【项目实战】Java 开发 Kafka 消费者
博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO TOP红人
Java知识图谱点击链接:体系化学习Java(Java面试专题)
感兴趣的同学可以收藏关注下 ,不然下次找不到哟
✊✊ 感觉对你有帮助的朋友,可以给博主一个三连,非常感谢

文章目录
- 1、什么是 Kafka 消费者
- 2、 Java 如何使用 Kafka 消费者
- 3、SpringBoot 如何使用 Kafka 消费者/ 消费者组
- 4、@KafkaListener 参数说明
- 5、你必须知道的 @KafkaListener 实现原理
- 写在最后
1、什么是 Kafka 消费者
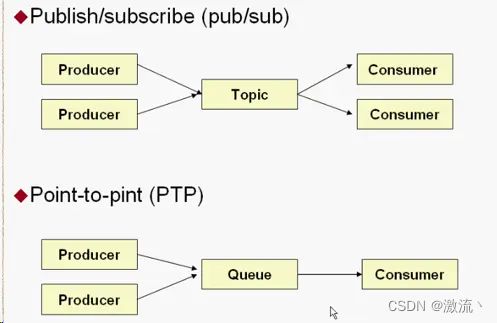
Kafka 消费者是使用 Apache Kafka 消息队列系统的应用程序,它们用于从 Kafka 主题(topics)中读取消息。消费者订阅一个或多个主题,并从这些主题中拉取消息以进行处理。消费者可以以不同的方式配置,例如,可以指定消息的偏移量(offset)以从特定位置开始消费消息,还可以指定消费者组(consumer group)以实现消息的分组消费。消费者是 Kafka 中的重要组成部分,用于实现可靠的消息传递和数据处理。
2、 Java 如何使用 Kafka 消费者
首先引入依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.8.0version>
dependency>
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
<version>2.7.2version>
dependency>
以下代码创建一个简单的 Kafka 消费者:
package com.pany.camp.kafka;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
*
* @description: Kafka 消费者
* @copyright: @Copyright (c) 2022
* @company: Aiocloud
* @author: pany
* @version: 1.0.0
* @createTime: 2023-06-26 18:04
*/
public class KafkaConsumerExample {
private static final String TOPIC_NAME = "test-topic";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String GROUP_ID = "test-group";
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> {
System.out.printf("Received message: key=%s, value=%s, partition=%d, offset=%d\n",
record.key(), record.value(), record.partition(), record.offset());
});
}
}
}
“test-topic” 替换为你要消费的 Kafka 主题的名称,将 “localhost:9092” 替换为 Kafka 服务器的地址,将 “test-group” 替换为你的消费者组的唯一标识符。
3、SpringBoot 如何使用 Kafka 消费者/ 消费者组
消费者是通过 @KafkaListener 监听消息获取的,案例如下:
package com.pany.camp.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
*
* @description: kafka 消费者
* @copyright: @Copyright (c) 2022
* @company: Aiocloud
* @author: pany
* @version: 1.0.0
* @createTime: 2023-07-14 8:31
*/
@Component
public class kafkaConsumerListenerExample {
@KafkaListener(topics = "your_topic_name", groupId = "your_consumer_group_id")
public void consume(ConsumerRecord<?, ?> record) {
Optional<?> value = Optional.ofNullable(record.value());
// 进行消息处理逻辑
System.out.println("print message: " + value);
}
}
4、@KafkaListener 参数说明
@KafkaListener 用于监听 Kafka 主题中的消息,并在消息到达时执行相应的逻辑。
KafkaListener 注解有以下参数:
- id :监听器的唯一标识符。如果未指定,默认为方法的名称。
- topics :要监听的 Kafka 主题列表。可以监听多个主题,以逗号分隔。
- topicPattern :要监听的 Kafka 主题的正则表达式模式。与 topics 参数互斥,只能选择其中一个。
- containerFactory :用于创建 Kafka 容器的工厂类。如果未指定,默认使用默认工厂类。
- concurrency :并发处理消息的线程数。默认为 1。
- groupId :Kafka 消费者组的标识符。如果未指定,默认为应用程序的名称。
- clientIdPrefix :Kafka 消费者的客户端 ID 的前缀。如果未指定,默认为空。
- autoStartup :是否在应用程序启动时自动启动监听器。默认为 true。
- properties :Kafka 消费者的其他属性配置。
这些参数可以根据具体需求进行配置,以便创建适合的 Kafka 消息监听器。
5、你必须知道的 @KafkaListener 实现原理
KafkaListener 的底层实现原理涉及到 Spring Kafka 的注解处理器和 Kafka 消费者的集成。
注解的处理过程:
1. 注解处理器:
- Spring Kafka 框架中的注解处理器负责解析和处理 KafkaListener 注解。
- 在应用程序启动时,注解处理器会扫描所有的 Bean,查找带有 KafkaListener 注解的方法,并为每个方法创建一个 KafkaMessageListenerContainer 对象。
- 注解处理器会解析注解上的参数,例如指定的 Kafka 主题、消费者组 ID、反序列化器等。
2. 创建 Kafka 消费者:
- KafkaMessageListenerContainer 对象负责创建和管理底层的 Kafka 消费者。
- 根据注解上的参数,KafkaMessageListenerContainer 会创建一个或多个 Kafka 消费者,并配置消费者的相关属性。
- 消费者的创建和配置是通过 Apache Kafka 客户端库实现的,Spring Kafka 提供了对客户端库的封装和集成。
3. 消费 Kafka 消息:
- KafkaMessageListenerContainer 对象会启动 Kafka 消费者,开始轮询 Kafka 服务器以获取新的消息。
- 当有消息到达时,消费者会将消息传递给带有 KafkaListener 注解的方法进行处理。
- 方法可以根据业务逻辑进行相应的处理,例如解析消息内容、进行数据处理、调用其他服务等。
- 处理完成后,可以选择确认消息的消费,或者抛出异常以触发重试机制。
4. 并发处理消息:
- KafkaMessageListenerContainer 支持并发处理消息,可以通过配置 concurrency 参数来指定处理消息的线程数。
- 如果设置了并发处理,KafkaMessageListenerContainer 会为每个线程创建一个独立的 Kafka 消费者,并通过分区分配策略将消息分配给不同的线程进行处理。
- 这样可以提高消息处理的吞吐量。
写在最后
Kafka消费者的优点是具有高吞吐量和低延迟的特性,能够处理大规模的消息流。它支持水平扩展,可以通过增加消费者实例来提高处理能力。此外,Kafka消费者还具有消息的持久化和可靠性保证,能够处理高并发的消息消费。
然而,Kafka消费者也存在一些缺点。首先,Kafka消费者的配置和管理相对复杂,需要关注许多参数和细节。其次,Kafka消费者在处理消息时需要自行管理偏移量,确保消息的有序性和正确性,这对于开发人员来说可能需要额外的工作。此外,Kafka消费者对于实时性要求较高的场景可能不太适用,因为消息的传递可能存在一定的延迟。
总的来说,Kafka消费者适用于需要处理大规模消息流的场景,对于数据的可靠性和持久化有较高要求,但在配置和管理上需要额外的注意和工作。
本文由激流原创,原创不易,希望大家关注、点赞、收藏,给博主一点鼓励,感谢!!!