服务发布后接口超时?两个注解带你起飞
不知道大家有没有碰到这样的问题:每次服务发布,在启动之后的一小段时间内,各种接口出现一些或多或少的超时,就像下图所示,凸起的线条是刚发布的机器的接口耗时,不同颜色代表不同机器:
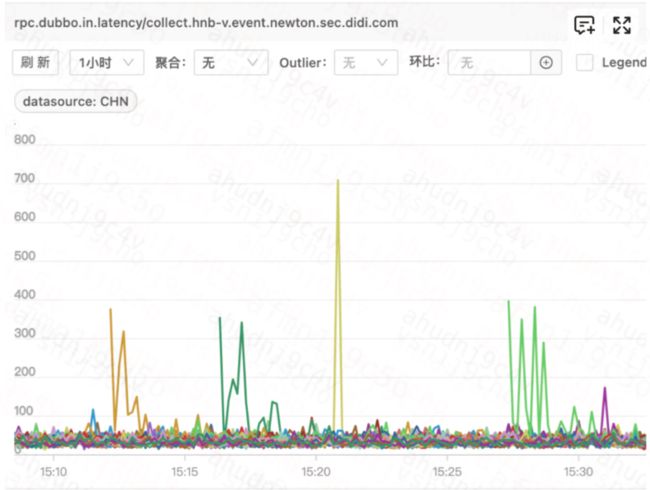
直到一段时间后,接口耗时才逐渐回到正常水位。往往在一些比较敏感的业务场景下,这种发布时的耗时突刺带来的影响,就不是那么可以简单容忍了。就拿实时风控场景来打个比方,黑灰产分子逐渐摸索到,你页面某个营销抢券活动,每个月底凌晨0点左右会出现小概率点击超时,掐指一算,哦,哥们儿你发布呢;好,一波突袭。
而刚好这部分超时的服务,就是上图中那一批正在发布的风控规则引擎服务。
因为发布后服务还在初始化一些资源,这部分黑产的抢券请求,到了风控规则引擎后出现了规则执行超时,网关层在接口限定的时间内没有拿到风控结果;网关层就会返回兜底的响应码,以示放行;而营销系统侧就会认为这是一笔合法的抢券请求:
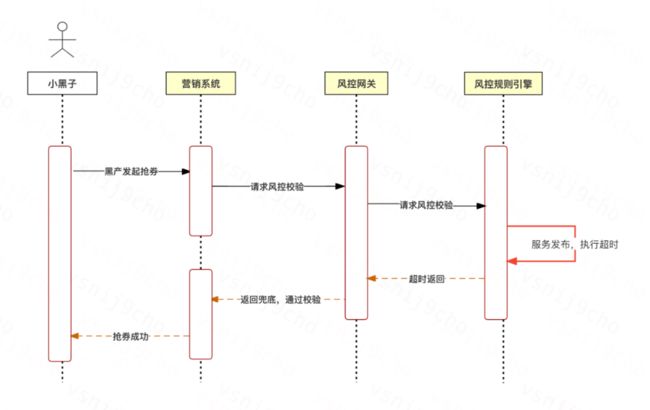
好了,游戏结束。黑产分子的钱捞到了,你的年终奖也打水漂了。
到目前为止,大家应该可以想到,这是一个关于服务预热的问题;而正如标题所说,我将试图通过本篇文章,帮助你改善服务启动时,接口耗时飙升的问题。
01
问题分析
启动后出现耗时抖动的原因是什么?相信不少技术人脑海里立马就会闪现出这些名词:类加载、对象创建、GC、连接池初始化、缓存的加载、JIT编译优化......
我们的应用中有很多代码和基础组件,都是基于懒加载的机制,在流量到达之后,再进行对应的资源加载,以保证应用本身可以尽可能快速启动。同时在JVM的运行过程中,对我们所写出来的代码进行一定手段的优化,例如C2编译、内存空间动态调整等,以便让应用启动后逐渐达到一个最佳的性能状态。而这些动作一般都会耗费一定的机器资源,甚至全局的停顿。
我们目前的风控规则引擎服务,是基于dubbo对风控网关提供服务的,而dubbo框架自身是带有启动预热功能的,先让我们来看一看dubbo源码中的预热逻辑(版本2.7.9):
(1)消费者先从url中拿到服务提供者的权重配置,默认是100。
(2)再从url中拿到服务提供者的上线时间戳,计算得到服务提供者的上线时间毫秒数。
(3)再从url拿到服务提供者预热的时间配置,默认10分钟。
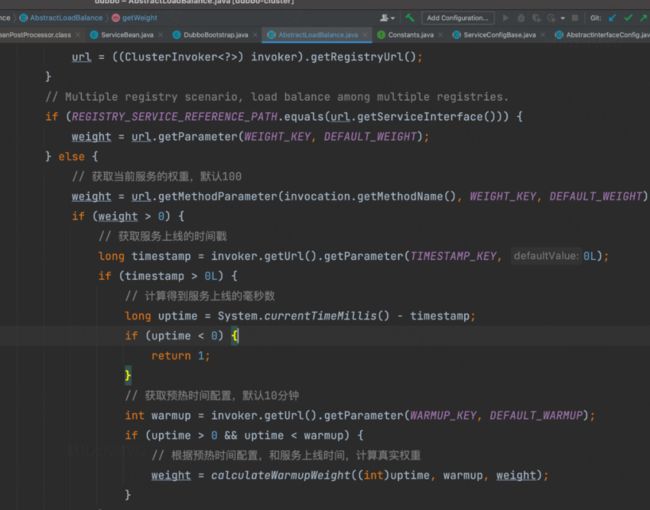
(4)再通过(上线时间毫秒数 / 10分钟毫秒数) * 100,就计算出了一个当前服务提供者的真实权重。

这里计算方式其实很简单,简单的说,服务运行时间越久,权重越高,直到达到配置的权重100。
如果服务提供者已运行 1 分钟,那么得到权重的结果为 10 ;如果服务提供者已运行 5 分钟,那么得到权重的结果为 50 ;如果服务提供者已运行 11 分钟,超过配置的预热时间阈值 10分 钟,那么将不会再计算,直接返回配置的权重100。
这样在客户端进行加权负载均衡路由的时候,选择到这台服务提供者的请求流量,在前10分钟内,就会基本呈现一个线性直线:
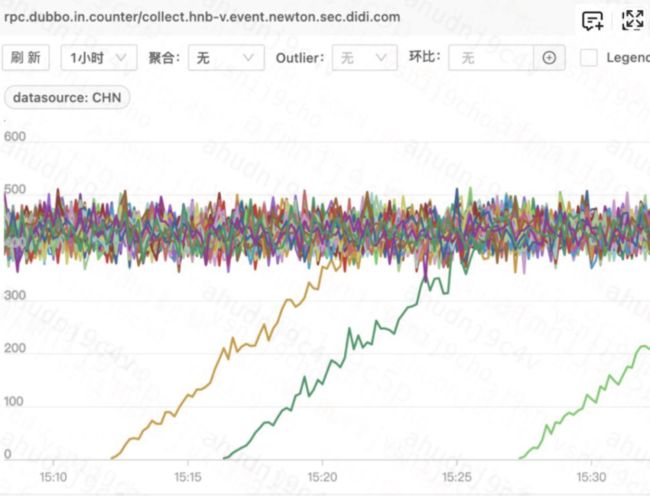
这种随着服务端上线时间,逐步给服务端增加流量权重的预热方案,对大部分后端服务来说没什么毛病,在服务端还没完全达到最佳性能的时候,先给予小比例的流量让服务端完成预热;等预热完成后,再恢复到正常流量。
但是还是存在对于风控这种敏感场景下的一个致命问题:刚启动的时候,放入的那些请求流量,因为受制于服务端本身一些JIT编译、连接池准备等预热工作没准备好,导致这部分流量显得 “很慢” ,会出现一些超时的case,进而导致一些资损。
02
解决思路
dubbo的预热机制是面向真实流量的,那我们完全可以在dubbo端口对外暴露之前,自己mock一部分压力流量来完成预热,那是不是就不会有上面影响真实流量的问题?
在基础组件中提供统一的注解和监听器,来自动完成这部分工作,这样对于不同的业务代码的侵入性就很低。
通过注解中不同的参数配置,来控制预热的强度和时间,从而满足不同业务接口的需要;同时这套预热组件,也能顺理成章地成为一个平台内部所有微服务的通用能力。
03
落地方案
1、我们在内部通用技术组件april中提供了一个新的注解:@Warmup,可以作用于接口方法上,属性列表:
concurrent:并行线程数,多少个线程发起压力预热,默认是1,单线程执行预热;如果大于1,采用多线程执行。
targetLatency:期待目标执行毫秒数,如果配置了就会达到目标延迟才停止。
maxCounts:接口最大预热次数,默认100次。
mockArgs:预热使用的模拟传入的参数列表,因为每次预热都是用的这些同样的参数列表,所以使用的参数数据建议是测试用的数据。
clusters:生效集群环境,取项目系统参数配置项app.cluster的值。如果值不为空,则预热只会在该集群生效。
其中targetLatency和maxCounts参数任意一个达到了阈值,就停止预热。
为什么基于注解来实现预热:
(1)对服务模块的代码侵入性低,只需要在原业务代码上添加注解。
(2)相对来说比较灵活,能做到方法级别预热。
(3)通用性强,能适配所有业务接口。
2、april组件中提供一个新的Spring application监听器:WarmupApplicationListener,优先级是 LOWEST_PRECEDENCE -2 ,在dubbo的启动类监听器DubboBootstrapApplicationListener之前执行。
这样就能保证预热发生在dubbo对外提供服务之前,被Spring自动触发自动预热。
3、底层执行流程:
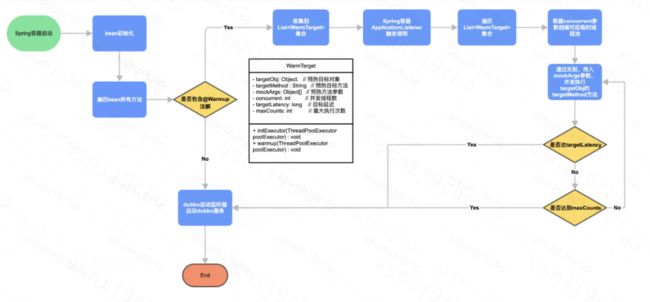
(1)在Spring进行实例化bean阶段,通过一个自定义的PeacefulTargetPostProcessor,完成对于所有bean的方法上的@Warmup注解的扫描,把每个带有@Warmup注解的方法,包装成一个带有预热目标方法、对象、参数列表、预热次数等信息的WarmTarget对象,收集到一个List集合。
(2)Spring容器实例化完所有的Bean对象后,发布容器刷新完成事件,WarmupApplicationListener监听到这个事件后,遍历List集合,并根据注解的concurrent参数创建对应的临时线程池。
(3)通过反射,基于注解传入的mockArgs参数,丢到临时线程池中,并发执行目标对象的目标方法。
(4)并在执行过程中,不断判断是否达到配置的预期方法执行耗时targetLatency,以及最大执行次数
maxCounts。
(5)所有方法预热完毕后,销毁预热临时线程池;随后Spring最后触发dubbo启动监听器,完成dubbo服务发布,正式对外接流。
04
效果检验
出于稳定性和当时的紧急程度等相关因素考虑,我们首先选取了另一个服务:数据特征执行服务,作为我们初次实验预热组件的对象。
未接入预热组件前,服务启动后,特征读取接口耗时:

选择单台机器实验,接入预热组件后,启动后接口耗时:

可以直观的看出来,接口耗时从原来的2.7s,降到了330ms左右,降低了将近一个数量级!
这个效果,看上去是不是还是很nice的?

但是转念一看,这个330ms,距离服务常稳运行时候的10ms左右的耗时,似乎还是有很大的距离。
是不是还是有一些隐藏在背后的东西,被我们忽略掉了?
05
扩展与优化
1、经过仔细观察服务的odin各项指标监控曲线,发现JVM垃圾回收Young GC的曲线,在预热之后的一段时间里,出现了比较大的波动:
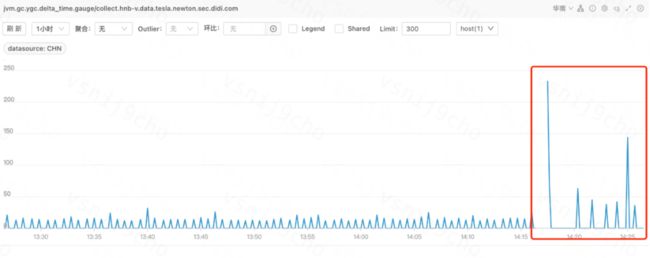
很容易推断出来,在我们的方案里,预热时会并发发起多次mock接口调用,期间创建了较多的对象,那在接下来的一段时间里,JVM就会触发频繁ygc,来回收掉这部分预热期间产生的无用对象。
于是我们尝试在预热完成后,除了释放上面提到的临时线程池,以及收集到WarmTarget之外,为了让整个服务轻装上阵,我们增加了一次强制系统fgc,用来在dubbo对外暴露服务之前,清空我们预热产生的垃圾对象:
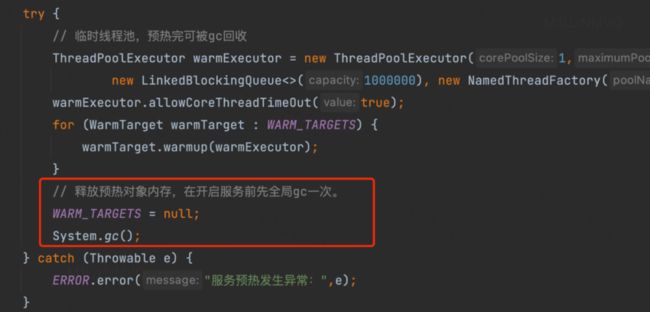
增加了强制gc之后,再暴露dubbo服务之后的耗时,降低到了180ms左右(再次感叹,垃圾回收果然是性能杀手):
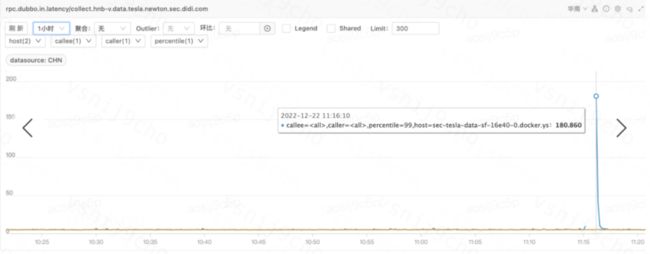
虽然相比原来的330ms已经降低不少,但是相比于我们服务常稳运行的10多ms左右,似乎还是有一小段路要走。
2、我们之前的目光一直停留在了方法内部执行的预热,但是放眼来看,我们这个服务接口本身是一个dubbo接口;那是不是意味着这个接口耗时,和dubbo服务端的链路执行耗时也有关系?
因为我们知道,dubbo底层在接收到客户端请求之后,具体执行的时候,会经过一系列的SPI接口创建实例,以及调用N多个Filter组件,最终才会走到我们的业务方法里:(那是不是有什么办法可以预热dubbo前面的这段spi+filter执行链路?)

同样的思路,我们在april-dubbo组件中,增加了一个DubboWarmupListener监听器,用来完成dubbo自身链路的预热,而预热的逻辑就是,在这个监听器里完成对于一个mock服务的循环调用,同样是在dubbo对外提供服务之前:
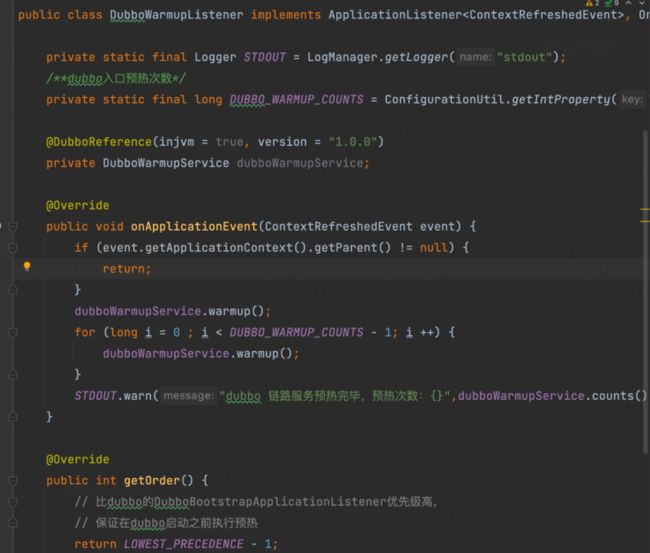
并且加入了一个新的注解:@EnableDubboWarmup ,来方便组件自动注入Spring。
再次发布到带台机器实验观察,最终耗时情况变成了这样:
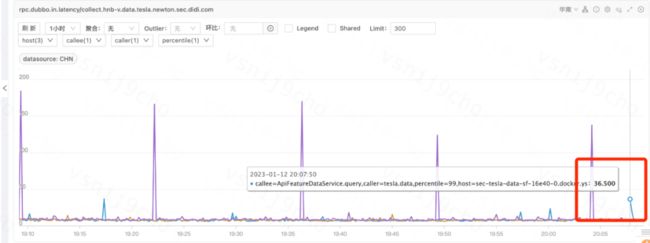
你没有看错,36ms。
虽然还没有完全达到常稳运行时的10ms左右,但36ms这个数字对于一个刚启动完的服务来说,对于业务服务侧的波动影响,基本已经是一个可以接受的阈值。
回过头来看,服务预热这件事情,似乎涉及到的知识点非常广泛,要是进一步深挖下去,仿佛平静的海面下,还有隐藏的巨兽.....
行至灯火阑珊处,开始翻查业内的服务预热相关的技术。
发现服务预热这件事情,在业内甚至有专门定制版的jdk来专门做这件事,底层是基于字节码持久化后,启动时重新加载实现的。
06
接入与交流
这套服务预热组件,目前已经收录到滴滴交易安全部的公共开发组件中。
有相关建议或者体验需要的小伙伴,欢迎在评论区交流,进一步推进服务预热组件的推广和开源。