Redis学习--------缓存更新策略、缓存穿透、缓存击穿、缓存雪崩
1.缓存更新策略
1.1 内存淘汰
通过设置Redis的你内存回收策略,回收key,下次访问就会更新key的内容(原理待补充)。
1.2 过期剔除
通过 EXPIRE key seconds [ NX | XX | GT | LT] 命令为key设置过期时间,当key过期之后,再次访问时,会进行缓存重建。
1.3 被动更新(常用)
当缓存的key数据有所更新时,同步改动Redis中的缓存数据。
涉及的问题:
1. 当缓存数据有变化时,是删除缓存还是更新缓存?
使用删除缓存。
分析:如果使用更新缓存的方可能会出现许多的频繁的更新缓存的情况。比如某个key,用户查询较少,更新频繁。用户在A时刻从缓存中查询了这个key,在B时刻也获取了这个key,如果A B两个时刻,这个key对应的数据更新了很多次,每次数据库更新,都会同步更新到Redis中,会造成很多无效写操作。
使用删除缓存时,如果缓存的数据有更新,就会删除这个key,用户下次获取数据时会重新构建缓存。减少了无效写操作。
2. 如何保证缓存和数据库操作同时成功或者同时失败?
使用事务或者分布式事务。
3. 先操作数据库还是先操作缓存?
使用先操作数据库在操作缓存数据。
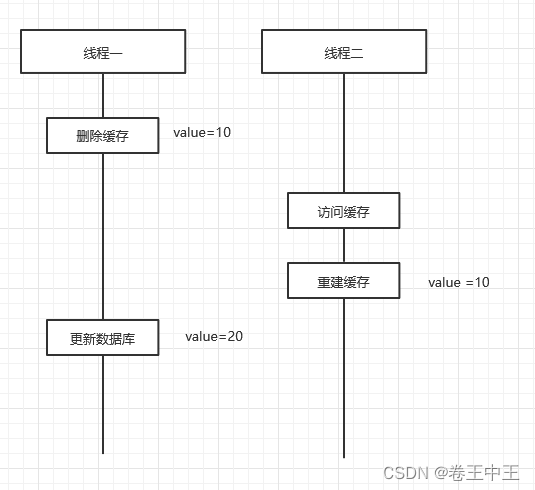
分析:如果先删除缓存,在更新数据库。如果多线程并发请求下,在删除缓存后,数据库更新前,有请求访问缓存时,就会重建缓存,然后i更新数据库,缓存里的数据就是历史数据。(图解一)
先操作数据库在删除缓存。在多线程 情况下如果访问的key刚好失效,在重建缓存之前,进行了数据库的操作和删除缓存,然后在重建缓存仍然时历史数据。但是这种情况相比上面的情况出现的机率较小,Redis的操作是远远快于数据库操作的(图解二)

2. 缓存穿透
2.1 场景
如果大量请求某个数据库不存在的数据时,这些请求会首先从Redis中取,由于Redis没有这个数据,所有的请求都会请求数据库,可能会造成数据库服务不可用活动宕机。

2.2 解决方案
2.2.1 缓存空值
如果在设置缓存时,查询的数据库为空值时,把空值作为value缓存到Redis中。然后为Redis的key设置过期时间。
优点:实现简单
缺点:可能会出现数据不一致的情况(如果缓存空值后,新增了这条数据,在过期时间之间可能会出现数据不一致的情况),可能会缓存许多空值
.
/**
* 解决redis缓存穿透(缓存空值)
*
* @param keyPrefix 缓存key前缀
* @param key 业务主键
* @param time 超时时间
* @param timeUnit 时间单位
* @param queryDBFun 查询数据库方法
* @param returnType 返回值类型
* @param 返回值类型
* @param 参数类型
* @return
*/
public <R,T> R resolveCacheThrough(String keyPrefix, T key, Long time, TimeUnit timeUnit, Function<T, R> queryDBFun, Class<R> returnType) {
String cacheKey = keyPrefix + ":" + String.valueOf(key);
// 查询缓存
String objectJson = stringRedisTemplate.opsForValue().get(cacheKey);
// 缓存是否命中
if(StrUtil.isNotBlank(objectJson)) {
// 缓存命中且不为空字符串,直接返回缓存数据
R r = JSON.parseObject(objectJson, returnType);
return r;
}
// 如果命中为空字符串,则返回null
if (objectJson != null) {
return null;
}
// 缓存未命中,查询数据库
R data = queryDBFun.apply(key);
// 数据是否存在
if (data == null) {
// 查询的数据不存在,缓存空字符串
stringRedisTemplate.opsForValue().set(cacheKey, "", time, timeUnit);
return null;
}
// 查询数据存在,重建缓存
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(data), time, timeUnit);
// 返回数据
return data;
}
2.2.2 布隆过滤器
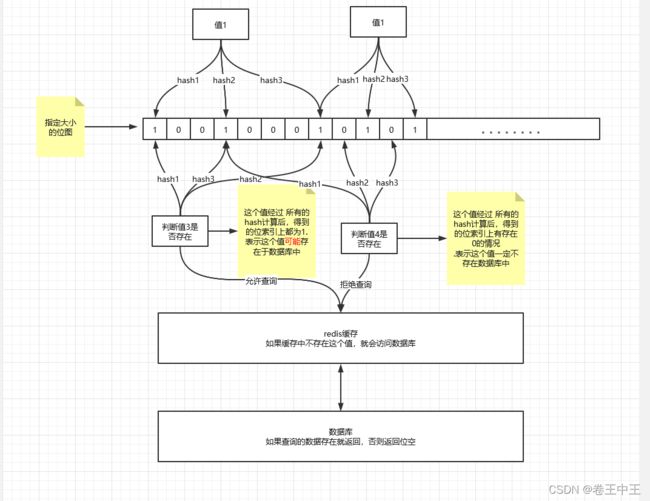
数据库中的数据会通过某种算法得到一个数值,会维护一个比较长的位图,会把计算的数值对应的位设置为1。如果请求某个数据时,首先经过布隆过滤器,根据数据求出对应的一个数值位,根据位图的数值位为1,表示存在这个数据,否则不存在数据,直接返回空数据。
优点:占用空间少
缺点:实现复杂,可能存在误判的情况(数据被删除,布隆过滤器不会更新)
2.2.3 辅助方案
1.数据库设置复杂的数据主键生成规则
2.数据主键生成设置某个生成规则
3.前端进行数据校验
3.缓存击穿
3.1 场景
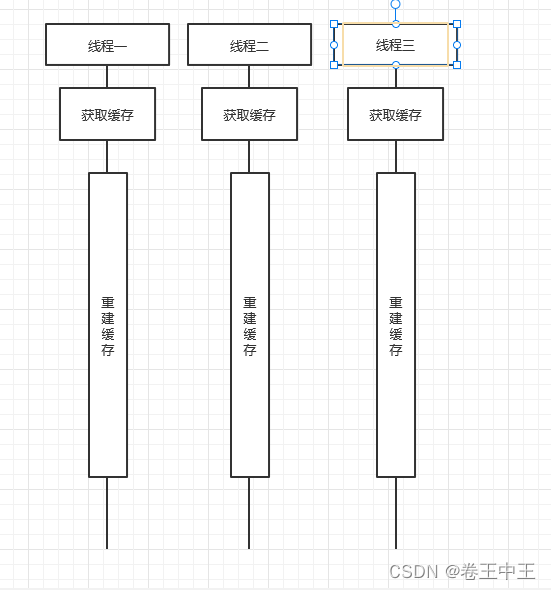
当某个热点数据在Redis过期,刚好被高并发访问,并且重建缓存比较耗时,大量 的请求访问Redis拿不到数据,都会进行重建缓存的操作,大量的请求就会访问数据库,造成数据库压力。
3.2 解决方案
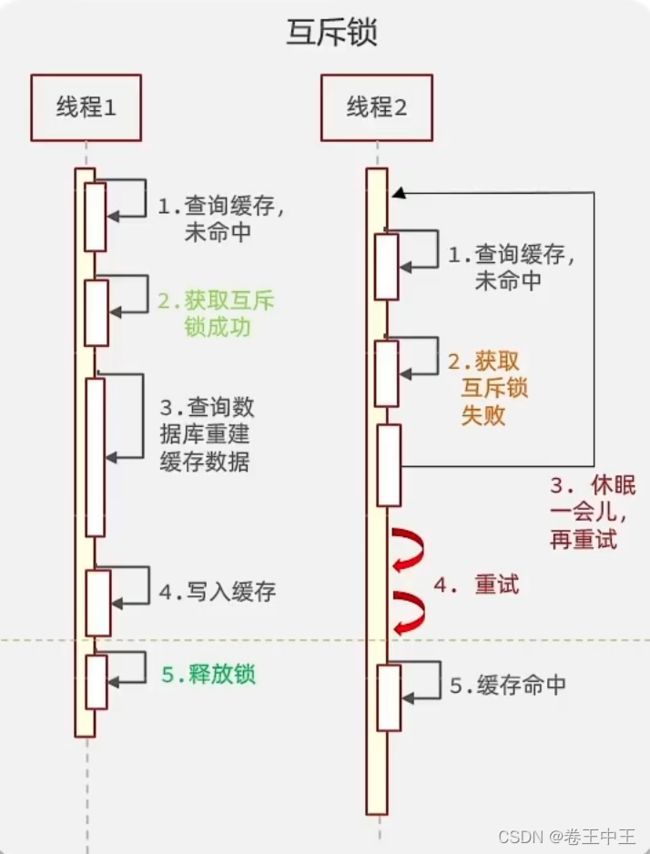
3.2.1 互斥锁
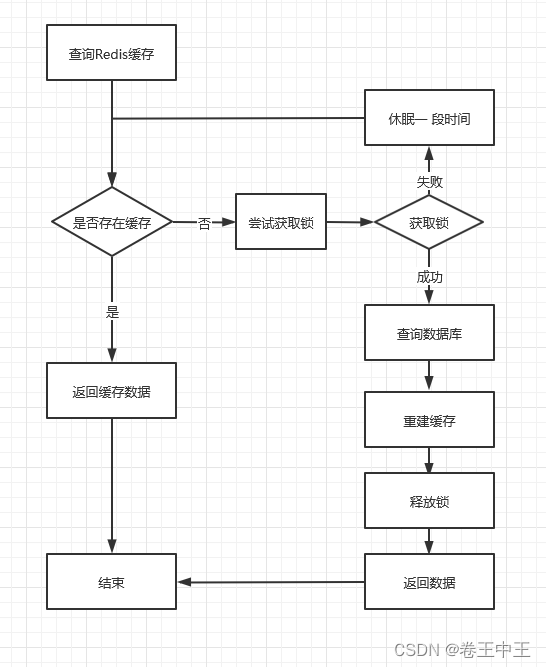
当多个并发请求一个过期的key时,多个请求不会都重建缓存,首先多个请求会进行争抢锁,获取到锁的请求会进行重建缓存,没有获取锁的请求会进行休眠一段时间,休眠完会重新从Redis获取缓存,如果缓存已经重建好了,就返回缓存的数据。如果缓存中任然没有数据,还会进行尝试获取锁,获取失败继续休眠。
优点:简单
缺点:会造成响应延迟,也可能会有死锁
/**
* 尝试获取锁
*
* @param lock 锁定主键
* @param time 锁的过期时间
* @param timeUnit 时间单位
* @return 是否获取到锁
*/
public Boolean tryLock(String lock, Long time, TimeUnit timeUnit) {
return stringRedisTemplate.opsForValue().setIfAbsent(lock, "Lock", time, timeUnit);
}
/**
* 释放锁
*
* @param lock 锁的主键
*/
public void releaseLock(String lock) {
stringRedisTemplate.delete(lock);
}
/**
* 解决缓存击穿问题(互斥锁)
*
* @param keyPrefix 主键前缀
* @param key 业务主键
* @param lock 锁的主键
* @param lockTime 超时时间
* @param bussinessKeyTime 业务主键缓存过期时间
* @param sleepTime 休眠时间
* @param timeUnit 时间单位
* @param queryDBFunction 查询数据库方法
* @param returnType 返回值类型
* @param 返回值类型
* @param 主键类型
* @return
*/
public <R,T> R resolveCacheBreakDownWithLock(String keyPrefix, T key,String lock, Long lockTime, Long sleepTime, Long bussinessKeyTime,
TimeUnit timeUnit, Function<T, R> queryDBFunction, Class<R> returnType) throws InterruptedException {
R returnData = null;
// 获取缓存key
String cacheKey = keyPrefix + ":" +String.valueOf(key);
while (returnData == null) {
// 根据key查询redis缓存
String cacheData = stringRedisTemplate.opsForValue().get(cacheKey);
if(StrUtil.isNotBlank(cacheData)) {
// 如果缓存中存在key,直接返回缓存数据
returnData = JSON.parseObject(cacheData, returnType);
}else if (cacheData != null) {
// 防止缓存穿透
return null;
} else {
// 缓存中不存在key或已经过期,尝试获取锁
if(tryLock(lock, lockTime, timeUnit)) {
// 成功获取锁,查询数据库
returnData = queryDBFunction.apply(key);
if(returnData == null) {
// 如果数据库不存在该数据,缓存空字符串
stringRedisTemplate.opsForValue().set(cacheKey, "", bussinessKeyTime, timeUnit);
// 释放锁
releaseLock(lock);
return null;
} else {
// 数据库存在该数据,重建缓存,返回数据
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(returnData), bussinessKeyTime, timeUnit);
// 释放锁
releaseLock(lock);
return returnData;
}
} else {
// 获取锁失败,线程休眠
TimeUnit.SECONDS.sleep(timeUnit.toSeconds(sleepTime));
}
}
}
return returnData;
}
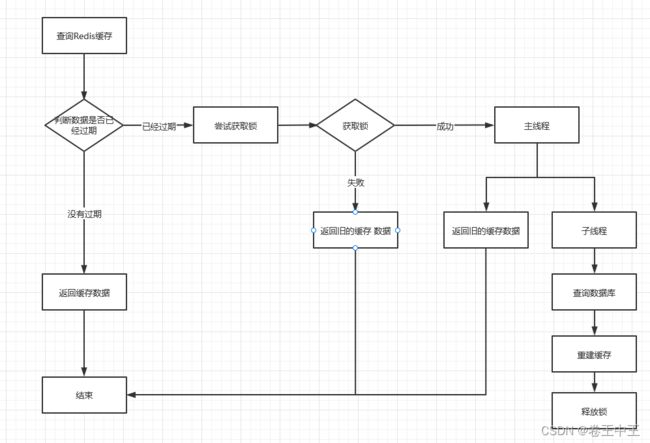
3.2.2 逻辑过期
缓存数据时不会为数据设置缓存过期时间,而是手动多存一个过期时间的字段,这个字段存储过期的时间点。当高并发请求时,每个请求会先根据过期时间字段判断缓存的数据是否已经过期,如果还没到过期时间,无需缓存重建,直接返回缓存数据。如果已经过了过期时间,首先会进行获取锁操作,如果获取锁成功,会创建一个新的线程进行缓存的重建操作,而主线程会拿旧的缓存数据返回。如果获取锁失败,表明此时已经有线程进行缓存重建了,直接返回旧的缓存数据。
优点:请求响应及时
缺点:复杂,可能会有短暂的数据不一致。

private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(3, 5, 3000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10));
/**
* 解决缓存击穿问题(逻辑过期时间)
* @param keyPrefix 缓存前缀
* @param key 缓存主键
* @param lock 锁
* @param lockTime 锁定时间
* @param bussinessKeyTime 业务缓存时间
* @param timeUnit 时间单位
* @param queryDBFunction 查询数据库方法
* @param 返回值类型
* @param 主键类型
* @return
* @throws InterruptedException
*/
public <R,T> R resolveCacheBreakDownWithExpirTime(String keyPrefix, T key,String lock, Long lockTime, Long bussinessKeyTime,
TimeUnit timeUnit, Function<T, R> queryDBFunction, Class<R> returnType) throws InterruptedException {
// 获取缓存的key
String cacheKey = keyPrefix + ":" + String.valueOf(key);
// 获取缓存数据
String cacheData = stringRedisTemplate.opsForValue().get(cacheKey);
// 解析缓存数据
RedisData redisData = JSON.parseObject(cacheData, RedisData.class);
// 获取当前时间
LocalDateTime now = LocalDateTime.now();
if (now.isAfter(redisData.getExpireTime())) {
// 缓存时间已经过期
if (tryLock(lock, lockTime, timeUnit)) {
// 成功获取到锁,开启新的线程重建缓存
threadPoolExecutor.execute(()->{
// 查询数据库
R apply = queryDBFunction.apply(key);
// 封装缓存数据
RedisData newObject = new RedisData();
LocalDateTime newNow = LocalDateTime.now();
newNow.plusSeconds(timeUnit.toSeconds(bussinessKeyTime));
System.out.println(newNow.getMinute());
newObject.setData(apply);
newObject.setExpireTime(newNow);
// 重建缓存
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(newObject));
try {
TimeUnit.SECONDS.sleep(50L);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 释放锁
releaseLock(lock);
});
}
}
// 返回数据
R data = JSON.parseObject(JSON.toJSONString(redisData.getData()), returnType);
return data;
}
4.缓存雪崩
4.1 场景
- Redis服务器宕机
- 大量Key同时间过期
4.2 解决方案
针对场景1:使用Redis集群模式,Redis主节点高可用
针对场景2:
①、设置有效期均匀分布
> 避免缓存设置相近的有效期,我们可以在设置有效期时增加随机值;
> 或者统一规划有效期,使得过期时间均匀分布。
> ②、数据预热
> 对于即将来临的大量请求,我们可以提前走一遍系统,将数据提前缓存在Redis中,并设置不同的过期时间。