OpenMP与C++:事半功倍地获得多线程的好处
来源:IIEEG 01-28-2011
在并行计算领域有一个广为流传的笑话——并行计算是未来之事并且永远都是。这个小笑话几十年来一直都是对的。一种类似的观点在计算机架构社区中流传,处理器时钟速度的极限似乎近在眼前,但时钟速度却一直在加快。多核革命是并行社区的乐观和架构社区的悲观的冲突。
现在主流的CPU厂商开始从追求时钟频率转移到通过多核处理器来增加并行支持。原因很简单:把多个CPU内核封装在一个芯片里可以让双核单处理器系统就像双处理器系统一样、四核单处理器系统像四处理器系统一样。这一实用方法让CPU厂商在能够提供更强大的处理器的同时规避了加速频率的诸多障碍。
到此为止这听起来是一个好消息,但事实上如果你的程序没有从多核里获取优势的话,它并不会运行得更快。这就是OpenMP的用武之地了。OpenMP可以帮助C++开发者更快地开发出多线程应用程序。
在这短小的篇幅里完整讲述OpenMP这个大而强的API库的相关内容是不可能的。因此,本文仅作一些初始介绍,通过示例让你能够快速地应用OpenMP的诸多特性编写多线程应用程序。如果你希望阅读更深入的内容,我们建议你去OpenMP的网站看看。
在Visual C++中使用OpenMP
OpenMP标准作为一个用以编写可移植的多线程应用程序的API库,规划于1997年。它一开始是一个基于Fortran的标准,但很快就支持C和C++了。当前的版本是OpenMP 2.0(译者注:最新版本已经是2.5版), Visual C++ 2005和XBox360平台都完全支持这一标准。
在我们开始编码之前,你需要知道如何让编译器支持OpenMP。Visual C++ 2005提供了一个新的/openmp开关来使能编译器支持OpenMP指令。(你也可以通过项目属性页来使能OpenMP指令。点击配置属性页,然后[C/C++],然后[语言],选中OpenMP支持。)当/openmp参数被设定,编译器将定义一个标识符_OPENMP,使得可以用#ifndef _OPENMP来检测OpenMP是否可用。
OpenMP通过导入vcomp.lib来连接应用程序,相应的运行时库是vcomp.dll。Debug版本导入的连接库和运行时库(分别为vcompd.lib和vcompd.dll)有额外的错误消息,当发生异常操作时被发出以辅助调试。记住尽管Xbox360平台支持静态连接OpenMP,但Visual C++并不支持。
OpenMP中的并行
OpenMP应用程序刚运行时只有一条线程,这个线程我们叫它主线程。当程序执行时,主线程生成一组线程(包括主线程),随着应用程序执行可能会有一些区域并行执行。在并行结束后,主线程继续执行,其它线程被挂起。在一个并行区域内能够嵌套并行区域,此时原来的线程就成为它所拥有的线程组的主线程。嵌套的并行区域能够再嵌套并行区域。
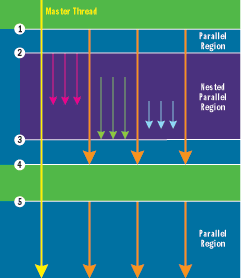
(图1)OpenMP并行段
图1展示了OpenMP如何并行工作。在最左边黄色的线是主线程,之前这一线程就像单线程程序那样运行,直到在执行到点1——它的第一个并行区域。在并行区域主线程生成了一个线程组(参照黄色和桔黄色的线条),并且这组线程同时运行在并行区域。
在点2,有4条线程运行在并行区域并且在嵌套并行区域里生成了新的线程组(粉红、绿和蓝)。黄色和桔黄色进程分别作为他们生成的线程组的主线程。记住每一个线程都可以在不同的时间点生成一个新的线程组,即便它们没有遇到嵌套并行区域。
在点3,嵌套的并行区域结束,每一个嵌套线程在并行区域同步,但并非整个区域的嵌套线程都同步。点4是第一个并行区域的终点,点5则开始了一个新的并行区域。在点5开始的新的并行区域,每一个线程从前一并行区域继承利用线程本地数据。
现在你基本了解了执行模型,可以真正地开始练习并行应用程序开发了。
OpenMP的构成
OpenMP易于使用和组合,它仅有的两个基本构成部分:编译器指令和运行时例程。OpenMP编译器指令用以告知编译器哪一段代码需要并行,所有的OpenMP编译器指令都 以#pragma omp开始。就像其它编译器指令一样,在编译器不支持这些特征的时候OpenMP指令将被忽略。
OpenMP运行时例程原本用以设置和获取执行环境相关的信息,它们当中也包含一系列用以同步的API。要使用这些例程,必须包含OpenMP头文件——omp.h。如果应用程序仅仅使用编译器指令,你可以忽略omp.h。
为一个应用程序增加OpenMP并行能力只需要增加几个编译器指令或者在需要的地方调用OpenMP函数。这些编译器指令的格式如下:
#pragma omp [clause[ [,] clause]…]
dierctive(指令)包含如下几种:parallel,for,parallel for,section,sections,single,master,criticle,flush,ordered和atomic。这些指令指定要么是用以工作共享要么是用以同步。本文将讨论大部分的编译器指令。
对于directive(指令)而言clause(子句)是可选的,但子句可以影响到指令的行为。每一个指令有一系列适合它的子句,但有五个指令(master,cirticle,flush,ordered和atomic)不能使用子句。
指定并行
尽管有很多指令,但易于作为初学用例的只有极少数的一部分。最常用并且最重要的指令是parallel。这条指令为动态长度的结构化程序块创建一个并行区域。如:
#pragma omp [clause[ [,] clause]…]
structured-block
这条指令告知编译器这一程序块应被多线程并行执行。每一条指令都执行一样的指令流,但可能不是完全相同的指令集合。这可能依赖于if-else这样的控制流语句。
这里有一个惯常使用的“Hello, World!”程序:
#pragma omp parallel
{
printf("Hello World\n");
}
在一个双处理器系统上,你可能认为输入出下:
Hello World
Hello World
但你可能得到的输出如下:
HellHell oo WorWlodrl
d
出现这种情况是因为两条线程同时并行运行并且都在同一时间尝试输出。任何时候超过一个线程尝试读取或者改变共享资源(在这里共享资源是控制台窗口),那就可能会发生紊乱。这是一种非确定性的bug并且难以查出。程序员有责任让这种情况不会发生,一般通过使用线程锁或者避免使用共享资源来解决。
现在来看一个比较实用的例子——计算一个数组里两个值的平均值并将结果存放到另一个数组。这里我们引入一个新的OpenMP指令:#pragma omp parallel for。这是一个工作共享指令。工作共享指令并不产生并行,#pragma omp for工作共享指令告诉OpenMP将紧随的for循环的迭代工作分给线程组并行处理:
#pragma omp parallel
{
#pragma omp for
for(int i = 1; i < size; ++i)
x[i] = (y[i-1] + y[i+1])/2;
}
在这个例子中,设size的值为100并且运行在一个四处理器的计算机上,那么循环的迭代可能分配给处理器p1迭代1-25,处理器p2迭代26-50,处理器p3迭代51-75,处理器p4迭代76-99。在这里假设使用静态调度的调度策略,我们将在下文讨论更深层次的调度策略。
还有一点需要指出的是这一程序在并行区域的结束处需要同步,即所有的线程将阻塞在并行区域结束处,直到所有线程都完成。
如果前面的代码没有使用#pragma omp for指令,那么每一个线程都将完全执行这个循环,造成的后果就是线程冗余计算:
#pragma omp parallel
{
for(int i = 1; i < size; ++i)
x[i] = (y[i-1] + y[i+1])/2;
}
因为并行循环是极常见的的可并行工作共享结构,所以OpenMP提供了一个简短的写法用以取代在#pragma omp parallel后面紧跟#pragma omp for的形式:
#pragma omp parallel for
for(int i = 1; i < size; ++i)
x[i] = (y[i-1] + y[i+1])/2;
你必须确保没有循环依赖,即循环中的某一次迭代不依赖于其它迭代的结果。例如下面两个循环就有不同的循环依赖问题:
for(int i = 1; i <= n; ++i) // Loop (1)
a[i] = a[i-1] + b[i];
for(int i = 0; i < n; ++i) // Loop (2)
x[i] = x[i+1] + b[i];
并行的Loop1的问题是因为当执行第i层迭代时需要用到i-1次迭代的结果,这是迭代i到i-1的依赖。并行的Loop2同样有问题,尽管原因有些不同。在这个循环中能够在计算x[i-1]的值之前计算x[i]的值,但在这样并行的时候不能再计算x[i-1]的值,这是迭代i-1到i的依赖。
当并行执行循环的时候必须确保没有循环依赖。当没有循环依赖的时候,编译器将能够以任意的次序执行迭代,甚至在并行中也一样。这是一个编译器并不检测的重要需求。你应该有力地向编译器断言将要并行执行的循环中没有循环依赖。如果一个循环存在循环依赖而你告诉编译器要并行执行它,编译器仍然会按你说的做,但结果应该是错误的。
另外,OpenMP对在#pragma omp for或#pragma omp parallel for里的循环体有形式上的限制,循环必须使用下面的形式:
for([integer type] i = loop invariant value;
i {<,>,=,<=,>=} loop invariant value;
i {+,-}= loop invariant value)
这样OpenMP才能知道在进入循环时需要执行多少次迭代。
OpenMP和Win32线程比较
当使用Windows API进行线程化的时候,用#pragma omp parallel为例来比较它们有利于更好地比较异同。从图2可见为达到同样的效果Win32线程需要更多的代码,并且有很多幕后魔术般的细节难以了解。例如ThreadData的构造函数必须指定每一个线程被调用时开始和结束的值。OpenMP自动地掌管这些细节,并额外地给予程序员配置并行区域和代码的能力。
DWORD ThreadFn(void* passedInData)
{
ThreadData *threadData = (ThreadData *)passedInData;
for(int i = threadData->start; i < threadData->stop; ++i )
x[i] = (y[i-1] + y[i+1]) / 2;
return 0;
}
void ParallelFor()
{
// Start thread teams
for(int i=0; i < nTeams; ++i)
ResumeThread(hTeams[i]);
// ThreadFn implicitly called here on each thread
// Wait for completion
WaitForMultipleObjects(nTeams, hTeams, TRUE, INFINITE);
}
int main(int argc, char* argv[])
{
// Create thread teams
for(int i=0; i < nTeams; ++i)
{
ThreadData *threadData = new ThreadData(i);
hTeams[i] = CreateThread(NULL, 0, ThreadFn, threadData,
CREATE_SUSPENDED, NULL);
}
ParallelFor(); // simulate OpenMP parallel for
// Clean up
for(int i=0; i < nTeams; ++i)
CloseHandle(hTeams[i]);
}
(图2)Win32多线程编程
共享数据与私有数据
在编写并行程序的时候,理解什么数据是共享的、什么数据是私有的变得非常重要——不仅因为性能,更因为正确的操作。OpenMP让共享和私有的差别显而易见,并且你能手动干涉。
共享变量在线程组内的所有线程间共享。因此在并行区域里某一条线程改变的共享变量可能被其它线程访问。反过来说,在线程组的线程都拥有一份私有变量的拷贝,所以在某一线程中改变私有变量对于其它线程是不可访问的。
默认地,并行区域的所有变量都是共享的,除非如下三种特别情况:一、在并行for循环中,循环变量是私有的。如图3里面的例子,变量i是私有的,变量j默认是共享的,但使用了firstprivate子句将其声明为私有的。
float sum = 10.0f;
MatrixClass myMatrix;
int j = myMatrix.RowStart();
int i;
#pragma omp parallel
{
#pragma omp for firstprivate(j) lastprivate(i) reduction(+: sum)
for(i = 0; i < count; ++i)
{
int doubleI = 2 * i;
for(; j < doubleI; ++j)
{
sum += myMatrix.GetElement(i, j);
}
}
}
(图3)OpenMP子句与嵌套for循环
二、并行区域代码块里的本地变量是私有的。在图3中,变量doubleI是一个私有变量——因为它声明在并行区域。任一声明在myMatrix::GetElement里的非静态变量和非成员变量都是私有的。
三、所有通过private,firstprivate,lastprivate和reduction子句声明的变量为私有变量。在图3中变量i,j和sum是线程组里每一个线程的私有变量,它们将被拷贝到每一个线程。
这四个子句每个都有一序列的变量,但它们的语义完全不同。private子句说明变量序列里的每一个变量都应该为每一条线程作私有拷贝。这些私有拷贝将被初始化为默认值(使用适当的构造函数),例如int型的变量的默认值是0。
firstprivate有着与private一样的语义外,它使用拷贝构造函数在线程进入并行区域之前拷贝私有变量。
lastprivate有着与private一样的语义外,在工作共享结构里的最后一次迭代或者代码段执行之后,lastprivate子句的变量序列里的值将赋值给主线程的同名变量,如果合适,在这里使用拷贝赋值操作符来拷贝对象。
reduction与private的语义相近,但它同时接受变量和操作符(可接受的操作符被限制为图4列出的这几种之一),并且reduction变量必须为标量变量(如浮点型、整型、长整型,但不可为std::vector,int[]等)。reduction变量初始化为图4表中所示的值。在代码块的结束处,为变量的私有拷贝和变量原值一起应用reduction操作符。
(图4)Reductoin操作符
在图3的例子中,sum对应于每一个线程的私有拷贝的值在后台被初始化为0.0f(记住图4表中的规范值为0,如果数据类型为浮点型就转化为0.0f。)在#pragma omp for代码块完成后,线程为所有的私有sum和原值做+操作(sum的原值在例子中是10.0f),再把结果赋值给原本的共享的sum变量。
非循环并行
OpenMP经常用以循环层并行,但它同样支持函数层并行,这个机制称为OpenMP sections。sections的结构是简明易懂的,并且很多例子都证明它相当有用。
现在来看一下计算机科学里一个极其重要的算法——快速排序(QuickSort)。在这里使用的例子是为一序列整型数进行递归的快速排序。为了简单化,我们不使用泛型模板版本,但其仍然可以表达OpenMP的思想。图5的代码展示了如何在快速排序的主要函数中应用sections(为简单起见我们忽略了划分函数)。
void QuickSort (int numList[], int nLower, int nUpper)
{
if (nLower < nUpper)
{
// create partitions
int nSplit = Partition (numList, nLower, nUpper);
#pragma omp parallel sections
{
#pragma omp section
QuickSort (numList, nLower, nSplit - 1);
#pragma omp section
QuickSort (numList, nSplit + 1, nUpper);
}
}
}
(图5)用OpenMP sections实现Quicksort
在这个例子中,第一个#pragma创建一个sections并行区域,每一个section用#pragma omp section前缀指令声明。每一个section都将被分配线程组里的单独线程执行,并且所有的sectoins能够确保一致并行。每一个并行section都递归地调用QuickSort。
就像在#pragma omp parallel for结构中一样,你有责任确保每一个section都不依赖于其它的sectoin,以使得它们能够并行执行。如果sectoins在没有同步存取资源的情况下改变了共享资源,将导致未定义结果。
在本例中像使用#pragma omp parallel for一样使用了简短的#pragma omp parallel sections。你也可以使用单独使用#pragma omp sections,后跟一个并行区域,就像你在#pragma omp for里做的一样。
在图5的程序实现中我们需要了解一些东西。首先,并行的sections递归调用,并行区域是支持递归调用的,特别在本例中并行sectoins就只是递归调用。因此如果使能并行嵌套机制,程序递归调用QuickSort时将产生大量新线程。这可能是也可能不是程序员所期望的,因为它导致产生相当多的线程。程序能够不使能并行嵌套机制以限制线程数量。不使能嵌套机制的时候,应用程序将在两条线程上递归调用QuickSort,而绝不会产生多于两条的线程。
另外,如果没有打开/openmp开关,编译器将生成完美的正确的串行快速排序实现。OpenMP的好处之一就是能够与不支持OpenMP的编译器中共存。