最接近真实情况的时延梯度数据。
关于卡尔曼滤波器的基础理论可以参考此链接 https://zhuanlan.zhihu.com/p/166342719。
最终根据时延梯度的变化趋势和下面的公式可确定是否需要增加、减少或保持发送端的流量。
Ar( t i ) = { 1.08Ar( t i − 1 ) ; [Increase状态] Ar( t i − 1 ) ; [Hold状态] 0.85Rr( t i ) ; [Decrease状态] \text{Ar(${t}_{i}$) }= \begin{cases} \text{1.08Ar(${t}_{i-1}$)};&\text{\space\space[Increase状态] } \\[5ex] \text{Ar(${t}_{i-1}$)};&\text{\space\space[Hold状态]} \\[5ex] \text{0.85Rr(${t}_{i}$) };&\text{\space\space[Decrease状态]} \end{cases} Ar(ti) =⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧1.08Ar(ti−1);Ar(ti−1);0.85Rr(ti) ; [Increase状态] [Hold状态] [Decrease状态]
【结合应用实例对卡曼滤波器工作过程的直观解释 https://blog.csdn.net/tiandijun/article/details/72469471】
4)接收端构造REMB报文反馈接收端带宽估计值
REMB(Receiver Estimated Max Bitrate)报文也属于一种RTCP报文,它的具体格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| FMT=15 | PT=206 | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| SSRC of packet sender |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| SSRC of media source |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unique identifier 'R' 'E' 'M' 'B' |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Num SSRC | BR Exp | BR Mantissa |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| SSRC feedback |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ... |
- SSRC of packet sender:此报发送方的SSRC。
- SSRC of media source:总是0
- Unique identifier:总是"REMB"字符串
- Num SSRC:本报文中SSRC的数量
- 估算带宽是uint64_t类型的整数,报文中用24bit表示则只能考虑指数形式 ,
- BR Exp:带宽的指数部分
- BR Mantissa:带宽的底数部分
- SSRC feedback:本报文适用的SSRC,由一个或多个SSRC条目组成
发送端从REMB报文中得到接收端的带宽估计值 = Mantissa * 2 ^ (Exp)
3、发送端基于延时(delay-based)的带宽估计
WebRTC早期版本基于延时的带宽估计算法放在接收端处理,而新版本的WebRTC将带宽估计统一放到了发送端,并采用Trendline滤波器。同时接收端基于延时估计带宽并反馈REMB报文的处理也仍然被保留,用于兼容旧版本。
1)使能发送端基于延时的带宽估计功能
WebRTC通过SDP报文中的如下字段,协商打开发送端带基于延时的宽统计(Sendside-BWE)功能
a=extmap:3 http://www.ietf.org/id/draft-holmer-rmcat-transport-wide-cc-extensions-01 <---指定RTP扩展头格式
a=rtcp-fb:102 transport-cc
前面介绍的各种算法在针对RTP报文进行统计时,总是依赖RTP报文头部的sequence number字段,正常情况下一个WebRTC session(RTC连接)中只有一条流,所以也没什么问题。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC |M| PT | sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| synchronization source (SSRC) identifier |
+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
| contributing source (CSRC) identifiers |
| .... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
但是WebRTC协议允许同一个session会话包含多个流(通过SSRC进行区分),也就是说之前算法总是会针对同一个session中的每条流分别估计带宽。
WebRTC最新的发送端带宽估计算法(Sendside BWE),定义了新的RTP扩展头,用于记录transport sequence number(针对整个session统一计数),所以也被称为传输层拥塞控制(transport-cc:Transport-wide Congestion Control)算法。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0xBE | 0xDE | length=1 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ID | L=1 |transport-wide sequence number | zero padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
如上图,发送端带宽估计算法(Sendside BWE)打开后,发送端的RTP报文的头部将增加了一个扩展信息transport-sequence-number ,代表传输层的报文序号。
2)接收端处理RTP报文并构造TransportPacketsFeedback报文
接收端如果支持transport-cc,则从RTP报文扩展头部获取transport-sequence-number字段信息,并记录RTP报文的到达时间(arrival_time_ms)。
同时,接收端按照某个周期定时发送含有transport-sequence-number和arrival_time_ms信息的TransportPacketsFeedback报文,格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| FMT=15 | PT=205 | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
0 | SSRC of packet sender |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4 | SSRC of media source |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
8 | base sequence number | packet status count |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
12 | reference time | fb pkt. count |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
16 | packet chunk | packet chunk |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
. .
. .
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| packet chunk | recv delta | recv delta |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
. .
. .
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| recv delta | recv delta | zero padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
从本质上看,TransportPacketsFeedback报文是RTP接收端对RTP发送端已发送数据的ACK,并且携带了报文在接收端的到达时间。
TransportPacketsFeedback报文采用base + bitmap的思想,使一个TransportPacketsFeedback报文能同时反馈多个RTP报文的有效信息(可计算每个RTP报文的传输层序列号和包到达时间)
- base sequence number: 16 bits,该FB包记录的首个RTP报文的transport-sequence-number。
- packet status count:16 bits, 该FB包记录的所有RTP报文个数。
- reference time:24 bits,该FB包记录的首个RTP报文的在接收端的到达时间,以64ms为单位。
- feedback packet count:8bits,已发送FB包的个器,可用于FB包丢失检测。
- packet chunk:16 bits ,描述RTP包的4种到达状态,以及与前面RTP包的时间间隔大小信息
00:包未收到
01:包已收到,时间间隔小
10:包已收到,时间间隔大或为负值
11:保留未使用
实际的packet chunk有Run Length Chunk 和Status Vector Chunk两种格式。
具体参考https://datatracker.ietf.org/doc/html/draft-holmer-rmcat-transport-wide-cc-extensions-01 - recv delta:8bits,当RTP包的状态为包已收到时,通过recv delta记录它与前一个RTP包的到达时间之间的间隔。
3)发送端接收TransportPacketsFeedback报文并估计码率
发送端收到TransportPacketsFeedback报文,通过base sequence number+偏移得到某个RTP报文的transport-sequence-number,再通过reference time和recv delta字段计算RTP报文在接收端的到达时间,同时发送端也记录了该报文的发送时间,最终根据时延梯度计算公式,可得到一系列的时延梯度( d d d)的测量值
d 时 延 梯 度 = ( t 2 − t 1 ) − ( T 2 − T 1 ) {{d}_{时延梯度}}= {({t}_{2}-{t}_{1}) - ({T}_{2}-{T}_{1})} d时延梯度=(t2−t1)−(T2−T1)
发送端使用Trendline滤波器,将上述过程2)中得到的时延梯度测量值拟合成如下图所示的一条直线,通过该直线的斜率可以判定时延梯度的变化趋势是增大还是减小。

4、三种带宽估计结果如何生效
事实上,WebRTC的拥塞控制算法总是综合考虑基于丢包率带宽估计 A s As As、(发送或接收端)基于时延的带宽估计 A r Ar Ar、用户配置的发送端最大码率 A m a x Amax Amax和最小码率 A m i n Amin Amin值,并根据如下公式得到最终的目标输出码率。
TargetBitrate=max[min(min( A s , A r ), A m a x ), A m i n ] \text{TargetBitrate=max[min(min($As$,$Ar$), $Amax$), $Amin$]} TargetBitrate=max[min(min(As,Ar), Amax), Amin]

总结:
WebRTC与QoS相关的知识点确实非常多,因为它追求的是几个互相矛盾的目标(低延时、少抖动、抗丢包),算法只能在几个目标中寻找平衡点,而不同网络之间的传输特性差异极大,且网络状态本身也是动态变化的,这就导致无法用一个简单的算法同时满足各种完全不同的网络环境,反而需要软件能够自适应网络状态变化,自动调节算法,动态保持一个最优的时延、抖动、丢包平衡点。
为了保证QoS,WebRTC从编码、传输、解码的全流程都有针对性的处理,涉及的内容也非常多,这里通过一张图作为总结

翻译 A Google Congestion Control Algorithm