ID3决策树学习算法——python实现
本周“人工智能理论与实践”课程老师要求复现决策树算法,本人复现思路参考周志华老师的《机器学习》书中的决策树学习基本算法,数据集使用的是书中“西瓜数据集2.0”。
这是本人的第一篇博客,如有问题还请大家多多指正。完整代码及训练数据已上传至Github。GitHub - MYuan0209/Decision-Tree----ID3
目录
问题描述
决策树
基本概念
划分选择
核心代码
计算当前样本集合中每一类所占的样本比例
计算样本集合的信息熵
计算信息增益
产生决策树
预测样本
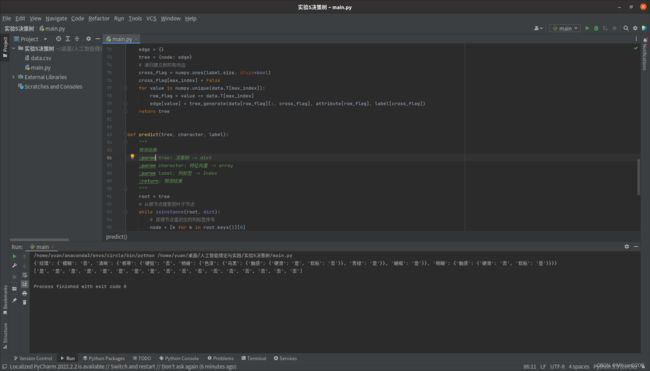
运行结果
问题描述
给定一个西瓜特征与是否为好瓜对应的表格,利用决策树判断是否为好瓜。
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
决策树
基本概念
决策树是一类常见的机器学习方法,其本质是通过树的结构来完成二分类任务。
决策树一般包含一个根节点,若干个内部节点和若干个叶子节点。其中叶子节点对应的是决策结果,其它每个节点对应的是一个属性测试。每个节点包含的样本集合根据属性测试的结果被划分到其子节点中,从根节点到每个叶子节点的路径对应着一个判定序列。
划分选择
我们如何选择属性测试的顺序从而达到最优划分?一般而言,我们希望每次划分后能够让尽可能多的样本属于同一类别。ID3决策树学习算法是以信息增益为准则来选择划分属性。
假定当前样本集合D中第k类样本所占的比例为![]() (k = 1, 2, ...,
(k = 1, 2, ..., ![]() ),则D的信息熵定义为
),则D的信息熵定义为
![]()
假定离散属性a有V个可能的取值{![]() },若使用a来对样本集合D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为
},若使用a来对样本集合D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为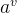 的样本,记为
的样本,记为![]() 。属性a对样本集合D进行划分所获得的信息增益为
。属性a对样本集合D进行划分所获得的信息增益为
![]()
一般而言,信息增益越大,则代表着使用属性a来进行划分后样本尽可能多的属于同一个类别。ID3决策树学习算法使用的选择属性公式为
![]()
核心代码
计算当前样本集合中每一类所占的样本比例
def probability(x):
"""
求当前样本集合D中每一类样本所占的比例
:param x:
:return:
"""
return [x[val == x].size / x.size for val in numpy.unique(x)]计算样本集合的信息熵
def information_entropy(attribute):
"""
求样本集合x的信息熵
:param attribute: 结果 -> array
:return: 结果的信息熵 -> float
"""
p = probability(attribute)
return -numpy.sum(p * numpy.log2(p))
计算信息增益
def conditional_information_entropy(data, attribute):
"""
求条件信息熵
:param data: 输入 -> array
:param attribute: 结果 -> array
:return: 条件信息熵 -> array
"""
return [numpy.sum([data[val == data].size / data.size * information_entropy(attribute[val == data])
for val in numpy.unique(data)]) for data in data.T]
def information_gain(data, attribute):
"""
求信息增益
:param data: 输入 -> array
:param attribute: 结果 -> array
:return: 每一列的信息增益 -> array
"""
ent = information_entropy(attribute)
ce = numpy.array(conditional_information_entropy(data, attribute))
return ent - ce产生决策树
def tree_generate(data, attribute, label):
"""
产生决策树
:param data: 输入 -> array
:param attribute: 结果 -> array
:param label: 列标签 -> Index
:return: 决策树 -> dict
"""
# 如果输入全属于同一类别或所有输入的结果取值相同,直接返回结果
p = probability(attribute)
if data.shape[1] == 1 or p[0] == 1:
return attribute[numpy.argmax(p)]
# 获得最大信息增益所对应的序号
nodes = information_gain(data, attribute)
max_index = nodes.argmax()
# 建立树的根节点
node = label[max_index]
edge = {}
tree = {node: edge}
# 递归建立树的有向边
cross_flag = numpy.ones(label.size, dtype=bool)
cross_flag[max_index] = False
for value in numpy.unique(data.T[max_index]):
row_flag = value == data.T[max_index]
edge[value] = tree_generate(data[row_flag][:, cross_flag], attribute[row_flag], label[cross_flag])
return tree预测样本
def predict(tree, character, label):
"""
预测函数
:param tree: 决策树 -> dict
:param character: 特征向量 -> array
:param label: 列标签 -> Index
:return: 预测结果
"""
root = tree
# 从根节点搜索到叶子节点
while isinstance(root, dict):
# 获得节点值对应的列标签序号
node = [k for k in root.keys()][0]
index = numpy.where(label == node)[0][0]
# 将根节点改为对应序号的子节点
edge = root[node]
root = edge[character[index]]
return root运行结果