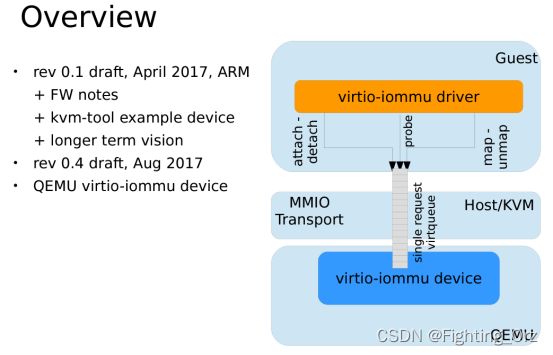
virtio iommu
1 简介 5
1.1 文档说明 5
1.1.1 背景 5
1.1.2 内容简介 5
1.1.3 适用范围 5
1.2 缩略语 5
1.3 参考资料 5
2 Virtio 5
2.1 Virtio 介绍 6
2.2 virtio简介 8
2.3 Virtio:一种Linux I/O虚拟化框架 13
2.4 linux virtiommu 18
3 SMMU 19
3.1 缩略语 19
3.2 DMA介绍 20
3.3 虚拟化技术 - I/O虚拟化 22
3.4 透传 - Device Passthrough 22
3.5 虚拟化技术 - 内存虚拟化 23
3.6 软件实现 - 影子页表 24
3.7 硬件辅助 - EPT/NPT 25
3.8 EPT/NPT MMU优化 27
4 SMMU和IOMMU技术 29
4.1 ARM的SMMU 29
4.2 ARM SMMU的原理与IOMMU 33
4.2.1 arm smmu的原理 33
4.2.2 smmu驱动与iommu框架 38
5 iommu-viommu(virtio-iommu) 45
5.1 virtio iommu - full emulate 45
5.2 virtio 详细介绍 46
5.3 IOMMU(四)-dma remapping 51
5.4 网上查找资料 51
5.5 virtio 虚拟化系列之一:从 virtio 论文开始 52
5.5.1 地址转换 53
5.5.2 Virtio-blk 后端 53
5.5.3 Virtio-blk 前端 54
5.5.4 总结 55
5.6 Qemu模拟IO和半虚拟化Virtio的区别以及I/O半虚拟化驱动介绍 55
5.6.1 QEMU的基本原理和优缺点 55
5.6.2 半虚拟化virtio的基本原理和优缺点 56
6 virtio-iommu 57
6.1 iommu datastruct 57
6.2 virtio iommu patch 60
6.3 dpdk vhost-uesr对vIOMMU的支持 62
6.3.1 DMA remapping 62
6.3.2 Interrupt remapping 65
6.3.3 总结 66
6.4 driver_probe 67
6.5 [2016] An Introduction to PCI Device Assignment with VFIO by Alex Williamson 68
6.6 vfio 73
6.7 KVM详解,太详细太深入了,经典 75
6.7.1 vhost-net (kernel-level virtio server) 78
7 pKVM 79
8 smmu_spec 80
9 vfio与iommu关系 81
9.1 vfio 设备直通简介 82
9.2 VFIO(Virtual Function IO)研究 84
9.2.1 研究目的 84
9.2.2 IOMMU 84
9.3 IOMMU历史知识及与VFIO的联系 85
9.4 Virtual IOMMU(cloud) 88
9.4.1 基本原理 88
9.4.2 为什么是 virtio-iommu? 89
9.5 linux doc for vfio 90
- 简介
- 文档说明
- 背景
- 内容简介
- 文档说明
-
-
- 适用范围
-
-
- 缩略语
表 1 缩略语
| 词语 |
解释 |
| crosVM |
Rust轻量级虚拟化VMM |
| KVM |
内核虚拟化模块 |
| pKVM |
Protected KVM |
-
- 参考资料
CROSVM官方文档: Introduction - Book of crosvm
- Virtio
- 本章节介绍了X86版本和ARM64版本crosVM的模拟环境.ARM64的稍复杂一点,需要先模拟一个ARM64 Host Server,再在其上运行crosVM.
为解决这些问题,Rusty Russell开发了virtio机制,其是一个在hypervisor之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,从而与hypervisor根据virtio标准协作,从而在Guest中达到更好的性能(特别是I/O性能),关于virtio在其论文中如此定义:
virtio:a series of efficient,well-maintained Linux drivers which can be adapted for various different hypervisor implementations using a shim layer.This includes a simple extensible feature mechanism for each driver.
理解: 正如Linux提供了各种hypervisor解决方案,这些解决方案都有自己的特点和优点。这些解决方案包括 Kernel-based Virtual Machine (KVM)、lguest和User-mode Linux等。在这些解决方案中需要各自实现自身平台下的设备虚拟化。而virtio为这些设备模拟提供了一个通用的前端,标准化了接口和增加了代码的跨平台重用。virtio提供了一套有效,易维护、易开发、易扩展的中间层 API,它为 hypervisor 和一组通用的 I/O虚拟化驱动程序提供高效的抽象。减少了各类平台下大量驱动开发的负担。
-
- Virtio 介绍
- virtio 即是这样一种利用半虚拟化技术提供I/O性能的框架
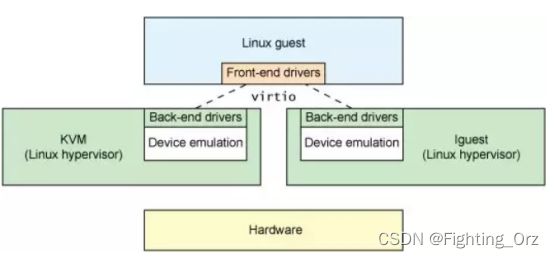
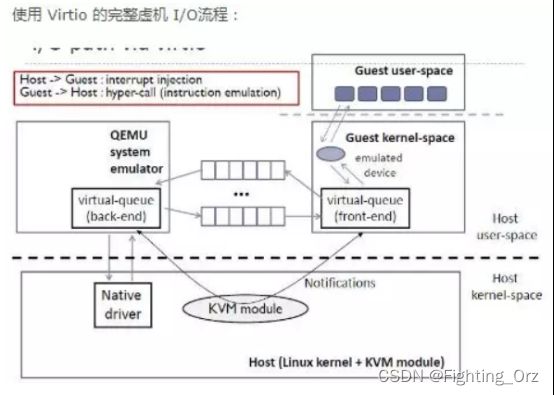
virtio 是一种前后端架构,包括前端驱动(Front-End Driver)和后端设备(Back-End Device)以及自身定义的传输协议。通过传输协议,virtio不仅可以用于QEMU/KVM方案,也可以使用其他的虚拟化方案。如虚拟机可以不必是QEMU,也可以是其他类型的虚拟机,后端不一定要在QEMU中实现,也可以在内核中实现(即vhost方案)
前端驱动为虚拟机内部的virtio模拟设备对应的驱动,每一种前端设备都需要有对应的驱动才能正常运行。前端驱动的主要作用是接收用户态的请求,然后按照传输协议将这些请求进行封装,再写I/O端口,发送一个通知到QEMU的后端设备。
后端设备则是在QEMU中,用来接收前端驱动发过来的I/O请求,然后从接收的数据中按
照传输协议的格式进行解析,对于网卡等需要实际物理设备交互的请求,后端驱动会对物理设备进行操作,从而完成请求,并且会通过中断机制通知前端驱动。
virtio前端和后端驱动的数据传输通过virtio队列(virtio queue,virtqueue)完成,一个设备会注册若干个virtio队列,每个队列负责处理不同的数据传输,有的是控制层面的队列,有的是数据层面的队列。virtqueue是通过vring实现的。vring是虚拟机和QEMU之间共享的一段环形缓冲区。当虚拟机需要发送请求到QEMU的时候就准备好数据,将数据描述放到vring中,写一个I/O端口,然后QEMU就能够从vring中读取数据信息,进而从内存中读出数据。QEMU完成请求之后,也将数据结构存放在vring中,前端驱动也就可以从vring中得到数据。vring的基本原理如图1所示

图1 vring原理
vring包含3个部分,第一部分是描述符表(Descriptor Table),用来表述I/O请求的传输数据信息,包括地址、长度等信息,第二部分是可使用的vring(Available Vring),这是前端驱动设置的表示后端设备可用的描述符表中的索引,第三部分已经使用的vring(Used Vring)是后端设备在使用完描述符表后设置的索引,这样前端驱动可以知道哪些描述符已经被用了。这里只是简单介绍了vring的基本组成,后面会详细介绍各个部分以及virtio协议的具体实现机制。
virtio设备是由一个PCI的控制器添加的,其本质上是一个virtio设备,会挂到virtio总线上,所以PCI总线上只会显示其驱动为virtio-pci
eventfd 是一个用来通知事件的文件描述符,timerfd 是定时器时间的文件描述符。二者都是内核向用户空间的应用发送通知的机制,可以有效地被用来实现用户空间的事件/通知驱动的应用程序
简单来说,就是eventfd用来触发事件通知,timerfd用来触发将来的事件通知
eventfd不仅可以用于进程之间的通信,还能用于用户态和内核态的通信
eventfd本质上是一个系统调用,创建一个事件通知fd,在内核内部创建有一个eventfd对象,可以用来实现进程之间的等待/通知机制,内核也可以利用eventfd来通知用户态进程事件
- 百度百科 virtio
除了前端驱动程序(在来宾操作系统中实现)和后端驱动程序(在 hypervisor 中实现)之外,virtio 还定义了两个层来支持来宾操作系统到 hypervisor 的通信。在顶级(称为 virtio)的是虚拟队列接口,它在概念上将前端驱动程序附加到后端驱动程序。驱动程序可以使用 0 个或多个队列,具体数量取决于需求。例如,virtio 网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而 virtio 块驱动程序仅使用一个虚拟队列。虚拟队列实际上被实现为跨越来宾操作系统和 hypervisor 的衔接点。但这可以通过任意方式实现,前提是来宾操作系统和 hypervisor 以相同的方式实现它
- kvm虚拟化基础
virtio 标准,是一个与Hypervisor 独立的、构建设备驱动的接口,允许多种HyperVisor使用一组相同的设备驱动程序,能够实现更好的对客户机的互操作性
virtio是一个沟通客户机前端设备与宿主机上设备后端模拟的比较高性能的协议
-
- virtio简介
参考链接:virtio 简介 - bakari - 博客园
- 什么是 virtio
virtio 是一种 I/O 半虚拟化解决方案,是一套通用 I/O 设备虚拟化的程序,是对半虚拟化 Hypervisor 中的一组通用 I/O 设备的抽象。提供了一套上层应用与各 Hypervisor 虚拟化设备(KVM,Xen,VMware等)之间的通信框架和编程接口,减少跨平台所带来的兼容性问题,大大提高驱动程序开发效率。
- 为什么是 virtio#
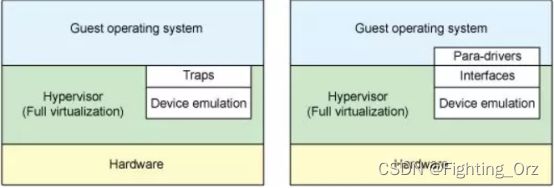
在完全虚拟化的解决方案中,guest VM 要使用底层 host 资源,需要 Hypervisor 来截获所有的请求指令,然后模拟出这些指令的行为,这样势必会带来很多性能上的开销。半虚拟化通过底层硬件辅助的方式,将部分没必要虚拟化的指令通过硬件来完成,Hypervisor 只负责完成部分指令的虚拟化,要做到这点,需要 guest 来配合,guest 完成不同设备的前端驱动程序,Hypervisor 配合 guest 完成相应的后端驱动程序,这样两者之间通过某种交互机制就可以实现高效的虚拟化过程。
由于不同 guest 前端设备其工作逻辑大同小异(如块设备、网络设备、PCI设备、balloon驱动等),单独为每个设备定义一套接口实属没有必要,而且还要考虑扩平台的兼容性问题,另外,不同后端 Hypervisor 的实现方式也大同小异(如KVM、Xen等),这个时候,就需要一套通用框架和标准接口(协议)来完成两者之间的交互过程,virtio 就是这样一套标准,它极大地解决了这些不通用的问题。
- virtio 的架构#
从总体上看,virtio 可以分为四层,包括前端 guest 中各种驱动程序模块,后端 Hypervisor (实现在Qemu上)上的处理程序模块,中间用于前后端通信的 virtio 层和 virtio-ring 层,virtio 这一层实现的是虚拟队列接口,算是前后端通信的桥梁,而 virtio-ring 则是该桥梁的具体实现,它实现了两个环形缓冲区,分别用于保存前端驱动程序和后端处理程序执行的信息。
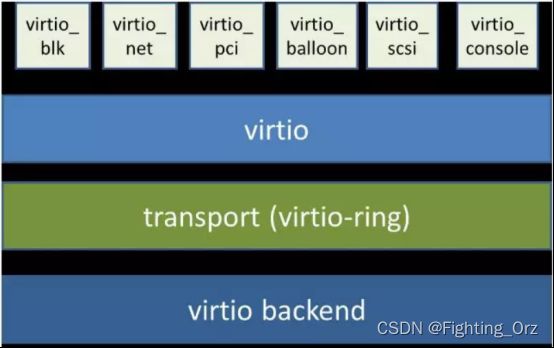
严格来说,virtio 和 virtio-ring 可以看做是一层,virtio-ring 实现了 virtio 的具体通信机制和数据流程。或者这么理解可能更好,virtio 层属于控制层,负责前后端之间的通知机制(kick,notify)和控制流程,而 virtio-vring 则负责具体数据流转发。
- virtio 数据流交互机制#
vring 主要通过两个环形缓冲区来完成数据流的转发,如下图所示。
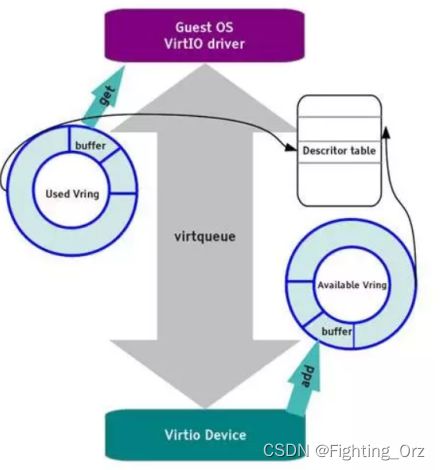
vring 包含三个部分,描述符数组 desc,可用的 available ring 和使用过的 used ring。
desc 用于存储一些关联的描述符,每个描述符记录一个对 buffer 的描述,available ring 则用于 guest 端表示当前有哪些描述符是可用的,而 used ring 则表示 host 端哪些描述符已经被使用。
Virtio 使用 virtqueue 来实现 I/O 机制,每个 virtqueue 就是一个承载大量数据的队列,具体使用多少个队列取决于需求,例如,virtio 网络驱动程序(virtio-net)使用两个队列(一个用于接受,另一个用于发送),而 virtio 块驱动程序(virtio-blk)仅使用一个队列。
具体的,假设 guest 要向 host 发送数据,首先,guest 通过函数 virtqueue_add_buf 将存有数据的 buffer 添加到 virtqueue 中,然后调用 virtqueue_kick 函数,virtqueue_kick 调用 virtqueue_notify 函数,通过写入寄存器的方式来通知到 host。host 调用 virtqueue_get_buf 来获取 virtqueue 中收到的数据。
存放数据的 buffer 是一种分散-聚集的数组,由 desc 结构来承载,如下是一种常用的 desc 的结构:
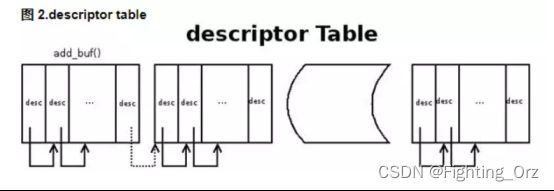
当 guest 向 virtqueue 中写数据时,实际上是向 desc 结构指向的 buffer 中填充数据,完了会更新 available ring,然后再通知 host。
当 host 收到接收数据的通知时,首先从 desc 指向的 buffer 中找到 available ring 中添加的 buffer,映射内存,同时更新 used ring,并通知 guest 接收数据完毕。
- 总结:#
virtio 是 guest 与 host 之间通信的润滑剂,提供了一套通用框架和标准接口或协议来完成两者之间的交互过程,极大地解决了各种驱动程序和不同虚拟化解决方案之间的适配问题。
virtio 抽象了一套 vring 接口来完成 guest 和 host 之间的数据收发过程,结构新颖,接口清晰。
-
- Virtio:一种Linux I/O虚拟化框架
参考:Virtio:一种Linux I/O虚拟化框架 - 安全客,安全资讯平台
简言之,virtio是设备和半虚拟化管理程序(paravirtualized hypervisor)之间的一个抽象层。virtio是Rusty Russell为了支持他自己的虚拟化方案lguest而开发的。这篇文章以对半虚拟化和设备仿真的介绍开始,然后探寻virtio中的一些细节。采用kernel 2.6.30版本的virtio框架进行讲解。
Linux是hypervisor的“游乐场”。正如我在文章使用Linux作为hypervisor中所展现的,Linux提供了许多具有不同特性和优势的虚拟化解决方案。例如KVM(Kernel-based Virtual Machine),lguest、和用户态的Linux。在Linux使用这些虚拟化解决方案给操作系统造成了重担,因为它们各自都有独立的需求。其中一个问题就是设备的虚拟化。virtio为各种各样设备(如:网络设备、块设备等等)的虚拟提供了通用的标准化前端接口,增加了各个虚拟化平台的代码复用。而不是各自为政般的使用繁杂的设备虚拟机制。
在Linux使用这些虚拟化解决方案给操作系统造成了重担,因为它们各自都有独立的需求。其中一个问题就是设备的虚拟化。virtio为各种各样设备(如:网络设备、块设备等等)的虚拟提供了通用的标准化前端接口,增加了各个虚拟化平台的代码复用。而不是各自为政般的使用繁杂的设备虚拟机制。
- 全虚拟化 vs. 半虚拟化
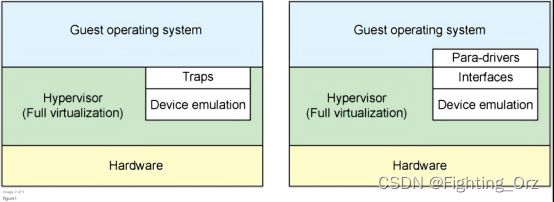
我们先来讨论两种完全不同的虚拟化方案:全虚拟化和半虚拟化。在全虚拟化中,客户操作系统在hypervisor上运行,相当于运行于裸机一般。客户机不知道它在虚拟机还是物理机中运行,不需要修改操作系统就可以直接运行。与此相反的是,在半虚拟化中,客户机操作系统不仅能够知道其运行于虚拟机之上,也必须包含与hypervisor进行交互的代码。但是能够在客户机和hypervisor的切换中,带来更高的效率(图1)。
译注:客户机与hypervisor的切换举例:客户机请求I/O,需要hypervisor中所虚拟的设备来响应请求,此时就会发生切换。
在全虚拟化中,hypervisor必须仿真设备硬件,也就是说模仿硬件最底层的会话(如:网卡驱动)。尽管这种仿真看起来方便,但代价是极低的效率和高度的复杂性。在半虚拟化中,客户机与hypervisor可以共同合作让这种仿真具有更高的效率。半虚拟化不足就是客户机操作系统会意识到它运行于虚拟机之中,而且需要对客户机操作系统做出一定的修改。
硬件也随着虚拟化不断地发展着。新处理器加入了高级指令,使客户机操作系统和hypervisor的切换更加高效。硬件也随着I/O虚拟化不断地发生改变(参照Resource了解PCI passthrough和单/多根I/O虚拟化)。
在传统的全虚拟化环境中,hypervisor必须陷入(trap)请求,然后模仿真实硬件的行为。尽管这样提供了很大的灵活性(指可以运行不必修改的操作系统),但却造成了低效率(图1左侧)。图1右侧展示了半虚拟化。客户机操作系统知道运行于虚拟机之中,加入了驱动作为前端。hypervisor为特定设备仿真实现了后端驱动。这里的前端后端就是virtio的构件,提供了标准化接口,提高了设备仿真开发的代码复用程度和仿真设备运行的效率。
作者注:virtio并不是半虚拟化领域的唯一存在。Xen提供了半虚拟化的设备驱动,VMware也提供了名为Guest Tools的半虚拟化支持。
- Linux客户机中的一种抽象
如前节所述,virtio为半虚拟化提供了一系列通用设备仿真的接口。这种设计允许hypervisor导出一套通用的设备仿真操作,只要使用这一套接口就能够工作。图2解释了为什么这很重要。通过半虚拟化,客户机实现了通用的接口,同时虚拟化管理程序提供设备仿真的后端驱动。后端驱动并不一定要一致,只要它实现了前端所需的各种操作就可以。
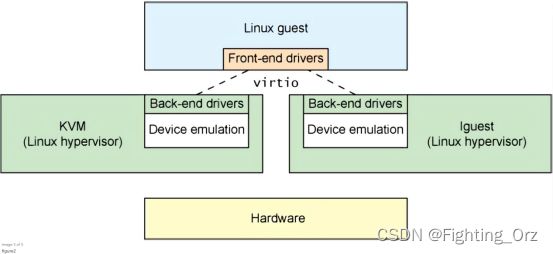
注意在实际中,使用用户空间的QEMU程序来进行设备仿真,所以后端驱动通过QEMU的I/O来与用户空间的hypervisor通信。QEMU是系统模拟器,包括提供客户机操作系统虚拟化平台,提供整个系统的仿真(PCI host controller, disk, network, video hardware, USB controller等)。
virtio依靠于简单的缓存管理,用来存储客户机的命令与客户机所需的数据。我们继续来看virtio的API及其构件。
- Virtio 架构
除了前端驱动(在客户机操作系统中实现)和后端驱动(在hypervisor中实现)之外,virtio还定义了两层来支持客户机与hypervisor进行通讯。虚拟队列(Virtual Queue)接口将前端驱动和后端驱动结合在一起。驱动可以有0个或多个队列,依赖于它们的需要。例如,virtio网络驱动使用了两个虚拟队列(一个用于接收一个用于发送),而virtio块设备驱动只需要一个。虚拟队列,通常使用环形缓冲,在客户机与虚拟机管理器之间传输。可以使用任意方式实现,只要客户机与虚拟机管理器相统一。

如图3,包含了五种前端驱动:块设备(如硬盘)、网络设备、PCI仿真、balloon驱动(用于动态的管理客户机内存使用)和一个终端驱动。每一个前端驱动,在hypervisor中都有一个相匹配的后端驱动。
- 概念层级
在客户机的视角来看,对象层级如图4所示。顶端是virtio_driver,表示客户机中的前端驱动。与驱动相匹配的设备被封装在virtio_device(在客户机中表示设备),其中有成员config指向virtio_config_ops结构(其中定义了配置virtio设备的操作)。virtqueue中有成员vdev指向virtio_device(也就是指向它所服务的某一设备virtio_device)。最下面,每个virtio_queue中有个类型为virtqueue_ops的对象,其中定义了与hypervisor交互的虚拟队列操作。
图4. virtio前端的对象层级
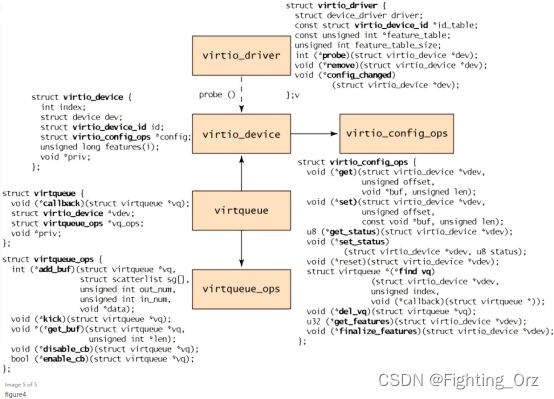
这一过程起始于virtio_driver的创建和后续的使用register_virtio_driver将驱动进行注册。virtio_driver结构定义了设备驱动的上层结构,包含了它所支持的设备的设备ID,特性表(根据设备的类型有所不同),和一系列回调函数。当hypervisor发现新设备,并且匹配到了设备ID,就会以virtio_device为参数调用probe函数(于virtio_driver中提供)。这一结构与管理数据一起被缓存(以独立于驱动的方式)。根据设备的类型,virtio_config_ops中的可能会被调用,以获取或设置设备相关的选项(例如,获取硬盘块设备的读/写状态或者设置块设备的块大小)。
注意,virtio_device中没有包含指向所对应virtqueue的成员(virtqueue有指向virtio_device的成员)。为了得到与virtio_device相关联的virtqueue,需要使用virtio_config_ops结构中的find_vq函数。这个函数返回与该virtqueue相关联的设备实例。find_vq还允许为virtqueue指定回调函数,用于在hypervisor准备好数据时,通知客户机。
virtqueue结构包含可选的回调函数(用于在hypervisor填充缓冲后,通知客户机)、一个指向virtio_device、一个指向virtqueue操作和一个特别的priv用于底层实现使用。callback是可选的,也可以动态的启用或禁用。
这个层级的核心是virtqueue_ops,其中定义了如何在客户机和hypervisor之间传输命令与数据。我们先来探索virtqueue中对象的添加和删除操作。
- Virtio缓冲
客户机驱动(前端)与hypervisor(后端)通过缓冲区进行通信。对于一次I/O,客户机提供一个或多个缓冲区表示请求。例如,你可以使用三个缓冲区,其中一个用来存储读请求,其他两个用来存储回复数据。内部这个配置被表示为分散/聚集(scatter-gather)列表(列表中的每个元素存储有缓冲区地址与长度)。
- 核心API
将客户机驱动与hypervisor驱动链接起来,偶尔是通过virtio_device,大多数情况下都是通过virtqueue。virtqueue支持五个API函数。使用第一个函数add_buf向hypervisor添加请求,这种请求以分散/聚集列表的形式,正如先前讨论的。为了提交请求,客户机必须提供请求命令,分散/聚集列表(以缓冲区地址和长度为元素的数组),向外提供请求的缓冲区的数量(也就是发送请求信息给hypervisor),向内传递数据的缓冲区的数量(hypervisor用来填充数据,返回给客户机)。当客户机通过add_buf向hypervisor提交一条请求后,客户机就可以使用kick通知hypervisor新请求已递送。但为了更好地性能,客户机应该在kick通知hypervisor之前,提交尽可能多的请求。
客户机使用get_buf接收从hypervisor中返回的数据。客户机可以简单地使用get_buf轮询或者等待由virtqueue callback函数的通知。当客户机知道了缓冲区数据可用,就会使用get_buf获取数据。
最后两个virtqueue的API是enable_cb和disable_cb,可用使用这两个函数启用和禁用回调函数(callback函数使用find_vq初始化设置)。注意回调函数与hypervisor在不同的地址空间,所以调用需要间接调用(indirect hypervisor call)(例如:kvm_hypercall)。
缓冲区的格式、顺序与内容仅对前端和后端驱动有意义。内部传送(现在使用环形缓冲区实现)只传输缓冲区,并不知道内部表达的意义。
- Virtio驱动例子
对于各种各样前端驱动,可以在Linux内核源码的./drivers子目录下找到。virtio网络驱动在./driver/net/virtio_net.c,virtio块驱动在./driver/block/virtio_blk.c。./driver/virtio子目录下提供了virtio接口的实现(virtio设备、驱动、virtqueue和环形缓冲区)。virtio也被用在了高性能计算(High-Performance Computing, HPC)研究之中,使用共享内存传递内部虚拟机的信息。特别的,这使用了virtio来实现虚拟化PCI接口。可以再resources中找到相关工作。
你可以在Linux内核中练习半虚拟化基础工作。你所需要的就是一个作为hypervisor的内核,客户机内核和用来仿真设备的QEMU。你可以使用KVM(一个存在于宿主机内核中的模块)或者Rusty Russell的lguest(一个修改过的Linux内核)。两种方案都支持virtio(配合以QEMU进行系统模拟和libvirt进行虚拟化管理)。
Rusty的成果是简化了半虚拟化驱动的开发,并且设备仿真性能更高。最重要的还是,virtio能够提供更好地性能(两三倍的网络I/O)比现有的商业解决方案。虽说有一定的代价,但如果你的hypervisor和客户机系统是Linux,还是非常值得的。
- 进一步
尽管你可以永远不会为virtio开发前端或者后端驱动,但它实现了一个有趣的架构,值得更加细致的理解它。与先前的Xen相比,virtio为了半虚拟化提高性能提供了新的可能。在作为投入使用的hypervisor和新虚拟技术的实验平台中,Linux不断地证明了它自己。virtio再一次证明了Linux作为hypervisor的优势和开放性。
-
- linux virtiommu
参考链接:[RFC 0/3] virtio-iommu: a paravirtualized IOMMU
The description itself seemed too long for a single email, so I split it
into three documents, and will attach Linux and kvmtool patches to this
email.
1. Firmware note,
2. device operations (draft for the virtio specification),
3. future work/possible improvements.
Just to be clear on the terms I'm using:
pIOMMU physical IOMMU, controlling DMA accesses from physical devices vIOMMU virtual IOMMU (virtio-iommu), controlling DMA accesses from physical and virtual devices to guest memory.
GVA, GPA, HVA, HPA
Guest/Host Virtual/Physical Address
IOVA I/O Virtual Address, the address accessed by a device doing DMA through an IOMMU. In the context of a guest OS, IOVA is GVA.
Note: kvmtool is GPLv2. Linux patches are GPLv2, except for UAPI
virtio-iommu.h header, which is BSD 3-clause. For the time being, the
specification draft in RFC 2/3 is also BSD 3-clause.
- SMMU
参考链接:ARM SMMU原理与IOMMU技术(“VT-d” DMA、I/O虚拟化、内存虚拟化)_rtoax的博客-CSDN博客_smmu 虚拟化
-
- 缩略语
表 1 virtio iommu缩略语
| 词语 |
解释 |
| KVM |
Kernel-based Virtual Machine,一种基于Linux内核的Type II虚拟机技术 |
| ASID |
Address Space ID 地址空间标识符 |
| CD |
Context Descriptor; 上下文描述符 |
| CTP |
Context-table pointer 上下文表指针 |
| EPT |
Extended Page Table 扩展页表 |
| GPA |
Guest Phyical Address guest 物理地址 |
| GVA |
Guest Virtual Address |
| HPA |
Host Phyical Address |
| IOVA |
IO Virtual Address space IO虚拟地址空间 |
| IPA |
Intermediate Phyical Address |
| NPT |
Nested Page Table 嵌套页表 |
| PCID |
Process context identifier 进程上下文标识符 |
| PMCG |
Performance Monitor Counter Groups 性能监控计数器组 |
| S2TTB |
Stage 2 Translate Table Base |
| SMMU |
System MMU 系统MMU |
| VT-d |
Virtualization Technology for Direct I/O 直接I/O虚拟化技术 |
关键:
MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA);
IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA;
IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译;
专门转换I/O地址的MMU在x86的阵营里就是IOMMU;
Intel把IOMMU技术叫做VT-d(Virtualization Technology for Direct I/O);
EPT/NPT MMU作为传统MMU的扩展,也是有TLB;
ARM公司主要是依靠出售core的license来赚钱的;
能够有能力完成设备iova 到 pa转换的有很多,例如有intel iommu, amd的iommu
-
- DMA介绍
DMA是指在不经过CPU干预的情况下外设直接访问(Read/Write)主存(System Memroy)的能力。
DMA带来的最大好处是:CPU不再需要干预外设对内存的访问过程,而是可以去做其他的事情,这样就大大提高了CPU的利用率。
在设备直通(Device Passthough)的虚拟化场景下,直通设备在工作的时候同样要使用DMA技术来访问虚拟机的主存以提升IO性能。那么问题来了,直接分配给某个特定的虚拟机的,我们必须要保证直通设备DMA的安全性,一个VM的直通设备不能通过DMA访问到其他VM的内存,同时也不能直接访问Host的内存,否则会造成极其严重的后果。因此,必须对直通设备进行“DMA隔离”和“DMA地址翻译”,隔离将直通设备的DMA访问限制在其所在VM的物理地址空间内保证不发生访问越界,地址翻译则保证了直通设备的DMA能够被正确重定向到虚拟机的物理地址空间内。
为什么直通设备会存在DMA访问的安全性问题呢?
原因也很简单:由于直通设备进行DMA操作的时候guest驱动直接使用gpa来访问内存的,这就导致如果不加以隔离和地址翻译必然会访问到其他VM的物理内存或者破坏Host内存,因此必须有一套机制能够将gpa转换为对应的hpa这样直通设备的DMA操作才能够顺利完成。
VT-d DMA Remapping的引入就是为了解决直通设备DMA隔离和DMA地址翻译的问题
地址空间标志(address-space-identifier)
首先要明确的是DMA Isolation是以Domain为单位进行隔离的,在虚拟化环境下可以认为每个VM的地址空间为一个Domain,直通给这个VM的设备只能访问这个VM的地址空间这就称之为“隔离”。根据软件的使用模型不同,直通设备的DMA Address Space可能是某个VM的Guest Physical Address Space或某个进程的虚拟地址空间(由分配给进程的PASID定义)或是由软件定义的一段抽象的IO Virtual Address space (IOVA),总之DMA Remapping就是要能够将设备发起的DMA Request进行DMA Translation重映射到对应的HPA上。
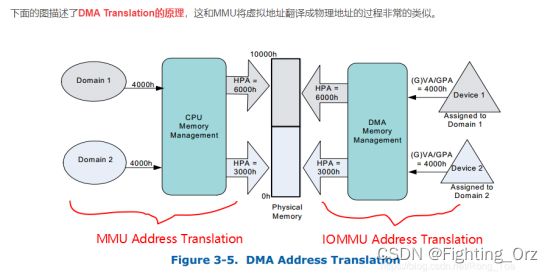
VT-d中引入root-table和context-table的目的比较明显,这些额外的table的存在就是为了记录每个直通设备和其被分配的Domain之间的映射关系。 有了这个映射关系后,DMA隔离的实现就变得非常简单。 IOMMU硬件会截获直通设备发出的请求,然后根据其Request ID查表找到对应的Address Translation Structure即该Domain的IOMMU页表基地址, 这样一来该设备的DMA地址翻译就只会按这个Domain的IOMMU页表的方式进行翻译,翻译后的HPA必然落在此Domain的地址空间内(这个过程由IOMMU硬件中自动完成), 而不会访问到其他Domain的地址空间,这样就达到了DMA隔离的目的。
DMA地址翻译的过程和虚拟地址翻译的过程是完全一致的,唯一不同的地方在于MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA),而IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA。IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译。例如,对于一个48bit的GPA地址空间的Domain而言,其IOMMU Page Table共分4级,每一级都是一个4KB页含有512个8-Byte的目录项。和MMU页表一样,IOMMU页表页支持2M/1G大页内存,同时硬件上还提供了IO-TLB来缓存最近翻译过的地址来提升地址翻译的速度。
-
- 虚拟化技术 - I/O虚拟化
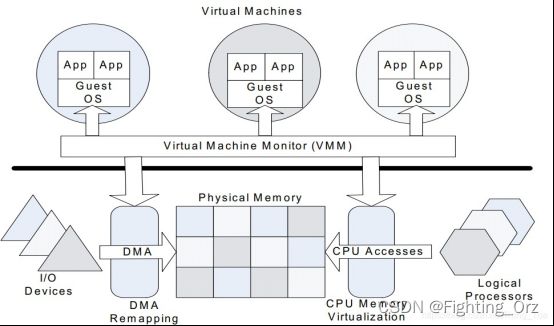
在虚拟化系统中,I/O外设只有一套,需要被多个guest VMs共享。VMM/hypervisor提供了两种机制来实现对I/O设备的访问,一种是透传(passthrough),一种是模拟(emulation)。
-
- 透传 - Device Passthrough
所谓passthrough,就是指guest VM可以透过VMM,直接访问I/O硬件,这样guest VM的I/O操作路径几乎和无虚拟化环境下的I/O路径相同,性能自然是非常高的。
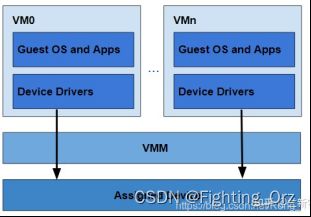
在虚拟化环境下,guest VM使用的物理地址是GPA,如果直接用guest OS中的驱动程序去操作I/O设备的话(这里的I/O限定于和内存统一编址的MMIO),那么设备使用的地址也是GPA。这倒不难办,使用CPU的EPT/NPT MMU查询对应guest VM的nPT页表,进行一下GPA->HPA的转换就可以了。
可是别忘了,有一些I/O设备是具备DMA(Direct Memory Access)功能的。由于DMA是直接在设备和物理内存之间传输数据,必须使用实际的物理地址(也就是HPA),但DMA本身是为了减轻CPU的处理负担而存在的,其传输过程并不经过CPU。对于一个支持DMA传输的设备,当它拿着GPA去发起DMA操作时,由于没有真实的物理内存地址,传输势必会失败。
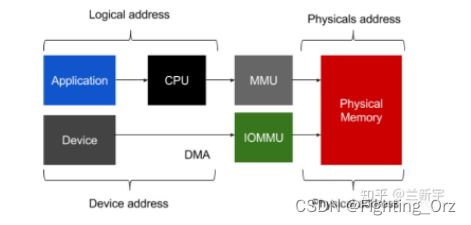
那如何实现对进行DMA传输的设备的GPA->HPA转换呢?再来一个类似于EPT/NPT的MMU?没错,这种专门转换I/O地址的MMU在x86的阵营里就是IOMMU。
然而,不和AMD使用相同的名字是Intel一贯的路数,所以Intel通常更愿意把这种硬件辅助的I/O虚拟化技术叫做VT-d(Virtualization Technology for Direct I/O)。作为后起之秀的ARM自然也不甘示弱,推出了对应的SMMU(System MMU)。
这里为了支持device passthrough(透传)模式下的DMA传输,IOMMU进行的是GPA->HPA的转换。既然EPT/NPT MMU都可以同时支持GVA->GPA和GPA->HPA的转换,那IOMMU是否也可以呢?这个问题也将留在后续的文章中讨论。 可以
Device passthrough(透传)机制要求VMM为guest VM分配好设备,并提供隔离。假设系统中现在有三个guest VMs,编号分别是0, 1, 2,如果VM 0分配到了网卡A,就要阻止VM 1和VM 2对网卡A的访问。
可以采用的方法是在拥有设备的guest VM加载驱动程序前,先给要分配出去的设备加载一个伪驱动作为占位符,由于没有真正的驱动程序,这个设备对于其他的guest VM来说就相当于是“隐藏”了。
这同时也暴露了使用device passthrough存在的一个问题,就是同一个I/O设备通常无法在不同的guest VM之间实现共享和动态迁移(比如PCI设备的热插拔)。下文将介绍的device emulation机制将可以解决设备共享和迁移的问题。
-
- 虚拟化技术 - 内存虚拟化
大型操作系统(比如Linux)的内存管理的内容是很丰富的,而内存的虚拟化技术在OS内存管理的基础上又叠加了一层复杂性,比如我们常说的虚拟内存(virtual memory),如果使用虚拟内存的OS是运行在虚拟机中的,那么需要对虚拟内存再进行虚拟化,也就是vitualizing virtualized memory。本文将仅从“内存地址转换”和“内存回收”两个方面探讨内存虚拟化技术。
在Linux这种使用虚拟地址的OS中,虚拟地址经过page table转换可得到物理地址
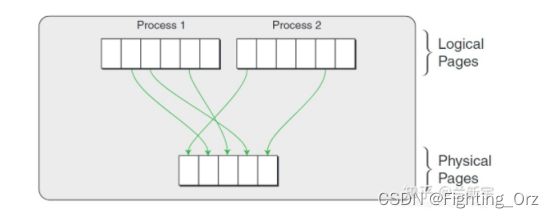
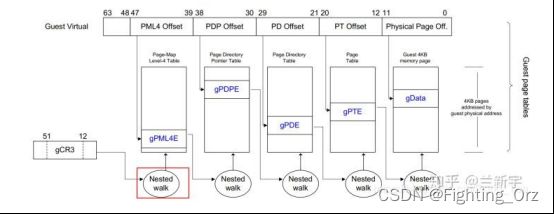
如果这个操作系统是运行在虚拟机上的,那么这只是一个中间的物理地址(Intermediate Phyical Address - IPA),需要经过VMM/hypervisor的转换,才能得到最终的物理地址(Host Phyical Address - HPA)。从VMM的角度,guest VM中的虚拟地址就成了GVA(Guest Virtual Address),IPA就成了GPA(Guest Phyical Address)。
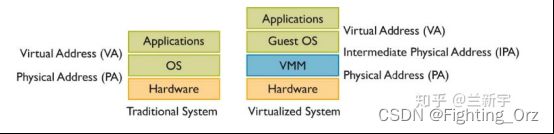
可见,如果使用VMM,并且guest VM中的程序使用虚拟地址(如果guest VM中运行的是不支持虚拟地址的RTOS,则在虚拟机层面不需要地址转换),那么就需要两次地址转换。
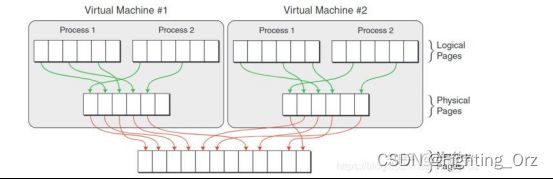
但是传统的IA32架构从硬件上只支持一次地址转换,即由CR3寄存器指向进程第一级页表的首地址,通过MMU查询进程的各级页表,获得物理地址。
-
- 软件实现 - 影子页表
为了支持GVA->GPA->HPA的两次转换,可以计算出GVA->HPA的映射关系,将其写入一个单独的影子页表(sPT - shadow Page Table)。在一个运行Linux的guest VM中,每个进程有一个由内核维护的页表,用于GVA->GPA的转换,这里我们把它称作gPT(guest Page Table)。
VMM层的软件会将gPT本身使用的物理页面设为write protected的,那么每当gPT有变动的时候(比如添加或删除了一个页表项),就会产生被VMM截获的page fault异常,之后VMM需要重新计算GVA->HPA的映射,更改sPT中对应的页表项。可见,这种纯软件的方法虽然能够解决问题,但是其存在两个缺点:
- 实现较为复杂,需要为每个guest VM中的每个进程的gPT都维护一个对应的sPT,增加了内存的开销。
- VMM使用的截获方法增多了page fault和trap/vm-exit的数量,加重了CPU的负担。
在一些场景下,这种影子页表机制造成的开销可以占到整个VMM软件负载的75%。

-
- 硬件辅助 - EPT/NPT
为此,各大CPU厂商相继推出了硬件辅助的内存虚拟化技术,比如Intel的EPT(Extended Page Table)和AMD的NPT(Nested Page Table),它们都能够从硬件上同时支持GVA->GPA和GPA->HPA的地址转换的技术。
GVA->GPA的转换依然是通过查找gPT页表完成的,而GPA->HPA的转换则通过查找nPT页表来实现,每个guest VM有一个由VMM维护的nPT。其实,EPT/NPT就是一种扩展的MMU(以下称EPT/NPT MMU),它可以交叉地查找gPT和nPT两个页表:
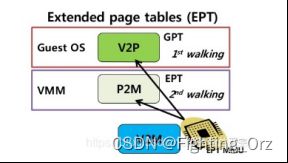
假设gPT和nPT都是4级页表,那么EPT/NPT MMU完成一次地址转换的过程是这样的(不考虑TLB):
首先它会查找guest VM中CR3寄存器(gCR3)指向的PML4页表,由于gCR3中存储的地址是GPA,因此CPU需要查找nPT来获取gCR3的GPA对应的HPA。nPT的查找和前面文章讲的页表查找方法是一样的,这里我们称一次nPT的查找过程为一次nested walk。
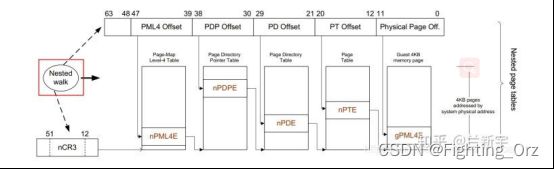
如果在nPT中没有找到,则产生EPT violation异常(可理解为VMM层的page fault)。如果找到了,也就是获得了PML4页表的物理地址后,就可以用GVA中的bit位子集作为PML4页表的索引,得到PDPE页表的GPA。接下来又是通过一次nested walk进行PDPE页表的GPA->HPA转换,然后重复上述过程,依次查找PD和PE页表,最终获得该GVA对应的HPA。
不同于影子页表是一个进程需要一个sPT,EPT/NPT MMU解耦了GVA->GPA转换和GPA->HPA转换之间的依赖关系,一个VM只需要一个nPT,减少了内存开销。如果guest VM中发生了page fault,可直接由guest OS处理,不会产生vm-exit,减少了CPU的开销。可以说,EPT/NPT MMU这种硬件辅助的内存虚拟化技术解决了纯软件实现存在的两个问题。
-
- EPT/NPT MMU优化
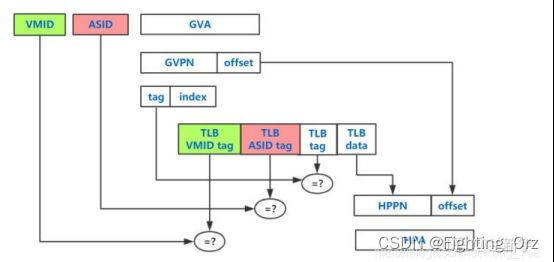
事实上,EPT/NPT MMU作为传统MMU的扩展,自然也是有TLB(《Linux内存管理:转换后备缓冲区(TLB)原理》)的,它在查找gPT和nPT之前,会先去查找自己的TLB(前面为了描述的方便省略了这一步)。但这里的TLB存储的并不是一个GVA->GPA的映射关系,也不是一个GPA->HPA的映射关系,而是最终的转换结果,也就是GVA->HPA的映射。
不同的进程可能会有相同的虚拟地址,为了避免进程切换的时候flush所有的TLB,可通过给TLB entry加上一个标识进程的PCID/ASID(ASID(Address Space ID))的tag来区分(参考这篇文章,或者这篇《Linux内存管理:转换后备缓冲区(TLB)原理》如何管理ASID小节)。同样地,不同的guest VM也会有相同的GVA,为了flush的时候有所区分,需要再加上一个标识虚拟机的tag,这个tag在ARM体系中被叫做VMID,在Intel体系中则被叫做VPID。
PS:
ASID:Address Space ID 地址空间标识符
PCID:Process context identifier 进程上下文标识符
PCID(进程上下文标识符)是在Westmere架构引入的新特性。简单来说,在此之前,TLB是单纯的VA到PA的转换表,进程1和进程2的VA对应的PA不同,不能放在一起。加上PCID后,转换变成VA + 进程上下文ID到PA的转换表,放在一起完全没有问题了。这样进程1和进程2的页表可以和谐的在TLB中共处,进程在它们之前切换完全不需要预热了!
在最坏的情况下(也就是TLB完全没有命中),gPT中的每一级转换都需要一次nested walk【1】,而每次nested walk需要4次内存访问,因此5次nested walk总共需要 (4+1)*5-1=24 次内存访问(就像一个5x5的二维矩阵一样):
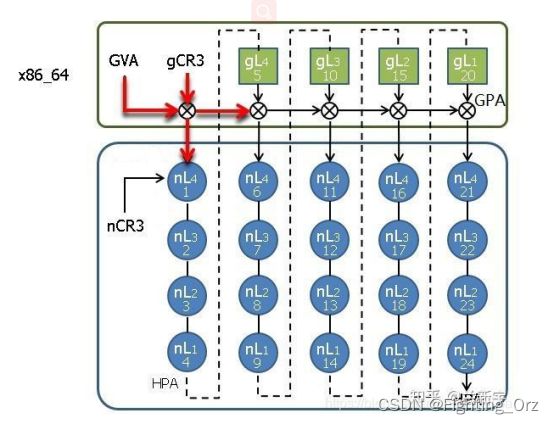
虽然这24次内存访问都是由硬件自动完成的,不需要软件的参与,但是内存访问的速度毕竟不能与CPU的运行速度同日而语,而且内存访问还涉及到对总线的争夺,次数自然是越少越好。
要想减少内存访问次数,要么是增大EPT/NPT TLB的容量,增加TLB的命中率,要么是减少gPT和nPT的级数。gPT是为guest VM中的进程服务的,通常采用4KB粒度的页,那么在64位系统下使用4级页表是非常合适的(参考这篇文章)。
而nPT是为guset VM服务的,对于划分给一个VM的内存,粒度不用太小。64位的x86_64支持2MB和1GB的large page,假设创建一个VM的时候申请的是2G物理内存,那么只需要给这个VM分配2个1G的large pages就可以了(这2个large pages不用相邻,但large page内部的物理内存是连续的),这样nPT只需要2级(nPML4和nPDPE)。
如果现在物理内存中确实找不到2个连续的1G内存区域,那么就退而求其次,使用2MB的large page,这样nPT就是3级(nPML4, nPDPE和nPD)。
下文将介绍从guest VM回收内存的技术。
注【1】:这里区分一个英文表达,stage和level,查找gPT的转换过程被称作stage 1,查找nPT的转换过程被称作stage 2,而gPT和nPT自身都是由multi-level的页表组成。
- SMMU和IOMMU技术
为支持I/O透传机制中的DMA设备传输而引入的IOMMU/SMMU技术,同时留了一个问题:IOMMU/SMMU是否可以同时支持GVA->GPA和GPA->HPA的转换?答案是Yes。
既然在虚拟化的环境中,DMA设备可以借助GPA->HPA的转换,绕过VMM,实现与guest VM中OS的直接数据传递。那在非虚拟化的环境中,DMA设备也可以借助GVA->GPA的转换,绕过OS kernel,实现与userspace(用户空间)的进程的直接交互,这种用法就是用户空间的DMA传输。
两者其实是统一的,不管是GVA还是GPA,说到底都是虚拟地址,有了IOMMU/SMMU之后,DMA就可以使用虚拟地址作为传输的目标地址了
-
- ARM的SMMU
- MMU地址翻译是将进程的虚拟地址(HVA)翻译成物理地址(HPA);
- IOMMU地址翻译则是将虚拟机物理地址空间内的GPA翻译成HPA;
- IOMMU页表和MMU页表一样,都采用了多级页表的方式来进行翻译;
- 专门转换I/O地址的MMU在x86的阵营里就是IOMMU;
- Intel把IOMMU技术叫做VT-d(Virtualization Technology for Direct I/O);
- EPT/NPT MMU作为传统MMU的扩展,也是有TLB;(快表)
在Linux的实现中,一个进程有一个对应的页表,而SMMU是为设备服务的,几个设备可能同属于一个guest VM,因此多个设备可能会共用一个GPA->HPA的转换页表。同一个guest VM的设备可能属于或者不属于某一个特定的进程,因此也可能共用或者不共用GVA->GPA的转换页表。
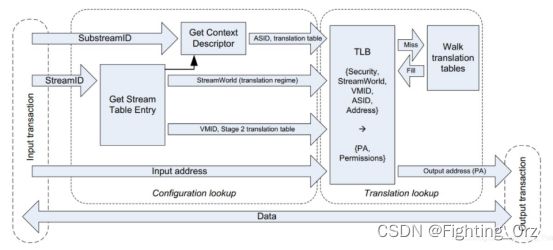
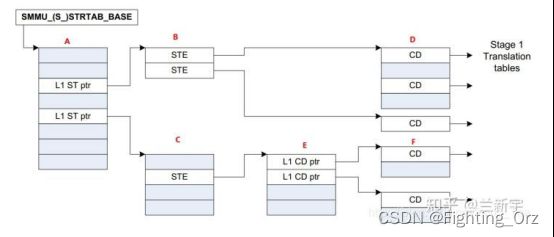
在SMMU中,一个发起DMA传输(transaction)的设备的信息由一个Stream Table Entry(STE)来描述。所有的STEs共同构成了Stream Table,可由StreamID作为Stream Table数组的索引,查找得到对应的STE,因此StreamID也就成了设备唯一性的标识。Stream table可以是1-level的:

也可以是2-level的,比如一个10位的StreamID使用[9:8]的2个bits作为第一级Stream table的索引,[7:0]的8个bits作为第二级Stream table的索引,这和使用虚拟地址作为索引查找页表是一样的(参考这篇文章)。
不同的是,多级页表中每级页表的大小是相同的,而第二级Stream table的大小可以是不同的,比如下图中A就是占满了的,有255个entries,而B和C分别只有4个entries和1个entry。用户可以根据实际的需要灵活配置,以节约内存空间。
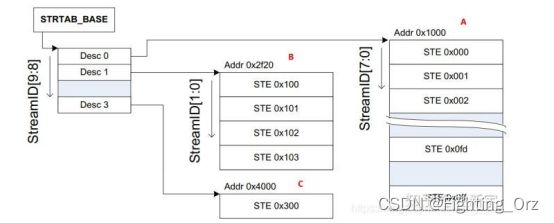
如果一个STE对应的设备要进行的是GPA->HPA的stage 2转换(关于stage请参考这篇文章的注[1]),那么该STE包含的S2TTB(Stage 2 Translate Table Base)将直接指向设备所属的guest VM对应的stage 2页表(下图中的D)。设备所属的VM由STE中的VMID标识,属于同一个VM的设备对应的STEs将指向同一个stage 2页表。
在同一个VM内,一个设备可能被VM内的多个进程共享,而这些进程会有不同的页表,因此一个设备在和不同进程交互时,也会使用不同的页表。为了区分,需要一个设备对应进程的描述信息,这个描述信息被称为CD(Context Descriptor)。
如果该设备需要进行的是GVA->GPA的stage 1转换(比如前面提到的用户空间的DMA传输),那么描述该设备的STE将指向当前进程对应的这个CD(下图中的B)。和同一个进程交互的不同设备将共用这个进程的stage 1页表,因此这些设备的STEs将指向同一个CD。

每个CD包含了一个标识进程的ASID(address space identifier),由TTB0和TTB1指向进程对应的stage 1页表(上图中的C)。熟悉ARM架构的同学应该知道,TTBR0和TTBR1是ARM中分别用来存储进程页表和内核页表的基地址的寄存器,由于这里不再是Register,而是内存中的Descriptor,但用途类似,所以就叫TTB0和TTB1。
同一个设备对应的所有CDs构成了一个CD table。CD table使用的查找索引被称为SubstreamID。SubstreamID最多占20个bits,这个规定是有出处的。熟悉PCIe的同学可能知道,PCIe中有个PASID,而PASID最大就是20个bits。SubstreamID基本就是和PASID(process address space identifier)对等的概念,虽然SMMU并不限于只支持PCIe的设备,但这里SubstreamID还是和PASID保持了统一的步调。
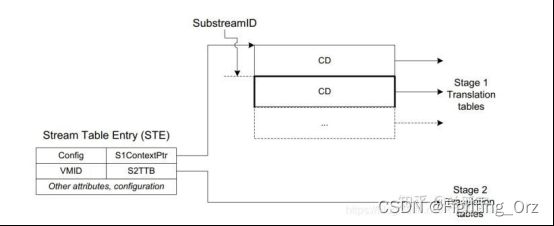
同Stream table一样,CD table可以是1-level的(下图中的D),也可以是2-level的(下图中的E和F)。
如果是熟悉x86的segmentation机制或者是看过这个系列的文章的同学,会不会发现SMMU中的这个Stream table/CD table,其实和x86中的GDT/LDT是很相似的。都是通过索引查找得到对应的entry,每一个entry都是记录的一些描述信息,而且后面还都是跟的page tables。
为什么IOMMU要使用专门的I/O页表?
以AMD的IOMMU为例,它和内置在一个CPU内的MMU(以下称作CPU MMU,ARM的CoreLink MMU,还有前面介绍的EPT/NPT,都属于CPU MMU)是存在一些区别的:
64位的x86_64系列的CPU MMU只支持4KB, 2MB和1GB的页大小(参考这篇文章),而AMD的IOMMU除了支持这些默认的页大小,还支持8KB, 16KB, 1MB, 4MB, 4GB的页大小。
CPU MMU需要按照页表结构一级一级的遍历,而当虚拟地址包含一长串的0的时候,AMD的IOMMU在查找时可以跳过其中的一级页表。
正因为有了IOMMU设计上的这些差异,使用专门的I/O页表可以获得更快的查找速度。如果非要用普通的页表也不是不可以,但需要舍弃IOMMU的一些特性,以适配普通页表的查找规则。然而,ARM的SMMU的设计就不是这样的,它使用普通的页表依然可以工作的很好,不需要专门的I/O页表。
-
- ARM SMMU的原理与IOMMU
- arm smmu的原理
- smmu 基本知识
- arm smmu的原理
- ARM SMMU的原理与IOMMU
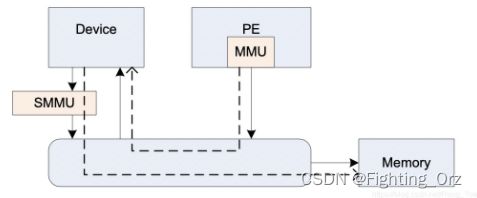
如上图所示,smmu 的作用和mmu 类似,mmu作用是替cpu翻译页表将进程的虚拟地址转换成cpu可以识别的物理地址。同理,smmu的作用就是替设备将dma请求的地址,翻译成设备真正能用的物理地址,但是当smmu bypass的时候,设备也可以直接使用物理地址来进行dma;
-
-
-
- smmu的数据结构
-
-
smmu的重要的用来dma地址翻译的数据结构都是放在内存中的,由smmu的寄存器保存着这些表在内存中的基地址,首先就是StreamTable(STE),这ste 表既包含stage1的翻译表结构也包含stage2的翻译结构,所谓stage1负责VA 到 PA的转换,stage2负责IPA到PA的转换。
接下来我们重点看一下这个STE的结构,到底在内存中是如何组织的;
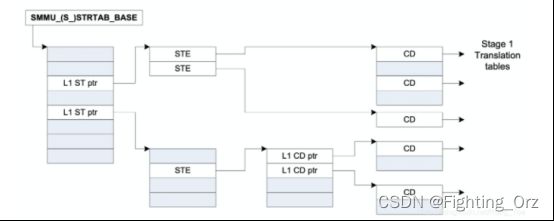
对smmu来说,一个smmu可以给很多个设备服务,所以,在smmu里面为了区分的对每个设备进行管理,smmu 给每一个设备一个ste entry,那设备如何定位这个ste entry呢?对于一个smmu来说,我们给他所管理的每个设备一个唯一的device id,这个device id又叫 stream id;对于设备比较少的情况下,我们的smmu 的ste 表,很明显只需要是1维数组就可以了,如下图:
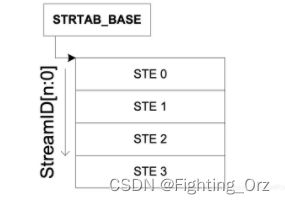
注意,这里ste采用线性表并不是真是由设备的数量来决定的,而是写在smmu 的ID0寄存器中的,也就是配置好了的,对于华为鲲鹏上的smmu基本不采用这种结构;
对于设备数量较多的情况下,我们为了 smmu 更加的皮实点,可以采用两层ste表的结构,如下图

这里的结构其实很类似我们的mmu的页表了,在arm smmu v3 我们第一层的目录desc的目录结够,大小采用8(STRTAB_SPLIT)位,也就是stream id的高8位,stream id剩下的低位全部用来寻址第二层真正的ste entry;
介绍完了 smmu 中管理设备的ste的表的两种结构后,我们来看看这个ste表的具体结构是啥,里面有啥奥秘呢:
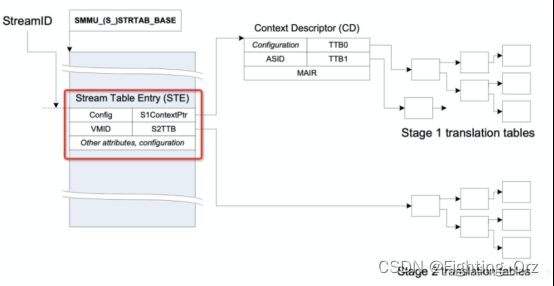
如上如所示,红框中就是smmu中一个ste entry的全貌了,从红框中能看出来,这个ste entry同时管理了stage1 和 stage2的数据结构;其中config是表示ste有关的配置项,这个不需要理解也不需要记忆,不知道的查一下smmuv3的手册即可,里面的VMID是指虚拟机ID,这里我们重点关注一下S1ContextPtr和S2TTB。
首先我们来说S1ContextPtr:
这个S1ContextPtr指向的一个Context Descriptor的目录结构,这张图为了好理解只画了一个,在我们arm中,如果没有虚拟机参与的话,无论是cpu还是smmu地址翻译都是从va->pa/iova->pa,我们称之为stage1,也就是不涉及虚拟,只是一阶段翻译而已。
重要的CD表,读到这里,你是不是会问一个问题,在smmu中我们为何要使用CD表呢?原因是这样的,一个smmu可以管理很多设备,所以用ste表来区分每个设备的数据结构,每个设备一个ste表。那如果每个设备上跑了多个任务,这些任务又同时使用了不同的page table 的话,那咋管理呢?对不对?所以smmu 采用了CD(Context Descriptor) 表来管理每个page table;
看一看cd(Context Descriptor) 表的查找规则:

先说另外一个重要的概念:SubstreamID(pasid),这个叫substreamid又称之为pasid,也是非常简单的概念,既然有表了,那也得有id来协助查找啊,所以就出来了这个id,从这里也可以看出来,道理都一样,用了表了就有id 啊
CD表,在smmu中也是可以是线性的或者两级的,这个都是在smmu 寄存器中配置好了的,由smmu驱动来读去,进行按对应的位进行分级,和ste表一样的原理;
介绍了两个基本的也重要的数据结构后我,smmu是在支持虚拟化的时候,可以同时进行stage1 和 stage2的翻译的,如下图所示:
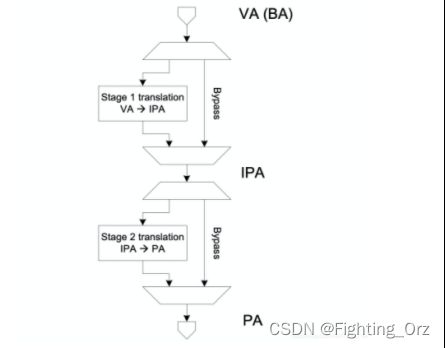
当我们在虚拟机的guest中启用smmu的时候,smmu是需要同时开启stage1 和 stage2的,当然了,smmu 也是可以进行bypass的;
-
-
-
- 1.3 smmu的地址翻译流程
-
-

如上图,基本可以很明显的概括出了一个外设请求 smmu 的地址翻译的基本流程,当一个外设需要dma的物理地址的时候,开始请求smmu的地址翻译,这时候外设给 smmu 3个比较重要的信息,分别是:streamid:协助smmu 找到管理外设的ste entry,subsreamid:当找到ste entry后,协助smmu找到对应的cd 表,通过这两个id smmu 就可以找到对应的iopge table了,smmu找到page table 后结合外设提交过来的最后一个信息iova,即可开始进行地址翻译;
smmu 也有tlb的缓存,smmu首先会根据当前cd表中存放的asid来查查tlb缓存中有没有对应page table的缓存,这里其实和mmu找页表的原理是一样的,不过多解释了,很简单;
上图中的地址翻译还涉及到了stage2,这里不解释了,smmu涉及到虚拟化的过程比较复杂,这个有机会再解释
-
-
- smmu驱动与iommu框架
- smmu v3驱动初始化
- smmu 与 iommu关系
- smmu驱动与iommu框架
-
smmu 和 iommu 是何种关系呢?
在我们的硬件体系中,能够有能力完成设备iova 到 pa转换的有很多,例如有intel iommu, amd的iommu ,arm的smmu等等,不一一枚举了;那这些不同的硬件架构不会都作为一个独立的子系统,所以,在linux 内核中 抽象了一层 iommu 层,由iommu层给各个外部设备驱动提供结构,隐藏底层的不同的架构;如图所示:
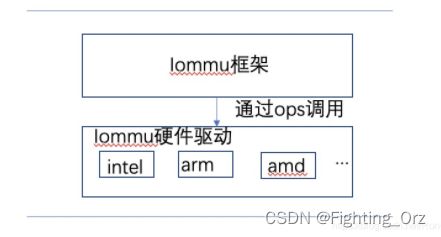
由上图可以很明显的看出来,各个架构的smmu驱动是如何使如何和iommu框架对接的,iommu框架通过不同架构的ops来调用到底层真正的驱动接口;
我们可以问自己一个问题:底层的驱动是如何对接到上层的?
接下来我们来看看进入内核代码来帮我们解开疑惑;
上图就是smmu v3 硬件驱动提供的所有的调用函数;
既然到了iommu层,那我们也会涉及到两种概念的管理,一种是设备如何管理,另外一种是smmu 提供的io page table如何管理;
为了分别管理,这两种概念,iommu 框架提供了两种结构体,一个是 struct iommu_domain 这个结构抽象出了一个domain的结构,用来代表底层的arm_smmu_domain,其实最核心的是管理这个domian所拥有的io page table。另外一个是sruct iommu_group这个结构是用来管理设备的,多个设备可以在一个iommu group中,以此来共享一个iopage table; 我们看一个网络上的图即可很明白的表明其中的关系:
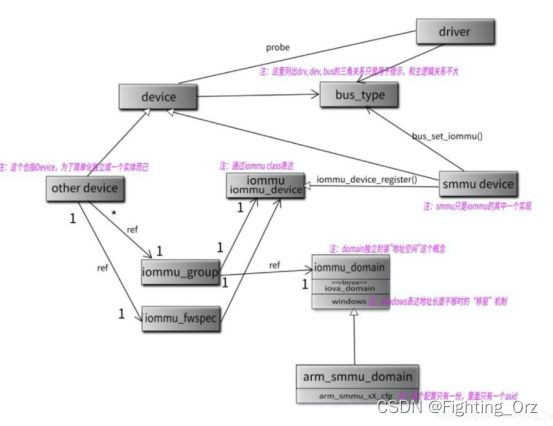
这张图中很明显的写出来smmu domian和 iommu的domain的关系,以及iommu group的作用;不再过多解释
-
-
-
- dma iova 与iommu
-
-
dma 和 iommu 息息相关,iommu的产生其实很大的原因就是避免dma的时候直接使用物理地址而导致的不安全性,所以就产生了iova, 我们在调用dma alloc的时候,首先在io 的地址空间中分配一个iova, 然后在iommu所管理的页表中做好iova 和dma alloc时候产生的物理地址进行映射;外设在进行dma的时候,只需要使用iova即可完成dma动作;
那我们如何完成dma alloc的时候iova到pa的映射的呢?
01 dma_alloc -> __iommu_alloc_attrs
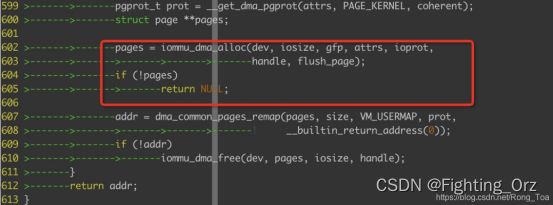
在__iommu_alloc_attrs函数中调用iommu_dma_alloc函数来完成iova和pa的分配与映射;
01 iommu_dma_alloc->__iommu_dma_alloc_pages,
首先会调用者个函数来完成物理页面的分配:

函数__iommu_dma_alloc_pages中完成的任务是页面分配,iommu_dma_alloc_iova完成的就是iova的分配,最后iommu_map_sg即可完成iova到pa的映射;
linux 采用rb tree来管理每一段的iova区间,这其实和我们的虚拟内存的分配是类似的,我们的vma的管理也是这样的;
我们接下来在来看看iova的释放过程,这个释放的过程,我们是可以看到看到strict 个 non-strict模式的最核心的区别的:
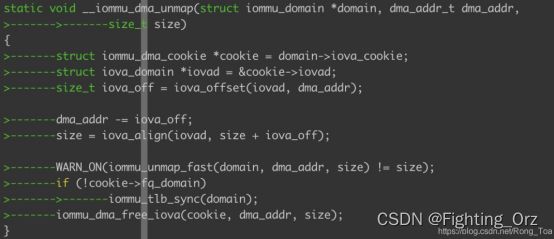
老规矩,直接撸代码,我们看到dma的释放流程也是很简单的,首先将iova和pa进行解映射处理,然后将iova结构给释放掉;
看图中解映射的部分就是在iommu_unmap_fast流程中处理的就是调用iommu的unmap然后通过ops 调用到arm smmu v3驱动的 unmap函数:
01 __iommu_dma_unmap->iommu_unmap_fast->(ops->unmap: arm_smmu_unmap)->arm_lpae_unmap?
我们进入函数arm_lpae_unmap中看看是干啥的,见下图:
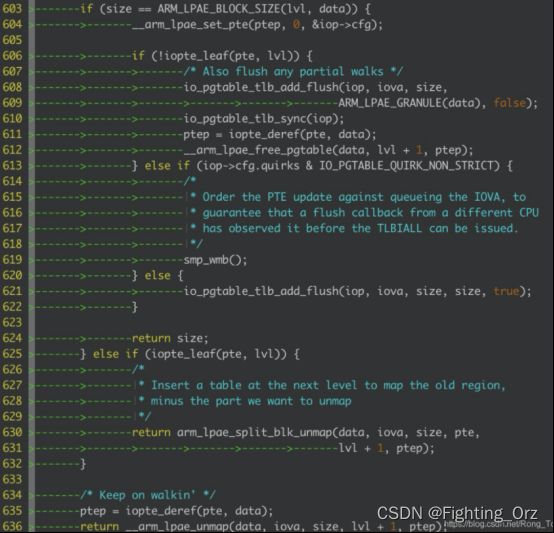
这个函数采用递归的方式来查找io page table的最后一项,当找到的时候,我们可注意看代码行613~622行,其中613~620行是当我们的iommu采用默认的non strict模式的时候,我们是不用立马对tlb进行无效化的;但是当我们采用strict模式的时候,我们还是会将tlb给刷新一下,调用函数io_pgtable_tlb_add_flush给smmu写入一个tlb无效化的指令;
那我们采用non-strict模式的时候是如何刷新tlb的呢?秘密就在函数iommu_dma_free_iova函数中见下图:
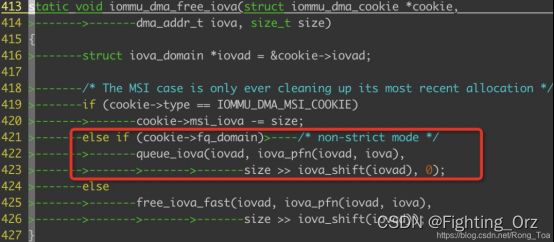
我们可以看到,如果采用non-strict的模式的时候,我们是放到一个队列中的,当我们的队列满的时候,会调用函数iovad->flush_cb,这个函数指针,最终会调用到函数:iommu_dma_flush_iotlb_all,来进行全局的tlb的刷新,smmu无需执行太多的指令了;
-
-
-
- smmu和iommu的bypass
-
-
方式一:将iommu 给彻底给bypass掉,linux 提供了iommu.passthrough command line的选项,这个选项配置上后,dma 默认不会走iommu,而是走传统的swiotlb方式的dma;
方式二:smmu v3的驱动默认支持驱动参数配置,disable_bypass,在系统中是默认关闭bypass的,我们可以通过这个来将某个smmu给bypass掉;
方式三:acpi 或者dts中不配置相应的smmu节点,比较粗暴的办法。
-
-
-
- smmu 的PMCG
-
-
ARM的SMMU提供了性能相关的统计寄存器(Performance Monitor Counter Groups - PMCG - 性能监控计数器组),首先要确定使用的系统里有arm_smmuv3_pmu这个模块,或者它已经被编译进内核。
这个模块的代码在内核目录kernel/drivers/perf/arm_smmuv3_pmu.c,内核配置是: CONFIG_ARM_SMMU_V3_PMU;
smmu pmcg 社区的patch 连接:https://lwn.net/Articles/784040/
详细用法可以参见 社区pmcg的补丁文档,里面内容很简单。
- iommu-viommu(virtio-iommu)
参考链接:virtio详细介绍和1.1新功能 - 云+社区 - 腾讯云
IOMMU(八)-vIOMMU - 云+社区 - 腾讯云
-
- virtio iommu - full emulate
qemu最早支持intel-iommu和iommu=smmuv3,后来有virtio-iommu,又演化出vhost-iommu,把virtio-iommu部分功能拿到内核来实现。整体上分为full emulated和hardware assisted emulation,full emulation就是virtio-iommu,纯软件实现iommu的所有功能,性能低,但virtio应用广,能和现有的实现结合起来,比如kernel中的vhost device-iotlb,dpdk中的vhost-user device-iotlb,iommu功能分布在qemu和virtio其它backend处。hardware assisted emulation肯定借助了硬件的好处,硬件实现了两层翻译和各种隔离,qemu做guest里driver和真正硬件之间的翻译,qemu不能直接给硬件提交工作,需要内核提供通道IOMMU Userspace API,通道下去再调用到硬件的驱动,好处就是可以和内核vfio-iommu那一套结合起来,自然而然就可以利用到fault handling,cache invalidation和PASID(process address space identifier)等,坏处就是guest里运行着厂商自己的driver,如果guest里运行virtio-iommu driver,外面能实现hardware assisted那么就更好。
还有一个问题就是,创建一个虚拟机,然后给这个虚拟机passthrough一个网卡,虚拟机的qemu进程并不需要用到hugepage,在这个虚拟机里运行DPDK需要用到hugepage,hugepage的好处就是长在内存pin住,虚拟机里DPDK用到的hugepage本质上还是qemu进程的非hugepage虚拟内存空间,如何保证DPDK的hugepage一直在真正的物理内存中?这和虚拟机中DPDK用不用vfio-pci没关系。
intel vt-d标准3.2版本第六章《Caching Translation Information》和第七章《Address Translation Faults》讲的东西似乎能解决这个问题,第六章节讲的是IOMMU硬件单元的cache,因为它用的转换表都在内存中,每次去内存读然后再遍历一遍开销很大,所以尽量cache(Context-cache,PASID-cache,IOTLB和Paging-structure Caches),有cache就得维护cache项的状态,是否有效,什么时候清理掉。还有一点就是Device-TLB,device发起一个address translation,IOMMU硬件单元查找自己的cache,然后把结果通过Translation-Completion给了device,device把结果缓存在自己的TLB。第七章讲了Non-recoverable Faults和Recoverable Faults,device发起一个request,IOMMU查找自己的page table发现没有对应的page,就给device-TLB返回一个有问题的Translation-Completion,device-TLB就能检测到这个错误,device上报给自己的driver,driver处理完后让device重试,这样的问题就是不够通用,device和driver各个厂商实现不一样。所以vt-d标准又说,如果device支持pcie page request service,那么device就给IOMMU发送一个page-request消息,IOMMU生成一个struct放在page request queue中,然后给CPU来个page request event中断,IOMMU驱动开始处理,指导IOMMU给device回复一个Page Group Response消息,device再重试刚才的request,这样的好处就是软件通用,代码都在IOMMU驱动中,device硬件要配合IOMMU硬件,整体上来说对硬件的要求很高。
-
- virtio 详细介绍
virtio是一种实践出来的技术,并且最终标准化,virtio是一种通用的虚拟化设备模拟标准,得到了大部分guest操作系统和hypervisor的支持,方便guest操作系统和hypervisor之间任意互相匹配。virtio出现之前hypervisor各有各的IO设备模拟方案,并在guest操作系统中大量合入驱动代码,导致一片混乱,后来xen中出来了部分virtio思想,在kvm中实现并且发扬光大,发表了论文《virtio: Towards a De-Facto Standard For Virtual I/O Devices》,论文促使virtio形成了正式标准。virtio标准最早是0.9.5版本(Virtio PCI Card Specification Version 0.9.5),于2012年形成了draft,并没有正式发布,继续发展,2016年发布了1.0版本(Virtual I/O Device (VIRTIO) Version 1.0),2019年发布了1.1版本(Virtual I/O Device (VIRTIO) Version 1.1)。
virtio详细介绍
virtio分为driver和device,driver部分运行于guest操作系统中,device部分运行于hypervisor中,driver和device是生产者和消费者模式动作,driver生产内存,device消费内存。不同virtio版本之间是互相兼容的,driver和device版本不同也可以互相运转。
基本要素
device status field
driver发现了device,driver可以正常驱动device,driver或者device出错了,driver或者device要进行reset。
device feature bit
driver和device协商feature以便于不同virtio版本之间兼容。
notification
driver和device互通通知对方,driver生产好的内存要通知device去消费,device消费完了要通知driver回收内存。
driver通知deivce用doorbell机制,在kvm中是写寄存器,kvm进行拦截再通知vhost。
device通知driver用中断机制,在kvm中是中断注入。
config space
典型的如virtio-net-device的MAC地址/MTU/最大支持队列数等。
virtqueue
每个virtqueue分成这三部分,descriptor/available/used,descriptor/available/used就是三个大数组,descriptor数组内容存放真正东西,available和used数组内容存放descriptor数组的下标。driver生产内存,把生产的内存地址和长度写在descriptor,然后把descriptor数据下标写到available数组中,通知device,device消费内存,消费完再把descriptor的数据下标定到used数组中,通知driver进行内存回收。
chained descriptor,几个desciptor项连在一起,适用于scater-gather。
indirect descriptor,主descriptor中一项指向另一个descriptor数组。
一般设备的virtqueue基本可以分三类rx virtqueue/tx virtqueue/ctrl virtqueue,rx virtqueue和tx virtqueue用于进行IO,driver通过ctrl virtqueue控制device。
used和avaible不一样是因为rx时,device给driver写数据,device写多少长度数据要给driver反回去。
初始化
device准备,driver发现device,状态更新和feature协商,driver分配virtqueue,把virtqueue地址告诉device。
承载
首先virtio设备是IO设备,IO设备得以某种方式和CPU内存联结在一起,IO设备还得以某种方式和内存交互数据,IO设备还得提供一种机制让CPU控制IO设备。
virtio标准中有三种承载机制,分别是pci,mmio和channel i/o,pci是最通用的计算机bus,qemu和kvm能很好的模拟pci bus,mmio主要用于嵌入式设备,这些设备没有pci bus,channel i/o用于一些IBM机器,很少见。这里以最常见的pci来说,它的作用就是让driver正常发现device,让driver有方法控制device,如写pci配置空间,写pci bar空间。
设备分类
virtio分为很多设备类型virtio-net/virtio-blk/virtio-scsi等等,virtqueue实现通用部分,每种设备再实现具体功能部分,可以扩展feature部分,在virtqueue传输的数据中定义自己功能相关标准等。
virtio1.1新功能
virtio 1.0存在的问题第一是性能不高,第二是硬件不太好实现。
driver和device运行在不同的cpu,driver和device共享内存,存在不同cpu之间互相通知进行cache刷新的问题,virtio1.0 virtqueue分成三个数组,三个数组分布在不同的cacheline上需要多次cache刷新,所以virtio 1.1引入了packed ring,把virtio 1.0中的三个数组合并成一个,这样大大减少了cache刷新的次数。具体做法就是packed virtqueue把available和used当成descriptor中flag字段两个bit,driver本地存放一个driver_local_bit,把available_bit=driver_local_bit和used_bit=!driver_local_bit,device本地存放一个device_local_bit,消费完内存后used_bit=device_local_bit。
通知是有开销的,virtio1.1 batch和in-order减少driver和device互相通知对方的次数,batch就是driver一次多生产几块内存,再通知device,in-order就是device按driver生产内存的顺序消费内存,消费完后只通知driver最后一块内存可以回收了,因为严格按顺序消费的,driver由此可知前面的内存也已经消费完了。
硬件实现也一样,driver写descriptor发现一次pci传输,写available数组又要发现一次pci传输,如果把descriptor和available数组合并只要一次pci传输即可。
实现情况
linux 4.18 virtio-net driver已经能支持virtio 1.1了,但vhost-net不支持virtio 1.1。
qemu master实现了virtio 1.1。
dpdk virtio pmd和vhost-user都支持virtio 1.1。
总结
virtio标准还会继续发展,功能会越来越多,设备类型会越来越多,如virtio GPU和virtio vIOMMU,GPU最难虚拟化,目前用的是mdev,没有IOMMU,virtio设备可以修改任意guest内存,有vIOMMU更安全,vIOMMU也可以用vt-d实现,virtio device emulation可以在qemu/kernel/dpdk中实现,virtio技术百花齐放,创新不断,是做虚拟化必须研究的技术。总结virtio的目标就是统一IO设备,虚拟机看到的所有的外设都是virtio类型,只需要安装virtio类型的驱动即可,如果硬件也能实现virtio,那么裸金属也一样了,虚拟机和裸金属互相热迁移,一个镜像走天下。
CPU访问内存用virtual_address,然后通过MMU转换成physical_address,外设访问内存用的bus_address,由bus把bus_address定位到物理内存上,不同的bus可能处理方法还不一样,但在pci下,目前bus_address就是phiscal_address。DMA内存由CPU分配,CPU需要把virtual_address转换成bus_address,然后DMA engine进行DMA操作。DMA_ZONE表示DMA可使用的内存范围,现在x86_64下一般设备所有内存都可用,所以说DMA_ZONE和bus_address为了兼容而保留其实不用特殊考虑。
DMA内存分配和回收,CPU分配内存,设备做DMA操作,然后CPU回收内存,这些内存是等下次DMA继续用还是一次就回收用到的api也不一样。
cache一致性,由体系保证,如果体系不能保证则只能禁止CPU对做DMA的内存缓存了。
cache aligned,由提供内存者保证,不aligned一些外设可能搞不定。
内核态DMA驱动和DMA API
一般外设都自带DMA功能,DMA只是外设的数据传输通道,外设的功能各不一样,但DMA传输数据通道功能都一样,所以内核就有了DMA API,其它外设驱动只要调用内核DMA API就可以搞定DMA相关的功能了,内存映射/数据对齐/缓存一致性等都由内核DMA API搞定。
dma_ops = &nommu_dma_ops;
i40e_alloc_mapped_page
└─dma_map_page
└─nommu_map_page
用户态DMA驱动
外设通过DMA把数据放到内核,用户态再系统调用把数据手动到用户态,开销很大,所以想着外设直接把数据手动到用户态,可用户态用的都是虚拟地址,第一个问题就是得把虚拟地址转换成物理地址,用/proc/self/pagemap正好可以获取虚拟地址对应的物理地址。第二个问题是怎么保证虚拟地址对应的物理地址一定存在于内存中并且固定在内存中的同一个物理地址,虚拟地址一定有对应的物理地址好说,可以直接把page的ref加1,并且强行给page写个0数据,但虚拟地址固定对应到一个物理地址就难说了,假如进程给一个虚拟地址找了一个page让设备给这个page DMA写数据,同时kernel开始了page migration或者same page merge,把进程的虚拟地址对应的物理设置成其它page,但设备DMA写的page还是原来的page,这样导致进程访问的数据就不是设备定到内存中的数据,但这种概率很小啊。总之hugepage能满足大部分特性
IOMMU
类同于MMU,对DMA做地址翻译,用来解决DMA的安全性问题,DMA API同时肩负起了设置IOMMU的职责。
dma_ops = &intel_dma_ops;
i40e_alloc_mapped_page
└─dma_map_page
└─intel_map_page
└─__intel_map_single
├─if(iommu_no_mapping) return paddr;
├─intel_alloc_iova
└─domain_pfn_mapping
内核用IOMMU的好处,限制了设备DMA可写的范围,设备不成随便从物理内存读写了。其实IOMMU更大的用处在于用户态驱动,如DPDK和qemu,用于qemu passthrough能更好的理解IOMMU的作用,guest发起DMA时设置的地址是guest_phy_addr,qemu拿到guest DMA的内存段开始地址guest_dma_phy_addr_start转换成自己的host_dma_virt_addr,然后把两个地址和DMA段的长度len通知vfio建立map,vfio找从host_dma_phy_addr开始的len长度的连续物理内存,host_dma_virt_addr映射到host_dma_phy_addr,然后pin住,让qemu的虚拟地址始终有物理内存对应并且对应到固定物理内存。vfio再给iommu建立表项,如果DMA要和guest_phy_addr交换数据,就和host_dma_phy_addr交换数据,iommu中有个iova,其实这个iova在这儿就是guest_phy_addr。dpdk中有--iova ,相比较于qemu这儿就是小菜一碟。
kvm device passthrough老方法
kvm_iommu_map_pages
└─iommu_map
└─intel_iommu_map(domain->ops->map)
└─domain_pfn_mapping
qemu用vfio实现device passthrough新方法
vfio_iommu_type1_ioctl
└─vfio_dma_do_map
└─vfio_pin_map_dma
└─vfio_iommu_map
└─iommu_map
└─intel_iommu_map(domain->ops->map)
└─domain_pfn_mapping
-
- IOMMU(四)-dma remapping
DMA remapping就是在DMA的过程中IOMMU进行了一次转换,MMU把CPU的虚拟地址(va)转换成物理地址(pa),IOMMU的作用就是把DMA的虚拟地址(iova)转换成物理地址(pa),MMU转换时用到了pagetable,IOMMU转换也要用到io pagetable,两者都是软件负责创建pagetable,硬件负责转换。IOMMU的作用就是限制DMA可操作的物理内存范围,当一个PCI设备passthrough给虚拟机后,PCI设备DMA的目的地址是虚拟机指定的,必须要有IOMMU限制这个PCI设备只能操作虚拟机用到的物理内存。
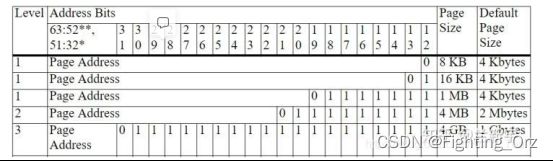
intel vt-d spec是IOMMU的标准,标准中一个domain就是一个隔离的空间,一个虚拟机就是一个domain,一个DPDK进行就是一个domain,一个PCI设备分配给这个domain后只能操作这个domain的物理内存。
io pagetable
IOMMU的pagetable和MMU的pagetable一模一样,转换方式也一样,都支持4KB/2M/1G大小的page,都支持4级和5级页表,4级和5级的区别就是va/iova的长度是48位还57位。
iova 设备发起DMA 请求时,要访问的地址,也就是 iommu 映射前的地址
vaddr 就是 mmap 的地址(这个是 host va 还是 guest va/gpa)
关键点:
StreamID: device 通过物理线连接到SMMU ,这个StreamID就是用来标识SMMU上连接的设备。想象一个8 ports hub上连接了8个物理设备,这8个设备就可以通过portID来标识,比如port 0代表第一个设备,同理steamID
STE: stream Table Entry,可以理解为SMMU页表转换的第一级索引,每一个streamID代表着一个STE,通过这个STE指向的连接可以找到真正的虚地址==》物理地址转换的页表。假设SMMU上连接着8个具体设备,每个设备都有自己的StreamID,那就有至少8个STE表项。
CD: Context Descriptor, stage 1的页表配置项,它其中的TTB0指向了真正的页表信息,比如PGD, PMD, PTE等,完全和MMU的页表转换原理一样
-
- 网上查找资料
理解SMMU基本原理和基本概念_finicswang的博客-CSDN博客_smmu
关键点:
StreamID: device 通过物理线连接到SMMU ,这个StreamID就是用来标识SMMU上连接的设备。想象一个8 ports hub上连接了8个物理设备,这8个设备就可以通过portID来标识,比如port 0代表第一个设备,同理steamID
STE: stream Table Entry,可以理解为SMMU页表转换的第一级索引,每一个streamID代表着一个STE,通过这个STE指向的连接可以找到真正的虚地址==》物理地址转换的页表。假设SMMU上连接着8个具体设备,每个设备都有自己的StreamID,那就有至少8个STE表项。
CD: Context Descriptor, stage 1的页表配置项,它其中的TTB0指向了真正的页表信息,比如PGD, PMD, PTE等,完全和MMU的页表转换原理一样
查找过程:
假设stream ID为16的设备发起了DMA操作(如下动作完全自动完成,前提是之前配置好了SMMU中所有的表项):
StreamID=16, 所以从寄存器strtab_base指向的地址中找到偏移为16的STE表项
该表项中的s1ContexPtr指向了下一级的stage 1转换地址CD(Context Descriptor)
CD中的TTB0指向了一个页表转换的基地址PGD
PGD-PMD-PTE 完成了虚拟地址到物理地址的转换(和MMU工作原理一样)
注:
其中引入的VMID, ASID的原因和MMU一样,都是为了在TLB中加于区别,防止cache bouncing
Stage2 的转换原理基本和Stage 1一致,不过没有额外的CD
-
- virtio 虚拟化系列之一:从 virtio 论文开始
参考链接 virtio 虚拟化系列之一:从 virtio 论文开始(文末有福利~)_Linux阅码场的博客-CSDN博客
VirtIO由 Rusty Russell 开发,他当时的目的是支持自己的虚拟化解决方案 lguest。VirtIO 是对准虚拟化 hypervisor 中的一组通用模拟设备IO的抽象。它是一种框架,通过它hypervisor 导出一组通用的模拟设备,并通过一个通用的应用编程接口(API)让它们在虚拟机中变得可用。它构造了一种虚拟化环境所独有的存储设备,因此需要在虚拟机内部安装特定的驱动程序才能正常驱使该设备进行工作。通常我们称虚拟机内部的驱动为前端驱动,称负责实现其功能模拟的程序(KVM平台下即为qemu程序)为后端程序,半模拟技术也常常被叫做前后端技术。采用半摸拟技术后,配合前端驱动,虚拟化设备完全可以采用全新的事件通知和数据传递机制进而大幅提升性能,例如在virtio-blk磁盘中,采用io_event_fd进行前端到后端通知,采用中断注入方式实现后端到前端的通知,并通过IO环(vring)进行数据的共享,IO模型也随之发生变化(如下图所示)
所以当KVM+Qemu有了Virtio的支持之后,虚拟机中的IO请求就不会在有虚拟机和host之间的切换,而是直接由QEMU中的后端驱动程序直接和host机器中真实的设备驱动通信,完成IO
-
-
- 地址转换
-
virtio 的一个目标就是提高虚拟设备性能,就要消除数据拷贝,采用共享内存的方式访问数据。virtio 的 virtqueue 在 Guest 和 Host 之间是共享的,但是由于在两个不同的地址空间,一个是 Guest Physical Address, 一个是 Host Virtual Address。virtqueue 在 Guest 端构建并初始化,Host 端只需要经过地址转换来建立对应的 virtqueue 结构即可,不用再重新初始化 virtqueue 结构。
Virtio 在初始化的时候进行第一步的地址映射:
- Guest 构建好 desc table;
- 通过写 PCI IO 空间 VIRTIO_PCI_QUEUE_PFN 来告知 Host ,Guest 的 virtqueue 的 GPA 地址;
- Host 收到了 GPA,然后转换成 Host 的虚拟地址。
因为 Host 是 Qemu 后端,Qemu 给虚拟机提供了内存,所以它知道 Guest OS 的物理地址范围。Qemu 根据自己记录的信息,可以将 gpa 转换成 hva。
-
-
- Virtio-blk 后端
-
我们先从后端讲起,因为后端相当于一个虚拟的硬件,后端提供什么功能,前端才能使用什么功能。对于 block 设备的虚拟化,后端需要提供 virtio 定义的 PCI 的能力,包括:
- Feature bits
- Status bits
- 配置空间
- reset
- ...
其中配置空间比较重要,通过 PCI 提供了Guest 访问 virtio 虚拟硬件的一些参数。对于 virtio-blk,包括基本的磁盘布局信息。
当 Guest OS 需要访问以上配置信息的时候,只需要调用 ioread 读对应的 offset,就可以读到数值。
同理,Guest OS 也可以通过 iowrite 来写对应的 offset,修改结构。
当完成 PCI 设置注册之后,前端 virtio-blk 调用 probe 来装载驱动。进行 feature 协商,以及基本的 IO 空间配置,此时前后端就可以进行数据传递。
当收到 Guest 的 notify 时,如图所示,Host 根据 last_used_idx 从 desc 表中重构 request,包括 virtio_blk_outhdr,iovec 等,这个过程需要进行地址空间转换,然后提交给 backend,就完成了,过程非常简单。当 IO 完成后,注入中断通知 Guest OS。
-
-
- Virtio-blk 前端
-
这是 Linux kernel 里面的一个 PCI 驱动,在 probe 阶段完成:
Virtqueue 的创建;
Feature 的协商;
PCI 配置空间读取 block 设备的空间布局等信息;
在完成 probe 之后,此时前后端就可以进行数据传递。
请求从 block 层到达 virtio-blk 驱动之后,构造 virtio_blk_outhdr,以及 scatterlist,然后通过 add_buf 放入描述符表以及notify host,至此 IO 提交完成。完成事件由中断触发。一个基本的 virtio-blk Guest driver 只需要 300 行左右就可以完成。
-
-
- 总结
-
Virtio 作者的目标是设计一套通用的,隐藏细节的,前后端方便实现,共享通用代码的虚拟化框架,从分析看来,通过 PCI 和 virtqueue 的抽象,的确能达到目的。
本文对部分细节只进行简单的说明,后续会在以下几个话题开展:
- Qemu 和 virtio 的内存映射
- 中断注入的实现
- Virtio 流控以及性能优化
- Vhost-user
当前,距离 virtio 问世已经十年有余,现在 virtio 的发展还在继续,包括增加更多的 feature bits,新的内存布局,以及 vhost-user,目的是提供更好的性能,以及更强大的功能。
-
- Qemu模拟IO和半虚拟化Virtio的区别以及I/O半虚拟化驱动介绍
参考链接:Qemu模拟IO和半虚拟化Virtio的区别以及I/O半虚拟化驱动介绍_weixin_34051201的博客-CSDN博客
-
-
- QEMU的基本原理和优缺点
-
基本原理:
使用QEMU模拟I/O的情况下,当客户机中的设备驱动程序(device driver)发起I/O操作请求之时,KVM模块中的I/O操作捕获代码会拦截这次I/O请求,然后经过处理后将本次I/O请求的信息存放到I/O共享页,并通知用户控件的QEMU程序。QEMU模拟程序获得I/O操作的具体信息之后,交由硬件模拟代码来模拟出本次的I/O操作,完成之后,将结果放回到I/O共享页,并通知KVM模块中的I/O操作捕获代码。最后,由KVM模块中的捕获代码读取I/O共享页中的操作结果,并把结果返回到客户机中。当然,这个操作过程中客户机作为一个QEMU进程在等待I/O时也可能被阻塞。另外,当客户机通过DMA(Direct Memory Access)访问大块I/O之时,QEMU模拟程序将不会把操作结果放到I/O共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中去,然后通过KVM模块告诉客户机DMA操作已经完成。
优缺点:
QEMU模拟I/O设备的方式,其优点是可以通过软件模拟出各种各样的硬件设备,包括一些不常用的或者很老很经典的设备(如4.5节中提到RTL8139的网卡),而且它不用修改客户机操作系统,就可以实现模拟设备在客户机中正常工作。在KVM客户机中使用这种方式,对于解决手上没有足够设备的软件开发及调试有非常大的好处。而它的缺点是,每次I/O操作的路径比较长,有较多的VMEntry、VMExit发生,需要多次上下文切换(context switch),也需要多次数据复制,所以它的性能较差。
-
-
- 半虚拟化virtio的基本原理和优缺点
-
基本原理:
其中前端驱动(frondend,如virtio-blk、virtio-net等)是在客户机中存在的驱动程序模块,而后端处理程序(backend)是在QEMU中实现的。在这前后端驱动之间,还定义了两层来支持客户机与QEMU之间的通信。其中,“virtio”这一层是虚拟队列接口,它在概念上将前端驱动程序附加到后端处理程序。一个前端驱动程序可以使用0个或多个队列,具体数量取决于需求。例如,virtio-net网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而virtio-blk块驱动程序仅使用一个虚拟队列。虚拟队列实际上被实现为跨越客户机操作系统和hypervisor的衔接点,但它可以通过任意方式实现,前提是客户机操作系统和virtio后端程序都遵循一定的标准,以相互匹配的方式实现它。而virtio-ring实现了环形缓冲区(ring buffer),用于保存前端驱动和后端处理程序执行的信息,并且它可以一次性保存前端驱动的多次I/O请求,并且交由后端去动去批量处理,最后实际调用宿主机中设备驱动实现物理上的I/O操作,这样做就可以根据约定实现批量处理而不是客户机中每次I/O请求都需要处理一次,从而提高客户机与hypervisor信息交换的效率。
优缺点:
Virtio半虚拟化驱动的方式,可以获得很好的I/O性能,其性能几乎可以达到和native(即:非虚拟化环境中的原生系统)差不多的I/O性能。所以,在使用KVM之时,如果宿主机内核和客户机都支持virtio的情况下,一般推荐使用virtio达到更好的性能。当然,virtio的也是有缺点的,它必须要客户机安装特定的Virtio驱动使其知道是运行在虚拟化环境中,且按照Virtio的规定格式进行数据传输,不过客户机中可能有一些老的Linux系统不支持virtio和主流的Windows系统需要安装特定的驱动才支持Virtio。不过,较新的一些Linux发行版(如RHEL 6.3、Fedora 17等)默认都将virtio相关驱动编译为模块,可直接作为客户机使用virtio,而且对于主流Windows系统都有对应的virtio驱动程序可供下载使用。
I/O半虚拟化驱动
I/O半虚拟化分成两段:
前端驱动(virtio前半段):virtio-blk,virtio-net,virtio-pci,virtio-balloon,virtio-console
支持的系统有:
Linux:CentOS 4.8+,5.4+,6.0+,7.0+
Windows:
virtio:虚拟队列,virt-ring
transport:后端处理程序(virt backend drivers):在QEMU中实现
- virtio-iommu
参考链接:[virtio-dev] Re: [PATCH v5 5/7] iommu: Add virtio-iommu driver
vSMMU has to stay in userspace though. The main reason we're proposing virtio-iommu is that emulating every possible vIOMMU model in the kernel would be unmaintainable. With virtio-iommu we can process the fast path in the host kernel, through vhost-iommu, and do the heavy lifting in userspace.
但是,vSMMU 必须留在用户空间。 我们提出 virtio-iommu 的主要原因是在内核中模拟所有可能的 vIOMMU 模型将是不可维护的。 使用 virtio-iommu,我们可以通过 vhost-iommu 处理主机内核中的快速路径,并在用户空间中完成繁重的工作。
-
- iommu datastruct
01 /**
02 * struct vringh_config_ops - ops for creating a host vring from a virtio driver
03 * @find_vrhs: find the host vrings and instantiate them
04 * vdev: the virtio_device
05 * nhvrs: the number of host vrings to find
06 * hvrs: on success, includes new host vrings
07 * callbacks: array of driver callbacks, for each host vring
08 * include a NULL entry for vqs that do not need a callback
09 * Returns 0 on success or error status
10 * @del_vrhs: free the host vrings found by find_vrhs().
11 */
12 struct virtio_device;
13 typedef void vrh_callback_t(struct virtio_device *, struct vringh *);
14 struct vringh_config_ops
15 {
16 int (*find_vrhs)(struct virtio_device *vdev, unsigned nhvrs,
17 struct vringh *vrhs[], vrh_callback_t *callbacks[]);
18 void (*del_vrhs)(struct virtio_device *vdev);
19 };
01 /* virtio_ring with information needed for host access. */
02 struct vringh
03 {
04 /* Everything is little endian */
05 bool little_endian;
06
07 /* Guest publishes used event idx (note: we always do). */
08 bool event_indices;
09
10 /* Can we get away with weak barriers? */
11 bool weak_barriers;
12
13 /* Last available index we saw (ie. where we're up to). */
14 u16 last_avail_idx;
15
16 /* Last index we used. */
17 u16 last_used_idx;
18
19 /* How many descriptors we've completed since last need_notify(). */
20 u32 completed;
21
22 /* The vring (note: it may contain user pointers!) */
23 struct vring vring;
24
25 /* IOTLB for this vring */
26 struct vhost_iotlb *iotlb;
27
28 /* spinlock to synchronize IOTLB accesses */
29 spinlock_t *iotlb_lock;
30
31 /* The function to call to notify the guest about added buffers */
32 void (*notify)(struct vringh *);
33 };
01 /*
02 * Leftmost-cached rbtrees.
03 *
04 * We do not cache the rightmost node based on footprint
05 * size vs number of potential users that could benefit
06 * from O(1) rb_last(). Just not worth it, users that want
07 * this feature can always implement the logic explicitly.
08 * Furthermore, users that want to cache both pointers may
09 * find it a bit asymmetric, but that's ok.
10 */
11 struct rb_root_cached
12 {
13 struct rb_root rb_root;
14 struct rb_node *rb_leftmost;
15 };
-
- virtio iommu patch
参考链接:[PATCH 0/1] Add virtio-iommu device specification
来自:Jean-Philippe Brucker
原文链接:[PATCH 0/1] Add virtio-iommu device specification
A short description of virtio-iommu and why we're doing this:
The virtio-iommu device allows a guest to manage DMA mappings for
physical, emulated and paravirtualized endpoints. It is designed to be portable and is currently compatible with at least x86 and Arm IOMMU
architectures. The MAP/UNMAP mode introduced here is architecture-
agnostic.
However some platforms will benefit from this device more than others in the short term. For example the Arm SMMU doesn't currently include a paravirtualized mode that would allow it to shadow a single translation stage into a physical SMMU. On Arm the only way to assign devices to guest userspace requires nesting translation, which isn't supported by all SMMUs, or using virtio-iommu.(在 Arm 上,将设备分配给访客用户空间的唯一方法需要嵌套转换,并非所有 SMMU 都支持,或者使用 virtio-iommu。)
网上资料:
qemu没有模拟出iommu硬件单元,把模拟的iommu称为虚拟的iommu,就是viommu。
其实viommu和嵌套虚拟化关系很大,比如把pci passthroughed device再次passthrough给虚拟机中的虚拟机,把emulated pci device passthrough给虚拟机中的虚拟机。
qemu最早支持intel-iommu和iommu=smmuv3,后来有virtio-iommu,又演化出vhost-iommu,把virtio-iommu部分功能拿到内核来实现。整体上分为full emulated和hardware assisted emulation,full emulation就是virtio-iommu,纯软件实现iommu的所有功能,性能低,但virtio应用广,能和现有的实现结合起来,比如kernel中的vhost device-iotlb,dpdk中的vhost-user device-iotlb,iommu功能分布在qemu和virtio其它backend处。hardware assisted emulation肯定借助了硬件的好处,硬件实现了两层翻译和各种隔离,qemu做guest里driver和真正硬件之间的翻译,qemu不能直接给硬件提交工作,需要内核提供通道IOMMU Userspace API,通道下去再调用到硬件的驱动,好处就是可以和内核vfio-iommu那一套结合起来,自然而然就可以利用到fault handling,cache invalidation和PASID等,坏处就是guest里运行着厂商自己的driver,如果guest里运行virtio-iommu driver,外面能实现hardware assisted那么就更好。
参考链接[PATCH v7 0/7] Add virtio-iommu driver
按照v0.9[1]规范实现virtio-iommu驱动程序。这是Linux v5.0-rc2上的一个简单的重基。我们现在使用v5.0中引入的dev_iommu_fwspec_get() helper,而不是访问dev->iommu_fwspec,但是v6的[2]没有任何功能更改。virtio-iommu的当前目标是让一个半虚拟的IOMMU在Arm上工作,并允许设备分配给客户用户空间。在这个用例中,映射是静态的,不需要优化性能,因此本系列试图保持简单。不过,在特性和优化方面还有很多工作要做,在v5.1中有这样的基础会很好。考虑到大多数更改都是针对驱动程序/iommu的,我认为驱动程序和未来的更改应该通过iommu树。你可以在v0.9.2上找到Linux驱动程序和kvmtool设备分支[3],在virtio-iommu/devel上找到模块和x86支持。也用Eric的QEMU设备[4]进行了测试。请注意,本系列依赖于Robin的探测延迟修复[5],该修复有望在v5.0中实现。
-
- dpdk vhost-uesr对vIOMMU的支持
参考链接:dpdk vhost-uesr对vIOMMU的支持-lvyilong316-ChinaUnix博客
在qemu-kvm架构下vIOMMU是由qemu来模拟实现的,而vhost-user作为dpdk的vhost实现也对其进行了适配。其对于虚拟机的功能就类似于IOMMU对于物理机。那么为什么要有支持vIOMMU的需求呢?最关键的原因就是为了“安全”,为了设备内存是在合法范围内的。我们知道IOMMU的主要核心功能有两个:DMA remapping,Interrupt remmapping。那么我们就看这两个功能分别是怎么实现的。
-
-
- DMA remapping
-
其实这里说DMA remapping不够准确,因为本质是vhost-uesr是采用memcpy的cpu内存拷贝内存实现了,而非DMA,但是大概流程是类似的。我们先来看一下没有vIOMMU的情况,数据包的拷贝方式。如下图所示:

vm前端virtio-net将guest物理地址(gpa)写入virtio ring的desc中,而后端vhost-user则需要在进行报文拷贝时,对gpa和hva进行转换。这里所说的hva是指host上vhost-uesr所在进程的host虚拟地址。当vm收发包时,vhost-uesr需要将desc中的gpa转换为hva,让后再进行操作。
下面我们看下支持了vIOMMU后的处理流程,如下图所示:
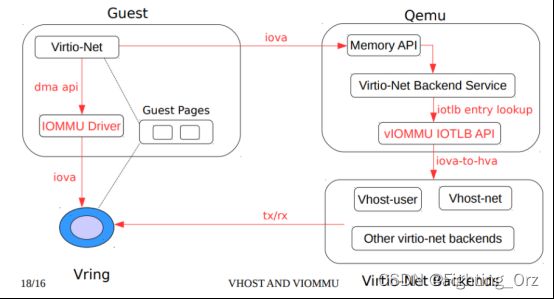
前端不再使用自己的物理地址gpa,而是使用io虚拟地址,即iova。Virtio ring的desc中记录的是guest的iova,vhost-user拷贝报文需要先将iova转换为vhost-uesr进程的hva,而iova到hva的转换还需要qemu参与,这个过程需要和qemu交互。如果guset支持vIOMMU除了对应的qemu和dpdk版本需要支持,还需要支持VIRTIO_F_IOMMU_PLATFORM这个feature。
前面说过vhost-user每次将iova转换为gpa需要让qemu协助,这是通过一个单独的unix socket连接完成的,其中关键的转换有以下三个:
1. QEMU的vIOMMU将IOVA(I / O虚拟地址)转换为GPA(客户机物理地址)。
2. Qemu的内存管理将GPA(客户物理地址)转换为HVA(qemu进程地址空间内的主机虚拟地址)。
3. Vhost-user库将(QEMU的)HVA转换为自己的HVA。这通常很简单,只需在vhost-user库映射QEMU的内存时将QEMU的HVA添加到mmap返回的地址中即可。
但是如果每个desc的地址转换都需要和qemu进行一次通信,无疑会使转发性能大打折扣。所以vhost-uesr进行了一些优化,具体就是实现一个IOTLB的cache。下图是vhost-user开启vIOMMU后的地址转换流程。
优势:建立iotlb 不用每次都翻译,提升效率
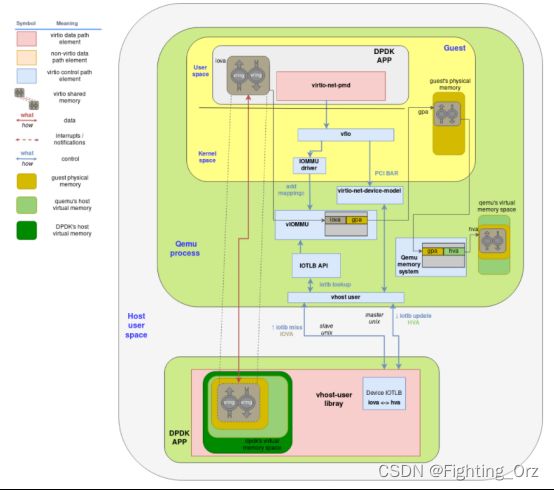
这个图的几个关键点如下:
- 客户机的物理内存空间是客户机所感知的物理内存,但显然,它位于QEMU的进程(主机)虚拟地址内部。分配了虚拟队列内存区后,该内存最终会落在客户机的物理内存空间中的某个位置。
- 将I / O虚拟地址分配给包含虚拟队列的内存范围时,带有其关联的客户机物理地址(GPA)的条目将添加到vIOMMU的TLB表中。
- 另一方面,QEMU的内存管理系统知道客户机物理内存空间在其自己的内存空间中的位置,因此,它能够将客户机物理地址转换为主机(QEMU)的虚拟地址。
- 当vhost-user库尝试访问其没有转换的IOVA时,它将通过辅助unix套接字发送IOTLB未命中消息。
- IOTLB API接收请求并查找地址,首先将IOVA转换为GPA,最后将GPA转换为HVA,然后通过主机unix套接字将转换后的地址发送回vhost-user库。
- 最后,vhost-user库必须进行一次最终转换。由于已将qemu的内存映射到自己的内存,因此必须将qemu的HVA转换为自己的HVA并访问共享内存。
-
-
- Interrupt remapping
-
上面介绍完vIOMMU的DMA remaping后再来看下interrupt remapping。X86系统的中断相关架构图如下所示:
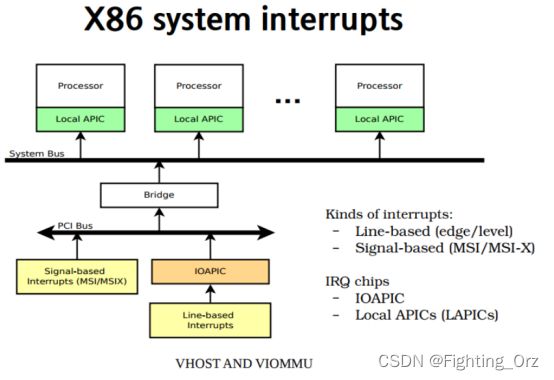
传统的INT中断通过IOAPIC转发到对应的Local APIC。如果没有interrupt remapping(IR)时,MSI中断会直接被送入guest,否则就会查询IR table,具体过程如下图。
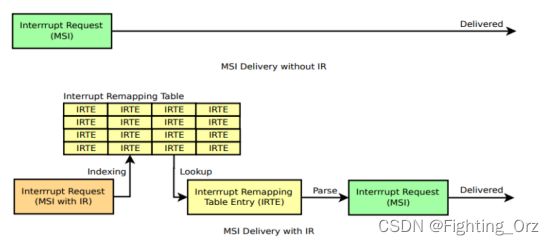
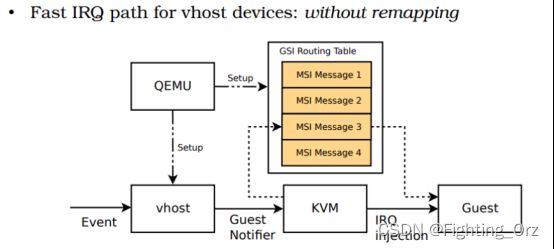
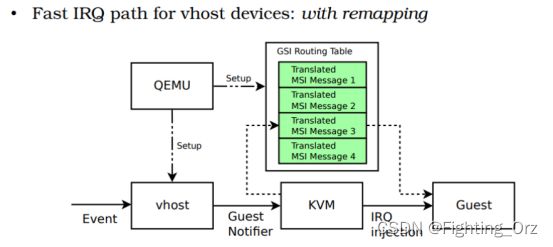
而vhost-user又是通过irqfd传递中断消息的。Qemu在支持IR前后对irqfd的相关设置也是不同的,具体如下图所示。
-
-
- 总结
-
vIOMMU增加了设备对guest的内存访问的安全性,同时vIOMMU的支持可以让guest内部可以使用vfio驱动允许dpdk,否则就只能使用uio或者vifo的noiommu模式:
/sbin/modprobe vfio enable_unsafe_noiommu_mode=1
/sbin/modprobe vfio-pci
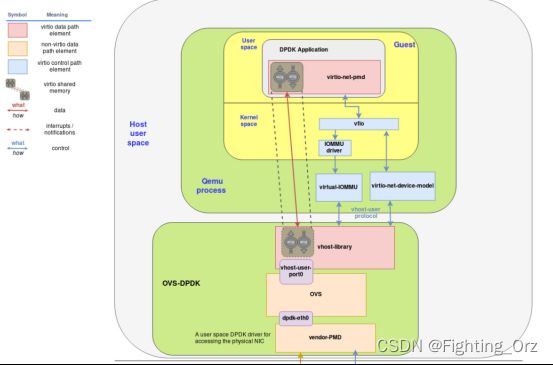
最后再一张图看一下IOMMU和vIOMMU的对比和不同的位置。

-
- driver_probe
参考链接:linux 驱动probe 被调用流程分析_goodnight1994的博客-CSDN博客_probe调用流程
至此,就调用到了你在自己驱动里边实现的your_probe_func()里边了,
关于probe函数,在里边主要做的主要工作如下:
a,给设备上电;
主要用到的函数为:regulator_get()
regulator_set_voltage()
具体上多少电,在哪一个电路上电,和你在dtsi文件的配置有关,而dtsi如何来配置,
也取决于设备在硬件上接哪路电路供电以及芯片平台对配置选项的定义。
b,初始化设备;
c,创建相关节点接口;
主要用到的函数为: sysfs_create_group();
需要实现static struct attribute_group 的一个结构体以及你需要的接口,如:
创建完节点后,就可以在linux应用层空间通过操作节点来调用驱动里边的对应函数了。
如,对节点enable,delay的read(或cat),write(或echo),就对应到其驱动实现的
-
- [2016] An Introduction to PCI Device Assignment with VFIO by Alex Williamson
链接:https://www.youtube.com/watch?v=WFkdTFTOTpA

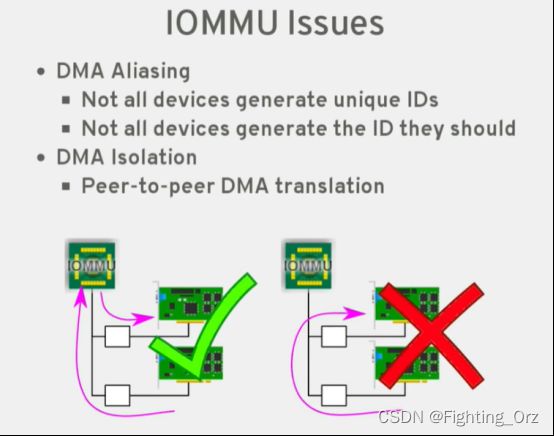



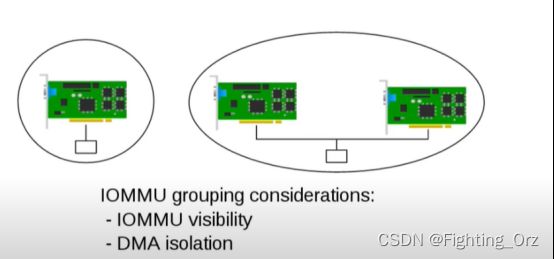
-
- vfio
参考链接:https://www.kernel.org/doc/Documentation/vfio.txt
许多现代系统现在都提供DMA和中断重新映射工具,以帮助确保I/O设备在分配给它们的边界内运行。这包括带有AMD-Vi和Intel VT-d的x86硬件,带有可分区端点(PEs)的POWER系统,以及诸如飞思卡尔PAMU的嵌入式PowerPC系统。VFIO驱动程序是一个IOMMU/设备无关的框架,用于在一个安全的IOMMU受保护环境中向用户空间公开直接的设备访问。换句话说,这允许安全的[2]_、非特权的用户空间驱动程序。
我们为什么要这样做?虚拟机通常在配置为最高的I/O性能时使用直接设备访问(“设备分配”)。从设备和主机的角度来看,这只是将虚拟机转变为用户空间驱动程序,具有显著减少延迟、更高带宽和直接使用裸机设备驱动程序[3]_的好处。一些应用程序,特别是在高性能计算领域,也受益于低开销,直接从用户空间的设备访问。例子包括网络适配器(通常是非基于tcp /IP的)和计算加速器。VFIO之前,这些驱动必须经过完整的开发周期,成为合适的上游驱动,保持树,或利用UIO的框架,没有IOMMU保护的概念,中断的支持有限,需要root特权访问诸如PCI配置空间。VFIO驱动程序框架打算统一这些,替换KVM PCI特定的设备分配代码,并提供一个比UIO更安全、更功能的用户空间驱动程序环境。
设备是任何I/O驱动的主要目标。 设备通常创建一个由I/O访问、中断和DMA组成的编程接口和DMA。 在不深入了解这些细节的情况下,到目前为止,DMA是维护安全环境的最关键的方面。因为允许一个设备对系统内存进行读写访问会给整个系统的完整性带来最大的风险。为了帮助减轻这种风险,许多现代的IOMMU现在将隔离属性纳入了
设备是任何 I/O 驱动程序的主要目标。设备通常创建一个由 I/O 访问、中断、
和DMA。在不详细讨论这些细节的情况下,DMA 是到目前为止,维护安全环境的最关键方面。因为允许设备对系统内存进行读写访问会对整个系统完整性的造成最大风险。为了帮助减轻这种风险,许多现代 IOMMU 现在都包含将属性隔离到,在许多情况下,只是一个接口用于翻译(即解决设备的寻址问题地址空间有限)。有了这个,现在可以隔离设备从彼此和任意内存访问,从而允许将设备安全地直接分配到虚拟机中。
这种隔离并不总是在单个设备的粒度上,即使 IOMMU 能够做到这一点,设备的属性,互连和 IOMMU 拓扑都可以减少这种隔离。
例如,一个单独的设备可能是一个更大的多设备的一部分。
功能外壳。虽然 IOMMU 可能能够区分外壳内的设备之间,外壳可能不需要设备之间的事务以到达 IOMMU。这方面的例子可以是带有后门的多功能 PCI 设备中的任何东西,在功能与非 PCI-ACS(访问控制服务)功能之间
桥允许重定向而不到达 IOMMU。拓扑
在隐藏设备方面也可以发挥作用。 PCIe 到 PCI
网桥掩盖了它背后的设备,使交易看起来好像
从桥本身。显然 IOMMU 设计起着主要的作用
也是。
因此,虽然在大多数情况下 IOMMU 可能具有设备级别粒度,任何系统都容易受到粒度降低的影响。因此,IOMMU API 支持 IOMMU 组的概念。
一组设备,可与系统中的所有其他设备隔离。因此,组是 VFIO 使用的所有权单位。虽然组是必须用于的最小粒度确保安全的用户访问,它不一定是首选粒度。在使用页表的 IOMMU 中,它可能是可以在不同组之间共享一组页表,减少平台的开销(减少 TLB 抖动,减少重复的页表),并给用户(仅编程一组翻译)。因此,VFIO 利用一个容器类,它可以包含一个或多个组。一个容器只需打开 /dev/vfio/vfio 字符设备即可创建。
容器本身提供的功能很少,所有
但是有几个版本和扩展查询接口被锁定了。
用户需要将组添加到容器中以进行下一级
的功能。为此,用户首先需要识别与所需设备关联的组。这可以使用以下示例中描述的 sysfs 链接。通过解除绑定来自主机驱动程序的设备并将其绑定到 VFIO 驱动程序,一个新的该组的 VFIO 组将显示为 /dev/vfio/$GROUP,其中$GROUP 是设备所属的 IOMMU 组号。
如果 IOMMU 组包含多个设备,则每个设备都需要在对 VFIO 组进行操作之前绑定到 VFIO 驱动程序,被允许(仅解除设备绑定就足够了如果 VFIO 驱动程序不可用,则主机驱动程序;这将使组可用,但不是该特定设备)。待定 - 接口
用于禁用驱动程序探测/锁定设备。
组准备好后,可以通过打开将其添加到容器中VFIO 组字符设备 (/dev/vfio/$GROUP) 并使用VFIO_GROUP_SET_CONTAINER ioctl,传递文件描述符以前打开的容器文件。如果需要 IOMMU 驱动程序支持组间共享 IOMMU 上下文,多个组可以设置为同一个容器。如果组未能设置为容器对于现有组,需要使用一个新的空容器
反而。
将一个(或多个)组附加到容器上,剩余的ioctl 变得可用,从而可以访问 VFIO IOMMU 接口。此外,现在可以获取每个文件的文件描述符在 VFIO 组文件描述符上使用 ioctl 的组内设备。
VFIO 设备 API 包括用于描述设备的 ioctl、I/O区域及其在设备描述符上的读/写/mmap 偏移量,以及用于描述和注册中断的机制、通知
-
- KVM详解,太详细太深入了,经典
参考链接:KVM详解,太详细太深入了,经典_sdulibh的博客-CSDN博客_kvm如何分配硬件资源

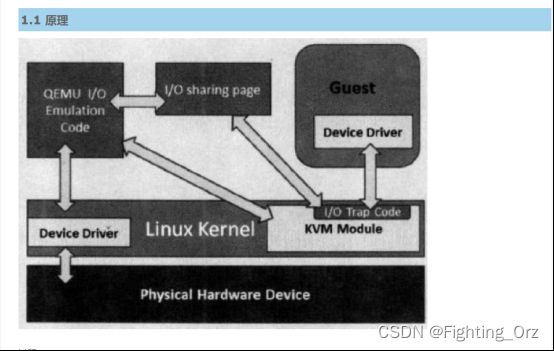
过程:
客户机的设备驱动程序发起 I/O 请求操作请求
KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求
经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序。
QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作。
完成之后,QEMU 将结果放回 I/O 共享页,并通知 KMV 模块中的 I/O 操作捕获代码。
KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机。
注意:当客户机通过DMA (Direct Memory Access)访问大块I/O时,QEMU 模拟程序将不会把结果放进共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中共,然后通知KVM模块告诉客户机DMA操作已经完成。
这种方式的优点是可以模拟出各种各样的硬件设备;其缺点是每次 I/O 操作的路径比较长,需要多次上下文切换,也需要多次数据复制,所以性能较差。
Virtio 是在半虚拟化管理程序中的一组通用模拟设备的抽象。这种设计允许管理程序通过一个应用编程接口 (API)对外提供一组通用模拟设备。通过使用半虚拟化管理程序,客户机实现一套通用的接口,来配合后面的一套后端设备模拟。后端驱动不必是通用的,只要它们实现了前端所需的行为。因此,Virtio 是一个在 Hypervisor 之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,进而根据 virtio 标准与 Hypervisor 协作,从而客户机达到更好的性能。
- 前端驱动:客户机中安装的驱动程序模块
- 后端驱动:在 QEMU 中实现,调用主机上的物理设备,或者完全由软件实现。
- virtio 层:虚拟队列接口,从概念上连接前端驱动和后端驱动。驱动可以根据需要使用不同数目的队列。比如 virtio-net 使用两个队列,virtio-block只使用一个队列。该队列是虚拟的,实际上是使用 virtio-ring 来实现的。
- virtio-ring:实现虚拟队列的环形缓冲区
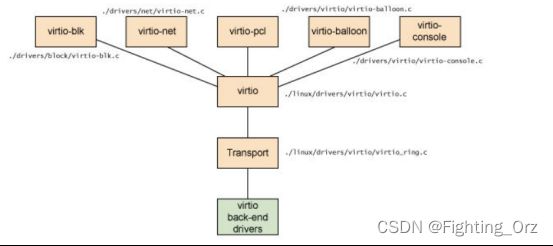
Linux 内核中实现的五个前端驱动程序:
- 块设备(如磁盘)
- 网络设备
- PCI 设备
- 气球驱动程序(动态管理客户机内存使用情况)
- 控制台驱动程序
Guest OS 中,在不使用 virtio 设备的时候,这些驱动不会被加载。只有在使用某个 virtio 设备的时候,对应的驱动才会被加载。每个前端驱动器具有在管理程序中的相应的后端的驱动程序。
以 virtio-net 为例,解释其原理:
virtio-net 的原理:
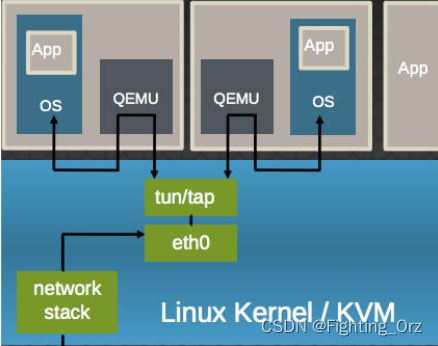
它使得:
- 多个虚机共享主机网卡 eth0
- QEMU 使用标准的 tun/tap 将虚机的网络桥接到主机网卡上
- 每个虚机看起来有一个直接连接到主机PCI总线上的私有 virtio 网络设备
- 需要在虚机里面安装 virtio驱动
virtio-net 的流程:
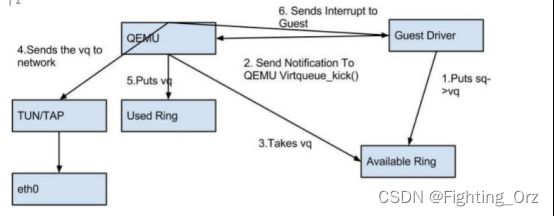
总结 Virtio 的优缺点:
- 优点:更高的IO性能,几乎可以和原生系统差不多。
- 缺点:客户机必须安装特定的 virtio 驱动。一些老的 Linux 还没有驱动支持,一些 Windows 需要安装特定的驱动。不过,较新的和主流的OS都有驱动可以下载了。Linux 2.6.24+ 都默认支持 virtio。可以使用 lsmod | grep virtio 查看是否已经加载。
-
-
- vhost-net (kernel-level virtio server)
-
前面提到 virtio 在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而如果对于网络 I/O 请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做 “vhost-net” 的驱动模块,它是作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,减少内核空间到用户空间的切换,从而提高效率。
根据 KVM 官网的这篇文章,vhost-net 能提供更低的延迟(latency)(比 e1000 虚拟网卡低 10%),和更高的吞吐量(throughput)(8倍于普通 virtio,大概 7~8 Gigabits/sec )。
vhost-net 与 virtio-net 的比较:
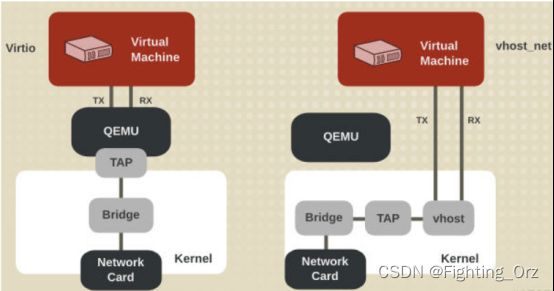
host-net 的要求:
- qemu-kvm-0.13.0 或者以上
- 主机内核中设置 CONFIG_VHOST_NET=y 和在虚机操作系统内核中设置 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 开始支持该特性)
- 在客户机内使用 virtion-net 前段驱动
- 在主机内使用网桥模式,并且启动 vhost_net

- pKVM
参考链接:LWN:Android上使用KVM!_LinuxNews搬运工的博客-CSDN博客
IOMMU 对于避免 DMA 攻击来说是有必要的,但目前的 SoC 都还没有真正准备好。理想情况下,IOMMU 可以简单地重新使用 CPU 中已经在用的页表,因此在 EL2 中只需要很有限的 IOMMU 管理代码。如果在 EL2 中添加多个不同的 IOMMU driver,使得代码变得臃肿,那不是一个好方案。
- smmu_spec
date:2021/4/31 版本



- vfio与iommu关系
参考链接:IOMMU DMA VFIO 一站式分析 | Yi颗烂樱桃
VFIO就是内核针对IOMMU提供的软件框架,支持DMA Remapping和Interrupt Remapping,这里只讲DMA Remapping。VFIO利用IOMMU这个特性,可以屏蔽物理地址对上层的可见性,可以用来开发用户态驱动(无虚拟机),也可以实现设备透传(虚拟机)。

-
- vfio 设备直通简介
参考链接:VFIO 设备直通简介 · Kernelgo's KVM学习笔记
Virtual Function I/O (VFIO) 是一种现代化的设备直通方案,它充分利用了VT-d/AMD-Vi技术提供的DMA Remapping和Interrupt Remapping特性, 在保证直通设备的DMA安全性同时可以达到接近物理设备的I/O的性能。 用户态进程可以直接使用VFIO驱动直接访问硬件,并且由于整个过程是在IOMMU的保护下进行因此十分安全, 而且非特权用户也是可以直接使用。 换句话说,VFIO是一套完整的用户态驱动(userspace driver)方案,因为它可以安全地把设备I/O、中断、DMA等能力呈现给用户空间。
为了达到最高的IO性能,虚拟机就需要VFIO这种设备直通方式,因为它具有低延时、高带宽的特点,并且guest也能够直接使用设备的原生驱动。 这些优异的特点得益于VFIO对VT-d/AMD-Vi所提供的DMA Remapping和Interrupt Remapping机制的应用。 VFIO使用DMA Remapping为每个Domain建立独立的IOMMU Page Table将直通设备的DMA访问限制在Domain的地址空间之内保证了用户态DMA的安全性, 使用Interrupt Remapping来完成中断重映射和Interrupt Posting来达到中断隔离和中断直接投递的目的。
1. VFIO 框架简介
整个VFIO框架设计十分简洁清晰,可以用下面的一幅图描述:

最上层的是VFIO Interface Layer,它负责向用户态提供统一访问的接口,用户态通过约定的ioctl设置和调用VFIO的各种能力。 中间层分别是vfio_iommu和vfio_pci,vfio_iommu是VFIO对iommu层的统一封装主要用来实现DMAP Remapping的功能,即管理IOMMU页表的能力。 vfio_pci是VFIO对pci设备驱动的统一封装,它和用户态进程一起配合完成设备访问直接访问,具体包括PCI配置空间模拟、PCI Bar空间重定向,Interrupt Remapping等。 最下面的一层则是硬件驱动调用层,iommu driver是与硬件平台相关的实现,例如它可能是intel iommu driver或amd iommu driver或者ppc iommu driver, 而同时vfio_pci会调用到host上的pci_bus driver来实现设备的注册和反注册等操作
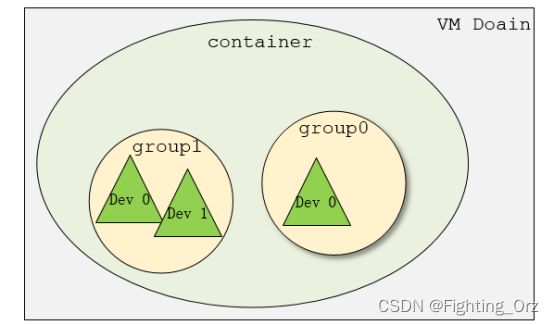
在了解VFIO之前需要了解3个基本概念:device, group, container,它们在逻辑上的关系如上图所示。
- Group 是IOMMU能够进行DMA隔离的最小硬件单元,一个group内可能只有一个device,也可能有多个device,这取决于物理平台上硬件的IOMMU拓扑结构。 设备直通的时候一个group里面的设备必须都直通给一个虚拟机。 不能够让一个group里的多个device分别从属于2个不同的VM,也不允许部分device在host上而另一部分被分配到guest里, 因为就这样一个guest中的device可以利用DMA攻击获取另外一个guest里的数据,就无法做到物理上的DMA隔离。 另外,VFIO中的group和iommu group可以认为是同一个概念。
- Device 指的是我们要操作的硬件设备,不过这里的“设备”需要从IOMMU拓扑的角度去理解。如果该设备是一个硬件拓扑上独立的设备,那么它自己就构成一个iommu group。 如果这里是一个multi-function设备,那么它和其他的function一起组成一个iommu group,因为多个function设备在物理硬件上就是互联的, 他们可以互相访问对方的数据,所以必须放到一个group里隔离起来。值得一提的是,对于支持PCIe ACS特性的硬件设备,我们可以认为他们在物理上是互相隔离的。
- Container 是一个和地址空间相关联的概念,这里可以简单把它理解为一个VM Domain的物理内存空间。
从上图可以看出,一个或多个device从属于某个group,而一个或多个group又从属于一个container。 如果要将一个device直通给VM,那么先要找到这个设备从属的iommu group,然后将整个group加入到container中即可。关于如何使用VFIO可以参考内核文档:vfio.txt
-
- VFIO(Virtual Function IO)研究
- 研究目的
- VFIO(Virtual Function IO)研究
参考链接:VFIO(Virtual Function IO)研究_敲出钞能力的博客-CSDN博客
研究利用-device vfio-pci的方式将PCI透传到虚拟机中后,在虚拟机中访问PCI设备的配置空间,MMIO寄存器,IO Port的流程是怎样的.
VFIO原理
VFIO把设备通过IOMMU映射的DMA物理内存地址映射到用户态中,让用户态程序可以自行操纵数据的传输,还可以自行注册中断处理函数,从而在用户态下实现设备的驱动程序.
因此VFIO的基础是IOMMU.
-
-
- IOMMU
-
基础功能
- 地址翻译
IOMMU可以将能直接访问memory的IO总线(DMA–capable)连接到RAM中.
与传统的MMU功能类似,MMU能将CPU使用的虚拟地址转化为物理地址,而IOMMU能将device使用的虚拟地址(也称为设备地址或者IO地址)转化为物理地址.
如果没有IOMMU,DMA也能直接访问RAM中的内容,但是让DMA没有限制地访问RAM是一件很危险的事情,而IOMMU能够对这个过程加以限制,当DMA访问的地址合法时,IOMMU才返回正确的数据.
- 硬件中断重映射
除了翻译地址的功能,IOMMU还能对硬件中断进行重映射,达到屏蔽部分中断,或自定义中断处理函数的目的.
- 设备隔离
基于地址翻译和硬件中断重映射两大功能,IOMMU就具有了隔离设备的能力,这提高了设备访问RAM时和设备发出中断时的安全性.
除了将单个设备隔离的功能外,IOMMU还能隔离一组设备,如隔离PCI桥上的几个设备,所以IOMMU还有一个概念,叫做IOMMU_GROUP, 代表一组被隔离的设备的集合.
通过把host的device和对应driver解绑,然后绑定在VFIO的driver上,就会在/dev/vfio/目录下出现一个group,这个group就是IOMMU_GROUP号,如果需要在该group上使用VFIO,需要将该group下的所有device与其对应的驱动解绑.
VFIO Container
在IOMMU_GROUP的基础上,VFIO封装了一层Container Class,Container的作用是,当我们想在不同的IOMMU_GROUP之间共享TLB和page tables(用于地址翻译的页表)时,就将这些group放到同一个container中,因此Container可以看做是IOMMU_GROUP的集合.
虚拟化中VFIO的应用
这里演示一个将网卡设备利用VFIO透传到虚拟机中的例子.需要注意的是,利用VFIO将PCI设备透传到虚拟机之后,Host将无法使用该设备.
-
- IOMMU历史知识及与VFIO的联系
参考链接
在虚拟化普及之前,IOMMU主要提供2种功能,
- 避免bounce buffers的功能,
- 创建连续DMA操作功能。
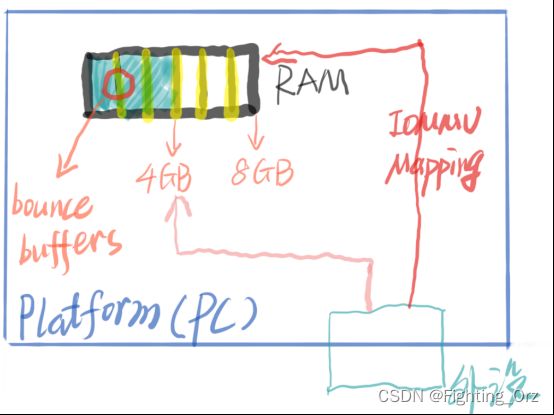
Bounce Buffers
如果外设的寻址空间小于平台(如PC)的寻址空间,例如外设只支持寻址4GB空间,但是PC支持寻址8GB,如果PC中的驱动程序分配了4GB以上的空间给设备,那么设备将无法对该空间执行DMA操作。
解决该问题的一种思路就是利用bounce buffers. Bounce buffers是处于较低内存中的缓冲区空间,外设可以在其中进行临时的DMA操作,操作完成后,将结果复制到驱动程序分配的高地址内存缓冲区中。
但是这种方法会导致效率降低,因为多了一步复制操作,当数据量比较大时,会明显降低数据处理效率。
IOMMU为外设提供IOVA空间,驱动程序可以通过访问IOVA来访问设备空间,避免了bounce buffers的使用,提高了数据处理效率。
Creating contiguous DMA operations
当驱动程序使用多个buffers时,IOMMU可以将这多个buffer映射成连续的地址,这样方便操作,例如之前需要对2个4KB大小的buffer进行2个4KB大小的DMA操作,现在只需要进行1个8KB大小的DMA操作,提高了效率。

这两个功能对于host上的高性能I / O仍然很重要,但是从虚拟化角度来看,我们喜欢的IOMMU功能是现代IOMMU的隔离功能。在PCI-Express之前,不可能进行大规模的隔离,因为常规PCI不会使用请求设备的ID(请求者ID)来标记transaction。 PCI-X包含某种程度的请求者ID,但是互连规则使支持的隔离性不完整。使用PCIe,每个设备都使用该设备唯一的请求者ID(PCI总线/设备/功能编号,BDF)来标记事务,该请求者ID用于引用该设备的唯一IOVA表。我们忽然之间从 “从共享的IOVA空间卸载无法访问的内存并整合内存”,到“每个设备都拥有一个IOVA空间”,我们不仅可以将其用于这些功能(卸载无法访问的内存并整合内存),还可以限制来自设备的DMA访问。为了分配给虚拟机,现在只需要将IOVA放在Host分配给VM使用的物理空间内,该设备就可以在Guest地址空间中透明地执行DMA。
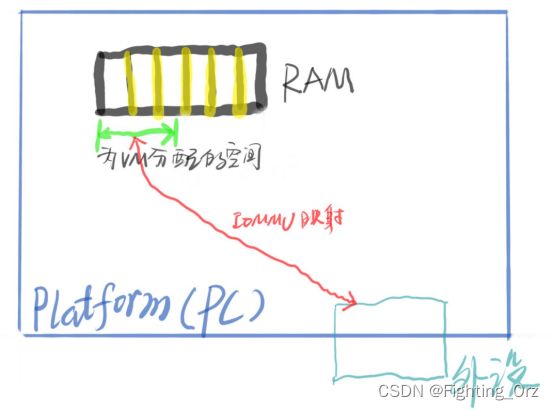
IOMMU_GROUP: IOMMU group试图描述从IOMMU的角度来看可以隔离的最小设备集。这样做的第一步是每个设备必须关联到唯一的IOVA空间。也就是说,如果多个设备使用相同的IOVA空间作为别名,则IOMMU无法区分它们。这就是典型的x86 PC将所有常规PCI设备分组在一起的原因,所有这些设备的别名为同一PCIe至PCI桥接器。旧式KVM设备分配将允许用户独立分配这些设备给guest,但是肯定会配置失败。 VFIO由IOMMU组控制,因此可以防止违反IOMMU粒度这一最基本要求的配置。
-
- Virtual IOMMU(cloud)
参考链接:cloud-hypervisor/iommu.md at v19.0 · cloud-hypervisor/cloud-hypervisor · GitHub
-
-
- 基本原理
-
将虚拟IOMMU暴露给客户的可能性对于支持特定的用例是很有趣的。尽管如此,重要的是要记住虚拟IOMMU可能会影响连接设备的性能,这就是为什么在启用这一功能时要小心的原因
保护嵌套虚拟机
为什么要向客户暴露一个虚拟IOMMU的第一个原因是为了提高虚拟设备(VIRTIO设备)代表客户驱动执行的内存访问的安全性。
有了虚拟IOMMU,VMM站在客户驱动和它的设备对应物之间,在尝试访问客户内存之前验证和翻译每个地址。这是由VMM执行的标准插值。
增加的安全性不适用于一个简单的情况,即每个VMM有一个虚拟机。因为客体不能被信任,因为我们总是认为它可能是恶意的,并在虚拟机内获得未经授权的权限,防止一些设备访问整个客体内存是没有意义的。
但是,让我们来看看嵌套虚拟化的有趣案例,让我们假设我们有一个VMM在运行第一层虚拟机。这个L1客体是完全可信的,因为用户打算从这个L1运行多个VM。我们最终可能会有多个二层虚拟机运行在一个L1虚拟机上。在这种特殊情况下,如果不向L1客体暴露一个虚拟IOMMU,任何L2客体都有可能使用来自主机VMM的设备实现来访问整个客体L1内存。虚拟IOMMU可以防止这种麻烦,因为它将验证设备被授权访问的地址。
实现VFIO嵌套
拥有一个虚拟IOMMU的另一个原因是允许从主机通过多层虚拟化传递物理设备。让我们以一个有物理IOMMU的系统为例,运行一个有虚拟IOMMU的虚拟机。虚拟IOMMU的实现负责在每次DMA映射变化时更新物理DMA重映射表(DMAR)。这必须通过主机上的VFIO框架进行,因为这是与物理IOMMU互动的唯一用户空间接口。
依靠这种更新机制,有可能将物理设备附加到虚拟IOMMU上,这使得这些设备可以从L1传递到另一个虚拟化层。
-
-
- 为什么是 virtio-iommu?
-
云管理程序项目决定实施全新的virtio-iommu设备,以便为其用户提供一个虚拟的IOMMU。其原因是准虚拟化解决方案带来的简单性。通过由客体本身处理的一面,它消除了捕获内存页访问和阴影的复杂性。这就是为什么该项目不会试图实现对物理IOMMU的完全仿真。
前提条件
由于virtio-iommu已经部分进入了5.3版本的Linux内核,所以需要一个特殊的分支来使事情与云管理程序一起工作。我们说的部分是指x86,因为它已经完全适用于ARM架构。
用法
为了将虚拟IOMMU暴露给客户,需要创建一个virtio-iommu设备并通过ACPI IORT表将其暴露。这可以通过将至少一个设备附加到虚拟IOMMU上简单地实现。
向客户公开一个特定的设备作为这个IOMMU后面的设备的方法是在命令行中明确地用iommu=on选项来标记它。
并非所有的设备都支持这个额外的选项,默认值总是关闭的,因为我们想避免对大多数不需要这个选项的用户的性能产生影响。
请参考命令行--help,找出要连接到虚拟IOMMU的设备支持。
下面是一个简单的例子,将virtio-blk设备连接到虚拟IOMMU上。
-
- linux doc for vfio
参考链接:https://www.kernel.org/doc/Documentation/vfio.txt
许多现代系统现在提供了DMA和中断重映射设施以帮助确保I/O设备在它们被分配的范围内行事。 这包括带有AMD-Vi和Intel VT-d的x86硬件。带有可分区端点(PE)的POWER系统和嵌入式PowerPC系统,如飞思卡尔PAMU。 VFIO驱动是一个IOMMU/设备不可知的框架,在一个安全的、受IOMMU保护的环境下,设备直接访问用户空间。 换句话说,这允许
我们为什么要这样做? 虚拟机往往利用直接设备访问("设备分配"),当配置为最高可能的I/O性能。 从设备和主机的角度来看,这只是将虚拟机变成一个用户空间驱动程序,其好处是著减少延迟,提高带宽,并直接使用裸机设备驱动程序
一些应用程序,特别是在高性能计算领域,也受益于用户空间的低开销、直接设备访问。 示例包括网络适配器(通常不基于 TCP/IP)和计算加速器。 在 VFIO 之前,这些驱动要么经过完整的开发周期成为合适的上游驱动,在树外维护,要么使用 UIO 框架,它没有 IOMMU 保护的概念,有限的中断支持,并且需要 root 权限 访问诸如 PCI 配置空间之类的东西。 VFIO 驱动程序框架旨在统一这些,取代 KVM PCI 特定的设备分配代码,并提供比 UIO 更安全、更有功能的用户空间驱动程序环境。 组、设备和 IOMMU
设备是任何 I/O 驱动程序的主要目标。设备通常会创建一个由 I/O 访问、中断和 DMA 组成的编程接口。在不详细介绍这些细节的情况下,DMA 是迄今为止维护安全环境的最关键方面,因为允许设备对系统内存进行读写访问会对整个系统完整性造成最大风险。
为了帮助减轻这种风险,许多现代 IOMMU 现在将隔离属性合并到在许多情况下仅用于转换的接口中(即解决地址空间有限的设备的寻址问题)。有了这个,设备现在可以相互隔离,也可以与任意内存访问隔离,从而允许将设备安全地直接分配到虚拟机中。
但是,这种隔离并不总是在单个设备的粒度上。即使 IOMMU 能够做到这一点,设备、互连和 IOMMU 拓扑的属性都可以降低这种隔离。例如,单个设备可能是更大的多功能机箱的一部分。虽然 IOMMU 可能能够区分机箱内的设备,但机箱可能不需要设备之间的事务来到达 IOMMU。这方面的例子可以是任何东西,从在功能之间具有后门的多功能 PCI 设备到不支持 PCI-ACS(访问控制服务)的桥接器,允许重定向而不到达 IOMMU。拓扑也可以在隐藏设备方面发挥作用。 PCIe-to-PCI 桥掩盖了它背后的设备,使事务看起来好像来自桥本身。显然,IOMMU 设计也是一个主要因素。
因此,虽然在大多数情况下 IOMMU 可能具有设备级粒度,但任何系统都容易受到粒度降低的影响。因此,IOMMU API 支持 IOMMU 组的概念。组是一组可与系统中所有其他设备隔离的设备。因此,组是 VFIO 使用的所有权单位。
虽然组是确保安全用户访问所必须使用的最小粒度,但它不一定是首选粒度。在使用页表的 IOMMU 中,可以在不同组之间共享一组页表,从而减少平台(减少 TLB 抖动,减少重复页表)和用户(仅编程单组翻译)。出于这个原因,VFIO 使用了一个容器类,它可以包含一个或多个组。只需打开 /dev/vfio/vfio 字符设备即可创建容器。
就其本身而言,容器提供的功能很少,除了几个版本和扩展查询接口之外,所有功能都被锁定。用户需要将组添加到容器中以实现下一级功能。为此,用户首先需要识别与所需设备相关联的组。这可以使用下面示例中描述的 sysfs 链接来完成。通过将设备与主机驱动程序解除绑定并将其绑定到 VFIO 驱动程序,该组将出现一个新的 VFIO 组,名称为 /dev/vfio/$GROUP,其中 $GROUP 是设备所属的 IOMMU 组号。如果 IOMMU 组包含多个设备,则在允许对 VFIO 组进行操作之前,每个设备都需要绑定到 VFIO 驱动程序(如果 VFIO 驱动程序不可用,仅解除设备与主机驱动程序的绑定也足够了;这将使组可用,但不是那个特定的设备)。 TBD - 用于禁用驱动程序探测/锁定设备的接口。
一旦组准备好,可以通过打开 VFIO 组字符设备 (/dev/vfio/$GROUP) 并使用 VFIO_GROUP_SET_CONTAINER ioctl 将其添加到容器中,并传递先前打开的容器文件的文件描述符。如果需要并且 IOMMU 驱动程序支持在组之间共享 IOMMU 上下文,则可以将多个组设置为同一个容器。如果一个组未能设置为具有现有组的容器,则需要使用新的空容器来代替。
将一个(或多个)组附加到容器后,剩余的 ioctl 变为可用,从而可以访问 VFIO IOMMU 接口。此外,现在可以使用 VFIO 组文件描述符上的 ioctl 获取组内每个设备的文件描述符。
VFIO 设备 API 包括用于描述设备的 ioctl、I/O 区域及其在设备描述符上的读/写/mmap 偏移量,以及用于描述和注册中断通知的机制。 VFIO 使用示例
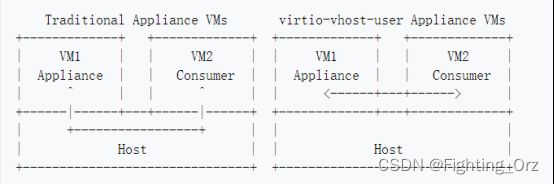
virtio-vhost-user
参考链接:Features/VirtioVhostUser - QEMU
virtio-vhost-user设备让客座充当vhost设备后端,这样虚拟网络交换机和存储设备虚拟机就可以为其他客座提供virtio设备。virtio-vhost-user目前正在开发中,还没有准备好用于生产。
- 用于云环境的设备
在云环境中,所有东西都是客体。用户不可能在主机上运行vhost-user进程。这使得高性能的vhost-user设备无法在云环境中运行。
virtio-vhost-user允许vhost-user设备以虚拟机图像的形式被运送。它们可以直接向其他客人提供I/O服务,而不是通过额外的设备模拟层,如主机网络交换机。
- 无需退出的vm间通信
一旦vhost-用户会话建立起来,所有的vring活动都可以由共享内存中的轮询模式驱动程序执行。这消除了数据路径中的vmexits,因此可以实现最高的虚拟机到虚拟机通信性能。即使在需要中断的时候,virtio-vhost-user也可以使用轻量级的vmexits,这要感谢ioeventfd,而不是退出到主机用户空间。这确保了虚拟机到虚拟机的通信绕过了QEMU的设备仿真。
- 工作方法
Virtio设备最初是在QEMU主机用户空间进程中模拟的。后来,vhost允许virtio设备的一个子集,称为vhost设备后端,在主机内核内实现。vhost-user允许vhost设备后端驻留在主机用户空间进程中。
virtio-vhost-user通过将vhost设备后端移到客户机中,使其更进一步。它的工作原理是将vhost-user协议通过一个新的virtio设备类型(称为virtio-vhost-user)进行隧道化。
下图显示了两个访客的通信方式。
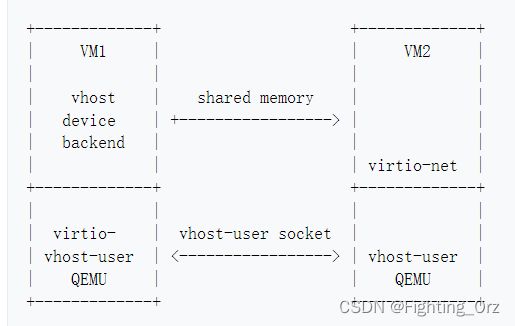
- VM2看到的是一个普通的virtio-net设备。VM2的QEMU使用现有的vhost-user功能,就像它与主机用户空间vhost-user后端对话一样。
- VM1的QEMU将vhost-user协议信息从VM1的QEMU隧道到新的virtio-vhost-user设备,这样VM1的客户软件就可以作为vhost-user后端。
- 可以用virtio-vhost-user重新使用现有的vhost-user后端软件,因为它们使用相同的vhost-user协议信息。virtio-vhost-user的PCI设备需要一个驱动程序,以代替通常的vhost-user UNIX域套接字来传输信息。该驱动可以在客户用户空间进程中使用Linux vfio-pci实现,但客户内核驱动的实现也是可能的。
- vhost设备后端vrings是通过共享内存访问的,在数据路径中不需要vhost-用户的信息交换。当使用轮询模式驱动时,没有vmexits。即使在使用中断时,QEMU也不参与数据路径,因为ioeventfd轻量级的vmexits被占用。
- 所有的vhost设备类型都与virtio-vhost-user一起工作,包括net、scsi和blk。
-
结论
- virtio iommu 是vfio 透传iommu设备给guest外,允许将设备设备分配给guest os实现方法
- virtio-iommu的当前目标是让一个半虚拟的IOMMU在Arm上工作,并允许设备分配给客户用户空间。
- 在Arm上,将设备分配给客户用户空间的唯一方法需要嵌套转换,这不是所有SMMUs都支持的,或者使用virtio-iommu。virtio-iommu设备允许客户管理物理、仿真和半虚拟化端点的DMA映射。
- qemu最早支持intel-iommu和iommu=smmuv3,后来有virtio-iommu,又演化出vhost-iommu,把virtio-iommu部分功能拿到内核来实现。整体上分为full emulated和hardware assisted emulation,full emulation就是virtio-iommu,纯软件实现iommu的所有功能,性能低,但virtio应用广,能和现有的实现结合起来。
- 我们的目标是通过将iommu 透传给一个虚拟机,并将其做为virtiio 后端,其他虚拟机中实现virtio 前端,进而达到设备共享的目的,并能够满足地址的隔离和dma功能,就目前的分析来看,并不具备参考价值
- 可以参考 virtio-vhost-user 的方法,来实现设备的共享和虚拟机之间的通信,目前还处于开发阶段,而且是基于qemu实现的,如果要迁移到crosvm中,工作量较大
- virtio-iommu 的spec 文档,并未公布出来