学习笔记十一:kubeadm安装生产环境多master节点k8s高可用集群
kubeadm安装生产环境多master节点k8s高可用集群
- 环境规划
-
- kubeadm和二进制安装k8s适用场景分析
- 初始化安装k8s集群的实验环境 三台测试机都需要做
-
-
- 关闭交换分区swap,提升性能
- 修改机器内核参数
- 配置安装k8s组件需要的阿里云的repo源
- 安装基础软件包
- 安装docker-ce
- 安装初始化k8s需要的软件包,三台都执行
-
- 通过keepalive+nginx实现k8s apiserver节点高可用(只涉及k8smaster1和k8smaster2)
-
-
- 安装nginx主备:
- keepalive配置
-
- 主keepalived
- 备keepalive
- 启动服务:
- 测试vip是否绑定成功
- 测试keepalived:
-
- kubeadm初始化k8s集群
-
-
-
- 在k8smaster1执行
- 分别把初始化k8s集群需要的离线镜像包上传到k8smaster1、k8smaster2、k8snode1机器上,手动解压:
- 如果初始化有问题,k8s重新初始化
-
-
- 扩容k8s集群-添加master节点
-
-
- 扩容k8s集群-添加node节点
- 安装kubernetes网络组件-Calico
- 测试在k8s创建pod是否可以正常访问网络
- 测试coredns是否正常
-
- 同master网段下有kubectl也可以执行相关操作
- kubeadm init初始化流程分析
-
-
- kubeadm 在执行安装之前进行了相当细致的环境检测
- 完成安装前的配置
-
- 安装常见相关问题
环境规划
k8s环境规划:
podSubnet(pod网段) 10.244.0.0/16
serviceSubnet(service网段): 10.96.0.0/16
实验环境规划:
操作系统:centos7.6或者centos7.9
配置: 4Gib内存/4vCPU/60G硬盘
网络:NAT
开启虚拟机的虚拟化:
先初始化master,后进行克隆更方便些。可以做到 安装初始化k8s需要的软件包 后进行克隆
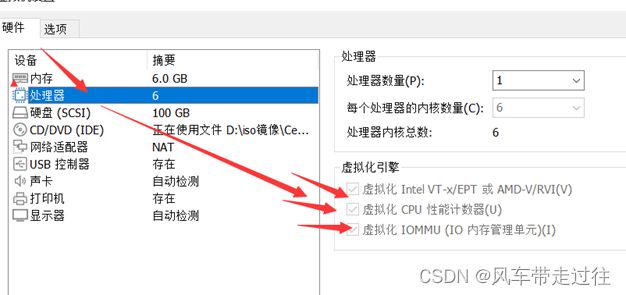
查看自己电脑几核的CPU


- master:apiserver,controller-manager,etcd,schedule,kubelet,docker,kube-proxy,keepalived,nginx,calico
- node:kubelet,docker,kube-proxy,calico,coredns
kubeadm和二进制安装k8s适用场景分析
kubeadm是官方提供的开源工具,是一个开源项目,用于快速搭建kubernetes集群,目前是比较方便和推荐使用的。kubeadm init 以及 kubeadm join 这两个命令可以快速创建 kubernetes 集群。Kubeadm初始化k8s,所有的组件都是以pod形式运行的,具备故障自恢复能力。
- kubeadm是工具,可以快速搭建集群,也就是相当于用程序脚本帮我们装好了集群,属于自动部署,简化部署操作,自动部署屏蔽了很多细节,使得对各个模块感知很少,如果对k8s架构组件理解不深的话,遇到问题比较难排查。
kubeadm适合需要经常部署k8s,或者对自动化要求比较高的场景下使用 - 二进制:在官网下载相关组件的二进制包,如果手动安装,对kubernetes理解也会更全面。
- Kubeadm和二进制都适合生产环境,在生产环境运行都很稳定,具体如何选择,可以根据实际项目进行评估。
初始化安装k8s集群的实验环境 三台测试机都需要做
参考:学习笔记一:VMware配置虚拟机centos并初始化
https://blog.csdn.net/weixin_43258559/article/details/122121258
插件链接
链接:https://pan.baidu.com/s/1oN4x61NVvRUnuYnTn4IA2g
提取码:gog3
关闭交换分区swap,提升性能
swapoff -a
永久关闭:注释swap挂载,给swap这行开头加一下注释
vim /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
为什么要关闭swap交换分区?
Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定–ignore-preflight-errors=Swap来解决。
修改机器内核参数
modprobe br_netfilter
echo "modprobe br_netfilter" >> /etc/profile
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
问题1:sysctl是做什么的?
在运行时配置内核参数
-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载
问题2:为什么要执行modprobe br_netfilter?
修改/etc/sysctl.d/k8s.conf文件,增加如下三行参数:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
sysctl -p /etc/sysctl.d/k8s.conf出现报错:
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解决方法:modprobe br_netfilter
问题3:为什么开启net.bridge.bridge-nf-call-iptables内核参数?
在centos下安装docker,执行docker info出现如下警告:
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决办法:
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
问题4:为什么要开启net.ipv4.ip_forward = 1参数?
kubeadm初始化k8s如果报错:
就表示没有开启ip_forward,需要开启。
net.ipv4.ip_forward是数据包转发:
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
配置安装k8s组件需要的阿里云的repo源
cat > /etc/yum.repos.d/kubernetes.repo<<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
安装基础软件包
yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet ipvsadm
安装docker-ce
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce-20.10.6 docker-ce-cli-20.10.6 containerd.io -y
systemctl start docker && systemctl enable docker && systemctl status docker
配置docker镜像加速器和驱动
cat >/etc/docker/daemon.json <<EOF
{
"registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com", "https://rncxm540.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
修改docker文件驱动为systemd,默认为cgroupfs,kubelet默认使用systemd,两者必须一致才可以。
systemctl daemon-reload && systemctl restart docker
systemctl status docker
安装初始化k8s需要的软件包,三台都执行
yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6
注:每个软件包的作用
Kubeadm: kubeadm是一个工具,用来初始化k8s集群的
kubelet: 安装在集群所有节点上,用于启动Pod的
kubectl: 通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
通过keepalive+nginx实现k8s apiserver节点高可用(只涉及k8smaster1和k8smaster2)
安装nginx主备:
在k8smaster1和k8smaster2上做nginx主备安装
yum install nginx keepalived -y
修改nginx配置文件。主备一样
rm -rf /etc/nginx/nginx.conf
cat >/etc/nginx/nginx.conf<<EOF
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.40.10:6443 weight=5 max_fails=3 fail_timeout=30s;
server 192.168.40.11:6443 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF
keepalive配置
主keepalived
rm -rf /etc/keepalived/keepalived.conf
cat >/etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.40.199/24
}
track_script {
check_nginx
}
}
#vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
#virtual_ipaddress:虚拟IP(VIP)
EOF
cat> /etc/keepalived/check_nginx.sh<<EOF
#!/bin/bash
#1、判断Nginx是否存活
counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" )
if [ $counter -eq 0 ]; then
#2、如果不存活则尝试启动Nginx
service nginx start
sleep 2
#3、等待2秒后再次获取一次Nginx状态
counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" )
#4、再次进行判断,如Nginx还不存活则停止Keepalived,让地址进行漂移
if [ $counter -eq 0 ]; then
service keepalived stop
fi
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
备keepalive
rm -rf /etc/keepalived/keepalived.conf
cat >/etc/keepalived/keepalived.conf <<EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.40.199/24
}
track_script {
check_nginx
}
}
EOF
cat> /etc/keepalived/check_nginx.sh<<EOF
#!/bin/bash
#1、判断Nginx是否存活
counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" )
if [ $counter -eq 0 ]; then
#2、如果不存活则尝试启动Nginx
service nginx start
sleep 2
#3、等待2秒后再次获取一次Nginx状态
counter=$(ps -ef |grep nginx | grep sbin | egrep -cv "grep|$$" )
#4、再次进行判断,如Nginx还不存活则停止Keepalived,让地址进行漂移
if [ $counter -eq 0 ]; then
service keepalived stop
fi
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
启动服务:
主keepalive
systemctl daemon-reload
yum install nginx-mod-stream -y
systemctl start nginx
systemctl start keepalived
systemctl enable nginx keepalived
systemctl status keepalived

备keepalive
systemctl daemon-reload
yum install nginx-mod-stream -y
systemctl start nginx
systemctl start keepalived
systemctl enable nginx keepalived
systemctl status keepalived

测试vip是否绑定成功
ip addr

测试keepalived:
停掉k8smaster1上的keepalived,Vip会漂移到k8smaster2
k8smaster1执行
service keepalived stop
在k8smaster2 查看
ip addr

启动k8smaster1上的nginx和keepalived,vip又会漂移回来
systemctl daemon-reload
systemctl start keepalived
ip addr

kubeadm初始化k8s集群
在k8smaster1执行
cd /root/
cat >kubeadm-config.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.20.6
controlPlaneEndpoint: 192.168.40.199:16443
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
certSANs:
- 192.168.40.10
- 192.168.40.11
- 192.168.40.12
- 192.168.40.199
networking:
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/16
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
EOF
分别把初始化k8s集群需要的离线镜像包上传到k8smaster1、k8smaster2、k8snode1机器上,手动解压:
使用kubeadm初始化k8s集群
k8simage-1-20-6.tar.gz链接:https://pan.baidu.com/s/1SYU77sfFmiY6wmg0B1syng?pwd=i00j
提取码:i00j
docker load -i k8simage-1-20-6.tar.gz
kubeadm init --config kubeadm-config.yaml --ignore-preflight-errors=SystemVerification
出现如下提示安装成功

- 特别提醒:–image-repository registry.aliyuncs.com/google_containers为保证拉取镜像不到国外站点拉取,手动指定仓库地址为registry.aliyuncs.com/google_containers。kubeadm默认从k8s.gcr.io拉取镜像。 我们本地有导入到的离线镜像,所以会优先使用本地的镜像。
- mode: ipvs 表示kube-proxy代理模式是ipvs,如果不指定ipvs,会默认使用iptables,但是iptables效率低,所以我们生产环境建议开启ipvs,阿里云和华为云托管的K8s,也提供ipvs模式,如下:


显示如下,说明安装完成:
配置kubectl的配置文件config,相当于对kubectl进行授权,这样kubectl命令可以使用这个证书对k8s集群进行管理

mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get nodes
此时集群状态还是NotReady状态,因为没有安装网络插件。
如果初始化有问题,k8s重新初始化
kubeadm reset
rm -rf /root/.kube
rm -rf /etc/cni/net.d
修改完一些配置比如kubeadm-config.yaml 后,重新初始化
kubeadm init --config kubeadm-config.yaml --ignore-preflight-errors=SystemVerification
扩容k8s集群-添加master节点
把k8smaster1节点的证书拷贝到k8smaster2上
在k8smaster2创建证书存放目录:
cd /root && mkdir -p /etc/kubernetes/pki/etcd &&mkdir -p ~/.kube/
把k8smaster1节点的证书拷贝到k8smaster2上:
scp /etc/kubernetes/pki/ca.crt k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.key k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.key k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.pub k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.crt k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.key k8smaster2:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.crt k8smaster2:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/pki/etcd/ca.key k8smaster2:/etc/kubernetes/pki/etcd/
证书拷贝之后在k8smaster2上执行如下命令,复制自己的,这样就可以把k8smaster2和加入到集群,成为控制节点:
在k8smaster1上查看加入节点的命令:k8smaster1初始化的token只有24小时有效期,过期就无法使用了,可以使用下面命令在生成token,方便节点加入
kubeadm token create --print-join-command
#显示如下:
kubeadm join 192.168.40.199:16443 --token nchv8g.kuf5pjxefhsouk3w --discovery-token-ca-cert-hash sha256:c20203d30b3a81a4367005a42c52044633d2e020839b683d423d7158056d8f7b
注意末尾加–control-plane参数,只有加了这个参数才知道加入的是控制节点
–ignore-preflight-errors=SystemVerification 这个参数是不校验配置文件,在安装时使用该参数不会报错
![]()
在k8smaster2上执行: 注意加–control-plane --ignore-preflight-errors=SystemVerification 参数
kubeadm join 192.168.40.199:16443 --token nchv8g.kuf5pjxefhsouk3w --discovery-token-ca-cert-hash sha256:c20203d30b3a81a4367005a42c52044633d2e020839b683d423d7158056d8f7b
--control-plane --ignore-preflight-errors=SystemVerification
在k8smaster1上查看集群状况:
kubectl get nodes

上面可以看到k8smaster2已经加入到集群了
扩容k8s集群-添加node节点
在k8smaster1上查看加入节点的命令:
kubeadm token create --print-join-command
#显示如下:
kubeadm join 192.168.40.199:16443 --token v7j894.g2ah9t5ywaov3li9 --discovery-token-ca-cert-hash sha256:c20203d30b3a81a4367005a42c52044633d2e020839b683d423d7158056d8f7b
把k8snode1加入k8s集群:
kubeadm join 192.168.40.199:16443 --token v7j894.g2ah9t5ywaov3li9 --discovery-token-ca-cert-hash sha256:c20203d30b3a81a4367005a42c52044633d2e020839b683d423d7158056d8f7b --ignore-preflight-errors=SystemVerification
看到上面说明k8snode1节点已经加入到集群了,充当工作节点
在k8smaster1上查看集群节点状况:
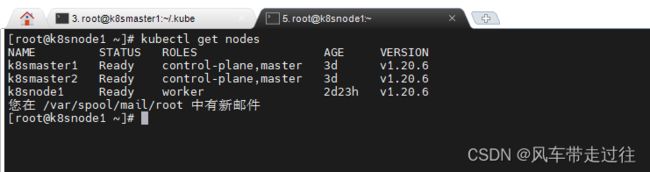
kubectl get nodes

可以看到k8snode1的ROLES角色为空,就表示这个节点是工作节点。
可以把k8snode1的ROLES变成work,按照如下方法:
kubectl label node k8snode1 node-role.kubernetes.io/worker=worker

注意:上面状态都是NotReady状态,说明没有安装网络插件
kubectl get pods -n kube-system

两个coredns pod是pending状态,这是因为还没有安装网络插件,等到下面安装好网络插件之后这个cordns就会变成running了
安装kubernetes网络组件-Calico
上传calico.yaml到k8smaster1上,使用yaml文件安装calico 网络插件 。
链接:https://pan.baidu.com/s/1XauZzanmljkFzcFUoZwwrA?pwd=dbp0
提取码:dbp0
kubectl apply -f calico.yaml
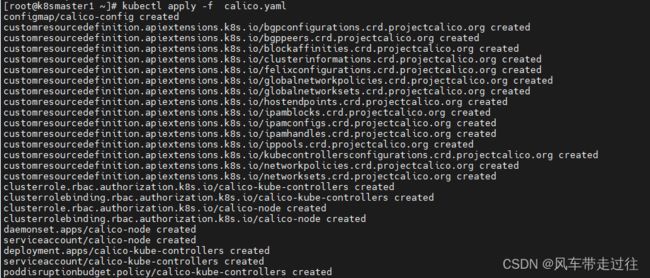
注:在线下载配置文件地址是: https://docs.projectcalico.org/manifests/calico.yaml
kubectl get pod -n kube-system
coredns-这个pod现在是running状态,运行正常

再次查看集群状态。
kubectl get nodes
STATUS状态是Ready,说明k8s集群正常运行了

测试在k8s创建pod是否可以正常访问网络
把busybox-1-28.tar.gz上传到k8snode1节点,手动解压
docker load -i busybox-1-28.tar.gz
在k8smaster1执行
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
ping www.baidu.com
#通过上面可以看到能访问网络,说明calico网络插件已经被正常安装了
#退出pod exit

测试coredns是否正常
在k8smaster1执行
链接:https://pan.baidu.com/s/1O4rrRM3SmoMNQzX6k3btlw?pwd=s3e6
提取码:s3e6
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
nslookup kubernetes.default.svc.cluster.local
注意:busybox要用指定的1.28版本,不能用最新版本,最新版本,nslookup会解析不到dns和ip

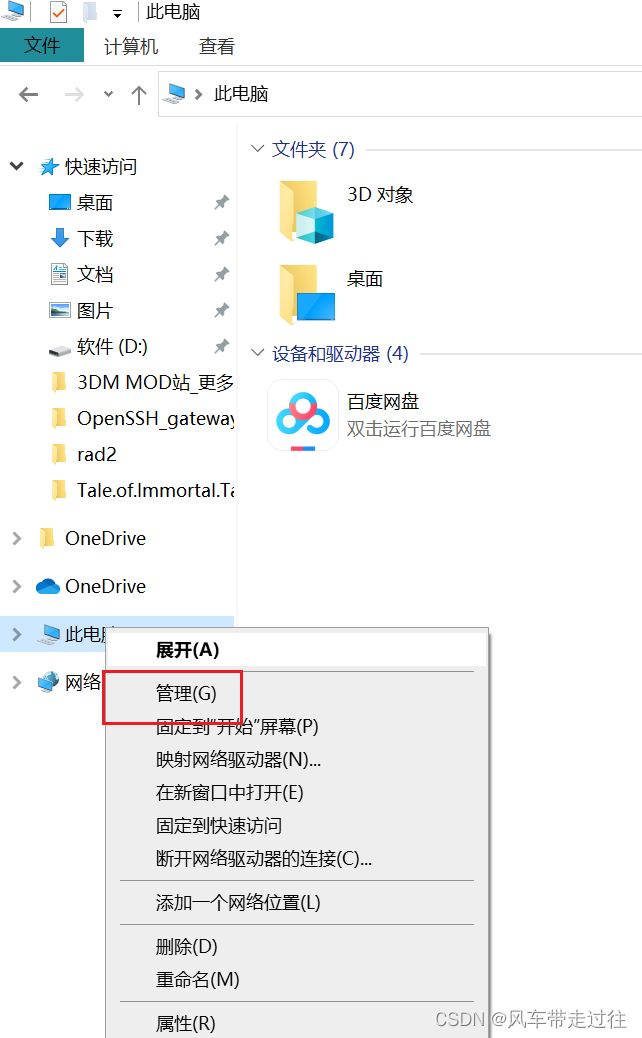
同master网段下有kubectl也可以执行相关操作
/root/.kube/config
从k8smaster1拷贝到其他机器的/root/.kube/下,其他机器也可以执行kubectl 查看k8smaster1 的信息

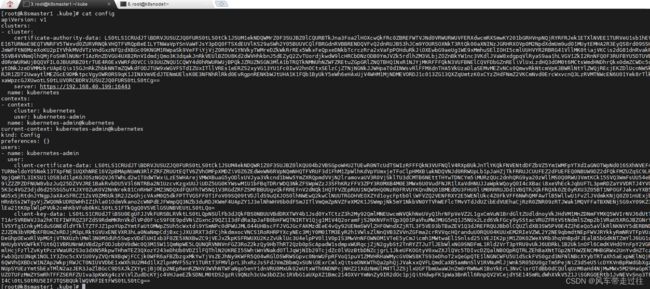
在k8snode1执行查下nodes,发现报错
在k8snode1创建.kube文件夹,以便master复制config文件过来
kubectl get nodes
mkdir /root/.kube

在k8smaster1拷贝/root/.kube/config至k8snode1的/root/.kube目录下
scp config k8snode1:/root/.kube/config
在k8snode1执行查询nodes操作,发现也可以执行相关kubectl命令了
kubectl get nodes
kubeadm init初始化流程分析

注意:操作系统需要我们手动配置好,包括防火墙、swap、selinux关掉
kubeadm 在执行安装之前进行了相当细致的环境检测
- 检查执行 init 命令的用户是否为 root,如果不是 root,直接快速失败(fail fast);
- 检查待安装的 k8s 版本是否被当前版本的 kubeadm 支持(kubeadm 版本 >= 待安装 k8s 版本);
- 检查防火墙,如果防火墙未关闭,提示开放端口 10250;
- 检查端口是否已被占用,6443(或你指定的监听端口)、10257、10259;
- 检查文件是否已经存在,/etc/kubernetes/manifests/*.yaml;
- 检查是否存在代理,连接本机网络、服务网络、Pod网络,都会检查,目前不允许代理;
- 检查容器运行时,使用 CRI 还是 Docker,如果是 Docker,进一步检查 Docker 服务是否已启动,是否设置了开机自启动;
- 对于 Linux 系统,会额外检查以下内容:
8.1) 检查以下命令是否存在:crictl、ip、iptables、mount、nsenter、ebtables、ethtool、socat、tc、touch;
8.2) 检查 /proc/sys/net/bridge/bridge-nf-call-iptables、/proc/sys/net/ipv4/ip-forward 内容是否为 1;
8.3) 检查 swap 是否是关闭状态; - 检查内核是否被支持,Docker 版本及后端存储 GraphDriver 是否被支持;对于 Linux 系统,还需检查 OS 版本和 cgroup 支持程度(支持哪些资源的隔离);
- 检查主机名访问可达性;
- 检查 kubelet 版本,要高于 kubeadm 需要的最低版本,同时不高于待安装的 k8s 版本;
- 检查 kubelet 服务是否开机自启动;
- 检查 10250 端口是否被占用;
- 如果开启 IPVS 功能,检查系统内核是否加载了 ipvs 模块;
- 对于 etcd,如果使用 Local etcd,则检查 2379 端口是否被占用, /var/lib/etcd/ 是否为空目录; 如果使用 External etcd,则检查证书文件是否存在(CA、key、cert),验证 etcd 服务版本是否符合要求;
- 如果使用 IPv6,
检查 /proc/sys/net/bridge/bridge-nf-call-iptables、/proc/sys/net/ipv6/conf/default/forwarding 内容是否为 1;
以上就是 kubeadm init 需要检查的所有项目了!
完成安装前的配置
- 在 kube-system 命名空间创建 ConfigMap kubeadm-config,同时对其配置 RBAC 权限;
- 在 kube-system 命名空间创建 ConfigMap kubelet-config-,同时对其配置 RBAC 权限;
- 为当前节点(Master)打标记:node-role.kubernetes.io/master=;
- 为当前节点(Master)补充 Annotation;
- 如果启用了 DynamicKubeletConfig 特性,设置本节点 kubelet 的配置数据源为 ConfigMap 形式;
- 创建 BootStrap token Secret,并对其配置 RBAC 权限;
- 在 kube-public 命名空间创建 ConfigMap cluster-info,同时对其配置 RBAC 权限;
- 与 apiserver 通信,部署 DNS 服务;
- 与 apiserver 通信,部署 kube-proxy 服务;
- 如果启用了 self-hosted 特性,将 Control Plane 转为 DaemonSet 形式运行;
- 打印 join 语句;
安装常见相关问题
问题1:sysctl是做什么的?
在运行时配置内核参数
-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载
问题2:为什么要执行modprobe br_netfilter?
修改/etc/sysctl.d/k8s.conf文件,增加如下三行参数:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
sysctl -p /etc/sysctl.d/k8s.conf出现报错:
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解决方法:
modprobe br_netfilter
问题3:为什么开启net.bridge.bridge-nf-call-iptables内核参数?
在centos下安装docker,执行docker info出现如下警告:
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决办法:
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
问题4:为什么要开启net.ipv4.ip_forward = 1参数?
kubeadm初始化k8s如果报错:
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
执行下列语句
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
就表示没有开启ip_forward,需要开启。
net.ipv4.ip_forward是数据包转发:
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。