Java-集合
概述
- 所有的集合类和集合接口都在java.util包下。
- 在内存中申请一块空间用来存储数据,在Java中集合就是替换掉定长的数组的一种引用数据类型。
集合与数组的区别
| 名称 | 数组 | 集合 |
|---|---|---|
| 长度区别 | 数组长度固定,定义长了造成内存空间的浪费,定义短了不够用 | 集合大小可以变,用多少空间拿多少空间 |
| 内容区别 | 数组可以存储基本数据类型和引用数据类型 | 集合中能存储引用数据类型(存储的为对象的内存地址) list.add(100);//为自动装箱,100为Integer包装的 |
| 元素区别 | 数组中只能存储同一种类型成员 | 集合中可以存储不同类型数据(一般情况下也只存储同一种类型的数据) |
List和Set
- 单列集合 Collection
- List可以重复:ArrayList/LinkedList
- Set不可重复:HashSet/TreeSet
(1)添加
add(Object obj)
addAll(Collection coll)
(2)获取有效元素的个数
int size()
(3)清空集合
void clear()
(4)是否是空集合
boolean isEmpty()
(5)是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象。
boolean containsAll(Collection coll):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。
(6)删除
boolean remove(Object obj):通过元素的equals方法来判断是都是要删除的那个元素。只会删除找到的第一个元素。
boolean removeAll(Collection coll):取当前集合的差集。
(7)取两个集合的交集
boolean retainAll(Collection coll):把交集的结果存在当前集合中,不影响coll。
(8)集合是否相等
boolean equals(Object obj)
(9)转成对象数组
Object[] toArray()
(10)获取集合对象的哈希值
hashCode()
(11)遍历
iterator():返回迭代器对象,用于集合遍历。

2. 双列集合Map:HashMap/TreeMap

ArrayList(数组实现)
属性
DEFAULT_CAPACITY = 10 默认长度,初始化容量为10
Object[] EMPTY_ELEMENTDATA = {} //有参构造所创建
Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {} //无参构造所创建的
Object[] elementData;底层为Object类型的数组,存储的元素都在此。
int size 实际存放的个数
优缺点
ArrayList集合底层是数组,怎么优化?
尽可能少的扩容。因为数组扩容效率比较低,
建议在使用ArrayList集合 的时候预估计元素的个数,给定一个初始化容量。
数组优点:
检索效率比较高。(每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址,
然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高。)
数组缺点:
随机增删元素效率比较低。
另外数组无法存储大数据量。(很难找到一块非常巨大的连续的内存空间。)
向数组末尾添加元素,效率很高,不受影响。
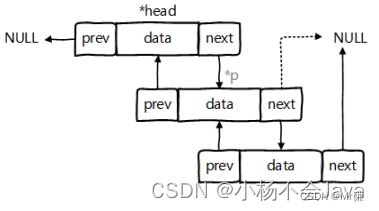
LinkedList(链表)
void addFirst(Object obj)
void addLast(Object obj)
Object getFirst()
Object getLast()
Object removeFirst()
Object removeLast()
属性
transient int size = 0;//初始长度
transient Node<E> first;//头节点
transient Node<E> last;//尾节点
优缺点
LinkedList和ArrayList方法一样,只是底层实现不一样。ArrayList底层为数组存储,
LinkedList是以双向链表存储。LinkedList集合没有初始化容量。
最初这个链表中没有任何元素。first和last引用都是null。
链表的优点:
由于链表上的元素在空间存储上内存地址不连续。
所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。
在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议
使用LinkedList。
链表的缺点:
不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头
节点开始遍历,直到找到为止。所以LinkedList集合检索/查找的效率
较低。
ArrayList:把检索发挥到极致。(末尾添加元素效率还是很高的。)
LinkedList:把随机增删发挥到极致。
加元素都是往末尾添加,所以ArrayList用的比LinkedList多。
Vector(数组实现、线程同步)
void addElement(Object obj)
void insertElement(Object obj,int index)
void set ElementAt(Object obj,int index)
void removeElement(Object obj)
void removeAllElements()
1、底层也是一个数组。
2、初始化容量:10
3、怎么扩容的?
扩容之后是原容量的2倍。
10--> 20 --> 40 --> 80
4、Vector中所有的方法都是线程同步的,都带有synchronized关键字,
是线程安全的。效率比较低,使用较少了。
5、怎么将一个线程不安全的ArrayList集合转换成线程安全的呢?
使用集合工具类:
java.util.Collections;
java.util.Collection 是集合接口。
java.util.Collections 是集合工具类。
Collections.synchronizedList();//将及格转换为线程安全的。
Set
Set集合也是一个接口,继承自Collection,与List类似,都需要通过实现类来进行操作。
特点
1.不允许包含重复的值
2.没有索引(就不能使用普通的for循环进行遍历)
Set 注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
对象的相等性本质是对象 hashCode 值 (iava 是依据对象的内存地址计算出的此序号)
判断的,如果想要让两人不同的对象视为相等的,就必须覆盖 Obiect 的 hashCode 方法和 equals 方法
代码实现
public class Demo {
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
//添加元素
set.add(new Student("黄固",28));
set.add(new Student("欧阳锋",38));
set.add(new Student("段智兴",48));
set.add(new Student("洪七公",40));
set.add(new Student("段智兴",48));
//从程序的角度来考虑,两个段智兴不是同一个对象,都有自己的存储空间,所以哈希值也不一样。
for (Student stu : set) {
System.out.println(stu);
}
/*
重写hashcode和equals
Student{name='段智兴', age=48}
Student{name='欧阳锋', age=38}
Student{name='洪七公', age=40}
Student{name='黄固', age=28}
*/
}
}
哈希值
Set集合的去重原理使用的是哈希值。
1.标准的基本类型只要值相等,哈希值就相同;
Integer a=10;
Integer b=10;
那么a和b的哈希值就相同。类似的还有Short、Long、Byte、Boolean、String等等
2.同一个对象,与何时运行该程序无关;
哈希值算法中,对象的内存地址不参与运算。因此只要是同一个对象,那么该对象的哈希值就不会改变。
3.关于容器的哈希值
java中常用的容器有List、Map、Set。那么它们的哈希值又有什么特点呢?
假设有如下两个List:
List<String> list1= new ArrayList<String>();
list1.add("item1");
list1.add("item2");
List<String> list2= new ArrayList<String>();
list2.add("item2");
list2.add("item1");
这两个List的哈希值是不一样的。对于List来讲,每一个元素都有它的顺序。
如果被添加的顺序不同,最后的哈希值必然不同。
假如有如下两个Map:
Map<String, String> map1= new HashMap<String, String>();
map1.put("a", "1");
map1.put("b", "2");
map1.put("c", "3");
Map<String, String> map2= new HashMap<String, String>();
map2.put("b", "2");
map2.put("a", "1");
map2.put("c", "3");
这两个Map虽然元素添加的顺序不一样,但是每一个元素的Key-Value值一样。
Map是一种无序的存储结构,因此它的哈希值与元素添加顺序无关,这两个Map的哈希值相同。
假如有如下两个Set:
Set<String> set1= new HashSet<String>();
set1.add("a");
set1.add("b");
set1.add("c");
Set<String> set2= new HashSet<String>();
set2.add("b");
set2.add("a");
set2.add("c");
类似的,由于Set也是一种无序的存储结构,两个Set虽然添加元素的顺序不一样,
但是总体来说元素的个数和内容是一样的。因此这两个Set的哈希值也相同。
其实,Set的实现是基于Map的。我们可以看到,如果将Set中的元素当做Map中的Key,
把Map中的value始终设置为null,那么它就变成了一个Set。
Set<String> set1= new HashSet<String>();
set1.add("a");
set1.add("b");
set1.add("c");
Map<String, String> map1= new HashMap<String, String>();
map1.put("a", null);
map1.put("b", null);
map1.put("c", null);
通过实验我最后得到了印证,set1与map1的哈希值相同。
HashSet (Hash表)
* 哈希表边存放的是哈希值。 HashSet 存储元素的顺序并不是按照存入时的顺序和 List 显然不同)
而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode 方法来获取的,
HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法如果 equals 结果为 true ,
HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。
* 哈希值相同 equals 为 false 的元素是怎么存储呢,就是在同样的哈希值下顺延
(可以认为哈希值相同的元素放在一个`哈希桶`中)。也就是哈希一样的存一列。
图1表示hashCode值不相同的情况;
图2表示hashCode值相同,但 equals 不相同的情况。
HashSet 通过 hashCode 值来确定元素在内存中的位置。一个 hashCode 位置上可以存放多个元素

public class Demo {
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<>();
//添加元素
set.add("黄固");
set.add("欧阳锋");
set.add("段智兴");
set.add("洪七公");
set.add("段智兴");//重复的元素不能存进去
System.out.println(set);//打印集合 [黄固, 欧阳锋, 段智兴, 洪七公]
}
}
TreeSet (二叉树)
1. TreeSet是使用二叉树的原理,对新add的对象按照指定的顺序排序(升序、降序),
每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
2. Integer和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的,
自己定义的类必须实现 Comparable 接口,并且看写相应的 compareTo函数,才可以正常使用。
3. 在覆写 compare函数时,要返回相应的值才能使 TreeSet 按照一定的规则来排序
4. 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
// 创建一个TreeSet集合
TreeSet<String> ts = new TreeSet<>();
// 添加String
ts.add("zhangsan");
ts.add("lisi");
ts.add("wangwu");
ts.add("zhangsi");
ts.add("wangliu");
// 遍历
for(String s : ts){
// 按照字典顺序,升序!
System.out.println(s);
}
/*
lisi
wangliu
wangwu
zhangsan
zhangsi
*/
TreeSet<Integer> ts2 = new TreeSet<>();
ts2.add(100);
ts2.add(200);
ts2.add(900);
ts2.add(800);
ts2.add(600);
ts2.add(10);
for(Integer elt : ts2){
// 升序!
System.out.println(elt);
}
}
}
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
Customer c1 = new Customer(32);
Customer c2 = new Customer(20);
Customer c3 = new Customer(30);
Customer c4 = new Customer(25);
// 创建TreeSet集合
TreeSet<Customer> customers = new TreeSet<>();
// 添加元素
customers.add(c1);
customers.add(c2);
customers.add(c3);
customers.add(c4);
// 遍历
for (Customer c : customers){
System.out.println(c);
}
TreeSet<Student> ts = new TreeSet<>();//默认排序规则
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int res = o1.getAge() - o2.getAge();
return 0 == res ? o1.getName().compareTo(o2.getName()) : res;
//三目运算符 等于零用姓名排序
}
});//默认排序规则
//添加元素
ts.add(new Student("Andy",19));
ts.add(new Student("Jack",18));
ts.add(new Student("Tom",21));
ts.add(new Student("Lucy",17));
ts.add(new Student("Bob",21)); //当年龄相同时,按照姓名的字典顺序排序
for (Student stu : ts) {
System.out.println(stu);
}
}
}
// 放在TreeSet集合中的元素需要实现java.lang.Comparable接口。
// 并且实现compareTo方法。equals可以不写。
class Customer implements Comparable<Customer>{
int age;
public Customer(int age){
this.age = age;
}
// 需要在这个方法中编写比较的逻辑,或者说比较的规则,按照什么进行比较!
// k.compareTo(t.key)
// 拿着参数k和集合中的每一个k进行比较,返回值可能是>0 <0 =0
// 比较规则最终还是由程序员指定的:例如按照年龄升序。或者按照年龄降序。
@Override
public int compareTo(Customer c) { // c1.compareTo(c2);
return c.age - this.age;
}
public String toString(){
return "Customer[age="+age+"]";
}
}
LinkHashSet (HashSet+LinkedHashMap)
对于 LinkedHashSet 而言,它继承于 HashSet、又基于LinkedHashMap 来实现的。
LinkedHashSet 底层使用LinkedHashMap 来保存所有元素,它继承于 HashSet,
其所有的方法操作上又与 HashSet 相同,因此linkedHashSet 的实现上非常简单,
只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,
底层构造一个LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,
直接调用父类 HashSet 的方法即可。
Map
① 添加、删除、修改操作:
> Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
> void putAll(Map m):将m中的所有key-value对存放到当前map中
> Object remove(Object key):移除指定key的key-value对,并返回value
> void clear():清空当前map中的所有数据
② 元素查询的操作:
> Object get(Object key):获取指定key对应的value
> boolean containsKey(Object key):是否包含指定的key
> boolean containsValue(Object value):是否包含指定的value
> int size():返回map中key-value对的个数
> boolean isEmpty():判断当前map是否为空 boolean equals(Object obj):判断当前map和参数对象obj是否相等
③ 元视图操作的方法:
> Set keySet():返回所有key构成的Set集合
> Collection values():返回所有value构成的Collection集合
> Set entrySet():返回所有key-value对构成的Set集合
双列集合:用来存储键值对的集合。
interface Map<K,V> : K(key)键 ,V(value)值
将键映射到值的对象,不能出现重复的键,每个键最多可以映射到一个值
1、Map和Collection没有继承关系。
2、Map集合以key和value的方式存储数据:键值对
key和value都是引用数据类型。
key和value都是存储对象的内存地址。
key起到主导的地位,value是key的一个附属品。
import java.util.HashMap;
import java.util.Map;
/**
* @Description 集合的基本方法
*/
public class Map {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("STU001","Andy");
map.put("STU002","Jack");
map.put("STU003","Tom");
map.put("STU004","Bob");
map.put("STU004","Smith");//设置(修改)
//如果键不存在,则表示添加元素。如果键存在,则表示设置值。
//删除
System.out.println(map.remove("STU003")); //Tom
//判断是否包含
System.out.println(map.containsKey("STU003")); //false
System.out.println(map.containsKey("STU004")); //true
System.out.println("-----------------------");
System.out.println(map.containsValue("Tom")); //false
System.out.println(map.containsValue("Smith")); //true
System.out.println("-----------------------");
System.out.println(map.isEmpty());//判断集合是否为空 false
map.clear();//清空集合
System.out.println(map.isEmpty()); //true
System.out.println(map); //{}
}
}
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @Description
*/
public class map_get {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("STU001","Andy");
map.put("STU002","Jack");
map.put("STU003","Tom");
map.put("STU004","Bob");
//get通过键获取值
System.out.println(map.get("STU003"));
System.out.println("------------------");
//keySet 获取所有键的Set集合
Set<String> keySet = map.keySet();
System.out.println(keySet);
//values 获取所有值的Collection集合
Collection<String> values = map.values();
System.out.println(values);
//entrySet 获取所有键值对对象的Set集合
Set<Map.Entry<String, String>> es = map.entrySet();
//Map集合通过entrySet()方法转换成的这个Set集合,Set集合中元素的类型是 Map.EntryHashMap (数组+链表+红黑树)
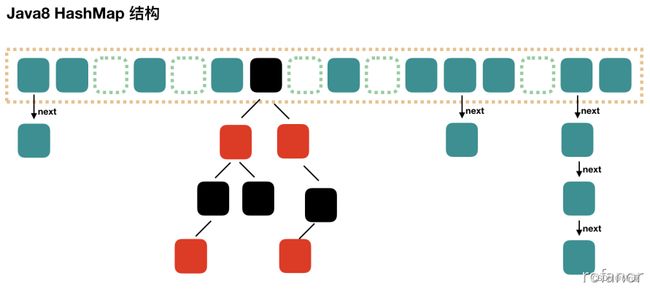
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,
但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null.
HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。
如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有线程安全的能力,
或者使用 ConcurrentHashMap。 我们用下面这张图来介绍HashMap 的结构。
ConcurrentHashMap

Segment段
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个ConcurrentHashMap 由一个个 Segment组成,Segment 代表”部分“或”一段“的意思,
所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个segment.
线程安全(Segment继承ReentrantLock加锁)
简单理解就是,ConcurrentHashMap 是一个Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,
所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,
也就实现了全局的线程安全
并行度(默认16)
concurrencyLevel: 并行级别、并发数、 Segment 数,怎么翻译不重要,理解它。默认是 16,
也就是说ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,
最多可以同时支持 16 个线程并发写,
只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,
但是一旦初始化以后,它是不可以扩容的,再具体到每 Segment 内部,
其实每 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
HashTable (线程安全)
Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自 Dictionary 类,
并且是线程安全的,任一时间只有一个线程能写 Hashtable,并发性不如 ConcurrentHashMap,
因为 ConcurrentHashMap引入了分段锁。
Hashtable 不建议在新代码中使用,不需要线程安全的场合可以用 HashMap 替换,
需要线程安全的场合可以用 ConcurrentHashMap 春换
TreeMap (可排序)
TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,
也可以指定排序的比较器,当用 lterator 遍历 TreeMap 时,得到的记录是排过序的。
如果使用排序的映射,建议使用 TreeMap。
在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,
否则会在运行时抛出 iavalang.ClassCastException 类型的异常.
LinkHashMap (记录插入顺序)
LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 terator 遍历LinkedHashMap 时,
先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序.
Properties
Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型。
Properties被称为属性类对象。 Properties是线程安全的。
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
/**
* @Description Properties特有方法
*/
public class PropertiesTest {
public static void main(String[] args) throws IOException {
Properties prop = new Properties();
final String SRC = "./myConf.ini";//定义配置信息存储路径
//mySave(prop,SRC);//存储配置文件
myLoad(prop,SRC);//加载配置文件信息
//PASSWORD<--->123456
//DATABASE<--->YX2115
//PORT<--->3306
//USERNAME<--->root
}
private static void myLoad(Properties prop, String src) throws IOException {
FileReader fr = new FileReader(src);
prop.load(fr);//通过流,加载指定路径的配置文件
fr.close();
//遍历
Set<String> keySet = prop.stringPropertyNames();//获取对象键的Set集合
for (String key : keySet) {
System.out.println(key + "<--->" + prop.getProperty(key));//通过键拿到值
}
}
private static void mySave(Properties prop, String src) throws IOException {
//将配置信息存储到对象中
prop.setProperty("USERNAME","root");
prop.setProperty("PASSWORD","123456");
prop.setProperty("DATABASE","YX2115");
prop.setProperty("PORT","3306");
//写入文件
FileWriter fw = new FileWriter(src);//创建输出流对象
prop.store(fw,"MyDataBase Configure!~");
fw.close();
}
}
Queue
概念
队列是一种特殊的线性表,遵循先入先出、后入后出的基本原则,一般来说,它只允许在表的前端进行删除操作,
而在表的后端进行插入操作,但是java的某些队列运行在任何地方插入删除;
比如我们常用的 LinkedList 集合,它实现了Queue 接口,因此,我们可以理解为 LinkedList 就是一个队列;

常用队列
ArrayBlockingQueue:基于数组数据结构实现的有界阻塞队列。
LinkedBlockingQueue:基于链表数据结构实现的有界阻塞队列。
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
DelayQueue:支持延迟操作的无界阻塞队列。
SynchronousQueue:用于线程同步的阻塞队列。
LinkedTransferQueue:基于链表数据结构实现的无界阻塞队列。
LinkedBlockingDeque:基于链表数据结构实现的双向阻塞队列。
队列常用方法
add 增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回false
poll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
put 添加一个元素 如果队列满,则阻塞
take 移除并返回队列头部的元素 如果队列为空,则阻塞
drainTo(list) 一次性取出队列所有元素
知识点: remove、element、offer 、poll、peek 其实是属于Queue接口。
队列特性
队列主要分为阻塞和非阻塞,有界和无界、单向链表和双向链表之分;
阻塞和非阻塞
阻塞队列
入列(添加元素)时,如果元素数量超过队列总数,会进行等待(阻塞),待队列的中的元素出列后,元素数量未超过队列总数时,就会解除阻塞状态,进而可以继续入列;
出列(删除元素)时,如果队列为空的情况下,也会进行等待(阻塞),待队列有值的时候即会解除阻塞状态,进而继续出列;
阻塞队列的好处是可以防止队列容器溢出;只要满了就会进行阻塞等待;也就不存在溢出的情况;
只要是阻塞队列,都是线程安全的;
非阻塞队列
不管出列还是入列,都不会进行阻塞,
入列时,如果元素数量超过队列总数,则会抛出异常,
出列时,如果队列为空,则取出空值;
一般情况下,非阻塞式队列使用的比较少,一般都用阻塞式的对象比较多;阻塞和非阻塞队列在使用上的最大区别就是阻塞队列提供了以下2个方法:
出队阻塞方法 : take()
入队阻塞方法 : put()
有界和无界
有界:有界限,大小长度受限制
无界:无限大小,其实说是无限大小,其实是有界限的,只不过超过界限时就会进行扩容,就行ArrayList 一样,在内部动态扩容
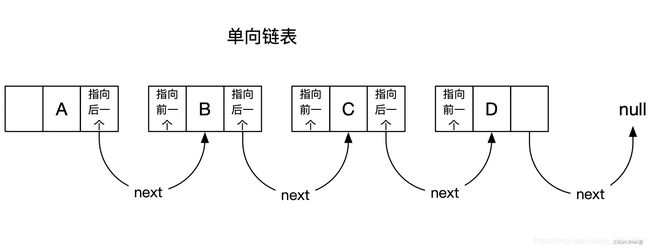
单向链表和双向链表
单向链表 : 每个元素中除了元素本身之外,还存储一个指针,这个指针指向下一个元素;

非阻塞队列
1、ConcurrentLinkedQueue
单向链表结构的无界并发队列, 非阻塞队列,由CAS实现线程安全,内部基于节点实现
2、ConcurrentLinkedDeque
双向链表结构的无界并发队列, 非阻塞队列,由CAS实现线程安全
3、PriorityQueue
内部基于数组实现,线程不安全的队列
阻塞队列
1、DelayQueue
一个支持延时获取元素的无界阻塞队列
2、LinkedTransferQueue
一个由链表结构组成的无界阻塞队列。
3、ArrayBlockingQueue
有界队列,阻塞式,初始化时必须指定队列大小,且不可改变;,底层由数组实现;
4、SynchronousQueue
最多只能存储一个元素,每一个put操作必须等待一个take操作,否则不能继续添加元素
5、PriorityBlockingQueue
一个带优先级的队列,而不是先进先出队列。元素按优先级顺序被移除,而且它也是无界的,也就是没有容量上限,
虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError 错误;