基于Python爬虫+词云图+情感分析对某东上完美日记的用户评论分析

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
前言
一、研究背景
二、技术原理
三、获取数据
四、词云图分析
五、情感分析
六、往期推荐
前言
最近参加了腾讯云Cloud Studio的作品评选,本次实验的爬虫代码点击链接查看,https://club.cloudstudio.net/a/12010256262184960,对大家有帮助的话欢迎大家点个赞和Fork!十分感谢!
一、研究背景
随着互联网和社交媒体的发展,用户评论成为了消费者表达自己意见和情感的主要途径之一。对于企业来说,深入了解用户对其产品或服务的看法可以帮助他们更好地了解市场需求、产品改进的方向,以及消费者的情感倾向。因此,对用户评论进行分析已经成为了市场研究和商业决策的重要手段之一。
完美日记作为一家知名的化妆品品牌,其在社交媒体和电商平台上拥有大量的用户评论。通过对完美日记的用户评论进行分析,可以揭示出以下几个方面的信息:
-
消费者满意度: 通过情感分析,可以了解消费者对完美日记产品的满意度。情感分析可以判断评论中的情感倾向,如正面、负面或中性,从而判断消费者对产品的态度。
-
产品特点: 用户评论中可能提到产品的不同特点、功能和效果。通过词云图,可以直观地了解哪些特点被频繁提及,从而了解产品的优势和劣势。
-
市场趋势: 对用户评论进行分析可以发现市场的趋势和消费者的需求。例如,如果多数评论中提到某种产品特点,说明这个特点可能是当前市场上消费者关注的焦点。
-
品牌声誉: 用户评论不仅关注产品,还可能涉及到品牌的声誉、客服服务等方面。通过分析评论中对品牌的评价,可以了解品牌在消费者心目中的形象。
-
竞争分析: 通过比较完美日记与竞争对手的用户评论,可以了解不同品牌的优势和劣势,为市场竞争和战略制定提供依据。
因此,基于Python爬虫获取完美日记用户评论,结合词云图和情感分析技术,可以深入挖掘用户的情感、意见和需求,为完美日记品牌的市场营销、产品改进以及品牌管理提供有价值的信息支持。这种综合分析方法有助于企业更好地了解市场动态,优化产品策略,提升品牌价值。
二、技术原理
-
Python爬虫: 爬虫是一种自动化工具,用于从网页上获取数据。通过Python编写爬虫脚本,可以模拟人类浏览器行为,访问目标网站,抓取用户评论数据。常用的Python爬虫库包括Requests和Beautiful Soup,它们可以帮助获取网页内容并解析HTML结构。
-
词云图生成: 词云图是一种图形化展示文本数据中关键词频率的方式。制作词云图需要对文本进行预处理,包括分词、去除停用词(如“的”、“是”等常见词语)、统计词频等。然后,根据词频将关键词按照大小不同进行排列,生成词云图。Python中的词云库如WordCloud可以帮助生成词云图。
-
情感分析: 情感分析是一种自然语言处理技术,用于判断文本中表达的情感倾向,如积极、消极或中性。情感分析可以通过机器学习模型,如基于深度学习的模型或传统的文本分类算法,来训练并判断文本情感。这些模型会根据文本的词汇、语法结构以及上下文来判断情感。
在本次实验中,爬虫技术用于获取完美日记的用户评论数据,词云图技术用于可视化评论中的关键词频率,情感分析技术用于判断评论的情感倾向。结合这些技术,可以从大量的评论数据中提取出有关产品、品牌和消费者情感的有价值信息。
本次实验技术工具
Python版本:3.9
代码编辑器:jupyter notebook
三、获取数据
本次实验的目标是获取某东上关于完美日记的用户评论数据,打开京东官网,来到完美日记官方旗舰店

打开商品评论并使用开发者工具进行抓包分析,找到返回用户评论的接口并确定关键参数,最后使用requests库进行模拟请求,将返回的数据进行解析提取即可。
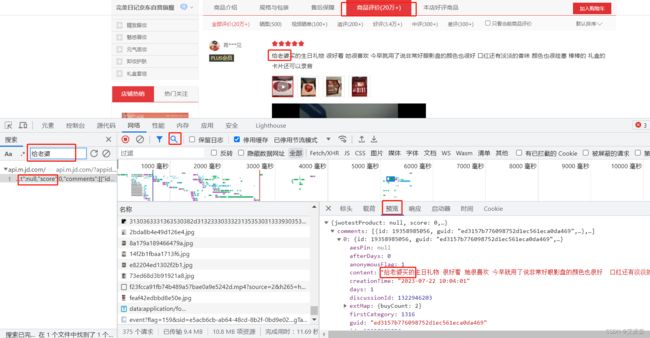
分析过程其实不难,学过爬虫的话都知道,完整的代码及使用教程都在文章开头的链接里。
代码运行之后,只需要输入你要爬取的商品ID和要爬取的页数即可

商品ID就是商品详情页网址最后的那串数字
![]()
四、词云图分析
首先读取我们刚爬取的完美日记评论数据
import pandas as pd
with open('JD_comment_100055983355.txt')as f:
comment_list = []
for comment in f.readlines():
comment = comment.replace('\n','')
comment_list.append(comment)
df = pd.DataFrame(data=comment_list,columns=['comment'])
df
接着自定义我们的画词云图函数
import jieba
import collections
import re
import stylecloud
from PIL import Image
def draw_WorldCloud(df,pic_name,color='white'):
data = ''.join([item for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list), # 提取500个词进行绘图
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 C:\Windows\Fonts\ ,根据里面的字体编号来设置
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板,调色网址: https://jiffyclub.github.io/palettable/
background_color=color, # 背景颜色
icon_name='fas fa-cloud', # 形状的图标名称 蒙版网址:https://fontawesome.com/icons?d=gallery&p=2&c=chat,shopping,travel&m=free
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()调用函数作图
draw_WorldCloud(df['comment'],'完美日记用户评论词云图')[('喜欢', 146), ('颜色', 140), ('产品', 112), ('效果', 98), ('不错', 91), ('包装', 91), ('口红', 88), ('好看', 76), ('质感', 75), ('适合', 64), ('女朋友', 58), ('滋润', 52), ('持久', 48), ('完美', 47), ('特别', 45), ('肤色', 45), ('精致', 44), ('朋友', 42), ('礼物', 40), ('礼盒', 38), ('感觉', 37), ('日记', 36), ('满意', 32), ('物流', 30), ('值得', 28), ('超级', 26), ('送给', 26), ('京东', 26), ('特色', 26), ('质量', 25), ('购买', 22), ('快递', 20), ('速度', 20), ('推荐', 20), ('买来', 19), ('很快', 19), ('收到', 18), ('上档次', 16), ('高级', 16), ('色号', 16), ('盒子', 16), ('眼影', 15), ('高端', 15), ('性价比', 15), ('购物', 15), ('老婆', 14), ('颜值', 14), ('精美', 14), ('看着', 13), ('很漂亮', 13), ('送人', 13), ('日常', 13), ('搭配', 13), ('打开', 13), ('情人节', 13), ('整体', 12), ('价格', 12), ('设计', 11), ('希望', 11), ('质地', 11), ('合适', 11), ('下次', 11), ('卖家', 11), ('看起来', 11), ('活动', 10), ('挺不错', 10), ('客服', 10), ('大气', 10), ('漂亮', 10), ('外观', 10), ('高大', 10), ('生日礼物', 9), ('红色', 9), ('实惠', 9), ('很棒', 9), ('还会', 9), ('细腻', 9), ('掉色', 9), ('服务态度', 9), ('品牌', 9), ('发货', 9), ('宝贝', 9), ('体验', 9), ('做工', 9), ('拿到', 9), ('三种', 9), ('第二天', 8), ('信赖', 8), ('媳妇', 8), ('划算', 8), ('显白', 8), ('三个', 8), ('小巧', 8), ('节日', 8), ('来说', 8), ('一支', 8), ('粉色', 7), ('好评', 7), ('犹豫', 7), ('简直', 7)]

从词云图可以发现,完美日记是一款口红产品,在颜色、包装、效果上有着不错的口碑,且这款产品多为送女朋友的礼物。
五、情感分析
情感分析我们使用到是SnowNLP模块,SnowNLP是一个用于中文文本情感分析的Python库,它可以帮助你判断中文文本的情感倾向,即判断文本是积极的、消极的还是中性的。得到的分数表示文本的情感倾向,越接近1表示积极情感,越接近0表示消极情感。
代码如下:
#加载情感分析模块
from snownlp import SnowNLP
import matplotlib.pyplot as plt
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in df['comment']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:
if (i>=0.6):
myval.append("积极")
good=good+1
elif 0.2
接着做出情感分析的可视化图
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析',family='SimHei',size=14,color='blue')
plt.show()![]()
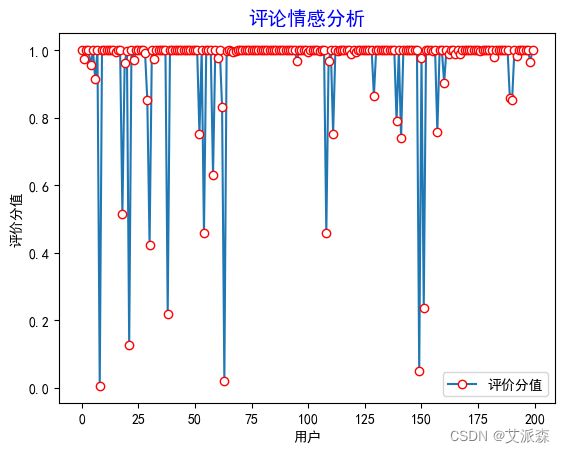
从图中可以看出绝大多数的评论情感得分都是在1附近,但是我们不知道消极、中性、积极评论的占比,于是我们做出饼图进行展示分析:
y = df['评价类别'].value_counts().values.tolist()
plt.pie(y,
labels=['积极','中性','消极'], # 设置饼图标签
colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色
autopct='%.2f%%', # 格式化输出百分比
)
plt.show()
可以看出积极评论占比95%,消极评论仅占2%,可见该款产品的口碑非常不错!
六、往期推荐
基于爬虫+词云图+Kmeans聚类+LDA主题分析+社会网络语义分析对大唐不夜城用户评论进行分析
基于Tomotopy构建LDA主题模型(附案例实战)
用Python爬取电影数据并可视化分析
基于TF-IDF+KMeans聚类算法构建中文文本分类模型(附案例实战)
文本分析-使用jieba库进行中文分词和去除停用词(附案例实战)
基于sklearn实现LDA主题模型(附实战案例)
数据分析案例-文本挖掘与中文文本的统计分析
数据分析实例-获取某宝评论数据做词云图可视化
数据分析案例-对某宝用户评论做情感分析
文本分析-使用jieba库实现TF-IDF算法提取关键词
ROSTEA软件下载及情感分析详细操作教程(附网盘链接)
SnowNLP使用自定义语料进行模型训练(情感分析)