数据平台SQL开发详解与函数使用
云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
Flink SQL动态表
创建Kafka动态表
下图为在Flink里创建kafka动态表。知道kafka的信息和数据格式信息后创建kafka表,在建表语句的最后一个字段,我们添加了一个kafka topic元数据信息:create_time(数据写入kafka的时间),基于以上操作便可以完成kafka动态表创建,后续便可以在Flink SQL里对topic进行数据读取或者写入。
- Kafka地址:10.2.3.14:9092
- Topic名称:r_01
- 消费者组id:8001
- 样例数据:订单1购买了商品1,消费金额1元
{"order_id":1,"product_id":1,"trans_amount":1}
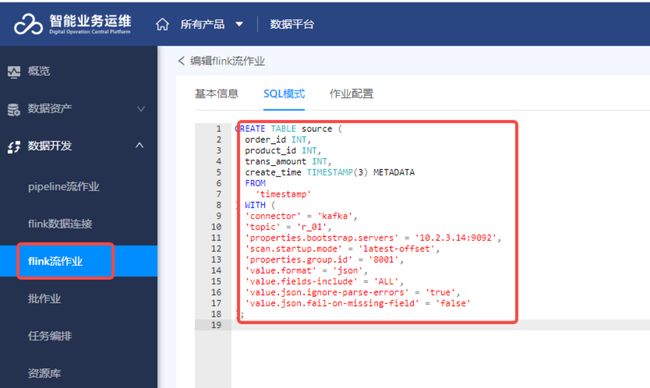
创建Clickhouse动态表
下图为在Flink里创建Clickhouse动态表。此时可以看到Clickhouse的表结构,包含相关字段的数据类型和主键信息,与Flink SQL建表语句中的字段、数据格式和主键也一一对应。 WITH里面是Clickhouse的连接信息和数据操作的配置信息
- Clickhouse地址:10.2.3.14:8123
- 数据库名称:default
- 数据表:product_sale
- 表结构及样例数据如下:
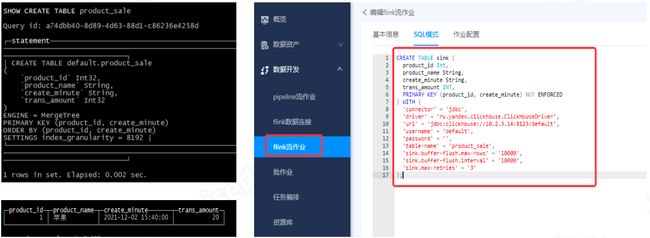
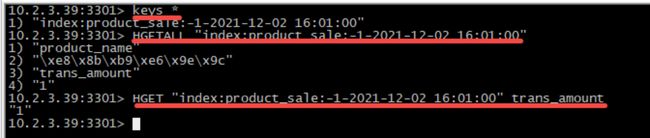
创建Redis动态表
下图为在Flink里创建Redis动态表。由于Redis表设计初衷是用于做维表,故必须包含可供数据关联的主键和用于补齐数据的普通字段,在建表语句里体现为必须设置一个或多个主键,还必须具有一个或多个的普通字段。 数据在Redis中的存储是HASH格式,可以使用HGETALL查看数据内容。
- redis地址:10.2.3.39:3301
- Key前缀:index:product_sale
- redis例数据如下:


Flink SQL连接参数
连接Kafka
-
connector:指定连接器类型,固定值kafka。
-
topic:指需要消费或写入数据的topic。
-
bootstrap.servers:kafka连接地址,可以填写多个,以逗号分割。
-
Broker地址:在集群正常运行时填写一个或多个节点均可读取到数据。此外,当kafka节点较多,topic分区较少时填写一个节点,当topic分区并不在该节点上时,也能够读取到数据。需注意,当kafka服务出现问题时,如果个别节点服务中断,填写多个broker地址可以提高抗风险能力。
-
消费模式
- earliest-offset对应平台中的从头开始消费。任务的每次启动都会按照从前往后的顺序读取topic内现有的所有数据。但是这个顺序是相对的,如果topic有多个分区,存在一定的数据倾斜,那数据较少的分区从数据时间上来看会读的相对快一些。kafka数据的读取是按照分区来读的;
- latest-offset对应平台中的从当前开始消费。任务在启动时会从最新的数据开始读取;
- group-offsets对应平台中的按照group offset消费。这种模式下,任务在第一次启动时会读取最新的数据,在后续任务重启时,会接着上次运行结束时处理到的数据点位继续处理,这种模式也是kafka消费者的默认消费模式。该模式需要配合设置group id,kafka会按照group id把处理数据的偏移量记录下来。由于是kafka记录着偏移量,故group id可以跨平台、跨应用来使用。比如当有一个java任务需要做kafka数据的持久化且由flink来实现,此时flink任务使用即可用与java任务相同的group id来实现任务平滑切换,做到无数据丢失、无数据重复;
-
Group id:用于记录处理数据的偏移量,在任务重启或异常恢复的时候继续从断点开始处理数据。
-
Value.format:kafka消息格式。常用的为csv、json、raw以及多种cdc格式。
-
Ignore-parse-errors:解析失败的原因包含多种,比如部分数据格式不是json,此时便会丢弃整条数据。需注意,如果其中一条json数据中的一个字段格式与建表语句中的格式不同,强转失败时只会影响这一个数据字段,不影响其它字段的解析。
-
Fail-on-missing-field:当kafka消息中缺少create table中定义的字段时是否终止flink任务。

连接Clickhouse
url:这里可以填写单个jdbc url,表示以集群的方式写入逻辑表;也可以填写多个jdbc url,多个url使用逗号间隔,表示以轮询的方式写入Clickhouse本地表;
Table-name:表名只能有一个,在轮询写入本地表的时候,url连接和数据库可以相同或不同,比如同一个url上的不同库,但是表名必须相同;
Flush-max-rows:配合使用可以实现flink到clickhouse的同步输出、半同步输出、异步输出
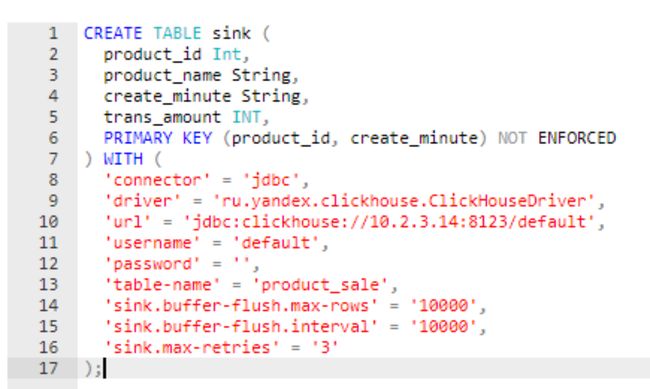
连接Redis
仅支持redis的hash结构,详细数据结构如下:
hash key:{key-prefix}{key-spacer}{k1}{key-spacer}{k2}
hash field:schema中除了key字段之外的其他字段
hash value:存储key之外其他字段对应的值,flink redis schema支持的类型:STRING、BOOLEAN、TINYINT、SMALLINT、INT、BIGINT、DOUBLE
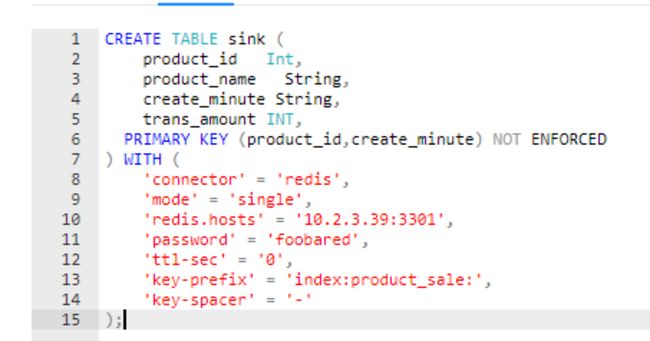
Flink SQL函数
Flink SQL函数分为内置函数和自定义函数
自定义函数:
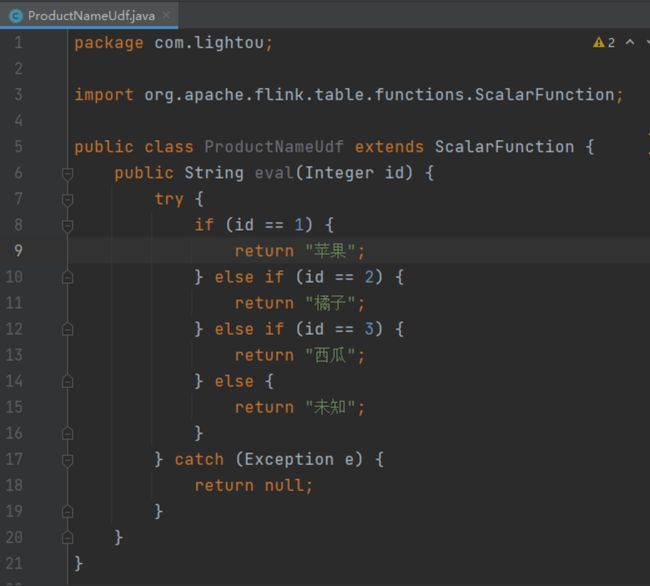
ScalarFunction:行级数据处理,一行的一列或多列数据处理输出一个数据
TableFunction:也是行级数据处理,接受一个或多个参数输入,但是可以输出多行多列数据
AggregateFunction:聚合函数,配合group by使用,可根据多行多列数据计算输出一个指标值
TableAggregateFunction:表聚合函数,配合group by使用,根据多行多列数据计算输出多行多列数据,表聚合函数目前还不能使用在FlinkSQL中,适用于Flink Table API
操作示例:
这里以水果的ID获取到水果名称,演示一下自定义函数的用法。Udf可以使用Java代码来开发,具备java语言的特性,比如多态。示例里的类继承Flink的ScalarFunction,实现了一个eval函数,自定义函数的编写较为简单。此外,还可以根据Java的多态特性编写多个eval函数,实现多类型数据的处理。 编写好的自定义函数,打成jar包后通过平台的资源库页面上传至平台,在编写数据处理任务时,使用 create temporary function的方式引入该自定义函数,即可使用。
Flink SQL案例
需求描述
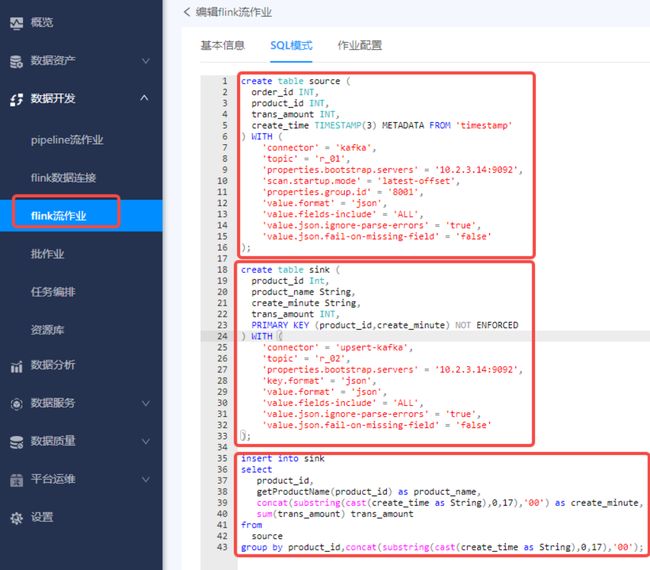
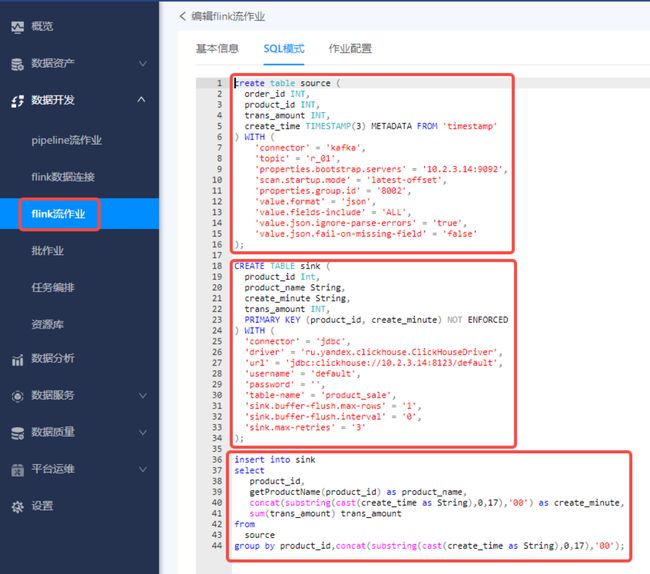
对topic r_01 中的水果销售流水进行统计,得到每种水果每分钟的销售额,将计算结果分别输出到kafka、clickhouse、redis。
topic中数据格式: { "order_id":1, "product_id":1, "trans_amount":1 }
计算结果应包含如下字段: { "product_id":1, "product_name":"苹果", "create_minute":'2021-12-02 12:00:00’, "trans_amount":3 }
具体操作
kafka to kafka
- 创建一个kafka source
- 创建一个kafka sink
- 编写数据处理sql
kafka to clickhouse
- 创建一个kafka source
- 创建一个clickhouse sink
- 编写数据处理sql
kafka to redis
- 创建一个kafka source
- 创建一个redis sink
- 编写数据处理sql
Checkpoint
状态的作用
Checkpoint是Flink存储任务运行状态的一个检查点,状态是flink的一等公民,可以让程序记住运行的中间结果,以便任务异常时的重启恢复
Flink应用异常示例
- 实时统计当日订单总额的程序异常中断,从状态恢复不需要从0点开始重新计算
- 实时ETL同步kafka数据到外部存储异常中断,从状态恢复则不需要从头消费
状态数据的存储
- 可以保存在内存中,当状态数据过大,内存Oom
- 保存在持久化的文件系统中,比如本地或者hdfs
- 通过状态过期时间控制flink应用的状态大小
- 状态数据需要周期性地保存下来,用于故障恢复
如何从检查点恢复
- 读取最近一次checkpoint中的状态数据,比如累计销售额sum值为8000元
- 读取最近一次checkpoint中提交的offset,比如partition 0,offset 1000
- 上述状态数据表明,flink应用程序在消费到(0,1000)这个位点时统计的销售额为8000元
- 应用恢复正常后,从(0,1001)开始消费,sum从8000开始累加
检查点内部状态数据的一致性
- 内部状态数据一致性语义:精确一致或者至少一次
- 同样是上述样例,如果是精确一致性语义,则sum值对每条kafka消息只统计一次,如果是至少一次,则sum值的统计结果有可能偏高
- 如果topic只有一个分区,则是精确一致,因为flink连接kafka source的并行度为分区数,在并行度为1的情况下不存在多流不同时到达的情况
- Kafka多分区情况下,flink默认是多并行度,此时设置为 至少一次语义,再加上多流很大概率不会同时到达,会导致统计结果偏高。
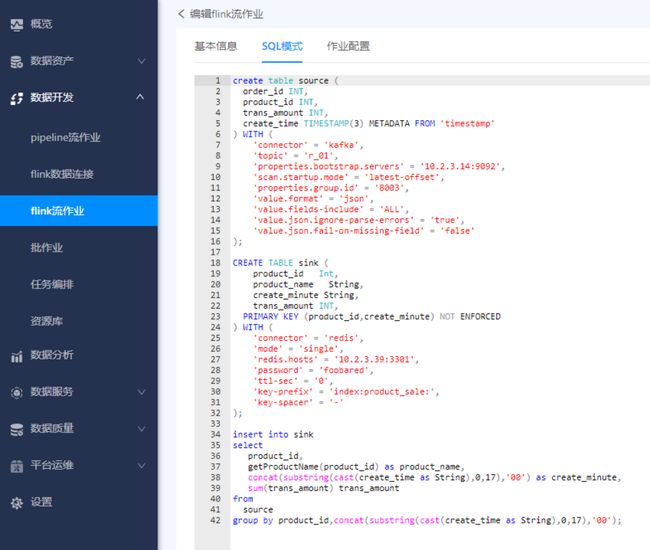
检查点设置
建立flink流任务时可选选择是否开启检查点并设置检查点周期 。开启检查点有两个作用,一是在任务运行发生意外自动重启的时候会从检查点恢复,可以确保任务从异常点继续计算,保持数据连贯性与准确性;另一个作用是在手动停止任务后,再次启动的时候,可以选择是否从上一个检查点继续执行任务。
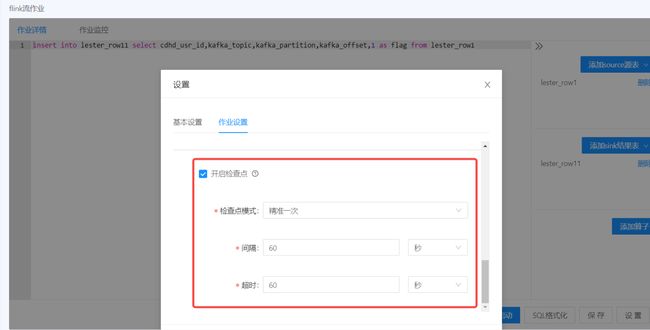
检查点恢复
任务中断后再次启动时可以选择是否从最近一个检查点恢复状态数据。目前支持固定延迟和失败比率的重启策略,分别对应固定重启次数和一段时间内失败次数超过阈值则不再重启。
总结了很多有关于java面试的资料,希望能够帮助正在学习java的小伙伴。由于资料过多不便发表文章,创作不易,望小伙伴们能够给我一些动力继续创建更好的java类学习资料文章,
请多多支持和关注小作,别忘了点赞+评论+转发。右上角私信我回复【03】即可领取免费学习资料谢谢啦!
