Dinky实践系列之FlinkCDC整库实时入仓入湖
摘要:本文介绍了 Dinky 功能实践系列的 Flink CDC 整库实时入仓入湖的分析。内容包括:
-
前言
-
环境要求
-
源库准备
-
整库同步参数介绍
-
整库入湖 Hudi
-
整库入仓 StarRocks
-
整库入库 MySQL
-
整库同步 Kafka
-
整库入库 PostgreSQL
-
整库入仓 ClickHouse
-
总结
一、前言
Dinky 整库同步发布已经有一段时间,通过阅读本文,您将会熟悉 Dinky 整库同步的用法。为此Dinky 社区准备了整库同步的系列,方便大家快速上手使用。
因业界中 Sink 端的库较多,特意选择了现在比较通用或者流行的库做为演示。并选择了 mysql-cdc做为 Source 端实现整库同步到 各 Sink 端。当然通过阅读本文,如果你的 Source 端 oracle-cdc,那么将 mysql-cdc替换即可。
二、环境要求
| 软件 | 版本 |
| CDH | 6.2.0 |
| Hadoop | 3.0.0-cdh6.2.0 |
| Hive | 2.1.1-cdh6.2.0 |
| Hudi | 0.11.1 |
| Flink | 1.13.6 |
| Flink CDC | 2.2.1 |
| StarRocks | 2.2.0 |
| Dinky | 0.6.6-SNAPSHOT |
| MySQL | 5.7 |
| PostgreSQL | 13 |
| ClickHouse | 22.2.2.1(单机版) |
所需依赖
整库同步需要在 Flink下加载周围组件所需要的 Flink connector 即可。依赖如下:
# hive依赖包antlr-runtime-3.5.2.jarhive-exec-2.1.1-cdh6.2.0.jarlibfb303-0.9.3.jarflink-sql-connector-hive-2.2.0_2.12-1.13.6.jarhive-site.xml# hadoop依赖flink-shaded-hadoop-2-uber-3.0.0-cdh6.3.0-7.0.jar# Flink Starrrocks依赖flink-connector-starrocks-1.2.2_flink-1.13_2.12.jar# Hudi 依赖hudi-flink1.13-bundle_2.12-0.11.1.jar# Dinky hadoop依赖flink-shaded-hadoop-3-uber-3.1.1.7.2.8.0-224-9.0.jar# Dinky 整库同步依赖包dlink-client-1.13-0.6.5.jardlink-client-base-0.6.5.jardlink-common-0.6.5.jar# flink cdc依赖包flink-sql-connector-mysql-cdc-2.2.1.jar# mysql 驱动依赖mysql-connector-java-8.0.21.jar# kafka flink依赖flink-sql-connector-kafka_2.12-1.13.6.jar# postgresql jdbc依赖postgresql-42.2.14.jar# clickhouse 依赖clickhouse-jdbc-0.2.6.jarflink-connector-clickhouse-1.13.6.jar
说明
1.Hive 依赖包放置 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
2.Hadoop 依赖包放置 $FLINK_HOME/lib 下
3.Flink Starrrocks 依赖包放置 $FLINK_HOME/lib 和$DINKY_HOME/plugins 下
4.Hudi 依赖包放置 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
5.Dinky hadoop 依赖包放置 $DINKY_HOME/plugins 下(网盘或者群公告下载)
6.Dinky 整库同步依赖包放置 $FLINK_HOME/lib 下
7.Flink CDC 依赖包放置 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
8.MySQL 驱动依赖放置 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
9.Kafka Flink 依赖 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
10.PostgreSQL jdbc 依赖放置 $FLINK_HOME/lib 和$DINKY_HOME/plugins 下
11.ClickHouse 依赖放置 $FLINK_HOME/lib 和 $DINKY_HOME/plugins 下
以上依赖放入后,重启 Flink 集群和 Dinky。如果中间遇到一些jar包冲突,可自行根据报错解决相关冲突的包。
三、源库准备
MySQL 建表
如下sql脚本采用 Flink CDC 官网
# mysql建表语句(同步到Starocks)CREATE TABLE bigdata.products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512));ALTER TABLE bigdata.products AUTO_INCREMENT = 101;INSERT INTO bigdata.productsVALUES (default,"scooter","Small 2-wheel scooter"),(default,"car battery","12V car battery"),(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),(default,"hammer","12oz carpenter's hammer"),(default,"hammer","14oz carpenter's hammer"),(default,"hammer","16oz carpenter's hammer"),(default,"rocks","box of assorted rocks"),(default,"jacket","water resistent black wind breaker"),(default,"spare tire","24 inch spare tire");CREATE TABLE bigdata.orders (order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,order_date DATETIME NOT NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id INTEGER NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed) AUTO_INCREMENT = 10001;INSERT INTO bigdata.ordersVALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
四、整库同步参数介绍
对于 Dinky 整库同步的公共参数,在大多数 Sink 目标端都是适用的。除个别 Sink 目标端,因底层实现方式不同,所以不能一概而论。如 Hudi。公共参数依据 Dinky 提供的语法,如下:
| key | value | 上下游 |
| connector | mysql-cdc | source 端 |
| hostname | 主机名 | source 端 |
| port | 端口 | source 端 |
| username | 用户名 | source 端 |
| password | 密码 | source 端 |
| checkpoint | checkpoint 时间间隔 | source 端 |
| scan.startup.mode | 全量或增量读取 | source 端 |
| parallelism | 1 | source 端 |
| database-name | 数据库名称 | source 端 |
| table-name | 表名称,支持正则 | source 端 |
| sink.* | *代表 sink 端所有参数 | sink 端 |
提示: 对于sink.*,在使用的过程中需要注意的是,sink是必须要写的,'*' 星号代表的是所有sink端的参数,比如原生 Flink Sink建表语句的连接器写"connector",在 Dinky 整库同步语法中必须是"sink.connector"。所有的 Sink 端必须参照此语法规范。
五、整库入湖 Hudi
作业脚本
EXECUTE CDCSOURCE demo_hudi2 WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '4406','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','database-name'='bigdata','table-name'='bigdata\.products,bigdata\.orders','sink.connector'='hudi','sink.path'='hdfs://nameservice1/data/hudi/${tableName}','sink.hoodie.datasource.write.recordkey.field'='${pkList}','sink.hoodie.parquet.max.file.size'='268435456',--'sink.write.precombine.field'='gmt_modified','sink.write.tasks'='1','sink.write.bucket_assign.tasks'='2','sink.write.precombine'='true','sink.compaction.async.enabled'='true','sink.write.task.max.size'='1024','sink.write.rate.limit'='3000','sink.write.operation'='upsert','sink.table.type'='COPY_ON_WRITE','sink.compaction.tasks'='1','sink.compaction.delta_seconds'='20','sink.compaction.async.enabled'='true','sink.read.streaming.skip_compaction'='true','sink.compaction.delta_commits'='20','sink.compaction.trigger.strategy'='num_or_time','sink.compaction.max_memory'='500','sink.changelog.enabled'='true','sink.read.streaming.enabled'='true','sink.read.streaming.check.interval'='3','sink.hive_sync.skip_ro_suffix' = 'true','sink.hive_sync.enable'='true','sink.hive_sync.mode'='hms','sink.hive_sync.metastore.uris'='thrift://bigdata1:9083','sink.hive_sync.db'='qhc_hudi_ods','sink.hive_sync.table'='${tableName}','sink.table.prefix.schema'='true')
创建并提交作业

查看 HDFS 目录及 Hive 表

创建 StarRocks Hudi 外部表
在创建外部表之前,在Starrocks上首先保证要将hdfs-site.xml文件分别部署到FE和BE节点的conf目录下。重启FE和BE节点。Hudi 外表是只读的,只能用于查询操作。当前支持 Hudi 的表类型为 Copy on write。
创建和管理 Hudi 资源
CREATE EXTERNAL RESOURCE "hudi0"PROPERTIES ("type" = "hudi","hive.metastore.uris" = "thrift://bigdata1:9083");SHOW RESOURCES;
创建 Hudi 外部表
CREATE EXTERNAL TABLE qhc_sta.orders (`order_id` int NULL COMMENT "",`order_date` datetime NULL COMMENT "",`customer_name` string NULL COMMENT "",`price` decimal(10, 5) NULL COMMENT "",`product_id` int NULL COMMENT "",`order_status` int NULL COMMENT "") ENGINE=HUDIPROPERTIES ("resource" = "hudi0","database" = "qhc_hudi_ods","table" = "bigdata_orders");CREATE EXTERNAL TABLE qhc_sta.products (id INT,name STRING,description STRING) ENGINE=HUDIPROPERTIES ("resource" = "hudi0","database" = "qhc_hudi_ods","table" = "bigdata_products");
查看 Hudi 外部表数据

六、整库入仓 StarRocks
作业脚本
EXECUTE CDCSOURCE jobname WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '3306','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'bigdata\.products,bigdata\.orders','sink.connector' = 'starrocks','sink.jdbc-url' = 'jdbc:mysql://192.168.0.4:19035','sink.load-url' = '192.168.0.4:18035','sink.username' = 'devuser','sink.password' = '123456','sink.sink.db' = 'qhc_ods','sink.table.prefix' = 'ods_','sink.table.lower' = 'true','sink.database-name' = 'qhc_ods','sink.table-name' = '${tableName}','sink.sink.properties.format' = 'json','sink.sink.properties.strip_outer_array' = 'true','sink.sink.max-retries' = '10','sink.sink.buffer-flush.interval-ms' = '15000','sink.sink.parallelism' = '1')
创建作业
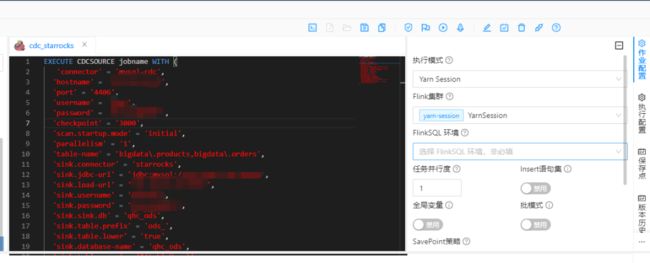
StarRocks 建表
CREATE TABLE qhc_ods.`ods_orders` (`order_id` largeint(40) NOT NULL COMMENT "",`order_date` datetime NOT NULL COMMENT "",`customer_name` varchar(65533) NULL COMMENT "",`price` decimal64(10, 5) NOT NULL COMMENT "",`product_id` bigint(20) NULL COMMENT "",`order_status` boolean NULL COMMENT "") ENGINE=OLAPPRIMARY KEY(`order_id`)COMMENT "OLAP"DISTRIBUTED BY HASH(`order_id`) BUCKETS 10PROPERTIES ("replication_num" = "3","colocate_with" = "qhc","in_memory" = "false","storage_format" = "DEFAULT");CREATE TABLE qhc_ods.`ods_products` (`id` largeint(40) NOT NULL COMMENT "",`name` varchar(65533) NOT NULL COMMENT "",`description` varchar(65533) NULL COMMENT "") ENGINE=OLAPPRIMARY KEY(`id`)COMMENT "OLAP"DISTRIBUTED BY HASH(`id`) BUCKETS 10PROPERTIES ("replication_num" = "3","colocate_with" = "qhc","in_memory" = "false","storage_format" = "DEFAULT");
查看 StarRocks 表
查看Starrocks表中数据是不是为空

提交 Flink 整库同步作业
再次查看 StarRocks

七、整库入库 MySQL
作业脚本
EXECUTE CDCSOURCE cdc_mysql2 WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '3306','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'bigdata\.products,bigdata\.orders','sink.connector' = 'jdbc','sink.url' = 'jdbc:mysql://192.168.0.5:3306/test?characterEncoding=utf-8&useSSL=false','sink.username' = 'root','sink.password' = '123456','sink.sink.db' = 'test','sink.table.prefix' = 'test_','sink.table.lower' = 'true','sink.table-name' = '${tableName}','sink.driver' = 'com.mysql.jdbc.Driver','sink.sink.buffer-flush.interval' = '2s','sink.sink.buffer-flush.max-rows' = '100','sink.sink.max-retries' = '5')
创建作业

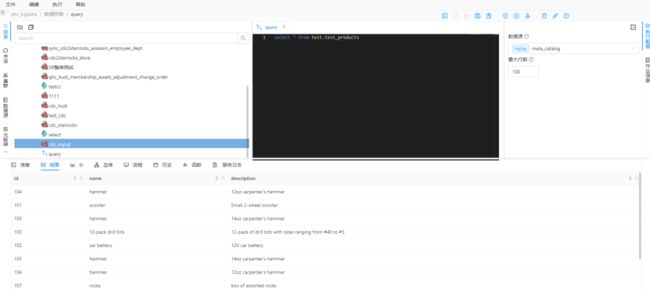
创建 MySQL 表
drop table test.test_products;CREATE TABLE test.test_products (id INTEGER NOT NULL ,name VARCHAR(255) NOT NULL,description VARCHAR(512));drop table test.test_orders;CREATE TABLE test.test_orders (order_id INTEGER NOT NULL ,order_date DATETIME NOT NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id INTEGER NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed);
提交 Flink 整库同步作业

查看 MySQL 数据
八、整库同步 Kafka
作业脚本
# cdc作业EXECUTE CDCSOURCE cdc_kafka WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '3306','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'bigdata\.products,bigdata\.orders','sink.connector'='datastream-kafka','sink.topic'='cdctest','sink.brokers'='bigdata2:9092,bigdata3:9092,bigdata4:9092')
创建作业

创建 Kafka Topic
创建 topic 可忽略,Dinky 整库同步会自动创建。
# 创建topic./bin/kafka-topics.sh \--create \--zookeeper bigdata2:2181,bigdata3:2181,bigdata4:2181 \--replication-factor 3 \--partitions 1 \--topic cdctest# 查看topic./bin/kafka-topics.sh --list \--zookeeper bigdata2:2181,bigdata3:2181,bigdata4:2181
提交 Flink 整库同步作业
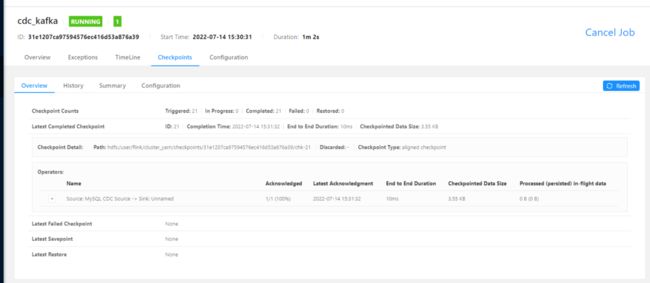
查看消费者
查看是否2张表数据
./bin/kafka-console-consumer.sh --bootstrap-server bigdata2:9092,bigdata3:9092,bigdata4:9092 --topic cdctest --from-beginning --group test_id九、整库入库 PostgreSQL
作业脚本
EXECUTE CDCSOURCE cdc_postgresql5 WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '3306','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'bigdata\.products,bigdata\.orders','sink.connector' = 'jdbc','sink.url' = 'jdbc:postgresql://192.168.0.5:5432/test','sink.username' = 'test','sink.password' = '123456','sink.sink.db' = 'test','sink.table.prefix' = 'test_','sink.table.lower' = 'true','sink.table-name' = '${tableName}','sink.driver' = 'org.postgresql.Driver','sink.sink.buffer-flush.interval' = '2s','sink.sink.buffer-flush.max-rows' = '100','sink.sink.max-retries' = '5')
创建作业
创建 PostgreSQL 表
CREATE schema test;drop table test.test_products;CREATE TABLE test.test_products (id INTEGER UNIQUE NOT NULL ,name VARCHAR(255) NOT NULL,description VARCHAR(512));drop table test.test_orders;CREATE TABLE test.test_orders (order_id INTEGER UNIQUE NOT NULL ,order_date timestamp NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NULL,product_id INTEGER NULL,order_status INTEGER NOT NULL -- Whether order has been placed);
提交 Flink 整库同步作业
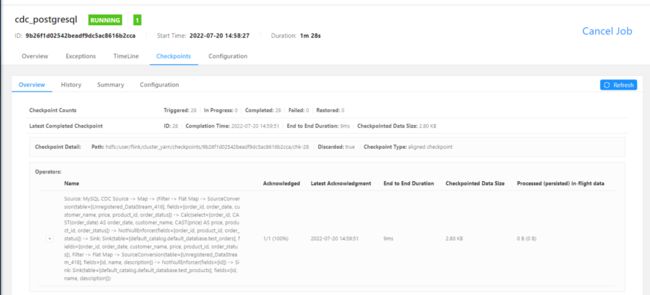
查看 PostgreSQL 数据
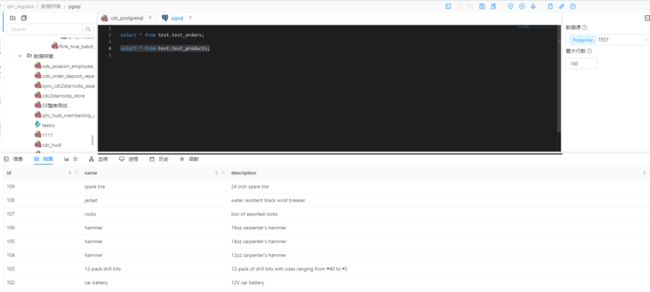
十、整库入仓 ClickHouse
作业脚本
EXECUTE CDCSOURCE cdc_clickhouse WITH ('connector' = 'mysql-cdc','hostname' = '192.168.0.4','port' = '4406','username' = 'root','password' = '123456','checkpoint' = '3000','scan.startup.mode' = 'initial','parallelism' = '1','table-name' = 'bigdata\.products,bigdata\.orders','sink.connector' = 'clickhouse','sink.url' = 'clickhouse://192.168.0.5:8123','sink.username' = 'default','sink.password' = '123456','sink.sink.db' = 'test','sink.table.prefix' = 'test_','sink.table.lower' = 'true','sink.database-name' = 'test','sink.table-name' = '${tableName}','sink.sink.batch-size' = '500','sink.sink.flush-interval' = '1000','sink.sink.max-retries' = '3')
创建作业
创建 ClickHouse 表
# 创建语句为本地表create database test;drop table test.test_products;CREATE TABLE test.test_products (id Int64 NOT NULL ,name String NOT NULL,description String)ENGINE = MergeTree()ORDER BY idPRIMARY KEY id;drop table test.test_orders;CREATE TABLE test.test_orders (order_id Int64 NOT NULL ,order_date DATETIME NOT NULL,customer_name String NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id Int64 NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed)ENGINE = MergeTree()ORDER BY order_idPRIMARY KEY order_id;
提交 Flink 整库同步作业

查看 ClickHouse 数据
