性能飙升20倍!!! 超高性能协议框架fury完爆protostuff
简单介绍:
序列化框架是系统通信的基础组件,在大数据、AI 框架和云原生等分布式系统中广泛使用。当对象需要跨进程、跨语言、跨节点传输、持久化、状态读写、复制时,都需要进行序列化,其性能和易用性影响运行效率和开发效率。
Fury 是一个基于 JIT 动态编译和零拷贝的多语言序列化框架,支持 Java/Python/Golang/JavaScript/C++ 等语言,提供全自动的对象多语言 / 跨语言序列化能力。
而提到protostuff,就要先提到Protocol Buffer,它是谷歌出品的一种数据交换格式,独立于语言和平台,类似于json。Google提供了多种语言的实现:java、c++、go和python。对象序列化成Protocol Buffer之后可读性差,但是相比xml,json,它占用小,速度快。适合做数据存储或 RPC 数据交换格式,相对我们常用的json来说,Protocol Buffer门槛更高,因为需要编写.proto文件,再把它编译成目标语言,这样使用起来就很麻烦。但是现在有了protostuff之后,就不需要依赖.proto文件了,他可以直接对POJO进行序列化和反序列化,使用起来非常简单。
今天,我们来做下性能评测:
fury
官网:https://furyio.org
开源地址:https://github.com/alipay/fury
使用引入:
implementation 'org.furyio:fury-core:0.1.0-SNAPSHOT'
protostuff:
官网:https://protostuff.github.io/
开源地址:https://github.com/protostuff/protostuff
使用引入:
implementation group: 'io.protostuff', name: 'protostuff-core', version: '1.8.0'
implementation group: 'io.protostuff', name: 'protostuff-runtime', version: '1.8.0'
测试设备: win11, 8core,16g memory,
JDK:
openjdk version "11.0.16.1" 2022-08-16
OpenJDK Runtime Environment TencentKonaJDK (build 11.0.16.1+2)
OpenJDK 64-Bit Server VM TencentKonaJDK (build 11.0.16.1+2, mixed mode)
用游戏中高频调用的技能回包做样本,字节大小 为1112 bytes,
SkillFire_S2C_Msg[attackerId=1784915096,harmList={HarmDTO[curHp=2214090.5,dead=true,maxHp=7244422.0,real=23590,targetId=2009239345,type=61,value=17495.12],HarmDTO[curHp=1152855.2,dead=true,maxHp=6402139.5,real=46839,targetId=1188603823,type=88,value=54630.61],HarmDTO[curHp=1504246.4,dead=true,maxHp=8543909.0,real=98086,targetId=1233342584,type=8,value=97565.03],HarmDTO[curHp=5198943.5,dead=true,maxHp=1997015.8,real=35577,targetId=1947070362,type=85,value=45887.67],HarmDTO[curHp=1639543.4,dead=false,maxHp=9637510.0,real=71485,targetId=1965108670,type=79,value=54457.5],HarmDTO[curHp=3545105.5,dead=true,maxHp=8496628.0,real=21708,targetId=1602879009,type=46,value=44459.16],HarmDTO[curHp=8786076.0,dead=false,maxHp=1442285.5,real=77398,targetId=1120550865,type=14,value=93219.53],HarmDTO[curHp=4911716.5,dead=false,maxHp=2528763.5,real=10983,targetId=2108488986,type=58,value=77973.16],HarmDTO[curHp=2909037.8,dead=false,maxHp=2109388.8,real=94957,targetId=1565205071,type=47,value=61426.68]},index=83,param1={4,2,0,3,3},skillCategory=ATTACK_PASSIVE]
对fury和protostuff 从包的大小和吞吐量两个指标做了性能对比,并且,我们对配置进行调整,是否可以有更优秀的表现,结果令人很满意!
对序列化后传输包体压缩率的各种比较如下:
| 协议 | 设置 | 压缩率 |
|---|---|---|
| fury | RefTracking=true, Number Compress=false | 42.87% |
| fury | RefTracking=true, Number Compress=true | 32.68% |
| fury | RefTracking=false, Number Compress=true | 32.68% |
| fury | RefTracking=false, Number Compress=true,class register | 25.66% |
| fury | RefTracking=true, Number Compress=true,class register | 25.66% |
| Protostuff | 23.79% |
在引用解析(RefTracking)关闭,类注册 (ClassRegistration)打开,整数压缩(NumberCompressed)打开的情况下,我们把这个纳入到性能测试案例中,得到了如下的数据(见enhance结尾的数据):
序列化:
Benchmark Mode Cnt Score Error Units
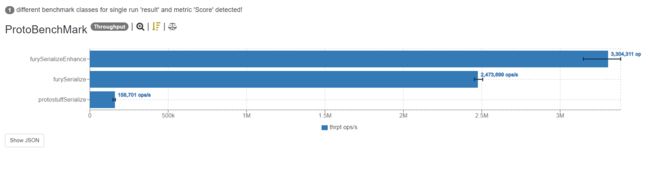
ProtoBenchMark.furySerialize thrpt 5 2473698.640 ± 85148.506 ops/s
ProtoBenchMark.furySerializeEnhance thrpt 5 3304310.535 ± 373448.362 ops/s
ProtoBenchMark.protostuffSerialize thrpt 5 158701.497 ± 24794.487 ops/s
反序列化:
Benchmark Mode Cnt Score Error Units
ProtoBenchMark.furyDeserialize thrpt 5 1449461.722 ± 824248.611 ops/s
ProtoBenchMark.furyDeserializeEnhance thrpt 5 2290441.366 ± 90505.315 ops/s
ProtoBenchMark.protostuffDeserialize thrpt 5 151250.316 ± 3770.036 ops/s

结论:
吞吐量对比:在默认引用解析打开,类注册关闭,整数压缩关闭的情况下,序列化上,fury 是protostuff 15.59 倍,反序列化上 fury 是protostuff 的9.58倍,完胜!
在引用解析关闭,类注册打开,整数压缩打开的情况下,序列化上,fury 提高到了protostuff 20.82 倍,反序列化上 fury 提高到了protostuff 的15.14倍,这个配置策略更适合游戏服务器!
包体压缩比上:在默认情况下,fury 和 protostuff 比较 42.87%> 23.79% , 大了快一倍左右,但在开启整数压缩和类名称注册下,压缩效果明显,达到了25.66%,基本已经接近Protostuff的压缩率。
Q&A:
- 引用解析(RefTracking)关闭和开启,对结果影响不大。
从官方问来了答案:
引用解析(RefTracking):pb之类的框架没法处理重复引用和循环引用,这个功能主要是处理这个的,如果重复对象很多,这个还是有开销的,没重复对象引用建议关闭。
2.在多线程的情况下,用ThreadLocalFury还是ThreadPoolFury,怎么决定?
线程频繁销毁,就用ThreadPoolFury,不然就ThreadLocalFury,缓存局部性更好
3.提前显式注册类,但我不想程序显式的去注册,能否改成在fury序列化时第一次遇到自定义类,在内部自动帮忙去注册呢?
这个不行的,第一次注册的顺序没法保证,除非使用FURY的元数据共享模式
参考链接:比JDK最高快170倍,蚂蚁集团开源高性能多语言序列化框架Fury