毕业设计-基于深度学习的单通道语音降噪技术
目录
前言
课题背景和意义
实现技术思路
一、基于子空间投影的时域语音降噪
二、基于噪声信息辅助的双阶段语音降噪
三、感知高相关时频损失函数研究
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-基于深度学习的单通道语音降噪技术
课题背景和意义
语音作为一种快捷、高效的通信方式,在人人交互以及人机交互中拥有重要 地位。日常生活中有大量与语音相关的应用,如手机通话,自动 语音识别(Automatic Speech Recognition,ASR),智能语音助手,电子助听器 等。这些应用大多需要在相对安静的环境中才能正常工作,然而在现实世界中, 往往不可避免地存在各种各样的噪声干扰,如自然噪声(风声,雨声等),机器 噪声(发动机工作声,风扇转动声等)以及人为噪声(餐厅中他人的说话声等) 等等。这些噪声干扰会导致语音质量和可懂度的下降,进而影响语音应用的正常 工作。以人机交互中的重要环节语音识别为例,在复杂噪声的干扰下,语音质量 明显下降,语音识别准确率也随之严重降低。为了抑制噪声的干扰,提高语音应 用的鲁棒性,语音降噪变得愈发重要。语音降噪是一种从带噪语音信号中恢复干净语音信号,进而 提高语音信号听感质量和可懂度的技术手段。
实现技术思路
一、基于子空间投影的时域语音降噪
研究动机 令, , ∈ ℝ分别代表带噪语音信号,干净语音信号和加性噪声信号,其中 T 代表信号采样点数。则带噪语音信号可以由下式表示:
![]()
令(⋅)代表语音降噪模型,其中表示模型中的可学习参数,则增强后的语 音信号可以由下式表示:
![]()
语音降噪的目标在于让增强语音信号与干净语音信号拥有尽可能接近的语 音听感质量。

现有的基于深度学习的语音降噪方法大多采用了编码器-解码器的网络结构, 如上图所示。这类方法先通过编码器将带噪语音编码得到嵌入向量,经过一些中间处理后再将嵌入向量送入解码器来预测干净语音。然而送入解码器的嵌入向 量不可避免地同时包含语音信息和噪声信息,直接用它进行解码可能会影响对干 净语音的预测。
基于子空间投影的时域语音降噪方法描述
SPTSNRN 的整体结构如图所示。SPTSNRN 基于经典的时域降噪模型 Wave-U-Net设计。它主要由四部分构成,分别为编码器,投影模块,语音解码 器以及噪声解码器。对于输入的带噪语音 x,编码器首先将它编码得到包含高层 次特征的嵌入向量 embmix,该嵌入向量同时包含了语音信息和噪声信息。

(1) 投影模块
投影模块具体结构如图所示,它由一个卷积模块和两个并行的自注意力 层(Self-Attention,SA)构成。其中卷积模块用于进一步提取嵌入向量的局部特征,而两个自注意力层则用于提取全局信息并将 embmix 投影得到语音嵌入向量 embs 和噪声嵌入向量 embn。下面介绍使用自注意力层实现投影的原理。
自注意力层是构建 Transformer[25]的重要部分,它与递归神经网络一样具备 时序建模能力,能够提取时序信息。
自注意力层的可学习参数由 3 个矩阵构成, 依次为 ∈ ℝ ×, ∈ ℝ×和 ∈ ℝ×,其中,,分别表示查 询向量,键向量和值向量的维度, 表示输入时间序列的特征维度。最后值矩阵 V 与注意 力矩阵 A 相乘得到最终输出 ∈ ℝ×。自注意力层的输入输出关系如式所示。

通过简单推导不难得到 SA 的最终输出可以写成下面的形式:

可以看到输出序列的每一个时间点的输出都是矩阵与一向量的乘积。 如图所示,不难证明矩阵与向量相乘的结果是矩阵列向量的线性组合,因而 的每一帧都处在的列向量所张成的子空间内。

通过对两个添加正交约束,让它们的列向量彼此正交,我们可以让两个自 注意力层输出所在的子空间互相正交,从而极大程度地分离嵌入向量中的语音信 息与噪声信息。为此与 Subspace[40]一样,我们在训练中额外添加了针对两个 的正交约束损失 LOC,其计算方法如式所示:
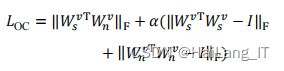
(2) 编码器 编码器的具体结构如图所示,它由 L 个卷积模块级联构成,每个卷积模 块包含一维 CNN,批归一化层(Batch Normalization,BN),含参修正线性单元 激活函数(Parametric Rectified Linear Unit,PReLU)以及下采样层(Down Sampling, DS)。

(3) 解码器 解码器包含了语音解码器和噪声解码器两个模块,两个解码器的具体结构完 全一致。

由于在编码过程和投影过程中难免会造成信息的丢失,故本文在编码器和解 码器对应卷积模块间添加了跳连。

二、基于噪声信息辅助的双阶段语音降噪
在以上基础上提出了基于噪声信息辅助的双阶段语音降噪模型 SPTSNRN-MN。该模型在 SPTSNRN 的基础上添加了融合网络(Merge Network, MN),该网络能够进一步利用 SPTSNRN 中噪声解码器预测的噪声信息来辅助 和提升最终的语音降噪效果。
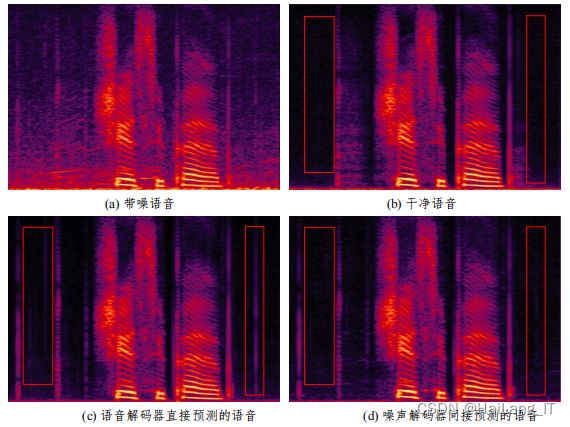
利用训练好的 SPTSNRN 对 VBD 测试集中的带噪语音同时预测 语音信号和噪声信号,然后比较语音解码器直接预测的语音信号和利用噪声解码 器间接预测的语音信号在 PESQ 上的差异。比较结果如图所示。

下图展示了间接 预测的语音和直接预测的语音的语谱图对比。其中带噪语音的噪声场景为公共广 场,信噪比为 12.5dB。
基于噪声信息辅助的双阶段语音降噪方法描述
选用两种融合方案都先通过网络预测权重, 然后通过该权重对直接预测的和间接预测的语音信号以加权相加的形式进行融 合。该权重能反映不同时间下直接预测和间接预测语音的相对质量,当某段时间 内间接预测的语音信号质量更好时,融合网络可以赋予它更大的权值,反之则赋 予直接预测的语音信号更大的权重,从而使得最终得到的语音信号拥有更好的语 音质量。
针对两种融合方案,设计了对应的融合网络。图展示了时域融合 网络的具体结构。其中̂和̂分别表示 SPTSNRN 预测的语音信号与噪声信号,x为带噪语音信号, ̂ 为最终预测的语音信号。

图展示了频域融合网络的具体结构。该网络完全由 5 个二维卷积模块构 成。其中前 4 个二维卷积模块由二维 CNN,BN 层以及 PReLU 激活函数构成, 最后一个卷积模块将 PReLU 激活函数替换成 Sigmoid 激活函数。所有 CNN 的 卷积核大小为(7,3),卷积步长为(1,1),从前至后 CNN 的输出通道数依 次为 36,72,72,36,1。、

通过将 SPTSNRN 与 MN 级联我们可以得到一个双阶段的语音降噪网络 SPTSNRN-MN,其网络结构如图所示。该网络首先在第一个阶段利用 SPTSNRN 预测语音信号以及噪声信号,然后在第二个阶段用 MN 将噪声信号与 语音信号相融合以得到更好降噪语音信号。

三、感知高相关时频损失函数研究
从损失函数出发,分析目前常用的损失函数与语音听感质量存在的失配 问题,并针对该问题提出了感知高相关时频损失函数。
研究动机
语音降噪的最终目的是希望让增强语音具有和真实语音一样的听感质量。尽 管 PESQ 等客观评价指标能较好地评估语音听感质量,但是由于这些指标在计算 过程中涉及了一些不可导的运算操作,所以无法直接将这些客观评价作为损失函 数指导网络的训练。
将 VBD 测试集中的带噪语音和干净语 音分解成 2 秒的片段,然后利用这些语音片段计算上述常用损失函数的损失值以 及对应的 PESQ,接着分析这些损失值与 PESQ 的相关度。这里我们采用样本皮 尔森相关系数 r 来衡量相关度,其计算方法如式所示:
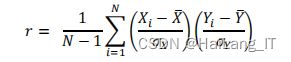
其中 N 为样本数,̅,̅分别代表 X 和 Y 的样本均值,和分别代表 X 和 Y 的样本标准差。r 的取值范围为-1 至 1,其绝对值越大,说明两个变量越相关,反之则说明越不相关。我们以样本的损失值为横坐标,PESQ 为纵坐标画出所有 样本的分布图,具体如图所示。

感知高相关时频损失函数方法描述
感知高相关视频损失函数的计算流程如图所示,其中与̂分别代表干净 语音和增强语音,与̂为对应的对数幅度谱(Log Amplitude Spectrum,LAS)。

相比 AES,MAES 中与感知更相关的误差分量获得了更大的权重。最后再对 MAES 在时间和频率上求平均便得到了最终的 PHRTF 损 失。PHRTF 损失详细的计算方法如式所示,其中⊗表示按元素 相乘。

1、频谱感知掩模预测
频谱感知掩模预测模块具体结构如图所示。该模块的结构比较简单,主 要包含了 L 个级联的卷积模块,一个动态平均池化层,一个线性层以及 Sigmoid 激活函数。其中每个卷积模块均由一个二维 CNN 以及 ReLU 激活函数组成。动 态平均池化层会对输入特征图的每个通道内的特征值取平均。

2、PHRTF 损失训练方法
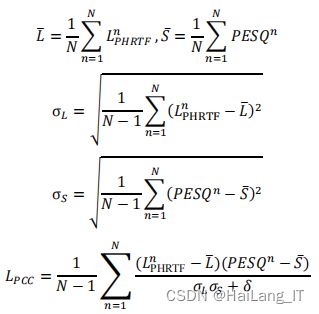
未训练的 PSMP 不能正确预测 PSM,故需要用合适的训练任务对 PSMP 模 块进行训练,以提升 PHRTF 损失与语音听感质量的相关度。考虑到 PESQ 能较 好的衡量语音听感质量,这里我们以提升 PHRTF 损失与 PESQ 的相关度为训练 目标。我们用皮尔森相关系数来衡量两者的相关度
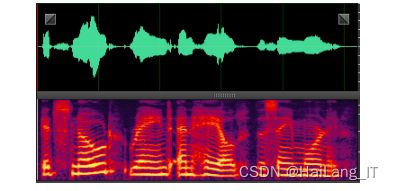
实现效果图样例
语音降噪技术:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!